定义
MoE(Mixture of Experts)是一种新兴的模型架构,广泛应用于各种闭源大模型中。传统的大模型都是单个模型进行推理,推理时使用全部的参数,而MOE则是借鉴了传统机器学习中的ensemble思想,将transformer模型的每个FFN层替换为一个MoE层。MoE层包含一个门控网络和若干个专家网络。
负载均衡
1. KeepTopK 策略:引入随机性的 "公平分配"
KeepTopK 是最基础也最常用的负载均衡策略,核心思想是 "引入噪声 + 强制选优",避免路由器过度依赖热门专家。

2. 辅助损失函数:用数学约束实现均衡
仅靠策略调整难以完全解决负载均衡问题,因此研究者在主损失(如交叉熵损失)之外,引入 "辅助损失(Auxiliary Loss)",将 "专家使用均匀性" (各个专家模块被激活的频率是否均衡。它衡量的是:模型是否公平地利用了所有专家,而不是偏向某几个专家)纳入模型优化目标
(1)核心逻辑
通过计算所有专家的 "使用重要性差异"(不同专家对模型最终输出的贡献程度的高低),迫使模型降低差异,实现公平分配。
方式一:Auxiliary-Loss-Free Load Balancing(辅助无损负载均衡)
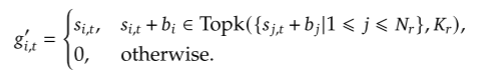
应用Auxiliary-Loss-Free Load Balancing时,仅在选择topk个亲合度分数的时候,为每一个专家添加一个偏置量 (这个偏置量仅仅用于topk筛选,不加入后续的权重计算)。在每个训练步骤结束的时候,如果某个专家过载,则按照某一特定比例减少其偏置量;如果某个专家负载不足,则相应的按照同一比例增加其偏置量。
3. 专家容量:限制 "工作量" 的硬性约束
负载不均衡不仅体现在 "选择哪些专家",还体现在 "每个专家处理多少 token"。即使专家被选中的次数相近,若大量 token 集中路由到某几个专家,仍会导致训练不充分。
(1)专家容量的定义
专家容量(Expert Capacity)是指单个专家在一个批次中最多能处理的 token 数量,设为。当某专家处理的 token 数量达到时,后续分配给该专家的 token 会被路由到次优专家。
(2)容量计算与调整
专家容量通常由 "容量因子(Capacity Factor)" 控制,计算公式为:
其中:
为批次中 token 的总数;
为每个 token 选择的专家数(Top-k);
为专家数量;
为容量因子(超参数,通常设为 1.0~1.2)。
(3)Token 溢出处理
若所有候选专家均达到容量上限,剩余 token 将跳过当前 MoE 层,直接进入下一层(称为 Token Overflow)。为减少溢出对性能的影响,通常需合理设置容量因子:过大会浪费算力,过小会导致大量溢出。
图14展示了当专家模块的溢出情况,FFNN1(左)承担了大部分的tokens任务,从而降低了整体的性能。
Switch Transformer:简化 MoE 的负载均衡方案
Switch Transformer 是最早解决 MoE 训练不稳定性的经典架构,其核心贡献是通过 "简化路由 + 优化容量控制",降低 MoE 的实现难度,同时提升训练稳定性。