一、前言:你的 Redis 内存都去哪了?
你是否遇到过:
INFO MEMORY显示used_memory: 2GB,但top命令显示 RSS(常驻内存)高达 5GB?- 设置了
maxmemory 4GB,但服务在 3.5GB 就开始频繁驱逐 Key? - 监控告警"内存使用率 95%",却找不到大 Key?
✅ 真相 :
Redis 的内存 ≠ 你的数据大小 !它由数据内存 + 元数据 + 缓冲区 + 碎片共同构成。
本文将带你:
- 拆解 Redis 内存的五大组成部分
- 详解 8 个核心内存配置参数
- 提供 5 大生产级内存优化策略
二、Redis 内存全景图:五大组成部分
通过 INFO MEMORY 命令,我们可以看到内存的详细构成:
| 组成部分 | 配置/命令 | 说明 |
|---|---|---|
| 1. 数据内存 | used_memory |
存储键值对的实际数据(含对象头、指针等) |
| 2. 内存碎片 | mem_fragmentation_ratio |
分配器(如 jemalloc)造成的未利用空间 |
| 3. 客户端缓冲区 | client-output-buffer-limit |
存储客户端请求/响应的临时缓冲区 |
| 4. 复制积压缓冲区 | repl-backlog-size |
主从复制用的环形缓冲区(默认 1MB) |
| 5. AOF 缓冲区 | - | 执行 AOF 持久化时的写入缓冲区 |
💡 关键指标 :
mem_fragmentation_ratio = used_memory_rss / used_memory
- 理想值:1.0 ~ 1.5
- > 1.5:内存碎片严重,需整理
- < 1.0:可能使用了 Swap(危险!)
三、核心内存配置参数详解
3.1 maxmemory:内存上限(必设!)
# redis.conf
maxmemory 4gb作用 :当内存达到此值,触发内存淘汰策略 。
建议 :设置为物理内存的 70%~80%,预留空间给操作系统和碎片。
3.2 maxmemory-policy:淘汰策略(关键!)
| 策略 | 说明 | 适用场景 |
|---|---|---|
noeviction |
不淘汰,写操作返回错误 | 缓存非核心数据 |
allkeys-lru |
所有 Key 中 LRU 淘汰 | 通用缓存(推荐) |
volatile-lru |
仅带过期时间的 Key 中 LRU 淘汰 | 混合存储(缓存+持久) |
allkeys-random |
随机淘汰 | 数据访问均匀 |
volatile-ttl |
优先淘汰 TTL 短的 Key | 会话缓存 |
⚠️ 注意 :
allkeys-*会淘汰任意 Key,volatile-*只淘汰有EXPIRE的 Key。
3.3 紧凑编码参数(节省 3~10 倍内存!)
Redis 对小对象使用更省内存的编码:
# Hash 使用 ziplist(而非 hashtable)
hash-max-ziplist-entries 512 # 元素数 ≤ 512
hash-max-ziplist-value 64 # 单个值 ≤ 64 字节
# List 使用 ziplist(而非 linkedlist)
list-max-ziplist-size -2 # 节点大小 ≤ 8KB
# Set 使用 intset(而非 hashtable)
set-max-intset-entries 512 # 整数元素 ≤ 512
# ZSet 使用 ziplist(而非 skiplist)
zset-max-ziplist-entries 128
zset-max-ziplist-value 64原理 :
ziplist和intset是连续内存结构,比指针链表更省空间。
3.4 客户端缓冲区限制
# 普通客户端(防 OOM)
client-output-buffer-limit normal 0 0 0
# 从库客户端(防主库内存溢出)
client-output-buffer-limit replica 256mb 64mb 60
# Pub/Sub 客户端
client-output-buffer-limit pubsub 32mb 8mb 60格式 :
hard limitsoft limitsoft seconds例如:
replica 256mb 64mb 60表示:
- 瞬时超过 256MB 断开连接
- 持续 60 秒超过 64MB 断开连接
3.5 复制积压缓冲区
repl-backlog-size 128mb # 默认 1MB,集群建议 ≥ 100MB作用:从库断线重连时,从此缓冲区同步增量数据,避免全量同步。
3.6 内存碎片整理(Redis 4.0+)
# 启用自动碎片整理
activedefrag yes
# 触发条件
active-defrag-ignore-bytes 100mb # 碎片 ≥ 100MB
active-defrag-threshold-lower 10 # 碎片率 ≥ 1.1
active-defrag-threshold-upper 100 # 碎片率 ≥ 2.0效果:将碎片率从 1.8 降至 1.1,释放大量内存。
四、生产级内存优化五大策略
4.1 策略 1:选用紧凑数据结构
案例:存储用户信息
bash
# 方案1:多个 String(浪费!)
SET user:1001:name "Alice"
SET user:1001:age "25"
SET user:1001:email "a@b.com"
# 方案2:单个 Hash(推荐!)
HSET user:1001 name "Alice" age "25" email "a@b.com"效果 :内存占用减少 50%+(共享 Key 名 + 紧凑编码)。
4.2 策略 2:合理设计 Key 和 Value
- Key 尽量短 :
u:1001优于user_profile_1001 - Value 避免大对象:单个 Value ≤ 10KB
- 使用数字代替字符串 :
status:1优于status:active
4.3 策略 3:设置合理的过期时间
bash
# 为缓存设置 TTL
SETEX session:abc123 1800 "user_data"好处:
- 自动清理无用数据
- 使
volatile-*淘汰策略生效
4.4 策略 4:监控并治理 BigKey
bash
# 扫描 BigKey
redis-cli --bigkeys
# 示例输出
[00.00%] Biggest string found 'big:config' has 1048576 bytes
[00.00%] Biggest hash found 'user:logs:1001' has 50000 fields处理:拆分 BigKey 或移至冷存储。
4.5 策略 5:启用自动碎片整理
# 生产环境推荐配置
activedefrag yes
active-defrag-cycle-min 5 # CPU 最小占用 5%
active-defrag-cycle-max 75 # CPU 最大占用 75%注意:整理过程会消耗 CPU,建议在业务低峰期进行。
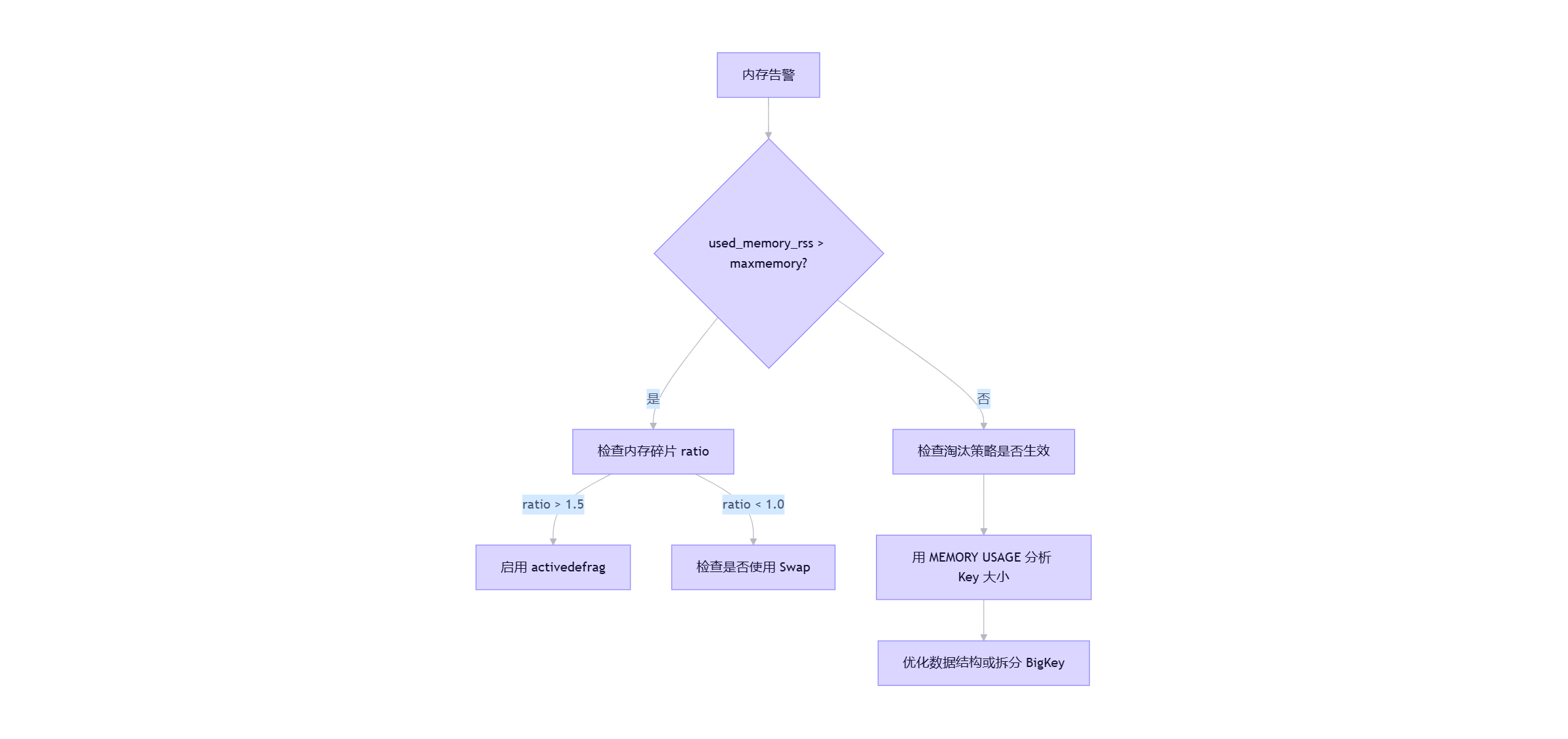
五、内存问题诊断流程图
六、结语
感谢您的阅读!如果你有任何疑问或想要分享的经验,请在评论区留言交流!