1.背景
构建代理(或任何LLM应用程序)的难点在于如何确保其足够可靠。虽然它们在原型中可能有效,但在实际应用场景中往往会失败。如何编写prompt至关重要。
(1).Agent为什么没有给出相对来说满意的东西?
当 Agent 运行未达预期时,根源通常在于内部的 LLM 调用产生了错误的决策或行为。这种失效主要源于两个维度:
- 模型基座能力不足(底层模型推理上限受限)
- 上下文供给失当(未能为模型输入"正确"的信息)
实践证明,后者往往才是导致 Agent 可靠性缺失的首要原因。**上下文工程(Context Engineering)**的本质,是以最优的格式为 LLM 精准匹配所需的实时信息与工具。这不仅是 AI 工程师的核心职责,更是打破 Agent 可靠性瓶颈的关键所在
(2).Agent 循环逻辑
一个典型的 Agent 循环由两个核心阶段交替构成:
- 模型调用(Model Call):将精心构造的 Prompt 与可用工具集(Tools)输入给 LLM。模型根据上下文进行推理
- 工具执行(Tool Execution):系统接收模型发出的请求并驱动相应工具运行。执行完成后,将产生的工具结果(Tool Results)反馈至上下文,为下一轮模型推理提供依据。
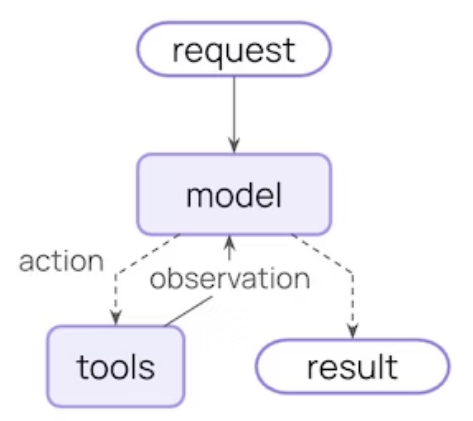
这个循环会持续,直到LLM决定完成
(3).核心调控点
构建可靠 Agent 的关键,在于精准管控 Agent 循环中每一个步骤内部以及步骤之间的信息流转:
| 上下文类型 | 调控维度 | 存储属性 |
|---|---|---|
| 模型上下文 (Model Context) | 调控输入模型的内容:指令(Instructions)、消息历史、可用工具集及输出格式。 | 瞬态 (Transient) |
| 工具上下文 (Tool Context) | 调控工具的访问与输出权限:对状态、存储空间及运行环境的读写逻辑。 | 持久 (Persistent) |
| 生命周期上下文 (Life-cycle) | 调控模型调用与工具执行之间的衔接:如自动摘要、护栏(Guardrails)策略、日志记录等。 | 持久 (Persistent) |
- 瞬态上下文 (Transient Context):指单次模型调用时 LLM 可见的实时数据。开发者可以在不改变系统全局状态的前提下,灵活调整当前轮次的对话消息、工具定义或 Prompt 模版。
- 持久性上下文 (Persistent Context):指在多个对话轮次中跨步保留的状态。这类上下文通常由生命周期钩子(Life-cycle Hooks)或工具写入操作进行永久化修改,构成了 Agent 的长期记忆与运行背景。
2.模型上下文 (Model Context)
模型上下文决定了单次模型调用的输入内容,包括指令、工具集、模型选择及输出格式。这些调控维度直接影响 Agent 的可靠性 与运行成本。
| 维度 | 定义与作用 |
|---|---|
| 系统提示词 (System Prompt) | 由开发者定义的基准指令,用于设定 LLM 的角色、行为准则及任务边界。 |
| 消息列表 (Messages) | 发送给 LLM 的完整对话历史,为当前轮次提供必要的语境和短期记忆。 |
| 工具集 (Tools) | Agent 可调用的外部实用程序或 API,赋予模型执行具体动作的能力。 |
| 模型配置 (Model) | 执行任务的具体模型实例及其配置(如 Temperature, Top-P 等)。 |
| 响应格式 (Response Format) | 对模型最终输出的 Schema 规范要求(如 JSON 格式定义),确保下游任务可解析。 |
(1).System Prompt
系统提示词(System Prompt)定义了 LLM 的核心行为逻辑与能力边界。在复杂的实际应用中,不同的用户群体、业务场景或对话阶段往往需要差异化的指令引导。高可靠性的 Agent 不会使用一成不变的静态提示词,而是通过动态整合以下要素,为当前对话状态提供最精准的指令
(2).消息管理 (Messages)
消息流(Messages)构成了发送至 LLM 的核心提示词内容。为了确保模型能够做出高质量的响应,精准管理对话历史中的内容至关重要。
(3).工具管理 (Tools)
工具(Tools)是 Agent 与外部世界交互的桥梁,使其能够操作数据库、API 以及各种外部系统。工具的定义质量 与检索精度直接决定了模型能否有效完成复杂任务。
- 工具定义 (Tool Definition)
LLM 并不直接运行代码,而是通过阅读工具的描述来决定是否调用。因此,高水平的工具定义需要包含:- 清晰的语义描述:明确工具的用途、限制及适用场景。
- 精准的 Schema 规范:详细定义输入参数的类型、格式及必要性。
python
from langchain.tools import tool
@tool(parse_docstring=True)
def search_orders(
user_id: str,
status: str,
limit: int = 10
) -> str:
"""按状态搜索用户订单.
当用户查询订单历史记录或想要查看订单状态时,可以使用此功能。
参数:
user_id:用户的唯一标识符
status:订单状态:'pending'、'shipped' 或 'delivered'
limit:返回结果的最大数量
"""
# Implementation here
pass- 工具选择 (Tool Selection)
在 Agent 架构中,并不是工具越多越好。工具集的规模与 Agent 的表现呈非线性关系:工具过载 会干扰模型注意力(Context Overload)并增加调用错误率;而工具缺失则会直接限制任务的完成能力。
(3).模型选择 (Model Selection)
不同的模型在推理能力、运行成本以及上下文窗口(Context Window)上各有千秋。在 Agent 的单次任务运行中,根据当前步骤的复杂度动态切换模型,是平衡性能与成本的最佳路径。
python
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from langchain.chat_models import init_chat_model
from typing import Callable
# Initialize models once outside the middleware
large_model = init_chat_model("claude-sonnet-4-6")
standard_model = init_chat_model("gpt-4.1")
efficient_model = init_chat_model("gpt-4.1-mini")
@wrap_model_call
def state_based_model(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""Select model based on State conversation length."""
# request.messages is a shortcut for request.state["messages"]
message_count = len(request.messages)
if message_count > 20:
# Long conversation - use model with larger context window
model = large_model
elif message_count > 10:
# Medium conversation
model = standard_model
else:
# Short conversation - use efficient model
model = efficient_model
request = request.override(model=model)
return handler(request)
agent = create_agent(
model="gpt-4.1-mini",
tools=[...],
middleware=[state_based_model]
)一个复杂的 Agent 任务通常可以拆解为不同难度的子任务,对应的模型策略如下:
- 轻量化模型 (Small/Fast Models) :
适用于逻辑简单的任务,如意图分类、简单的文本格式化或初步的消息摘要。 - 旗舰级模型 (Frontier/Large Models) :
适用于高难度的逻辑推理、复杂的代码生成或多步骤的规划任务。 - 长文本模型 (Long-Context Models) :
专门用于处理海量文档检索、大规模历史记录分析或超长代码库的理解。
(4).响应格式 (Response Format)
响应格式的核心价值在于将非结构化的文本转换为经过验证的结构化数据(Structured Data)。在需要提取特定字段或为下游系统供数时,自由形式的文本输出往往难以满足工程要求。
- 自由文本 (Free-form):适合与人类直接沟通,语义丰富但难以自动化处理。
- 结构化数据 (JSON/Schema):适合作为系统插件或工作流的一环,确定性极高。
技术要点: 设置
Response Format是消除模型输出"随机性"的最有效手段之一。它不仅定义了输出的样子 ,更定义了任务完成的标准。
-
定义格式(Defining Formats)
Schema 定义是模型的"执行蓝图"。通过精确设定字段名称、数据类型及语义描述,开发者可以明确约束模型的输出逻辑,确保其生成结果完全符合业务预期。要构建一个高引导性的 Schema,需要从以下三个维度进行定义:
- 字段名称 (Field Names) :使用具有明确语义的变量名,帮助模型理解每个字段的用途(例如使用
delivery_address而非addr)。 - 数据类型 (Types) :严格限制输出的数据格式(如
string、integer、boolean或自定义的enum枚举值)。 - 字段描述 (Descriptions) :这是最关键的引导环节。在描述中加入具体的约束或逻辑要求,相当于在输出阶段植入了微型指令。
- 字段名称 (Field Names) :使用具有明确语义的变量名,帮助模型理解每个字段的用途(例如使用
python
from pydantic import BaseModel, Field
class CustomerSupportTicket(BaseModel):
"""Structured ticket information extracted from customer message."""
category: str = Field(
description="Issue category: 'billing', 'technical', 'account', or 'product'"
)
priority: str = Field(
description="Urgency level: 'low', 'medium', 'high', or 'critical'"
)
summary: str = Field(
description="One-sentence summary of the customer's issue"
)
customer_sentiment: str = Field(
description="Customer's emotional tone: 'frustrated', 'neutral', or 'satisfied'"
)- 格式选择 (Selecting Formats)
动态响应格式选择(Dynamic Response Format Selection)允许 Agent 根据交互情境实时调整输出 Schema。这种灵活性确保了数据在不同阶段、针对不同受众时,始终保持最佳的复杂度与实用性。
python
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from pydantic import BaseModel, Field
from typing import Callable
class SimpleResponse(BaseModel):
"""简单回复,适合早期对话。"""
answer: str = Field(description="简短的回答")
class DetailedResponse(BaseModel):
"""对已展开的对话做出详细回应。"""
answer: str = Field(description="A detailed answer")
reasoning: str = Field(description="Explanation of reasoning")
confidence: float = Field(description="Confidence score 0-1")
@wrap_model_call
def state_based_output(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""根据所在state选择输出格式。"""
# request.messages is a shortcut for request.state["messages"]
message_count = len(request.messages)
if message_count < 3:
# Early conversation - use simple format
request = request.override(response_format=SimpleResponse)
else:
# Established conversation - use detailed format
request = request.override(response_format=DetailedResponse)
return handler(request)
agent = create_agent(
model="gpt-4.1",
tools=[...],
middleware=[state_based_output]
)(5).工具上下文 (Tool Context)
工具具有独特的双重属性:它们不仅读取 上下文,还会写入上下文。在 Agent 循环中,工具不仅是执行单元,更是信息流转的枢纽。
- 工具读取(Reads)
在真实的业务场景中,工具的运行往往不仅依赖于 LLM 提供的参数。为了做出正确决策,工具需要从更广泛的环境中获取支撑数据,例如用于数据库查询的 User ID 、访问外部服务的 API Key ,或是当前的会话状态 。工具通过读取以下三个维度的上下文来补全执行所需的关键信息:- 状态 (State - 短期记忆) :
读取当前会话的即时变量。例如:读取当前购物车中的物品列表,以便执行"计算总价"的操作。 - 存储 (Store - 长期记忆) :
检索跨会话的持久化数据。例如:读取用户的历史偏好或账号等级,以决定展示哪种折扣。 - 运行环境 (Runtime Context - 静态/全局配置) :
获取系统级的敏感或全局信息。例如:从环境变量中读取私有 API 密钥,或获取当前的服务器地理位置。
- 状态 (State - 短期记忆) :
python
from langchain.tools import tool, ToolRuntime
from langchain.agents import create_agent
@tool
def check_authentication(
runtime: ToolRuntime
) -> str:
"""检查用户是否已通过身份验证。"""
# Read from State: check current auth status
current_state = runtime.state
is_authenticated = current_state.get("authenticated", False)
if is_authenticated:
return "用户已通过身份验证"
else:
return "用户没有通过身份验证"
agent = create_agent(
model="gpt-4.1",
tools=[check_authentication]
)架构洞察 :将这些"背景参数"与"模型参数"分离,是保障 Agent 安全性的关键。永远不要让 LLM 直接处理 API Key 等敏感信息,而应由工具在执行层通过读取 Runtime Context 隐式注入。
- 工具写入 (Writes)
工具的执行结果不仅用于辅助 Agent 完成当前任务,还具有塑造未来决策 的作用。工具可以通过两种方式将关键信息注入上下文:一种是直接反馈给模型,另一种则是更新 Agent 的长期或短期记忆。-
直接反馈 (Direct Feedback) :
工具将执行结果实时返回给 LLM。模型基于这些即时反馈(如 API 返回的成功状态或错误详情)来决定下一步行动。
-
记忆更新 (Memory Update) :
工具可以将关键信息写入持久化存储(Store)或当前会话状态(State)。这意味着即使在多轮对话之后,这些重要的上下文信息依然对未来的步骤可见。
-
python
from langchain.tools import tool, ToolRuntime
from langchain.agents import create_agent
from langgraph.types import Command
@tool
def authenticate_user(
password: str,
runtime: ToolRuntime
) -> Command:
"""验证用户身份并更新状态。"""
# Perform authentication (simplified)
if password == "correct":
# Write to State: mark as authenticated using Command
return Command(
update={"authenticated": True},
)
else:
return Command(update={"authenticated": False})
agent = create_agent(
model="gpt-4.1",
tools=[authenticate_user]
)工程要点 :优秀的工具设计能够区分"瞬时结果"与"重要常识"。将那些对未来有决策价值的信息写入 Store,是让 Agent 具备"学习能力"和"长效记忆"的核心机制。