最近李飞飞的开源3D高斯溅射渲染引擎Spark 2.0感觉非常棒,Spark 2.0基于Three.js构建,用户可以通过WebGL2,将包含1亿+splats(3D高斯点/泼溅点)的超大规模3D世界,流式传输到任意设备上,包括桌面、iOS、Android、VR。Spark前身是World Labs开发的一款内部3D高斯溅射渲染引擎。彼时市面上的web渲染引擎均存在明显短板,例如,部分引擎一次只能正确渲染一个3D高斯溅射对象;部分引擎无法不能动态动画化splats;还有些引擎基于小众3D框架开发,或采用尚未普及的WebGPU技术,导致设备兼容性受限。
这款内部渲染引擎曾亮相于团队2024年发布的大型世界模型研究预览,以及早期场景展示项目Lofi Worlds。为了让更多开发者都能打造交互式3D高斯溅射web体验,团队整合技术积累,在2025年开源了一款通用型3D高斯溅射渲染引擎。当时名字还叫做Forge, 后改名Spark。
传统3D建模通过带纹理映射的三角形,一块一块拼出物体的表面。3D高斯溅射(3D Gaussian Splatting)则采用数百万个半透明椭球体(也就是splats),通过这些椭球体的色彩融合,呈现出超写实的细节效果。
对比两种构建三维世界的核心技术:传统建模像是用"方块"拼图,而3D高斯溅射像是用"云雾"渲染。
简单来说,一个靠"硬拼",一个靠"软叠"。
文章目录
-
- 0、我的知识储备
- [1. 传统3D建模:像用"乐高"拼装](#1. 传统3D建模:像用“乐高”拼装)
- [2. 3D高斯溅射 (3DGS):像用"油墨"喷绘](#2. 3D高斯溅射 (3DGS):像用“油墨”喷绘)
- [3. 什么是 Splat?(画家的"斑点")](#3. 什么是 Splat?(画家的“斑点”))
- [4. 画家算法(Painter's Algorithm):怎么画?(从后往前叠)](#4. 画家算法(Painter's Algorithm):怎么画?(从后往前叠))
- 6、多技术混合
- [7、3D 生成技术](#7、3D 生成技术)
-
- [7.1. NeRF (神经辐射场):用"神经网络"记忆场景](#7.1. NeRF (神经辐射场):用“神经网络”记忆场景)
- [7.2. Diffusion (扩散模型):用"AI 推理"创造内容](#7.2. Diffusion (扩散模型):用“AI 推理”创造内容)
-
- [A. 2D 升维 3D (Score Distillation)](#A. 2D 升维 3D (Score Distillation))
- [B. 原生 3D Diffusion](#B. 原生 3D Diffusion)
- [8 3DGS 代码](#8 3DGS 代码)
-
- [训练阶段 vs. 推理阶段](#训练阶段 vs. 推理阶段)
- 与NeRF的关键区别
- 那么每个场景都需要重新训练一边3DGS文件?
- 未来的方向:通用3D生成
-
- [1. 3D Diffusion + 3DGS](#1. 3D Diffusion + 3DGS)
- [2. 大语言模型 + 3DGS](#2. 大语言模型 + 3DGS)
- [方案1. 端到端联合训练 (End-to-End Training)](#方案1. 端到端联合训练 (End-to-End Training))
- [方案2. 两阶段训练 (Two-Stage Training)](#方案2. 两阶段训练 (Two-Stage Training))
- [方案3. 推理时的优化 (Per-Scene Optimization)](#方案3. 推理时的优化 (Per-Scene Optimization))
- [8、NeRF 的推理](#8、NeRF 的推理)
-
- [为什么 NeRF 强调内参?](#为什么 NeRF 强调内参?)
- 总结
- 9、对世界模型的意义
0、我的知识储备
的"目标检测"属于判别式模型(Discriminative Model),而 3DGS 属于显式场景表示(Explicit Representation)。
世界模型 (World Model) 是当前 AI 的圣杯,它试图让 AI 理解物理世界的因果逻辑(比如:杯子掉地上会碎,球拍出去会飞)。
世界模型的痛点(缺乏真实感):
以前的世界模型(如 Sora 或 GameNGen)多是基于 2D 像素或隐空间(Latent Space)生成的。它们生成的视频往往会有"伪影",或者不符合物理透视(比如物体突然变形)。因为它们是在"脑补"像素,而不是真的在算几何。
3DGS 的救场(提供几何约束):
如果把 3DGS 作为世界模型的渲染后端,情况就变了。世界模型负责计算"下一帧球的位置在哪里",然后把这堆 3D 高斯点丢给 3DGS 渲染器。3DGS 利用真实的几何光栅化,保证画出来的画面绝对符合透视原理,没有伪影,且光影极其真实。
1. 传统3D建模:像用"乐高"拼装
原理:拼图游戏
传统方法(如游戏、电影特效)是把物体看作一个空心的外壳。工程师需要手动或用软件生成无数个三角形(Mesh),像贴瓷砖一样把这些三角形拼接起来,覆盖物体的表面。
纹理映射:为了让三角形看起来像木头或金属,需要把一张2D图片(纹理)"贴"在这些三角形上。
局限:如果物体表面非常复杂(比如蓬松的毛发、茂密的树叶),用三角形去硬拼会非常吃力,容易出现"锯齿"或棱角感,不够真实。
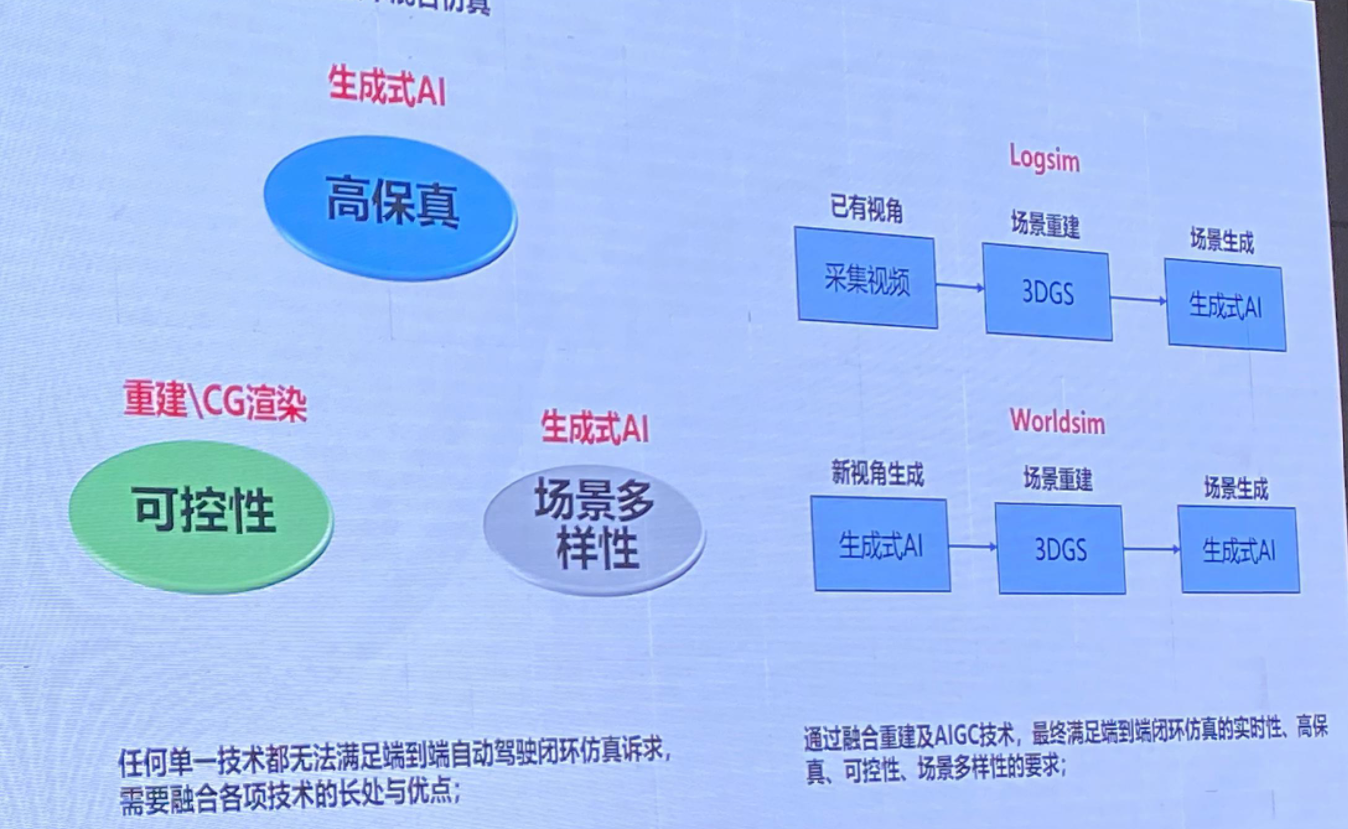
引用以下前领导的ppt

可控生成的核心性能:
1、长视频生成能力,首先是视频的连续性;其次是自然语言理解,能够通过自然语言控制参与者、行为、数量、天气等。支持多尺度、分辨率
2、可控能力,首先是空间多视角,环境结构可控以及参与者行为关系可控。
2. 3D高斯溅射 (3DGS):像用"油墨"喷绘
原理:印象派点彩画
3DGS 完全抛弃了"三角形"和"表面"的概念。它把场景分解成数百万个3D高斯分布(可以理解为半透明的椭球体,即 Splats)。
色彩融合:每一个小椭球体都带有位置、颜色和透明度信息。当从某个角度看过去时,数百万个半透明的"小斑点"会像油墨一样叠加、混合在一起。
超写实细节:因为不需要去拟合物体的几何边界(不需要定义哪里是"边缘"),它直接通过光线的叠加来还原画面。这就像用极高精度的颜料点绘,所以能呈现出近乎照片级的、模糊、半透明或复杂几何的细节(比如玻璃反光、烟雾、草丛)。
核心差异总结
传统建模是几何驱动:先构建物体的形状(骨架),再贴上皮肤(纹理)。
3D高斯溅射是图像驱动:不关心物体到底是什么形状,只关心光线看起来是什么样,通过无数"半透明斑点"的堆叠来欺骗你的眼睛。
3. 什么是 Splat?(画家的"斑点")
你可以把每一个 Splat 想象成画家手里的一块半透明的椭圆形海绵,或者一个模糊的光斑。
-
它不是硬邦邦的石头:它是有体积、有渐变的。
• 它的属性决定了它的样子:
- 位置 & 缩放:决定了这块"海绵"漂在空中哪里,以及是被拉长了还是压扁了。
- 旋转:决定了它是横着放还是竖着放。
◦ 颜色 & 不透明度:决定了这块"海绵"是什么颜色,以及它是完全遮挡视线,还是像薄纱一样透出后面的景色。
每一个splat都由位置、XYZ三轴缩放、旋转角度、颜色、不透明度这5个属性定义。
4. 画家算法(Painter's Algorithm):怎么画?(从后往前叠)
将splat渲染到屏幕上最常见的方法是画家算法(painter's algorithm)。就像画画时先画远处的、再画近处的,把几百万个小椭球按从远到近的顺序排好,一层一层叠上去,实时算出最终画面。
既然 Splat 是半透明的,谁在前谁在后就决定了最终的颜色。计算机采用了一种非常符合直觉的"油画家"策略:
-
排序:计算机先计算几百万个 Splat 距离你眼睛的远近。
-
从远到近:就像画油画先画背景的天空,再画远山,最后画近处的树木。
-
先画最远处的 Splat(比如远处的云)。
◦ 再画中间的 Splat(比如树叶),它会和下面的"云"混合。
-
最后画最近的 Splat(比如眼前的栏杆),它会盖在之前所有颜色的最上面。
-
-
融合:因为每一个 Splat 都是半透明的,后画上去的颜色会自然地和之前的颜色叠加、融合。
-
最终效果:数字版点彩画
当你把几百万个带有不同颜色、不同透明度的"3D高斯斑点(Splats)"按照这个顺序叠在一起时,神奇的事情发生了:
- 单个斑点看起来只是模糊的一团。
• 但当成千上万个斑点层层叠加、相互融合后,它们就"自动"形成了清晰的边缘、复杂的光影和极其真实的纹理。
这就是3D高斯溅射的精髓:不需要去定义物体的"边"在哪里,只需要用无数半透明的"斑点"通过叠加,把光线的效果"凑"出来。
6、多技术混合
引用前领导ppt
7、3D 生成技术
除了 3DGS,目前主流的 3D 生成技术还有 NeRF(神经辐射场) 和基于 Diffusion Model(扩散模型) 的生成技术。
简单来说,NeRF 是 3DGS 的"前辈",而 Diffusion 则是目前 AI 生成领域的"全能王"。
7.1. NeRF (神经辐射场):用"神经网络"记忆场景
在 3DGS 爆火之前,NeRF 是 3D 重建的霸主。它的思路和 3DGS 完全不同:
-
原理 :它不存储具体的点或面,而是训练一个神经网络。你可以把这个网络想象成一个有着超强记忆力的画家,它记住了对于这个场景里的任何一个点,从任何角度看过去应该是什么颜色和透明度。
-
特点 :画质极高,光影效果非常真实,但渲染速度很慢(因为每看一眼都要让神经网络算半天)。
-
怎么工作的 :你给 NeRF 几张某个房间的照片。它不直接存物体形状,而是训练一个神经网络,让它学会:"如果你站在 A 点看 B 点,你看到的光线和颜色应该是什么。"
-
渲染过程:当你想看新视角时,NeRF 会在你和场景之间连一条线,让网络计算这条线上无数个点的颜色和密度,然后像积灰一样把这些颜色累积起来,形成最终的画面。
-
特点 :它的优势是画面极其连贯、平滑,没有 3DGS 那种"斑点感",但因为每一帧都要重新计算庞大的神经网络,所以渲染速度很慢。
7.2. Diffusion (扩散模型):用"AI 推理"创造内容
的 Diffusion 是目前 AIGC(生成式 AI)的核心技术(比如 Midjourney、Stable Diffusion 都是这个原理)。它在 3D 领域的应用主要分两种:
A. 2D 升维 3D (Score Distillation)
这是目前最流行的 AI 生成 3D 的方式(例如 DreamFusion)。
- 原理:它利用预训练好的 2D 绘图 AI(如 Stable Diffusion)作为"老师"。系统先随机生成一个模糊的 3D 物体,然后"老师"从各个角度给它拍照。如果"老师"觉得某张照片不像提示词(比如"一只猫"),就会指导 3D 物体修改形状,直到各个角度拍出来都像猫。
- 特点 :不需要训练数据,只要输入文字就能生成全新的 3D 物体。
B. 原生 3D Diffusion
直接让 AI 在 3D 空间里"去噪"。
- 原理 :就像在 3D 空间里填满噪声点,AI 一点点把这些点擦除,最后留下一个清晰的 3D 模型。代表技术如 Shap-E 或 Point-E。
- 特点:生成速度极快(秒级),但细节丰富度通常不如前几种技术。
8 3DGS 代码
极简版 3DGS 训练推理框架
py
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from typing import Optional, Tuple
import matplotlib.pyplot as plt
class Simple3DGaussianSplatting:
"""
极简版 3D Gaussian Splatting
仅用于教学理解核心原理
"""
def __init__(self, num_gaussians: int = 1000, device: str = "cuda"):
self.device = torch.device(device if torch.cuda.is_available() else "cpu")
self.num_gaussians = num_gaussians
# 1. 初始化高斯椭球的属性
# 位置 (3D坐标)
self.positions = nn.Parameter(torch.randn(num_gaussians, 3, device=self.device) * 0.1)
# 缩放 (对数形式确保为正)
self.scales = nn.Parameter(torch.ones(num_gaussians, 3, device=self.device) * 0.01)
# 旋转 (用四元数表示)
self.rotations = nn.Parameter(torch.randn(num_gaussians, 4, device=self.device))
self.rotations.data = self.rotations.data / self.rotations.data.norm(dim=-1, keepdim=True)
# 颜色 (RGB)
self.colors = nn.Parameter(torch.rand(num_gaussians, 3, device=self.device))
# 不透明度 (用sigmoid确保在[0,1])
self.opacities = nn.Parameter(torch.sigmoid(torch.ones(num_gaussians, 1, device=self.device)))
# 优化器
self.optimizer = optim.Adam([
{'params': [self.positions], 'lr': 0.001},
{'params': [self.scales], 'lr': 0.003},
{'params': [self.rotations], 'lr': 0.003},
{'params': [self.colors], 'lr': 0.01},
{'params': [self.opacities], 'lr': 0.01}
])
def compute_covariance(self, scale: torch.Tensor, rotation: torch.Tensor) -> torch.Tensor:
"""
计算3D高斯的协方差矩阵
公式: Σ = R * S * S^T * R^T
"""
# 将四元数转为旋转矩阵
q = rotation / rotation.norm(dim=-1, keepdim=True)
# 简化版: 用缩放构造对角阵
S = torch.diag_embed(torch.exp(scale)) # 确保缩放为正
R = self.quat_to_rotmat(q) # 四元数转旋转矩阵
# 协方差矩阵 Σ = R * S * S^T * R^T
Sigma = R @ S @ S.transpose(-1, -2) @ R.transpose(-1, -2)
return Sigma
def quat_to_rotmat(self, q: torch.Tensor) -> torch.Tensor:
"""四元数转旋转矩阵 (简化版)"""
w, x, y, z = q.unbind(-1)
rotmat = torch.stack([
1 - 2*y*y - 2*z*z, 2*x*y - 2*w*z, 2*x*z + 2*w*y,
2*x*y + 2*w*z, 1 - 2*x*x - 2*z*z, 2*y*z - 2*w*x,
2*x*z - 2*w*y, 2*y*z + 2*w*x, 1 - 2*x*x - 2*y*y
], dim=-1).view(-1, 3, 3)
return rotmat
def project_to_2d(self, positions_3d: torch.Tensor,
camera_pose: torch.Tensor,
focal_length: float = 500.0) -> Tuple[torch.Tensor, torch.Tensor]:
"""
3D点投影到2D屏幕
简化版投影: 不考虑镜头畸变
"""
# 将世界坐标转为相机坐标
R = camera_pose[:3, :3] # 旋转矩阵
t = camera_pose[:3, 3] # 平移向量
# 坐标变换: p_cam = R * p_world + t
positions_cam = (R @ positions_3d.T).T + t.unsqueeze(0)
# 透视投影: p_screen = focal_length * (p_cam.xy / p_cam.z)
z = positions_cam[:, 2].clamp(min=0.1) # 避免除零
x_proj = focal_length * positions_cam[:, 0] / z
y_proj = focal_length * positions_cam[:, 1] / z
positions_2d = torch.stack([x_proj, y_proj], dim=1)
depths = positions_cam[:, 2] # 用于深度排序
return positions_2d, depths
def render_pixel(self, pixel_coord: torch.Tensor,
positions_2d: torch.Tensor,
colors: torch.Tensor,
opacities: torch.Tensor,
cov_2d: torch.Tensor) -> torch.Tensor:
"""
渲染单个像素的颜色 (Alpha混合)
使用画家算法: 从远到近混合
"""
# 计算像素到每个高斯中心的距离
diff = pixel_coord.unsqueeze(0) - positions_2d
# 2D高斯权重: exp(-0.5 * diff^T * Σ^{-1} * diff)
# 简化: 假设各向同性高斯
weights = torch.exp(-0.5 * (diff ** 2).sum(dim=-1) / 0.01)
weights = weights * opacities.squeeze()
# 按权重对颜色加权平均
weighted_colors = colors * weights.unsqueeze(-1)
# Alpha混合
total_weight = weights.sum().clamp(min=1e-8)
pixel_color = weighted_colors.sum(dim=0) / total_weight
return pixel_color.clamp(0, 1)
def render_image(self, camera_pose: torch.Tensor,
image_size: Tuple[int, int] = (64, 64)) -> torch.Tensor:
"""
渲染整个图像
"""
H, W = image_size
# 1. 3D转2D投影
positions_2d, depths = self.project_to_2d(self.positions, camera_pose)
# 2. 按深度排序 (画家算法: 从远到近)
sorted_indices = torch.argsort(depths, descending=True)
positions_2d = positions_2d[sorted_indices]
colors = self.colors[sorted_indices]
opacities = torch.sigmoid(self.opacities)[sorted_indices]
# 3. 创建画布
image = torch.zeros(H, W, 3, device=self.device)
# 4. 遍历所有像素 (简化版: 实际会用并行计算)
for i in range(H):
for j in range(W):
# 像素坐标 (归一化到[-1, 1])
pixel_coord = torch.tensor([
(j - W/2) / (W/2), # x
(i - H/2) / (H/2) # y
], device=self.device)
# 渲染这个像素
pixel_color = self.render_pixel(pixel_coord, positions_2d,
colors, opacities, None)
image[i, j] = pixel_color
return image
def adaptive_density_control(self, gradients: torch.Tensor, threshold: float = 0.01):
"""
自适应密度控制 (简化版)
根据梯度大小决定是否克隆/删除高斯
"""
# 计算位置梯度的大小
grad_magnitude = gradients.norm(dim=-1)
# 梯度大的地方需要更多高斯 (克隆)
clone_mask = grad_magnitude > threshold * 2
if clone_mask.any():
# 这里应该实现克隆逻辑
pass
# 梯度小的地方可以删除
prune_mask = grad_magnitude < threshold * 0.1
if prune_mask.any():
# 这里应该实现删除逻辑
pass
def train_step(self, target_image: torch.Tensor,
camera_pose: torch.Tensor,
image_size: Tuple[int, int] = (64, 64)):
"""
单步训练
"""
self.optimizer.zero_grad()
# 1. 渲染当前视角
rendered = self.render_image(camera_pose, image_size)
# 2. 计算损失 (L1 + 感知损失简化)
loss_l1 = torch.abs(rendered - target_image).mean()
# 3. 反向传播
loss_l1.backward()
# 4. 自适应控制 (可选)
if hasattr(self.positions, 'grad') and self.positions.grad is not None:
self.adaptive_density_control(self.positions.grad)
# 5. 更新参数
self.optimizer.step()
return loss_l1.item(), rendered
def create_synthetic_scene(num_gaussians: int = 500) -> Tuple[torch.Tensor, torch.Tensor]:
"""
创建合成场景: 一个简单的彩色球体
"""
# 创建球体表面的点
phi = torch.rand(num_gaussians) * 2 * np.pi
theta = torch.arccos(2 * torch.rand(num_gaussians) - 1)
radius = 2.0
x = radius * torch.sin(theta) * torch.cos(phi)
y = radius * torch.sin(theta) * torch.sin(phi)
z = radius * torch.cos(theta)
positions = torch.stack([x, y, z], dim=1)
# 创建彩虹色
colors = torch.zeros(num_gaussians, 3)
colors[:, 0] = (torch.sin(phi) + 1) / 2 # R
colors[:, 1] = (torch.cos(theta) + 1) / 2 # G
colors[:, 2] = (torch.sin(phi + theta) + 1) / 2 # B
return positions, colors
def main():
"""主训练循环"""
print("初始化 3DGS...")
# 创建模型
model = Simple3DGaussianSplatting(num_gaussians=1000)
# 创建目标图像 (简化: 一个简单的彩色球)
image_size = (64, 64)
target_image = torch.zeros(image_size[0], image_size[1], 3)
# 在中心画一个彩色圆
center_h, center_w = image_size[0] // 2, image_size[1] // 2
for i in range(image_size[0]):
for j in range(image_size[1]):
dist = ((i - center_h) ** 2 + (j - center_w) ** 2) ** 0.5
if dist < 20:
target_image[i, j, 0] = 1.0 # 红色
target_image[i, j, 1] = (dist / 20) # 绿色渐变
target_image[i, j, 2] = 0.5 # 蓝色
target_image = target_image.to(model.device)
# 定义相机位姿
camera_pose = torch.eye(4)
camera_pose[2, 3] = 5.0 # 相机在z=5的位置
# 训练循环
num_iterations = 100
print(f"开始训练,共{num_iterations}轮...")
for iteration in range(num_iterations):
loss, rendered = model.train_step(target_image, camera_pose, image_size)
if iteration % 10 == 0:
print(f"Iteration {iteration}: Loss = {loss:.6f}")
# 可视化
if iteration % 30 == 0:
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
axes[0].imshow(target_image.cpu().numpy())
axes[0].set_title("Target Image")
axes[0].axis('off')
axes[1].imshow(rendered.detach().cpu().numpy())
axes[1].set_title(f"Rendered (Iter {iteration})")
axes[1].axis('off')
plt.tight_layout()
plt.show()
print("训练完成!")
# 推理测试
print("\n推理测试: 从新视角渲染...")
# 创建新视角
new_camera_pose = torch.eye(4)
new_camera_pose[0, 3] = 1.0 # 相机右移
new_camera_pose[2, 3] = 5.0
with torch.no_grad():
new_view = model.render_image(new_camera_pose, image_size)
plt.figure(figsize=(6, 6))
plt.imshow(new_view.cpu().numpy())
plt.title("Novel View Synthesis")
plt.axis('off')
plt.show()
return model
if __name__ == "__main__":
model = main()3D 高斯表示
# 每个高斯椭球有5个属性
self.positions # 3D位置 (x, y, z)
self.scales # 缩放 (sx, sy, sz)
self.rotations # 旋转 (四元数表示)
self.colors # 颜色 (r, g, b)
self.opacities # 不透明度小结:把相机pose+图像作为输入,3DGS根据pose调整splats,生成图像和目标图像对比。以后改变pose就可以生成不同的图像,不需要把图像送入3DGS。
训练阶段 vs. 推理阶段
# 训练阶段: 需要图片 + pose
train_input = {
"images": all_images, # 多张图片
"poses": all_camera_poses, # 对应的相机位姿
"focal_length": focal # 相机参数
}
# 输出: 训练好的3D高斯椭球参数文件
# 推理阶段: 只需要pose
infer_input = {
"pose": new_camera_pose, # 新的相机位姿
"focal_length": focal # 相机参数
}
# 输出: 新视角的渲染图片-
训练阶段:从图片到3D模型
输入: [图片1 + 位姿1, 图片2 + 位姿2, 图片3 + 位姿3, ...]
↓
3DGS优化器调整splats参数
↓
输出: 3D高斯点云文件 (.ply)
(包含位置、颜色、不透明度等)
关键:训练时,3DGS是在"观察"这些图片,从中"学习"场景的3D结构。一旦训练完成,原始的图片就不再需要了。
-
推理阶段:从3D模型到新视角
输入: 训练好的splats + 新相机位姿
↓
3DGS渲染器投影、混合
↓
输出: 新视角图片
关键:推理时,3DGS已经"记住"了场景的3D结构,只需要你告诉它"从哪个角度看",它就能生成对应的2D图片
与NeRF的关键区别
3DGS 训练输出3D高斯点云文件 (显式几何),而NeRF是神经网络权重文件 (隐式函数)
推理计算,3DGS光栅化投影 (快),神经网络前向传播 (慢)
那么每个场景都需要重新训练一边3DGS文件?
每个新场景都需要单独训练一个 3DGS 模型。
这就是目前 3DGS 的核心限制之一:它是场景特定的(scene-specific),而不是通用生成模型。
3DGS 的训练本质是"重建",不是"学习"
| 模型类型 | 输入 | 输出 | 可泛化性 |
|---|---|---|---|
| 3DGS | 某个场景的多张照片 | 这个场景的3D点云 | ❌ 零泛化(只能重现这个场景) |
| NeRF | 某个场景的多张照片 | 这个场景的神经场 | ❌ 零泛化(只能重现这个场景) |
| Diffusion | 海量图片+文字 | 生成新图片的规则 | ✅ 强泛化(能画没见过的) |
| Sora | 海量视频+文字 | 生成新视频的规则 | ✅ 强泛化(能生成没见过的) |
未来的方向:通用3D生成
学术界正在努力让 3DGS 也能"学习":
1. 3D Diffusion + 3DGS
python
# 用3D扩散模型生成初始点云
initial_points = point_e_diffusion(prompt="a cat")
# 用3DGS精细化
refined_scene = 3dgs_refine(initial_points)2. 大语言模型 + 3DGS
python
# LLM理解场景描述
scene_description = llm_understand("阳光明媚的客厅")
# 生成对应的3DGS参数
scene_params = llm_to_3dgs(scene_description)
# 渲染
image = render_3dgs(scene_params)方案1. 端到端联合训练 (End-to-End Training)
这是最"重"的方案,也是目前研究的热点。
- 训练对象 :大语言模型(LLM)的参数 和 3DGS 的 splats 参数 同时 进行优化。
- 训练数据 :
(文本描述, 对应的多视角图像)。 - 过程 :
- LLM 看到文本(如"一个红色的沙发"),输出一组初始的 3DGS 参数(位置、颜色等)。
- 3DGS 渲染器根据这些参数生成一张图片。
- 计算生成图片与目标图片的差距(Loss)。
- 反向传播:误差不仅用来修正 3DGS 的点,还会传回给 LLM,教它"下次看到'红色'应该输出什么样的 RGB 值"。
- 结果:训练完成后,LLM 学会了"文字 -> 3D 结构"的映射,而 3DGS 学会了"如何精细表达这个结构"。
方案2. 两阶段训练 (Two-Stage Training)
这是目前更实用的方案,把任务拆开。
- 第一阶段(LLM 训练):训练 LLM 理解 3D 布局。例如,输入"客厅",LLM 输出一个粗略的"边界框"或"点云骨架"。
- 第二阶段(3DGS 训练) :
- 输入:LLM 给出的粗略结构 + 几张参考图片(或者 Diffusion 生成的图)。
- 过程:3DGS 进行常规的"重建训练",把粗略结构细化成高保真的画面。
- 注意:这里的 3DGS 训练是必须的,因为 LLM 只能给个大概,细节(纹理、光照)还得靠 3DGS 去拟合。
方案3. 推理时的优化 (Per-Scene Optimization)
- 预训练:LLM 已经在海量数据上训练好,学会了通用的 3D 知识。
- 使用流程 :
- 你输入新文本。
- LLM 瞬间生成一组"初始 3DGS 参数"。
- 关键步骤 :系统以这组参数为起点,进行一个非常短暂的 3DGS 训练(可能只需几分钟,甚至几秒钟)。
- 训练完成后,得到最终的 3DGS 文件,用于实时渲染。
8、NeRF 的推理
py
def render_nerf(
model: nn.Module, # 训练好的 NeRF 神经网络
camera_pose: torch.Tensor, # [4, 4] 相机外参矩阵
focal_length: float, # 焦距
image_size: int # 图片分辨率 (e.g., 800x800)
):
# 1. 生成光线 (Rays)
# 输入:相机位姿 + 焦距 -> 输出:每条光线的起点和方向
rays_o, rays_d = generate_rays(camera_pose, focal_length, image_size)
# 2. 沿着光线采样点
# 输入:光线方向 -> 输出:3D坐标 (batch, num_samples, 3)
points_3d = sample_points_along_rays(rays_o, rays_d)
# 3. 准备 5D 输入
# 输入:3D坐标 + 观察方向 -> 拼接成 (batch, num_samples, 5)
nerf_input = torch.cat([points_3d, rays_d], dim=-1)
# 4. 核心推理:喂给神经网络
# 输入:5D向量 -> 输出:RGB + Density
raw_output = model(nerf_input)
# 5. 体渲染积分
# 输入:Raw Output -> 输出:像素颜色 (batch, 3)
pixel_colors = volume_render(raw_output)
return pixel_colors对比:3DGS vs. NeRF 推理
| 特性 | 3DGS (Gaussian Splatting) | NeRF (Neural Radiance Fields) |
|---|---|---|
| 模型形态 | 显式点云文件 (.ply) | 隐式神经网络权重 (.pth) |
| 推理输入 | 相机位姿 (Pose) | 相机位姿 (Pose) + 光线方向 (Ray Direction) |
| 核心操作 | 光栅化 (Rasterization) 把 3D 椭球投影到 2D 屏幕 | 光线步进 (Ray Marching) 沿着光线问神经网络:"这里是什么?" |
| 计算量 | 主要是投影和 α \alpha α 混合 (非常适合 GPU 并行) | 每条光线都要跑很多次神经网络前向传播 (计算密集,较慢) |
| 速度 | 实时 (100+ FPS) | 较慢 (1-10 FPS,取决于优化) |
为什么 NeRF 强调内参?
NeRF:通常把内参作为光线生成函数的输入。因为 NeRF 研究中有很多多尺度、多相机的数据集(如 LLFF),内参变化很大,所以必须显式处理。
3DGS:专注于单场景重建,假设相机硬件不变,所以把内参"内化"了。
总结
- 3DGS 推理:拿着相机位姿,直接把 3D 高斯"拍扁"到 2D 屏幕上(像拍照片一样快)。
- NeRF 推理:拿着相机位姿,沿着视线去"问"神经网络无数次"前面那个点是什么颜色的?",然后加起来(像做数学积分一样慢)。
9、对世界模型的意义
Spark 2.0 的发布标志着 3D 内容从"本地高端设备独享"迈向了"云端普惠分发"的时代。它的核心意义在于打破了设备算力的物理围墙 ,通过流式传输和智能降维技术,让手机和 VR 也能流畅运行亿级点云的超大场景。这不仅解决了 3D 在 Web 端的落地难题,更为李飞飞团队构建的"世界模型"提供了至关重要的高保真视觉交互界面。
这项技术最硬核的价值在于它解决了"数据量大"与"设备性能差"之间的矛盾。它通过三大创新,让 3D 体验变得像刷短视频一样轻快:
- 像视频一样流式加载 :采用自研的
.RAD格式和渐进式传输。你不需要等几个 G 的数据下完,它优先加载粗糙轮廓,再根据你的视线方向动态加载高清细节。这种"走到哪、加载哪"的策略极大降低了带宽压力 。 - 智能视觉降维(LoD):利用连续细节层次技术,近处的物体用高精度渲染,远处的则自动简化。这就像人眼盯着近处看时,远处自然模糊一样,既省算力又保证视觉体验平滑无跳变 。
- 显存"乾坤大挪移":引入 GPU 虚拟内存机制,把显存当作硬盘用。即使场景有上亿个点,它也能通过动态置换数据块,让仅有有限显存的手机流畅运行,不再依赖昂贵的显卡 。
对世界模型的意义:从"可计算"到"可感知"
"世界模型"通常是指 AI 对物理世界的理解能力(类似于大脑的思维),而 Spark 2.0 则是这个大脑的"眼睛"和"输出口"。
- 世界模型的终极展示屏:世界模型生成的是数据和逻辑,而 Spark 2.0 负责把这些抽象数据变成人眼能直观感知的 3D 世界。没有它,世界模型生成的内容只能停留在代码层面,无法被人类直观交互和验证 。
- 具身智能的训练场:对于机器人或自动驾驶的 AI 来说,它们需要在拟真的环境里试错。Spark 2.0 能渲染出照片级真实的物理场景,为 AI 提供了一个低成本、可交互的"虚拟练兵场",帮助 AI 更好地理解空间关系和物理法则 。
- 空间智能的基石:李飞飞团队致力于让 AI 具备"空间智能"。Spark 2.0 的开源降低了 3D 内容的创作和分发门槛,这意味着未来会有更多高质量的 3D 数据产生,而这些数据正是喂养世界模型成长的最佳养料 。