Pose estimation-guided CNN for tea bud detection and plucking point identification
研究背景与痛点
任务目标:为智能采茶机器人解决(茶芽检测+拔茶点识别)问题
核心挑战:
目标背景高度相似、目标形态不一、严重遮挡/密集分布
核心方法:是把"拔芽茶点定位"重新定义成了"假体贴算问题",并设计了两阶段的流水线任务
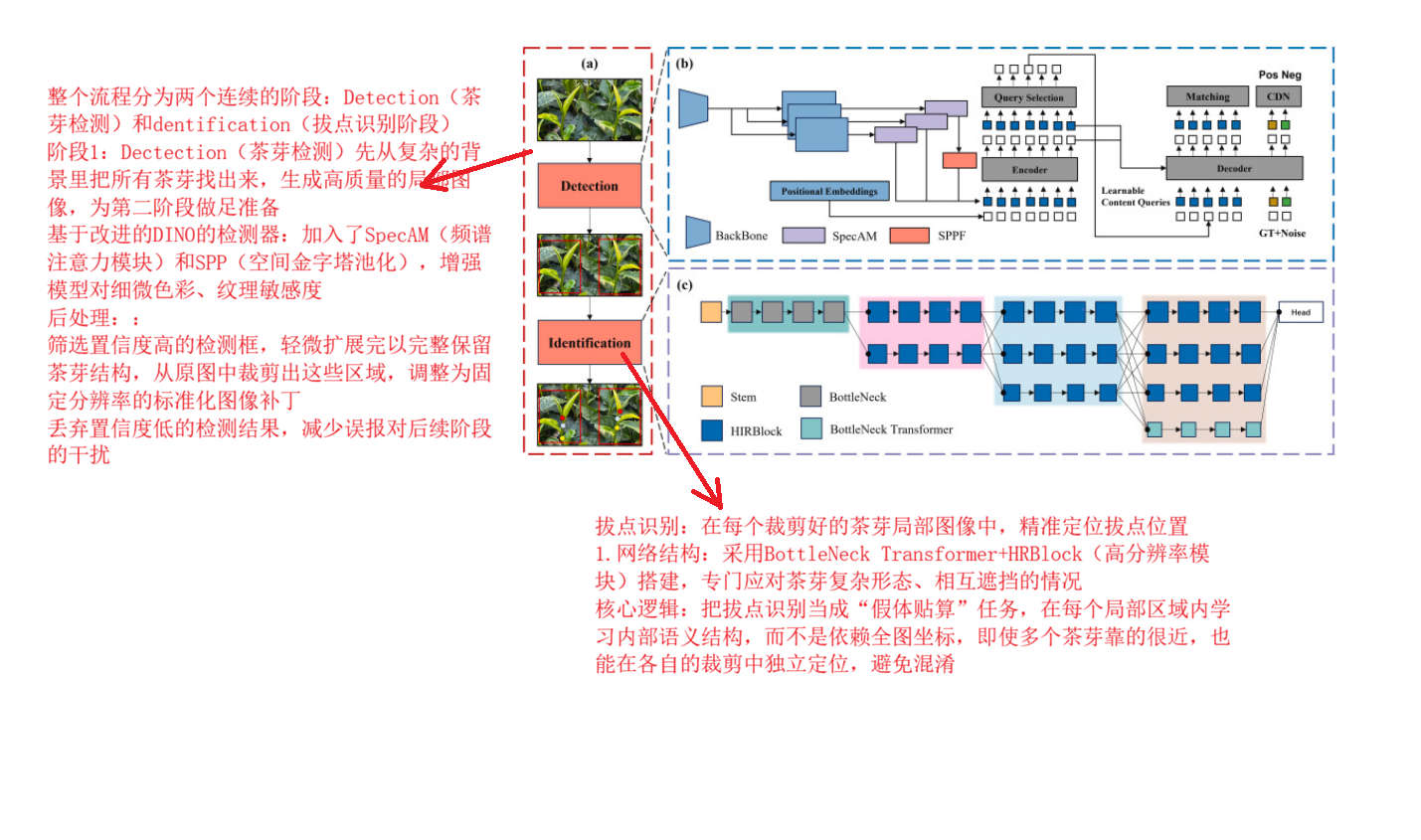
第一阶段:茶芽检测---基于DINO检测器,加入光谱注意力模块+多尺度特征融合(解决问题:增强模型对细微色彩、纹理对比度的敏感度,先把茶芽从复杂的背景里"揪出来")
第二阶段:拔芽点识别:带空间坐标编码的高分辨率网络--在茶芽被遮挡、簇聚的情况下,依然能精准定位到采摘点,解决遮挡和密集目标定位的难题
方法优势:
两阶段是耦合的:检测阶段的输出直接喂给识别阶段,能利用前一阶段的上下文信息,提升整体的鲁棒性
针对茶园场景做了定制优化:不是通用的目标检测模型的套用,而是专门解决了植物的"遮挡、相似、形态多变"三大痛点
借鉴人体姿态估计的思路,采用"先检测茶芽、再识别拔点"的两级流水线
1.第一阶段为第二阶段提供精准的的茶芽区域定位,提升模型的模块化程度与复杂场景的适应性,更适配真实茶园环境
2.优化DINO检测器,增强:
将频谱注意力模块和空间金字塔池化融入DINO的表征学习范式,在不增加计算成本/内存开销的前提下,提升茶芽检测的稳定性和抗干扰能力
3.高分辨率+瓶颈Transformer应对复杂场景,采用高分率的模块和瓶颈Transformer结构,让模型更好的地处理茶芽的复杂形态、相互遮挡问题
核心思想:从人类姿态估计(HPE)中找灵感
这篇论文的核心思路,是把茶芽检测+拔点识别任务,类比成多人人体姿态估计(HPE)问题:
每个茶芽就像一个人,而它的拔点就像人的"关键点"
借鉴HPE中(自上而下)的范式,设计了一个两阶段的流水线,解决茶园里茶芽密集、遮挡、形态多变的难题
为什么不是自下而上(HPE)方法:直接检测所有关键点,在分组,容易在茶芽密集、重叠时混淆关键点归属,姿态相似、关键点靠近时,容易出现分配错误
自上而下的HPE方法:先检测目标,再在目标框内估计关键点,能确保"一个茶芽对应一组拔点",对应不混乱,可以减少背景干扰
PENet两阶段工作流程图