|----------------------------------------------|----------------------------------------------------------------------|
| 欢迎各位同学关注我哦~ 在这个 AI 喧嚣的时代 不忘初心,戒骄戒躁,认真沉淀 |  |
|
在前两篇文章中,我们从整体结构到设计动机,逐步拆解了SDS的底层实现与它抛弃C字符串的根本原因。我们知道了SDS用 len 和 alloc 两个字段实现了O(1)获取长度和二进制安全,但留了一个关键问题没有展开:**当字符串不断追加、缩短、再追加时,SDS 如何在性能和内存之间取得平衡?**答案就藏在 sdsMakeRoomFor 的扩容策略和SDS独特的惰性释放机制中。
一、为什么SDS需要专门的扩容策略?
C字符串的追加操作(strcat)要求调用者自己保证目标缓冲区有足够空间,否则缓冲区溢出。更关键的是,C字符串每次增长都需要 realloc,而 realloc 是一个昂贵的系统调用:
- 可能触发
memcpy拷贝整块数据到新地址 - 可能触发操作系统内核的内存映射调整
- 在高并发下,
malloc/free频繁调用导致内存碎片
Redis每秒执行数万次字符串操作(协议构建、AOF追加、日志输出等),如果每次追加都 realloc,性能不可接受。
SDS的解决方案是两套互补策略:
- 空间预分配(Space Pre-allocation):追加时多分配空间,用内存换时间
- 惰性释放(Lazy Free):缩短时不立即归还内存,留作未来复用
二、sdsMakeRoomFor
扩容核心函数 。所有SDS追加操作的底层都经过 sdsMakeRoomFor:
sdscatlen → sdsMakeRoomFor
sdscatvprintf → sdscat → sdscatlen → sdsMakeRoomFor
sdscatfmt → sdsMakeRoomFor(逐字符调用)
sdsgrowzero → sdsMakeRoomFor2.1 源码逐行分析
c
// sds.c:204-246
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
// ===== 第一关:空间足够,直接返回 =====
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s - sdsHdrSize(oldtype);
newlen = (len + addlen);
// ===== 第二关:预分配策略 =====
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2; // 翻倍
else
newlen += SDS_MAX_PREALLOC; // 加1MB
// ===== 第三关:类型重新选择 =====
type = sdsReqType(newlen);
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
// ===== 第四关:决定realloc还是malloc =====
if (oldtype == type) {
// 类型不变,header大小不变,原地扩容
newsh = s_realloc(sh, hdrlen + newlen + 1);
if (newsh == NULL) return NULL;
s = (char*)newsh + hdrlen;
} else {
// 类型变了,header大小变了,必须新分配
newsh = s_malloc(hdrlen + newlen + 1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh + hdrlen, s, len + 1);
s_free(sh);
s = (char*)newsh + hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, newlen);
return s;
}2.2 四个决策关卡
第一关:空间是否足够?
c
if (avail >= addlen) return s;avail = alloc - len,即 buf 中已分配但未使用的空间。如果剩余空间已经够放 addlen 字节,直接返回,不做任何操作。
这是最常见的情况------得益于预分配,大部分追加操作在第一关就返回了。
第二关:预分配多少?
c
// sds.h:36
#define SDS_MAX_PREALLOC (1024*1024) // 1MB
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2; // 规则A:翻倍
else
newlen += SDS_MAX_PREALLOC; // 规则B:加1MB规则A(翻倍):当目标长度<1MB时,分配目标长度的2倍。
规则B(加1MB):当目标长度>=1MB时,在目标长度基础上再加1MB。
为什么不一直翻倍?因为当字符串已经很大时,翻倍意味着浪费大量内存。一个2MB的字符串追加1字节,如果翻倍就会分配4MB,浪费近2MB。而加1MB只浪费1MB。
1MB 分界点的选择:这是一个经验值。Antirez认为在Redis的典型场景中,超过1MB的字符串已经属于"大字符串",不应再激进地翻倍。
第三关:类型是否需要升级?
c
type = sdsReqType(newlen);预分配后 newlen 可能远超当前类型能表示的最大值,此时必须升级到更大的头部类型。
例如:当前 sdshdr8(alloc最大255),预分配后 newlen = 512,必须升级为 sdshdr16。
sdshdr5 永远不被用作扩容目标,因为它没有 alloc 字段,无法记录预分配的空间。
第四关:原地扩容还是重新分配?
c
if (oldtype == type) {
newsh = s_realloc(sh, hdrlen + newlen + 1);
} else {
newsh = s_malloc(hdrlen + newlen + 1);
memcpy((char*)newsh + hdrlen, s, len + 1);
s_free(sh);
}类型不变时用 realloc:
- header大小不变,
sds指针偏移量不变 realloc可能原地扩展(不需要拷贝数据)- 即使需要拷贝,也由
realloc内部完成
类型变化时必须 malloc + memcpy + free:
- header大小变了,
sds指针相对于内存块起始的偏移量也变了 realloc不会帮你移动buf的位置- 必须新分配一块内存,手动拷贝字符串内容
三、预分配策略的数学分析
3.1 翻倍策略的均摊复杂度
假设我们从一个空字符串开始,每次追加1字节,连续追加N次:
无预分配(每次realloc):N次realloc,总拷贝量= 1 + 2 + 3 + ... + N = O(N²)
翻倍预分配:
第1次追加: len=1, alloc=2 (翻倍)
第2次追加: len=2, alloc=4 (翻倍,无需realloc)
第3次追加: len=3, alloc=4 (无需realloc)
第4次追加: len=4, alloc=8 (翻倍)
...
第k次realloc发生在len = 2^n 时,分配2^(n+1)realloc次数 = log₂(N),总拷贝量= 2 + 4 + 8 + ... + N ≈ 2N = O(N)
均摊到每次追加操作的成本= O(1),这就是翻倍策略的核心价值。
3.2 内存浪费率分析
翻倍策略在最坏情况下,alloc = 2 * len,浪费率=50%。但实际上 alloc 还包含了之前append累积的空间,所以平均浪费率远低于50%。
加1MB策略的浪费率随字符串长度递减:
| len | alloc | 浪费 | 浪费率 |
|---|---|---|---|
| 1MB | 2MB | 1MB | 50% |
| 2MB | 3MB | 1MB | 33% |
| 5MB | 6MB | 1MB | 17% |
| 10MB | 11MB | 1MB | 9% |
| 100MB | 101MB | 1MB | 1% |
字符串越大,1MB的额外分配越微不足道。
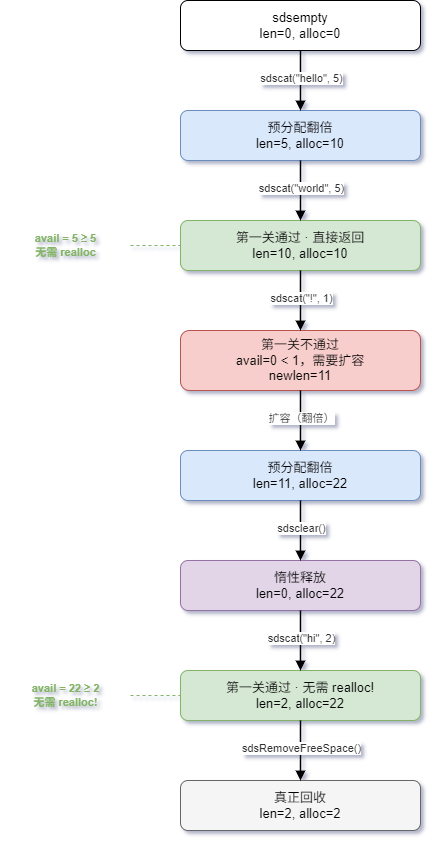
3.3 完整扩容过程示例
示例 1:短字符串连续追加
初始: s = sdsempty() len=0, alloc=0, hdr=sdshdr8(3B)
追加 "hello" (5B): len=5, alloc=10, hdr=sdshdr8(3B)
→ newlen = 0+5 = 5 < 1MB → 翻倍 → 10
→ sdsReqType(10) = SDS_TYPE_8,类型不变 → realloc
追加 " world" (6B): len=11, alloc=22, hdr=sdshdr8(3B)
→ avail = 10-5 = 5 < 6,需要扩容
→ newlen = 5+6 = 11 < 1MB → 翻倍 → 22
→ 类型不变 → realloc
追加 "!" (1B): len=12, alloc=22, hdr=sdshdr8(3B)
→ avail = 22-11 = 11 >= 1 → 第一关直接返回!无需任何系统调用示例 2:大字符串追加触发类型升级
初始: s = sdsnewlen(buf, 200) len=200, alloc=200, hdr=sdshdr8(3B)
追加 100 字节:
→ avail = 0 < 100,需要扩容
→ newlen = 200+100 = 300 < 1MB → 翻倍 → 600
→ sdsReqType(600) = SDS_TYPE_16,从TYPE_8升级
→ 类型变了 → malloc(5+600+1=606) + memcpy + free
→ 新: len=200, alloc=600, hdr=sdshdr16(5B)示例 3:超过1MB的大字符串
初始: s含1MB数据 len=1MB, alloc=1MB, hdr=sdshdr32(9B)
追加100字节:
→ newlen = len+addlen = 1MB+100 = 1048676
→ 1048676 >= 1MB(1048576),触发规则B:加1MB
→ newlen = 1048676 + 1048576 = 2097252 (约2MB+100)
→ alloc = 2097252, 浪费约1MB四、惰性释放机制
4.1 sdsclear
清空但不释放
c
// sds.c:193-196
void sdsclear(sds s) {
sdssetlen(s, 0);
s[0] = '\0';
// alloc 不变,内存不归还
}清空后,buf 中的旧数据仍然存在,但 len=0,新写入会覆盖。下次追加时,sdsMakeRoomFor 发现 avail = alloc - 0 = alloc > 0,在第一关就返回。
4.2 sdstrim
截断但不释放
c
// sds.c:700-713
sds sdstrim(sds s, const char *cset) {
// ... 计算新长度 ...
if (s != sp) memmove(s, sp, len);
s[len] = '\0';
sdssetlen(s, len);
return s; // alloc不变,不归还多余空间
}4.3 sdsrange
截取但不释放
c
// sds.c:731-757
void sdsrange(sds s, ssize_t start, ssize_t end) {
// ... 计算新长度 ...
if (start && newlen) memmove(s, s+start, newlen);
s[newlen] = 0;
sdssetlen(s, newlen);
// alloc不变,不归还多余空间
}4.4 为什么不立即释放?
场景 :Redis的客户端 querybuf 在处理完一个命令后,通常会清空缓冲区等待下一个命令:
c
// networking.c ------ 命令处理完毕后
sdsclear(c->querybuf);如果立即 realloc 缩小,下一个命令到来时又要 realloc 扩大------一来一回两次系统调用,而数据量和之前差不多。
惰性释放的逻辑:
- 清空时只改
len,不改alloc,不调用realloc→ 零系统调用 - 下次追加时,
avail > 0,大概率在sdsMakeRoomFor第一关就返回 → 零系统调用 - 只有当新数据量远超
alloc时才触发扩容 → 极少系统调用
五、空间回收
sdsRemoveFreeSpace,惰性释放保留了空间,但有时需要真正回收。sdsRemoveFreeSpace 将 alloc 缩小到与 len 相等,释放所有空闲空间。
5.1 源码分析
c
// sds.c:255-286
sds sdsRemoveFreeSpace(sds s) {
void *sh, *newsh;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen, oldhdrlen = sdsHdrSize(oldtype);
size_t len = sdslen(s);
sh = (char*)s - oldhdrlen;
type = sdsReqType(len); // 根据当前len重新选择最紧凑的类型
hdrlen = sdsHdrSize(type);
if (oldtype == type || type > SDS_TYPE_8) {
// 情况1: 类型不变 或 新类型>=TYPE_16
// 使用realloc,让分配器决定是否原地处理
newsh = s_realloc(sh, oldhdrlen + len + 1);
if (newsh == NULL) return NULL;
s = (char*)newsh + oldhdrlen;
} else {
// 情况2: 降级到TYPE_5或TYPE_8
// header很小,直接新分配更简单高效
newsh = s_malloc(hdrlen + len + 1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh + hdrlen, s, len + 1);
s_free(sh);
s = (char*)newsh + hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, len); // alloc == len,零空闲
return s;
}5.2 为什么类型变小时不能 realloc?
回收前 (sdshdr32, header=9B):
┌─────────────┬──────────────────┬────┐
│ header(9B) │ "hello"(5B) │ \0 │
└─────────────┴──────────────────┴────┘
^ ^
sh s = sh + 9
回收后 (sdshdr8, header=3B):
┌───────┬──────────────────┬────┐
│ hdr(3)│ "hello"(5B) │ \0 │
└───────┴──────────────────┴────┘
^ ^
sh s = sh + 3header从9字节缩小为3字节,buf 需要向前移动6字节。但 realloc 不关心你数据内部的布局,它只负责调整整块内存的大小------不会帮你把 buf 的内容往前搬。
所以必须:malloc 新块 → memcpy 内容 → free 旧块。
5.3 为什么 type > SDS_TYPE_8 时可以用realloc?
当 type > SDS_TYPE_8(即新类型是TYPE_16/32/64),说明 len 不小,header只会变大或不变。header变大时,realloc 扩大内存块,buf 相对于 sh 的偏移量不变(还是 oldhdrlen),所以 s 指针不需要调整,数据也不需要移动。
5.4 Redis何时调用sdsRemoveFreeSpace?
sdsRemoveFreeSpace 不是常规操作,只在特定场景下调用:
c
// server.c:865 ------ 回收客户端输入缓冲区的空闲空间
if (sdsavail(c->querybuf) > 1024*4) {
c->querybuf = sdsRemoveFreeSpace(c->querybuf);
}当客户端输入缓冲区的空闲空间超过4KB时,回收空闲空间避免内存浪费。
六、不同API的扩容行为对比
6.1 sdscatlen
一次性预分配
c
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
s = sdsMakeRoomFor(s, len); // 一次性确保 len 字节空间
memcpy(s + curlen, t, len);
sdssetlen(s, curlen + len);
s[curlen + len] = '\0';
return s;
}特点 :一次性调用 sdsMakeRoomFor,预分配的空间可以覆盖当前追加需求。后续小追加可能复用预分配空间。
6.2 sdscatfmt
逐字符按需扩容
c
sds sdscatfmt(sds s, char const *fmt, ...) {
while(*f) {
if (sdsavail(s) == 0) {
s = sdsMakeRoomFor(s, 1); // 每次只确保1字节
}
// ... 写入1字节或处理格式符 ...
}
}特点 :每次循环只确保1字节可用空间。看起来效率低,但 sdsMakeRoomFor 的翻倍策略保证了实际扩容次数很少。
对于格式符 %s/%S,会提前计算所需空间:
c
case 's':
case 'S':
l = (next == 's') ? strlen(str) : sdslen(str);
if (sdsavail(s) < l) {
s = sdsMakeRoomFor(s, l); // 一次性确保足够空间
}6.3 sdscatvprintf
栈缓冲区 + 翻倍重试
c
sds sdscatvprintf(sds s, const char *fmt, va_list ap) {
char staticbuf[1024], *buf = staticbuf;
size_t buflen = strlen(fmt) * 2;
if (buflen > sizeof(staticbuf)) {
buf = s_malloc(buflen);
} else {
buflen = sizeof(staticbuf); // 使用1024字节栈缓冲区
}
while(1) {
buf[buflen-2] = '\0';
vsnprintf(buf, buflen, fmt, cpy);
if (buf[buflen-2] != '\0') { // 检查是否截断
buflen *= 2; // 翻倍重试
buf = s_malloc(buflen);
continue;
}
break;
}
t = sdscat(s, buf); // 最终用sdscatlen追加到 SDS
if (buf != staticbuf) s_free(buf);
return t;
}特点 :先用1024字节栈缓冲区尝试格式化,不够则堆分配翻倍重试。最终通过 sdscat 一次性追加到SDS,触发 sdsMakeRoomFor 的预分配。
sdscatfmt为什么比sdscatvprintf快?
sdscatvprintf需要先格式化到临时缓冲区,再memcpy到SDS → 两次拷贝sdscatfmt直接格式化到SDS的buf中 → 一次拷贝
6.4 对比表
| API | 扩容方式 | 临时缓冲区 | 拷贝次数 |
|---|---|---|---|
sdscatlen |
一次 sdsMakeRoomFor |
无 | 1 |
sdscatfmt |
逐字符 sdsMakeRoomFor(1) |
无 | 1 |
sdscatvprintf |
栈缓冲区 + 翻倍重试 + 一次 sdsMakeRoomFor |
1024B栈/堆 | 2 |
七、sdsMakeRoomFor + sdsIncrLen
零拷贝模式。sdscatlen 的追加模式是:sdsMakeRoomFor → memcpy → 更新len。数据从源地址拷贝到 buf。
但在网络读取场景中,数据直接从内核写入 buf,不需要中间拷贝:
c
// sds.c:316-327 ------ 源码注释中的用法示例
sds s = sdsempty();
s = sdsMakeRoomFor(s, BUFFER_SIZE); // 1. 预留空间
nread = read(fd, s + sdslen(s), BUFFER_SIZE); // 2. 直接读入buf
sdsIncrLen(s, nread); // 3. 更新lenRedis中的实际用法 (networking.c:1524):
c
// 读取客户端数据
qblen = sdslen(c->querybuf);
sdsMakeRoomFor(c->querybuf, c->querybuf_peak + 1 - qblen);
nread = read(fd, c->querybuf + qblen, readlen);
sdsIncrLen(c->querybuf, nread);对比 sdscatlen 的两次拷贝路径:
read() → 内核缓冲区 → 中间buf → memcpy → SDS buf (sdscatlen路径)
read() → 内核缓冲区 → SDS buf (零拷贝路径)零拷贝路径省去了一次 memcpy,在高吞吐场景下性能提升明显。
sdsIncrLen源码
c
// sds.c:329-370
void sdsIncrLen(sds s, ssize_t incr) {
unsigned char flags = s[-1];
size_t len;
switch(flags & SDS_TYPE_MASK) {
case SDS_TYPE_5: {
unsigned char *fp = ((unsigned char*)s) - 1;
unsigned char oldlen = SDS_TYPE_5_LEN(flags);
assert(incr >= 0 && oldlen + incr < 32);
*fp = SDS_TYPE_5 | ((oldlen + incr) << SDS_TYPE_BITS);
len = oldlen + incr;
break;
}
case SDS_TYPE_8: { SDS_HDR_VAR(8,s); assert(sh->alloc-sh->len >= incr); len = (sh->len += incr); break; }
case SDS_TYPE_16: { SDS_HDR_VAR(16,s); assert(sh->alloc-sh->len >= incr); len = (sh->len += incr); break; }
case SDS_TYPE_32: { SDS_HDR_VAR(32,s); assert(sh->alloc-sh->len >= incr); len = (sh->len += incr); break; }
case SDS_TYPE_64: { SDS_HDR_VAR(64,s); assert(sh->alloc-sh->len >= incr); len = (sh->len += incr); break; }
}
s[len] = '\0';
}关键点:assert(sh->alloc - sh->len >= incr) 确保增量不超过预分配空间。这是调用者的责任------必须先调用 sdsMakeRoomFor 确保空间足够。
八、sdsgrowzero
扩展并填零
c
// sds.c:375-386 (sdsgrowzero)
sds sdsgrowzero(sds s, size_t len) {
size_t curlen = sdslen(s);
if (len <= curlen) return s;
s = sdsMakeRoomFor(s, len - curlen);
if (s == NULL) return NULL;
memset(s + curlen, 0, (len - curlen + 1)); // 新增区域填零(含\0)
sdssetlen(s, len);
return s;
}sdsgrowzero 确保字符串至少有 len 字节,新增部分用 \0 填充。适用场景:需要预分配并初始化的缓冲区。
九、类型升级与降级的完整分析
9.1 升级路径
扩容时,newlen 增大可能触发类型升级:
sdshdr5 → sdshdr8 → sdshdr16 → sdshdr32 → sdshdr64
(1B) (3B) (5B) (9B) (17B)升级条件:
| 当前类型 | 最大 alloc | 超过后升级为 |
|---|---|---|
| sdshdr5 | --- | 不参与扩容 |
| sdshdr8 | 255 | sdshdr16 |
| sdshdr16 | 65535 | sdshdr32 |
| sdshdr32 | 4294967295 (4GB) | sdshdr64 |
9.2 降级路径
sdsRemoveFreeSpace 回收空间时,len 变小可能触发类型降级:
sdshdr64 → sdshdr32 → sdshdr16 → sdshdr8注意 :不存在降到 sdshdr5 的情况。sdsReqType 在 len < 32 时返回 SDS_TYPE_5,但 sdsRemoveFreeSpace 的逻辑中,SDS_TYPE_5 被间接排除了------因为回收后的字符串可能在将来需要追加,sdshdr5 不支持追加。
实际上 sdsRemoveFreeSpace 没有显式排除TYPE_5,它确实可能降级到TYPE_5。但这通常不会造成问题,因为下次追加时 sdsMakeRoomFor 会立即升级为TYPE_8。
9.3 升级时的内存拷贝开销
| 场景 | 操作 | 原因 |
|---|---|---|
| 类型不变 | realloc |
可能原地扩展,零拷贝 |
| 类型升级 | malloc + memcpy + free |
header变大,buf偏移改变 |
| 类型降级 | malloc + memcpy + free |
header变小,buf偏移改变 |
优化空间 :理论上升级时可以用 realloc,因为header变大后数据整体后移,可以在旧内存末尾扩展。但 realloc 不保证原地扩展,如果移动了地址,header中 s 指针的偏移也要调整。当前实现用 malloc+memcpy+free 更简单安全。
十、预分配与惰性释放的协作流程
内存是最廉价的资源(相对CPU时间和系统调用),用适量的内存冗余换取极低的realloc频率。这不是浪费------这是缓存思维在内存管理中的应用。
至此,SDS 的三大核心议题------结构设计、设计哲学、扩容与预分配------已全部梳理完毕。SDS 用预分配和惰性释放告诉我们一个朴素但重要的道理:提前多占一点,比临时抢一点快得多 。这种"用空间换时间"的思路并非 SDS 独有,Redis 的字典在扩容时同样不急于一次性搬移数据,而是采用渐进式 rehash 将开销分摊到每一次操作中。下一站,我们将走进 Redis 的链表与字典,看看 adlist 如何实现经典的双向链表,dict 又是如何在哈希表之上构建出渐进式 rehash 与冲突解决机制的。
|----------------------------------------------|----------------------------------------------------------------------|
| 欢迎各位同学关注我哦~ 在这个 AI 喧嚣的时代 不忘初心,戒骄戒躁,认真沉淀 | |