


目录
[1.1. 性能优化](#1.1. 性能优化)
[1.2. 首次制作索引比较慢](#1.2. 首次制作索引比较慢)
[2.1. 搜索模块核心类](#2.1. 搜索模块核心类)
[2.2. 搜索核心执行流程](#2.2. 搜索核心执行流程)
[2.3. 核心方法](#2.3. 核心方法)
[1. 核心搜索(search)](#1. 核心搜索(search))
[2. 摘要生成 + 关键词标红 GenDesc()](#2. 摘要生成 + 关键词标红 GenDesc())
[3. 去除 HTML 标签和合并多个空格](#3. 去除 HTML 标签和合并多个空格)
一、索引模块
1.1. 性能优化
java
public void run() {
long beg = System.currentTimeMillis();
System.out.println("制作索引开始!");
// 储存待处理的文件列表
ArrayList<File> fileList = new ArrayList<>();
// 遍历文件目录,将所有文件加入待处理列表
enumFile(INPUT_PATH, fileList);
long endEnumFile = System.currentTimeMillis();
System.out.println("枚举文件完毕,消耗时间:" + (endEnumFile - beg) + " ms");
for (File f : fileList) {
System.out.println("开始解析:" + f.getAbsolutePath());
// 解析文件,标题、url、正文
parseHTML(f);
}
long endFor = System.currentTimeMillis();
System.out.println("解析文件完毕,消耗时间:" + (endFor - endEnumFile) + " ms");
index.save();
long end = System.currentTimeMillis();
System.out.println("制作索引结束,消耗时间:" + (end - beg) + " ms");
}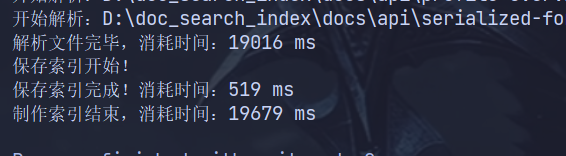
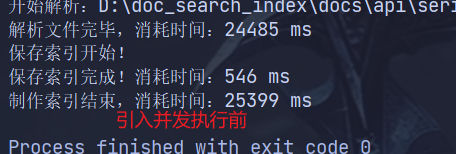
我们获取下每个执行方法的时间戳,会发现解析文件消耗了大量时间,这是因为 run() 方法采用单线程串行执行,文档数量越多,耗时呈线性增长,CPU 核心完全浪费。可以采用固定大小线程池并行解析文档,将 读文件和分词、建索引任务并发执行,最大化利用硬件资源。
我们直接使用线程来指定固定的线程数,避免线程频繁创建销毁。接着我们还需要使用同步工具 CountDownLatch,等待所有线程解析完成,再统一保存索引。此外还需要加锁保证多线程同时操作 Index 时数据不混乱。
java
public void runByTread() throws InterruptedException {
long beg = System.currentTimeMillis();
System.out.println("制作索引开始!");
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH, fileList);
CountDownLatch latch = new CountDownLatch(fileList.size());
ExecutorService service = Executors.newFixedThreadPool(4);
for (File file : fileList) {
service.submit(new Runnable() {
@Override
public void run() {
System.out.println("解析:" + file.getAbsolutePath());
parseHTML(file);
latch.countDown();
}
});
}
latch.await();
service.shutdown();
long end = System.currentTimeMillis();
System.out.println("制作索引结束,消耗时间:" + (end - beg) + " ms");
}在构建正排索引的方法中,ArrayList 非线程安全,docId 由 size() 生成,并发会导致ID 重复、文档覆盖、数组越界,所以必须保证生成 docId与添加到 ArrayList 这两步是原子操作,必须加锁!
java
synchronized (locker1) {
doc.setDocId(forwardIndex.size());
forwardIndex.add(doc);
}在构建倒排索引的方法中,HashMap 非线程安全,并发写入会导致数据丢失、链表死环、程序崩溃。在写入权重列表时必须加锁。
java
synchronized (locker2) {
List<Weight> invertedList = invertedIndex.get(entry.getKey());
if (invertedList == null) {
ArrayList<Weight> newInvertedList = new ArrayList<>();
Weight weight = new Weight();
weight.setDocId(doc.getDocId());
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
newInvertedList.add(weight);
invertedIndex.put(entry.getKey(), newInvertedList);
} else {
Weight weight = new Weight();
weight.setDocId(doc.getDocId());
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
invertedList.add(weight);
}
}
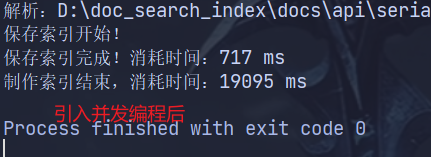
1.2. 首次制作索引比较慢
每次开机重启之后,第一次制作索引的速度会非常慢。这是因为在 parseContent() 解析 HTML 文本的时候需要读取文件,开销很大。AtomicLong 是 java.util.concurrent.atomic 包下的一个类,它提供了一种线程安全的方式来操作 long 类型的变量。
java
// 用于统计解析内容耗时
private AtomicLong t1 = new AtomicLong(0);
// 用于统计索引添加耗时
private AtomicLong t2 = new AtomicLong(0);
public void runByTread() throws InterruptedException {
long beg = System.currentTimeMillis();
System.out.println("制作索引开始!");
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH, fileList);
CountDownLatch latch = new CountDownLatch(fileList.size());
ExecutorService service = Executors.newFixedThreadPool(4);
for (File file : fileList) {
service.submit(new Runnable() {
@Override
public void run() {
System.out.println("解析:" + file.getAbsolutePath());
parseHTML(file);
latch.countDown();
}
});
}
latch.await();
service.shutdown();
index.save();
long end = System.currentTimeMillis();
System.out.println("制作索引结束,消耗时间:" + (end - beg) + " ms");
System.out.println("t1 = " + t1 + ", t2 = " + t2);
}
private void parseHTML(File f) {
// 1. 解析标题
String title = parseTitle(f);
// 2. 解析 URL
String url = parseURL(f);
// 记录程序开始执行时的时间点(纳秒级)
long beg = System.nanoTime();
// 3. 解析正文
String content = parseContent(f);
long mid = System.nanoTime();
// 4. 解析出来的信息加入到索引中
index.addDoc(title, url, content);
long end = System.nanoTime();
t1.addAndGet(mid - beg);
t2.addAndGet(end - mid);
}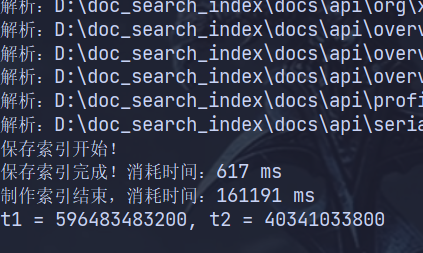
如果我们再次启动程序,会发现会快很多。
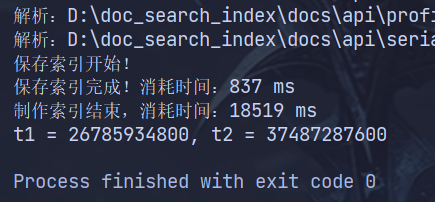
parseContent 核心是从硬盘读取文档文件。操作系统会自动把已读取的文件缓存到高速内存中。首次运行时,所有文档无内存缓存,只能低速直接读取硬盘,因此方法执行很慢;后续运行时,文件已存入系统内存缓存,直接读内存即可,速度大幅提升。我们可以使用 BufferedReader 缓冲流替换原始无缓冲文件流,批量读取文件内容,减少与硬盘的频繁交互,降低硬盘读取耗时。
java
private String parseContent(File f) {
try (BufferedReader bufferedReader = new BufferedReader(new FileReader(f))) {
boolean isCopy = true; // 标记是否正在复制文本内容
StringBuilder content = new StringBuilder();
while (true) {
int ret = bufferedReader.read();
// 到达文件末尾,停止读取
if (ret == -1) {
break;
}
char ch = (char) ret;
if (isCopy) {
// 遇到开始符号,停止复制
if (ch == '<') {
// 停止复制,跳过当前字符
isCopy = false;
continue;
}
content.append(ch);
} else {
// 遇到结束符号恢复复制
if (ch == '>') {
isCopy = true;
}
}
}
return content.toString();
} catch (IOException e) {
throw new RuntimeException(e);
}
}二、搜索模块
搜索模块是搜索引擎的查询核心,作用是加载已构建的正排 / 倒排索引,接收用户查询词,完成分词、触发索引、权重排序、结果封装,最终返回带标题、URL、摘要的搜索结果,是连接用户与索引数据的关键环节。
2.1. 搜索模块核心类
- DocSearcher:搜索核心类,承载所有搜索逻辑(分词、查索引、排序、封装结果)
- Result:最终返回给用户 / 前端的搜索结果封装类
- Weight:索引模块的权重对象,记录docId+ 文档权重值
- DocInfo:正排索引对象,存储文档的docId、标题、URL、正文
Result 类(搜索结果封装)
java
package com.yang.java_doc_searcher.searcher;
import lombok.Getter;
import lombok.Setter;
// 搜索结果封装
@Getter
@Setter
public class Result {
private String title;
private String url;
// 正文的一段摘要
private String desc;
@Override
public String toString() {
return "Searcher Result{" +
"title='" + title + '\'' +
", url='" + url + '\'' +
", desc='" + desc + '\'' +
'}';
}
}DocSearcher 类(核心搜索类)
java
package com.yang.java_doc_searcher.searcher;
import org.ansj.domain.Term;
import java.util.ArrayList;
import java.util.List;
public class DocSearch {
private Index index = new Index();
public DocSearch() {
index.load();
loadStopWord();
}
// 核心搜索方法(带权重合并)
public List<Result> search(String query) {
}
// 摘要生成方法(含关键词标红)
private String GenDesc(String content, List<Term> terms) {
}
// 多路权重归并方法
private List<Weight> mergeResult(List<List<Weight>> source) {
}
// 停用词加载方法
private void loadStopWord() {
}
}2.2. 搜索核心执行流程
- 分词:对用户查询词用 ansj 分词器拆分
- 过滤停用词:剔除无意义的高频词(如 a、is、空格)
- 触发索引:用分词结果查倒排索引,拿到匹配的文档权重列表
- 权重合并:多词匹配同一文档时,累加权重(优化点)
- 排序 + 封装:按权重降序排序,查正排索引补全信息,生成 Result
2.3. 核心方法
1. 核心搜索(search)
最终对外提供的搜索方法,整合停用词过滤 + 多路权重合并,解决多词查询排名不准、结果泛滥问题。
首先我们需要调用 ToAnalysis.parse 对查询词分词,ansj 自动将英文转为小写,保证与索引分词规则一致。接着遍历分词结果,对每个有效分词,调用 index.getInverted(word) 查询倒排。然后按权重降序排列(权重越高,文档相关性越强);最后通过 docId 查正排索引,补全标题、URL,调用 GenDesc 生成标红摘要,封装为 Result 返回。
java
// 核心搜索方法
public List<Result> search(String query) {
// 对查询词进行分词
List<Term> terms = ToAnalysis.parse(query).getTerms();
// 触发索引
List<Weight> allTermResult = new ArrayList<>();
for (Term term : terms) {
String word = term.getName();
// 查倒排索引:获取该词对应的所有文档权重
List<Weight> invertedList = index.getInverted(word);
if (invertedList != null) {
allTermResult.addAll(invertedList);
}
}
// 按权重进行降序排序
allTermResult.sort((o1, o2) -> o2.getWeight() - o1.getWeight());
// 封装结果:查正排索引,补全标题、url、摘要
List<Result> results = new ArrayList<>();
for (Weight weight : allTermResult) {
DocInfo docInfo = index.getDocInfo(weight.getDocId());
Result result = new Result();
result.setTitle(docInfo.getTitle());
result.setUrl(docInfo.getUrl());
result.setDesc(GenDesc(docInfo.getContent(), terms));
results.add(result);
}
return results;
}2. 摘要生成 + 关键词标红 GenDesc()
该方法用于从文档正文中截取关键词附近文本作为搜索摘要,并对关键词标红,提升用户阅读体验。执行逻辑是要遍历分词,找到第一个全词匹配的关键词在正文中的位置(避免部分匹配,如array≠arrays)。以关键词为中心,向前取 60 字符、向后取 160 字符,生成固定长度摘要。最后,用正则 (?i) 忽略大小写,将关键词用 <i> 标签包裹,前端设置红色样式。
java
private String GenDesc(String content, List<Term> terms) {
int firstPos = -1;
// 不区分大小写查找
String contentLower = content.toLowerCase();
for (Term term : terms) {
String word = term.getName();
// 确保前后有空格,避免部分匹配
firstPos = contentLower.indexOf(" " + word + " ");
if (firstPos > 0) {
break;
}
}
if (firstPos == -1) {
return " ";
}
int descBeg = Math.max(0, firstPos - 60);
String desc = descBeg + 160 > content.length()
? content.substring(descBeg) :
content.substring(descBeg, descBeg + 160) + "...";
for (Term term : terms) {
String word = term.getName();
desc = desc.replaceAll("(?!) " + word + " ", " <i>" + word + "</i> ");
}
return desc;
}3. 去除 HTML 标签和合并多个空格
java
public String parseContentByRegex(File f) {
// 读取文件内容
String content = readFile(f);
// 移除<script>标签及里面的内容
content = content.replaceAll("<script.*?>(.*?)</script>", " ");
// 移除其他html标签
content = content.replaceAll("<.*?>", " ");
// 将空白字符替换为单个空格
content = content.replaceAll("\\s+", " ");
return content;
}
private String readFile(File f) {
try (BufferedReader bufferedReader = new BufferedReader(new FileReader(f));) {
StringBuilder content = new StringBuilder();
while (true) {
int ret = bufferedReader.read();
if (ret == -1) {
break;
}
char c = (char)ret;
if (c == '\n' || c == '\r') {
c = ' ';
}
content.append(c);
}
return content.toString();
} catch (IOException e) {
e.printStackTrace();
}
return "";
}