1. 现状把握
- 复杂、长周期编程任务的稳定性不足:传统模型在耗时数小时、涉及多轮迭代和大量代码修改的任务中容易崩溃或中断。K2.6 通过 12 小时以上的连续工作案例证明了其稳定性。
- 任务自主性与并行能力有限:面对需要生成多格式交付物(报告、数据表、PPT)的复杂任务,模型缺乏自主拆解、并行处理与跨工具协作的能力。
- 编程模型泛化能力不足:模型在特定语言或框架上表现好,但难以跨语言(Rust、Go、Python、前端、DevOps)和跨任务类型稳定输出。
- Token 消耗与步骤冗余:模型解题步骤冗长,导致效率低、成本高、出错机会多。
- 从单一功能生成到完整应用开发的跨越问题:K2.6 需要从"帮我画个页面"进化到"帮我生成一个完整应用"(包含用户认证、数据库操作等)。
- 多智能体协同的效率与规模瓶颈:上一代模型在并发子智能体数量(100 个)和协同步骤数(1500 步)上存在限制,难以高效处理超大规模、多格式输出的复杂项目。
- AI 智能体的持续自主运行能力:模型需要能够全天候、跨应用地自主运行,在无人监督的情况下处理监控、告警等运维任务。
- 开源模型与闭源顶尖模型的差距:此前开源模型在主流编程基准上难以超越 GPT‑5.4 和 Claude Opus 4.6 等闭源模型。
2. Kimi K2.6横空出世
正式发布并开源新一代模型 Kimi K2.6,并配套推出开放的智能体生态 Claw Groups(第一文中称为 Agent 集群功能)。
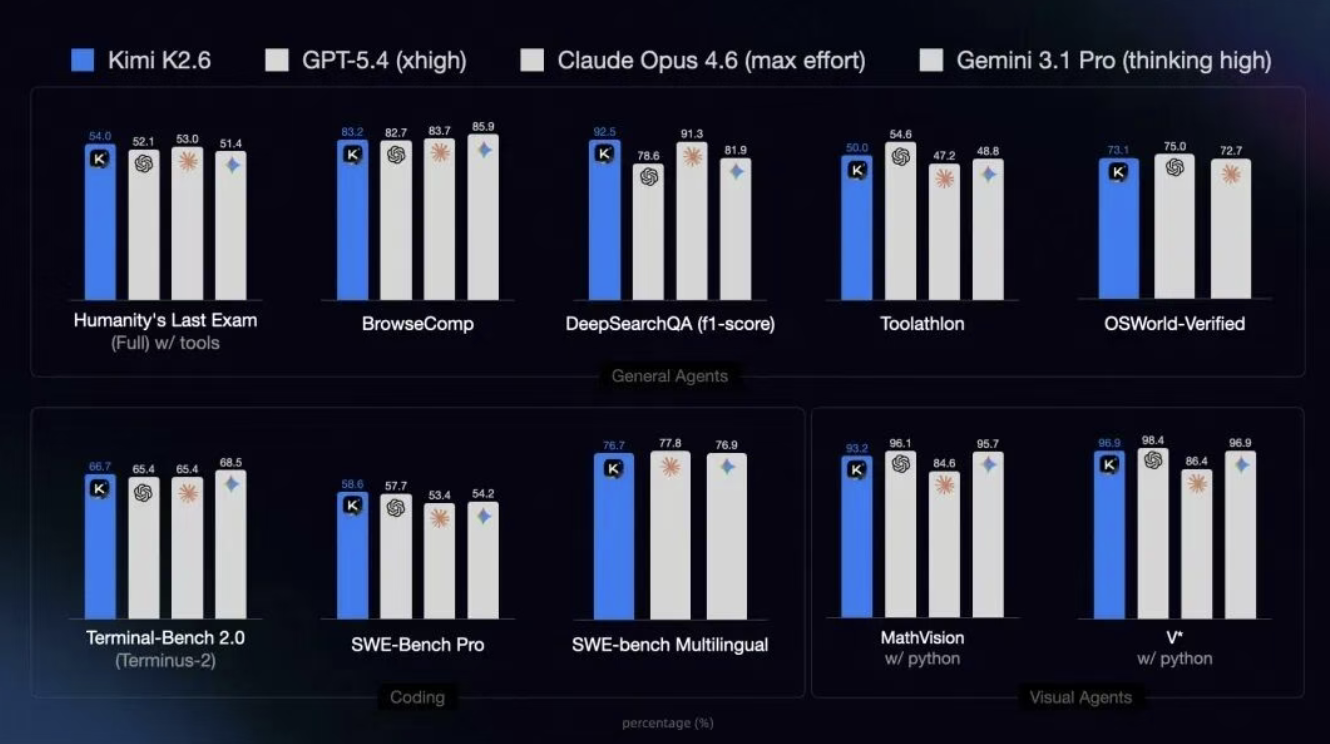
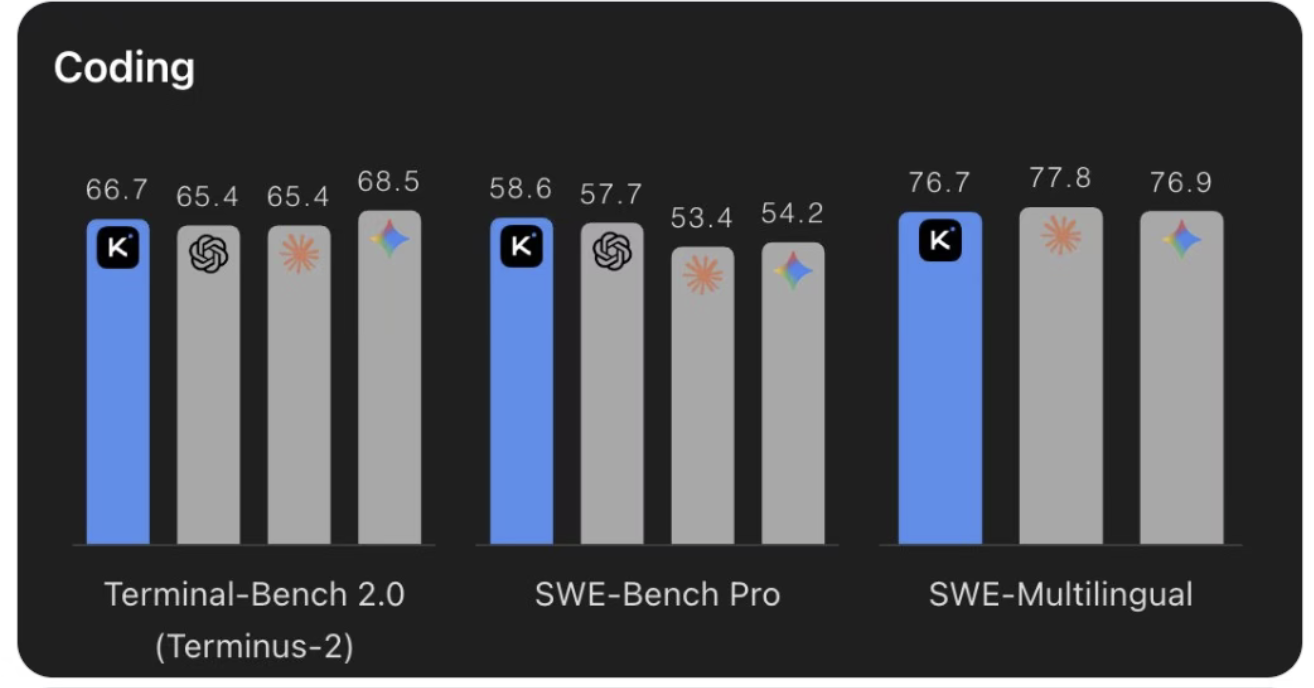
- K2.6 在 SWE‑Bench Pro 等主流编程基准上取得开源 SOTA(58.6 分),首次在主流基准上赢过 GPT‑5.4(xhigh)和 Claude Opus 4.6(max effort)。
- 用户只需输入一句话指令,模型就能自动拆解任务,创建多个不同角色的子 Agent(上限 300 个、4000 步),让它们并行工作,最终零人工干预地完成全套交付物。
- 通过 Claw Groups 构建一个能容纳异构智能体(来自任意设备、运行任意模型)、支持全天候持续运行的开放式协作平台,K2.6 在其中担任动态协调者。
3. 核心方法和策略
3.1 长时稳定性与效率优化
- 支持连续工作 12 小时以上不崩溃(实测 Zig 部署 12 小时、exchange-core 重构 13 小时)。
- 平均步骤数比 K2.5 减少约 35%,工具调用成功率达 96.60%,长上下文稳定性提升 18%。
3.2 大幅扩展的智能体集群(Agent Swarm)架构
- 并发子智能体数量从 100 个扩展至 300 个 ,协同步骤数从 1500 步扩展至 4000 步。
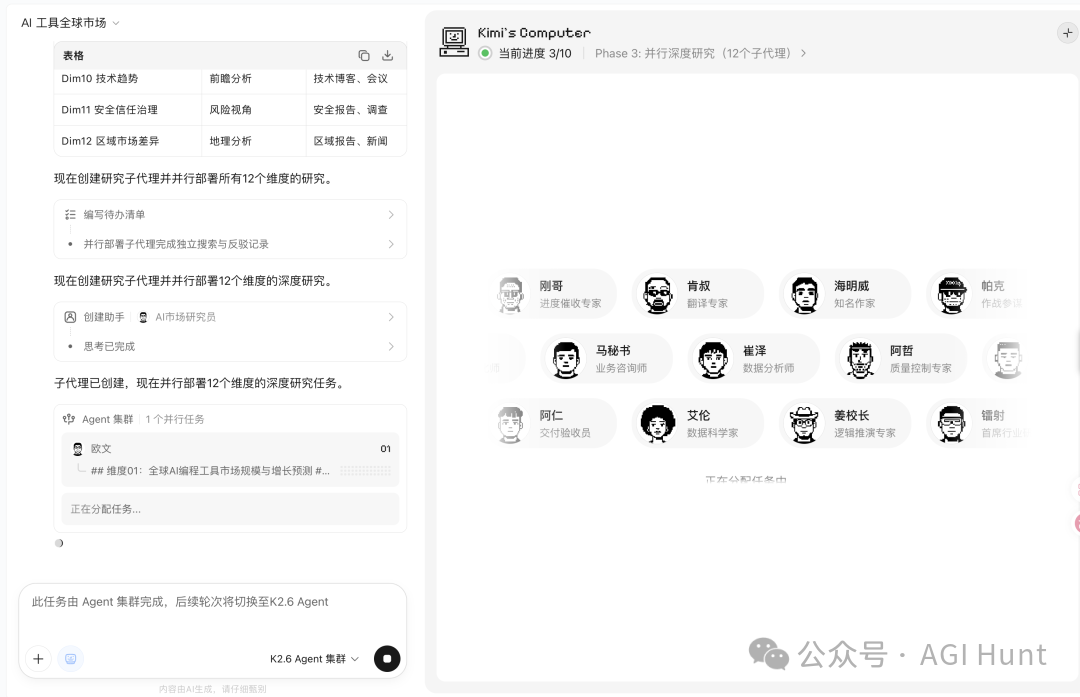
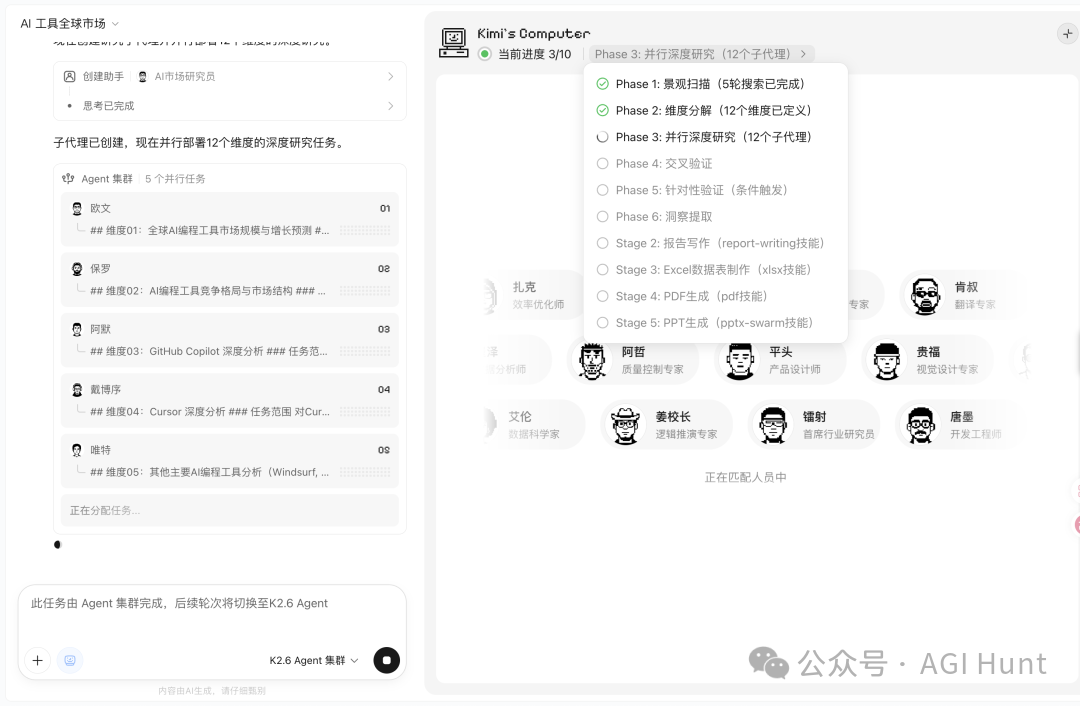
- 任务拆解流程:用户一句话指令 → 制定执行计划 → 拆解为多个维度 → 自动创建有名字、有角色定位的子 Agent → 各 Agent 并行搜索/分析(使用内置浏览器环境 Kimi's Computer)→ 交叉验证与洞察提取 → 并行生成多格式产物(PDF、Excel、PPT、网页等)。
- 支持将高质量文件(PDF、表格、PPT)转化为可复用的"技能" ,保留结构和格式特征,供后续任务直接调用。
3.3 跨语言与全栈开发能力深化
- 支持 Rust、Go、Python、前端、DevOps 工作流等多种语言和框架。
- 从简单提示词直接生成包含 WebGL 着色器、GSAP 动画、Three.js 3D 效果的复杂前端界面,以及覆盖用户认证、交互逻辑、数据库操作的轻量全栈应用。
3.4 开放异构的智能体生态 Claw Groups
- K2.6 在集群中担任动态协调者:根据各智能体的"技能图谱"和可用工具分配任务,失败时自动接管、重新分配,管理从启动到验收的完整交付生命周期。
- 支持异构生态:允许来自任意设备(本地笔记本、移动设备、云端实例)、运行任意模型的智能体接入同一协作空间,每个智能体可携带各自的专属工具、技能和持久化记忆上下文。
3.5 持续自主运行能力
- 为 OpenClaw、Hermes Agent 等智能体提供底层支持,使其能跨应用、全天候持续运行,在无人监督的场景下自主完成任务。
4. 实例参考
实例一:AI 编程工具市场分析报告
- 任务描述:用户一句话指令------"请用 Agent 集群帮我完成一份关于「2025-2026 全球 AI 编程工具市场分析」的交付物套装:一份 10 页的行业分析 PDF,一份 Excel 数据表,一份 15 页 PPT"。
- 执行过程 :
- K2.6 花几分钟制定计划,拆成 12 个维度(市场格局、竞争格局、Cursor 深度、Copilot 深度、其他工具对比、开源生态、功能技术对比、定价商业模式、企业采用、技术趋势、安全信任治理、区域市场差异)。
- 自动创建 12 个子 Agent(如翔哥、青枝、海明威、马秘书、崔浩、阿哲等),各有名字、头像和角色定位。
- 12 个 Agent 同时打开 Kimi's Computer 并行搜索数百上千个页面。
- 进入产物制作阶段后,又并行派出三个子代理:巴泰(Excel)、陈野(PDF)、家情(PPT)。陈野在 sandbox 里用 Python 写代码生成文件(装 Chromium,用 HTML 转 PDF),并主动发现图片尺寸问题并修复。
- 总耗时约一小时,零人工干预。
- 交付结果 :
- PDF 行业报告:12 页,覆盖市场格局(Copilot 42% vs Cursor $2B ARR)、采用率(84% 开发者使用、91% 企业采用但仅 29% 信任)等。
- Excel 数据表:主要工具的功能、定价、用户量级对比,含多个 sheet。
- PPT:15 页,带图表、数据和分析框架。
实例二:Zig 语言本地部署 Qwen3.5-0.8B 模型
- 任务描述:在 Mac(M3 Max)上本地部署 Qwen3.5-0.8B 模型,并使用 Zig 语言实现推理优化。
- 执行过程与结果 :共调用工具 4000 余次,持续执行 12 小时 ,经历 14 次迭代 。最终推理吞吐量从约 15 tokens/sec 提升至约 193 tokens/sec,比 LM Studio 快约 20%。
实例三:重构开源金融撮合引擎 exchange-core
- 任务描述 :自主重构一个具有 8 年历史的开源金融撮合引擎
exchange-core。 - 执行过程与结果 :历时 13 小时 ,遍历 12 种优化策略,调用工具逾 1000 次,精确修改超过 4000 行代码 。模型通过分析 CPU 和内存火焰图,定位瓶颈后重新设计核心线程拓扑结构(从
4ME+2RE调整为2ME+1RE)。最终中等吞吐量提升 185% (从 0.43 MT/s 到 1.24 MT/s),峰值吞吐量提升 133%(从 1.23 MT/s 到 2.86 MT/s)。
实例四:连续 5 天的自主运维
- 任务描述:月之暗面 RL 基础设施团队将一个基于 K2.6 的智能体用于生产环境运维。
- 执行过程与结果 :该智能体被连续运行了 5 天,期间自主处理监控告警、事故响应和系统运维,完整覆盖从告警触发到问题解决的全流程。
实例五:内部评测套件 Claw Bench 对比
- 任务描述:在编程任务、即时通讯集成、信息研究、定时任务管理和记忆调用五个领域,对比 K2.6 和 K2.5 的性能。
- 实验结果 :K2.6 在全部指标上均明显优于 K2.5 ,尤其在无人监督的持续运行场景中提升更为突出。
实例六:前端设计能力对比
- 任务描述:K2.6 Agent 与 Gemini 3.1 Pro 在 Google AI Studio 上进行前端设计能力对比。
- 实验结果:Kimi 胜出 47.5%,平手 21.1%,Google 胜出 31.4%。
5. 结论
- 开源模型开始领跑:K2.6 在主流编程基准上首次击败最强闭源模型 GPT‑5.4 和 Claude Opus 4.6,标志着开源不再是追赶者,而是开始领跑。
- AI 编程工具的竞争已转向"产品力":竞争焦点从"谁的模型跑分高"转向"谁能帮你做更多的事"------跑分是门票,Agent 集群是产品力。
- 一句话 + 零干预 + 一小时 = 完整交付物:用户只需输入一句话,K2.6 就能自主拆解任务、并行运作,一小时零人工干预地交付完整专业的交付物套装。
- 全栈应用生成能力是下一个里程碑:K2.6 已经从"帮我画个页面"进化到"帮我生成一个完整应用"。
- 智能体集群能力实现代际跃升:并发子智能体数量扩展至 300 个、步骤数扩展至 4000 步,并支持将输出物转化为可复用的"技能",使 AI 能够处理前所未有的复杂任务。
- 开启了开放的异构智能体生态:Claw Groups 允许不同来源、不同模型的智能体无缝协作,K2.6 在其中扮演核心协调者角色,为构建大规模、混合型 AI 团队奠定了基础。
- 具备了全天候自主运行的可靠性:通过连续 5 天自主运维等案例,证明了 K2.6 已具备在生产环境中长期、稳定、无人监督地执行关键任务的能力。
- 价格优势明显:K2.6 的 API 价格仅为 Claude Opus 4.6 的六分之一(出自第一文)。
- 发布节奏加快:从 K2.5(1 月底)到 K2.6(4 月),不到三个月完成一次大版本迭代(出自第一文)。
6. 注意事项
- 生成内容需要人工复核:虽然"大毛病确实没有",但"小问题多少还是有一点的"------如果直接拿来给出版社出书,"还是要再过目一下子"。日常参考、学习或做分析则足够。
- 任务复杂时耗时较长:第一文指出"非要说有什么缺点,那就是略有点久",但这也取决于任务复杂度(如核心实例耗时约一小时)。
- Agent 集群依赖内置浏览器环境:子 Agent 并行搜索时使用的是"Kimi's Computer(一个内置的浏览器环境)",任务执行可能依赖于特定环境支持。
- 部分实例的呈现存在技术限制:第一文在展示前端能力时出现了多次"视频加载失败,请刷新页面再试"的提示,说明在普通浏览环境下无法完整复现所有展示效果。
- 与最顶尖模型仍有差距:第二文承认,尽管 K2.6 非常强大,但"与 A 厂刚发布 Mythos 和 opus 4.7 还有差距"。
- 体验存在主观性 :第二文指出,"真实能力如何,以你的体验为准",官方基准测试和展示案例可能无法完全代表所有用户的真实使用感受,实际效果可能因具体场景和任务而异。
7. 模型参数与部署事项
1. 开源内容与许可
| 开源项目 | 具体内容 | 获取方式 / 说明 |
|---|---|---|
| 模型权重 | 1 万亿参数的 MoE 模型权重文件 | Hugging Face(moonshotai/Kimi-K2.6)或 Gitee 镜像 |
| 模型代码与配置 | 模型架构定义、推理代码、使用说明 | 同上,包含配置文件 |
| 基础使用教程 | 部署指南、API 接入文档 | 官方文档网站 |
| Ollama 集成 | 一键运行命令 | ollama run kimi-k2.6(对 Mac 用户友好) |
| 开源许可协议 | Modified MIT License | ✅ 允许学术研究、个人非商业项目 ❌ 不允许直接用于商业用途(商业需使用官方 API) |
2. 参数规模
| 参数类型 | 数值 | 说明 |
|---|---|---|
| 总参数量 | 1 万亿 (1 Trillion) | 模型全部参数,奠定知识广度 |
| 激活参数量 | 320 亿 (32 Billion) | 每次推理实际计算参数量,保证效率 |
| 上下文长度 | 256K tokens | 可一次性处理约《三体》三部曲体量 |
| 模型架构细节 | 61 层, 384 个专家, MLA 注意力等 | 详见官方技术文档 |
3. 个人开发者所需的算力资源(按部署方式分类)
| 部署方式 | 硬件要求 | 性能表现 | 成本区间 | 优势 | 劣势 |
|---|---|---|---|---|---|
| 本地 Mac (Apple Silicon) | M1/M2/M3 Pro/Max 芯片,建议 32GB+ 内存 | 实测推理吞吐量最高 193 tokens/s(比 LM Studio 快 20%) | 一次性设备成本(已有 Mac 则零成本) | 数据本地,无需联网,体验流畅 | 性能低于 GPU 集群,不适合高并发 |
| GPU 云服务器 | 推荐 8× NVIDIA H100 80GB(完整 BF16 权重约 595GB,需 640GB 显存) | 可达到最佳推理性能(使用 vLLM 或 SGLang) | 按小时计费,成本较高 | 性能最强,可定制,适合大规模压测 | 配置复杂,个人长期使用昂贵 |
| 量化版本(4-bit) | 显存需求降低,但仍需多卡(1T 总参数量 4-bit 约 500GB) | 性能有一定损失 | 仍需高端 GPU 集群 | 降低显存门槛 | 个人 PC 仍无法单机运行 |
| 官方 API 调用 | 无需任何本地 GPU | 稳定、低延迟 | 按量付费:约 ¥0.95 / 百万输入 tokens | 零门槛、免运维、最适合个人开发测试 | 需联网,高频使用可能累积费用 |
💎 针对个人开发者的核心建议
| 使用场景 | 推荐方案 | 理由 |
|---|---|---|
| 快速验证想法、开发应用 | 使用官方 API | 成本最低、无需配置、即刻上手 |
| 本地体验、学习模型能力 | M 系列芯片 Mac + Ollama | 一条命令运行,性能可接受,数据安全 |
| 深度研究、性能调优 | 租用 8×H100 云实例 + 4-bit 量化 | 平衡成本与性能,可复现论文结果 |