作者:来自 Elastic Benjamin Trent
深入解析 DiskBBQ 的块布局、文档 ID 压缩模式以及原生 SIMD 内核如何协同工作,为 9.4 版本中的 DiskBBQ 带来 40% 的向量评分吞吐量提升。
通过这个面向 Search AI 的**自助式动手实验** 亲自体验向量搜索。你现在就可以开始**免费的云试用** ,或者在你的**本地机器**上体验 Elastic。
Elasticsearch DiskBBQ 已经通过基于块的布局加速了 Better Binary Quantization (BBQ) 向量操作。Elasticsearch 9.4 新增了**原生单指令多数据(SIMD)内核**,使吞吐量相比单向量操作提升接近 3 倍。下面我们来看看这种格式是如何工作的。
DiskBBQ 通过密集且连续的块布局,直接从内存映射(memory-mapped)的索引文件中读取向量字节。这种方式能够保持较低的堆内存使用量,同时让引擎能够处理远超可用 RAM 容量的数据集。在这些块布局内部,DiskBBQ 还会对文档 ID 块进行编码,在减少磁盘占用的同时保持较低的解码开销。
本文将介绍其倒排列表(posting list)布局、文档 ID 打包模式,以及批量评分(bulk scoring)为何能够如此高效。
DiskBBQ 如何在磁盘上存储向量倒排列表
在每个倒排列表的开头,我们会写入质心(centroid)评分校正值、向量数量以及整体的文档 ID 编码方式。随后,我们以块(block)的形式写入文档 ID 和向量数据。
这些块及其内部数据都按照文档 ID 升序排列。这种设计遵循了分片(segment)文档 ID 的顺序,从而保留了索引排序(index sort order)。与这种顺序对齐的过滤器更有可能一次性包含或排除整个数据块。
在存储完文档 ID 后,我们会存储量化后的向量字节数据,然后再存储该数据块中所有向量对应的校正值(corrections)。
 倒排列表的布局。从元数据头(metadata header)开始,后面跟随多个数据块(block)。每个数据块包含 bulk_size 个文档 ID,然后是量化后的向量字节数据,最后是量化后的校正值(correction values)。
倒排列表的布局。从元数据头(metadata header)开始,后面跟随多个数据块(block)。每个数据块包含 bulk_size 个文档 ID,然后是量化后的向量字节数据,最后是量化后的校正值(correction values)。
DiskBBQ 如何压缩文档 ID 以减少磁盘空间
为了确保文档 ID 数据块能够快速解码,DiskBBQ 会使用相同的编码格式对倒排列表中的每个数据块进行编码。
DiskBBQ 会先计算每个数据块所需的编码方式,然后选择整个倒排列表中空间开销最大的那种编码方式,并将其统一应用到所有文档数据块上。这样做虽然可能会牺牲部分压缩率,但能够简化解码逻辑并提高读取性能。
在撰写本文时,DiskBBQ 提供五种用于存储文档 ID 的压缩方案。每种方案都会先对文档 ID 值进行完整的增量编码(delta encoding),然后再在增量编码后的文档 ID 之上应用以下某一种编码类型。
| 编码类型 | 条件 | 节省的字节数(示例) |
|---|---|---|
| 连续(Continuous) | ID 连续递增(max−min+1 == len) | 16 字节 → 4 字节 |
| 16 位增量编码(Delta 16) | 所有增量值都能用 16 位表示 | 64 字节 → 33 字节 |
| 每个值使用 21 位 | 所有值都能用 21 位表示 | 12 字节 → 8 字节 |
| 每个值使用 24 位 | 所有值都能用 24 位表示 | 64 字节 → 48 字节 |
| 回退模式(Fallback,全量整数) | 其他任何情况 | 无压缩效果 |
最高效的方式是连续编码(Continuous)。
当满足条件 max(doc_block) - min(doc_block) + 1 == len(doc_block) 时,就会使用这种编码方式。这意味着文档 ID 是连续递增的,因此增量编码(delta encoding)只需要存储最小值,后续的文档 ID 都可以通过在前一个值的基础上依次加 1 重新构造出来。
例如,文档 ID 为:
[4858192, 4858193, 4858194, 4858195]
在这种情况下,无需写入四个独立的 int 值(共 16 字节),只需要写入一个值:
4858192
解码时即可恢复为:
4858192, 4858193, 4858194, 4858195
因此,存储空间从 16 字节减少到 4 字节。
 连续编码(Continuous encoding);只需要写入一个整数。
连续编码(Continuous encoding);只需要写入一个整数。
接下来是 delta 16。
当所有 delta 都能放入 16 位(即两个字节)时,就会使用这种编码方式。
假设我们有:
doc_ids = [1000, 1003, 1010, 1020, 1041, 1055, 1070, 1090, 1100, 1125, 1200, 1300, 2000, 4000, 16000, 66000]
那么:
min = 1000
得到的 deltas 为:
deltas = [0, 3, 10, 20, 41, 55, 70, 90, 100, 125, 200, 300, 1000, 3000, 15000, 65000]
这些 16 个 delta 可以被打包成 8 个 int32(32 字节),再加上一个 min 值,从而使字节占用几乎减少 2 倍。
 Delta 16;写入最小值,然后将两个 16 位的 delta 打包进每个 32 位整数中。
Delta 16;写入最小值,然后将两个 16 位的 delta 打包进每个 32 位整数中。
下一种是每个值 21 位编码。
这是一种相对复杂的方案,其中每组三个值会被压缩进一个 64 位的数值中,并且如果有剩余值,则会以 3 字节的尾部进行存储。
一个具体例子是:
doc_ids=[1000, 70000, 140000]
它们会被压缩成一个 64 位整数:
doc0 | (doc1 << 21) | (doc2 << 42)
最终结果是,三个原始整数值(共 12 字节)被压缩为 8 字节。
 每个值 21 位,一种相当复杂的方案,将三元组压缩为 64 位值,并在末尾附加 3 字节的尾部。
每个值 21 位,一种相当复杂的方案,将三元组压缩为 64 位值,并在末尾附加 3 字节的尾部。
倒数第二种压缩方式用于每个整数最多只需要 24 位的情况。
由于一个 int 通常需要 32 位空间,而 24 位会空出整整 1 个字节,因此不能浪费这部分空间。该方案的目标是尽可能填满所有字节。
因此,这种编码方式会把这些"空出来的字节"重新利用起来,把后续的数值填充进去。
例如:
docs_ids = [1000, 70000, 140000, 300000, 500000, 800000, 1000000, 1300000, 1600000, 1900000, 2200000, 3000000, 4000000, 8000000, 12000000, 16000000]
最终,最后四个整数会被压缩进前面整数留下的"空闲字节"中,从而把 16 个整数(通常需要 64 字节)压缩为 48 字节。
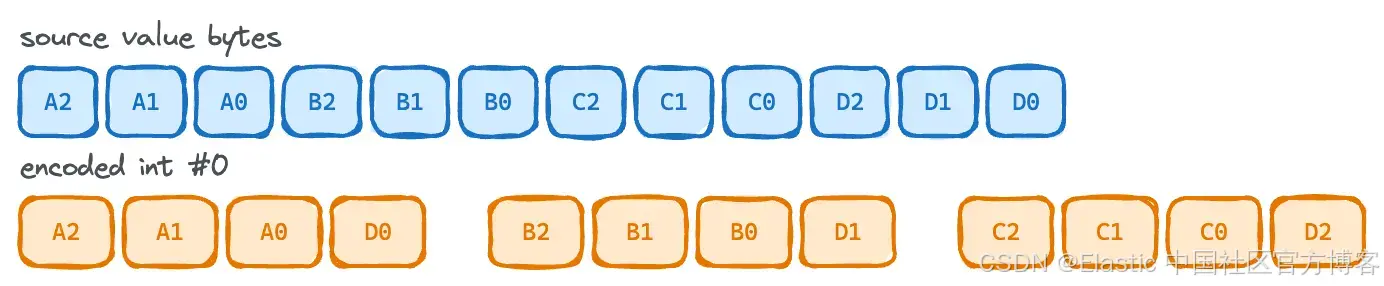 这是一个 24 位每值编码的示例,其中最后一组字节被打包进前面的空间中。它利用了那一"空闲字节"的存储空间。
这是一个 24 位每值编码的示例,其中最后一组字节被打包进前面的空间中。它利用了那一"空闲字节"的存储空间。
最终一种是回退(fallback)方案。
DiskBBQ 会将每个 doc ID 以完整精度的整数形式存储,不进行任何磁盘压缩。因此,这种方式不会带来任何磁盘空间上的节省。由于 doc ID 在压缩前已经经过 delta 编码,因此 fallback 的使用频率非常低。
为什么 DiskBBQ 的批量评分更快:SIMD 与 CPU 缓存饱和
将向量按块存储使得可以进行 SIMD 优化的批量评分。这种方式能够让 CPU cache line 保持高利用率,从而持续加载向量字节,并使用 SIMD 优化内核来应用量化(quantization)校正值。
如果向量与校正值是交错存储的,那么在每次计算完一个向量分数之后,都需要立即应用校正,这会破坏吞吐量,并失去对校正应用进行优化的机会。
下面是一个性能基准测试(benchmark),展示了在不同优化下吞吐量的提升情况。这是一个在 M1Max MacBook 上使用 Java 25 运行的 JMH benchmark。向量维度为 1024,每次操作包含 10 个查询,在 10 个包含 32 个向量的 block 上执行。
Benchmark (bits) (dims) (similarityFunction) Mode Cnt Score Error Units
Float32Scalar 1 1024 DOT_PRODUCT thrpt 5 0.348 ± 0.014 ops/ms
Float32PanamaVector 1 1024 DOT_PRODUCT thrpt 5 1.106 ± 0.043 ops/ms
BBQIndividual 1 1024 DOT_PRODUCT thrpt 5 8.420 ± 0.180 ops/ms
BBQBulkPartial 1 1024 DOT_PRODUCT thrpt 5 15.306 ± 0.757 ops/ms
BBQBULK 1 1024 DOT_PRODUCT thrpt 5 16.672 ± 0.572 ops/ms
BBQBulkNative 1 1024 DOT_PRODUCT thrpt 5 23.258 ± 2.273 ops/ms下面是对上述各个 benchmark 的说明:
-
Float32Scalar:纯 JVM 执行浮点运算,没有任何手工优化的 SIMD。
-
Float32PanamaVector:使用了部分 SIMD 优化的代码路径,基于 Panama Vector API。
-
BBQIndividual:逐个执行 bit-wise BBQ 操作。每个向量单独加载到 JVM heap 中进行评分和校正。
-
BBQBulkPartial :基于 mmap 文件段的 off-heap 批量评分,使用 Panama Vector操作读取数据;校正值随后在 JVM heap 上应用。
-
BBQBULK:完整的 off-heap 批量评分,向量和校正值都通过 SIMD 优化的 Java Vector API 从 mmap 文件中直接读取并处理。
-
BBQBulkNative:这是 Elasticsearch 9.4 中的实现。完全原生的批量向量操作,直接从索引文件读取字节并执行 SIMD 处理。
这些结果展示了吞吐量的演进过程,从最基础的逐个浮点运算开始。
切换到 SIMD(使用 Vector API 手动优化)后,浮点运算吞吐量提升约 3 倍,但仍然慢于 BBQ 中自动向量化的逐位运算方式。
随后切换到批量评分(bulk scoring)后,BBQ 吞吐量再次提升近 2 倍。
再加入 Elasticsearch 9.4 的新优化原生 SIMD 内核后,又带来一次显著提升,使整体性能相比逐个 bit-wise 评分提升接近 3 倍 ,相较 float32 操作则达到了惊人的 66 倍提升。
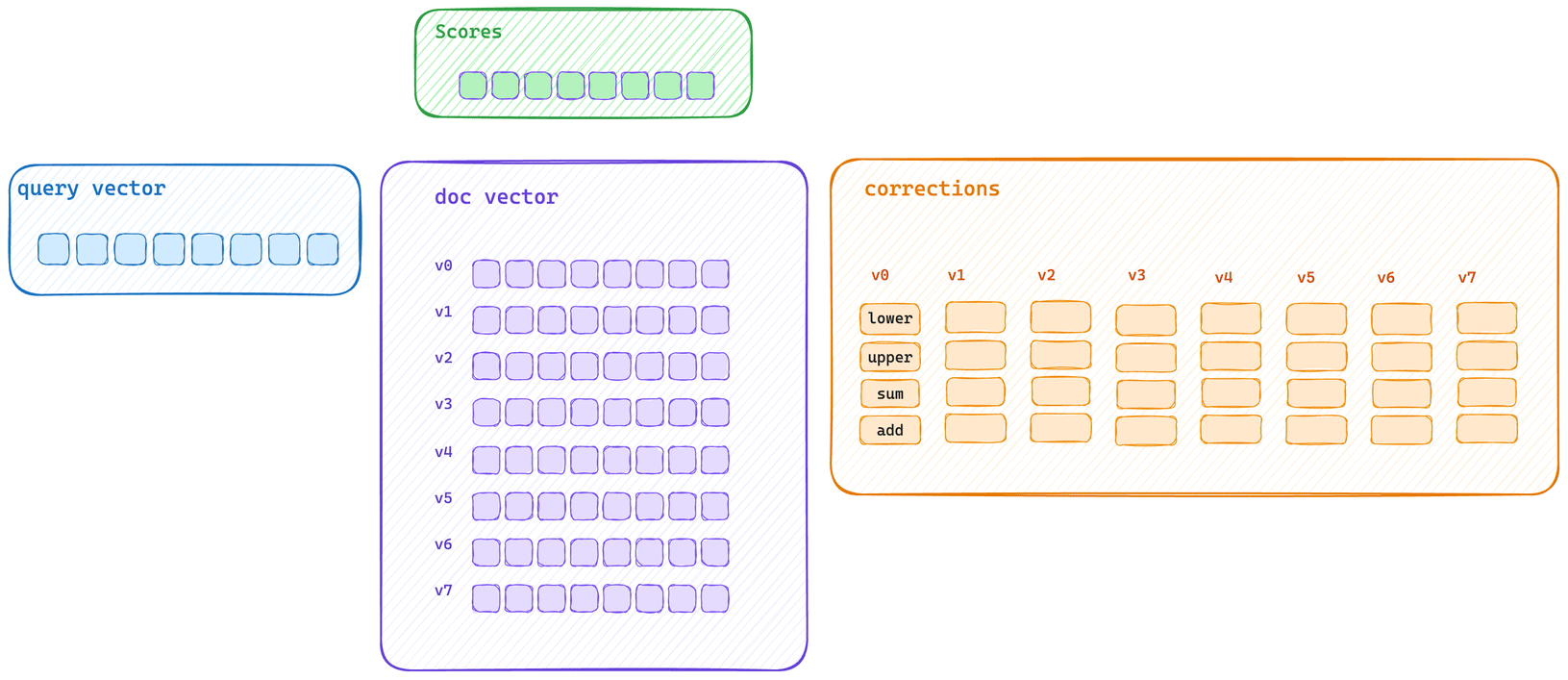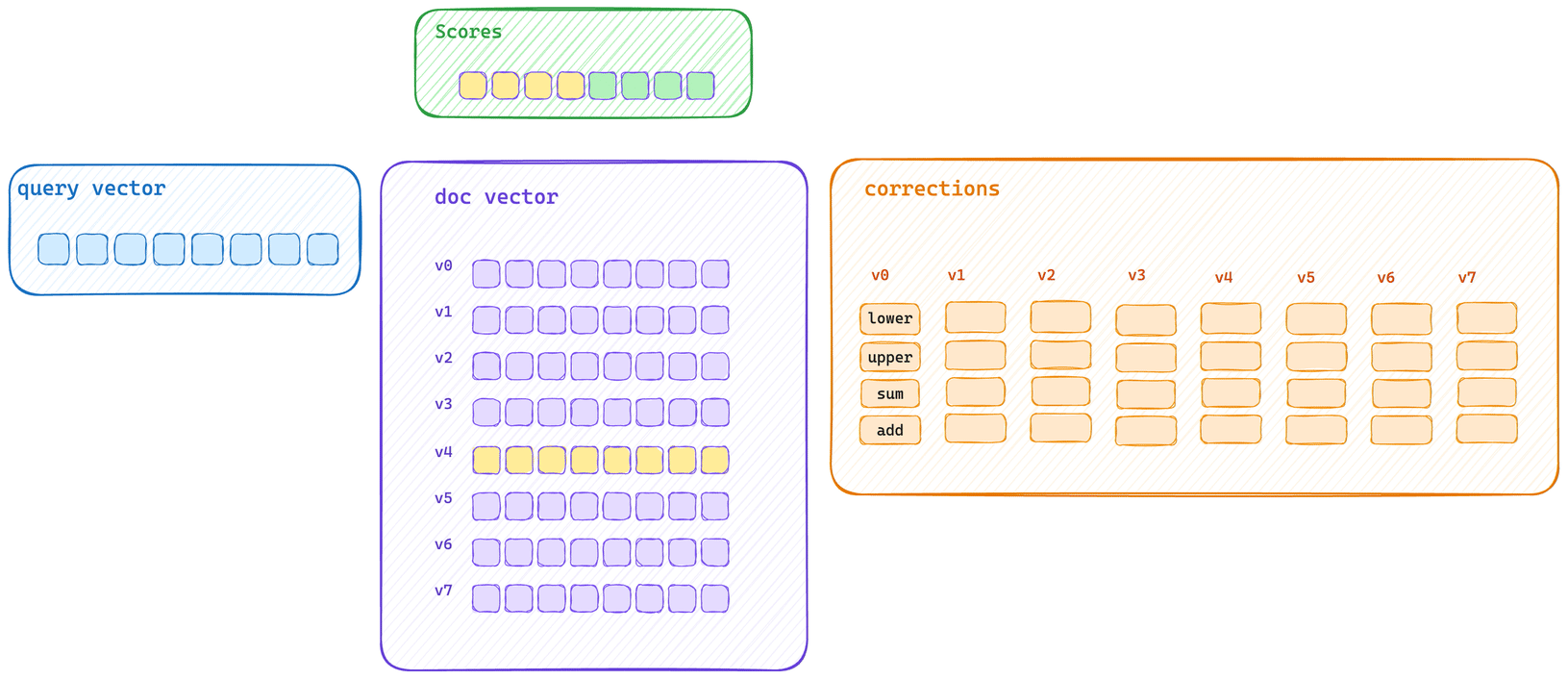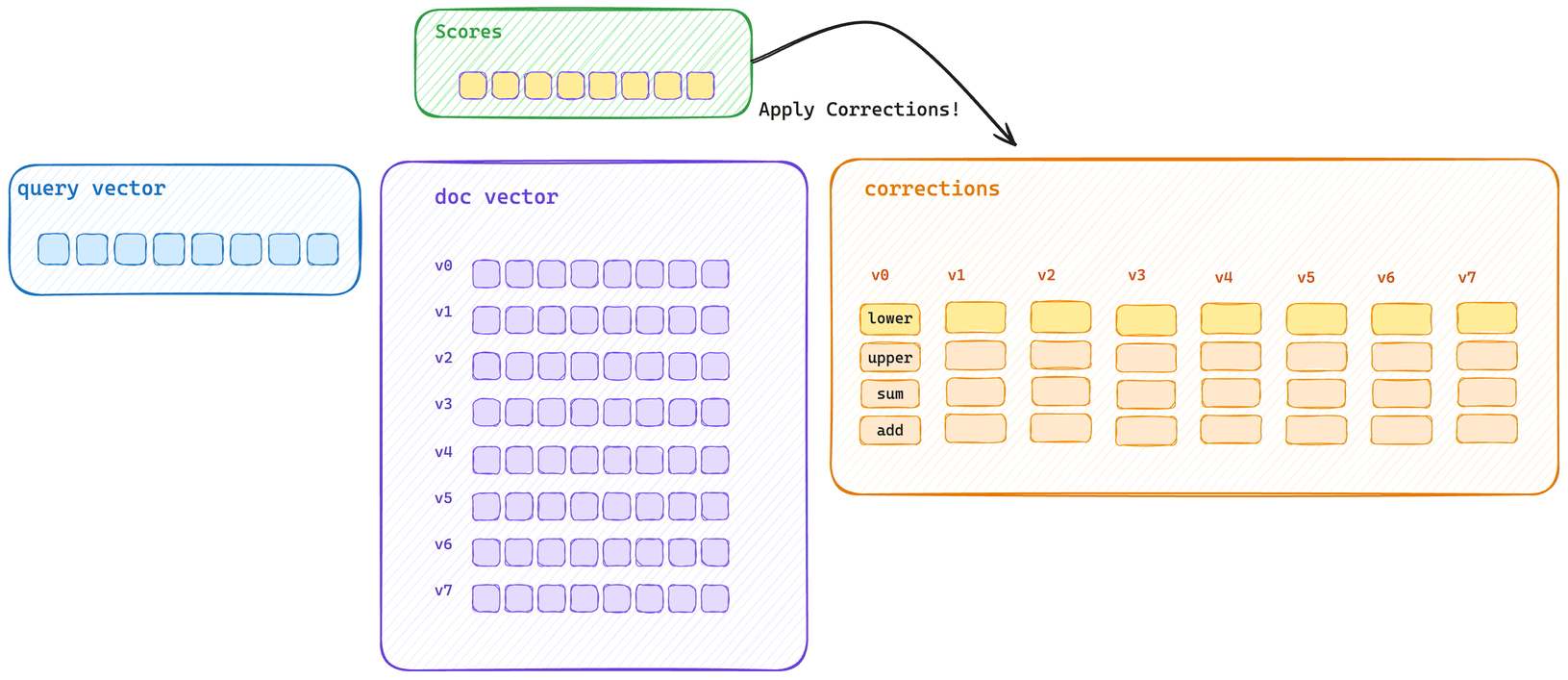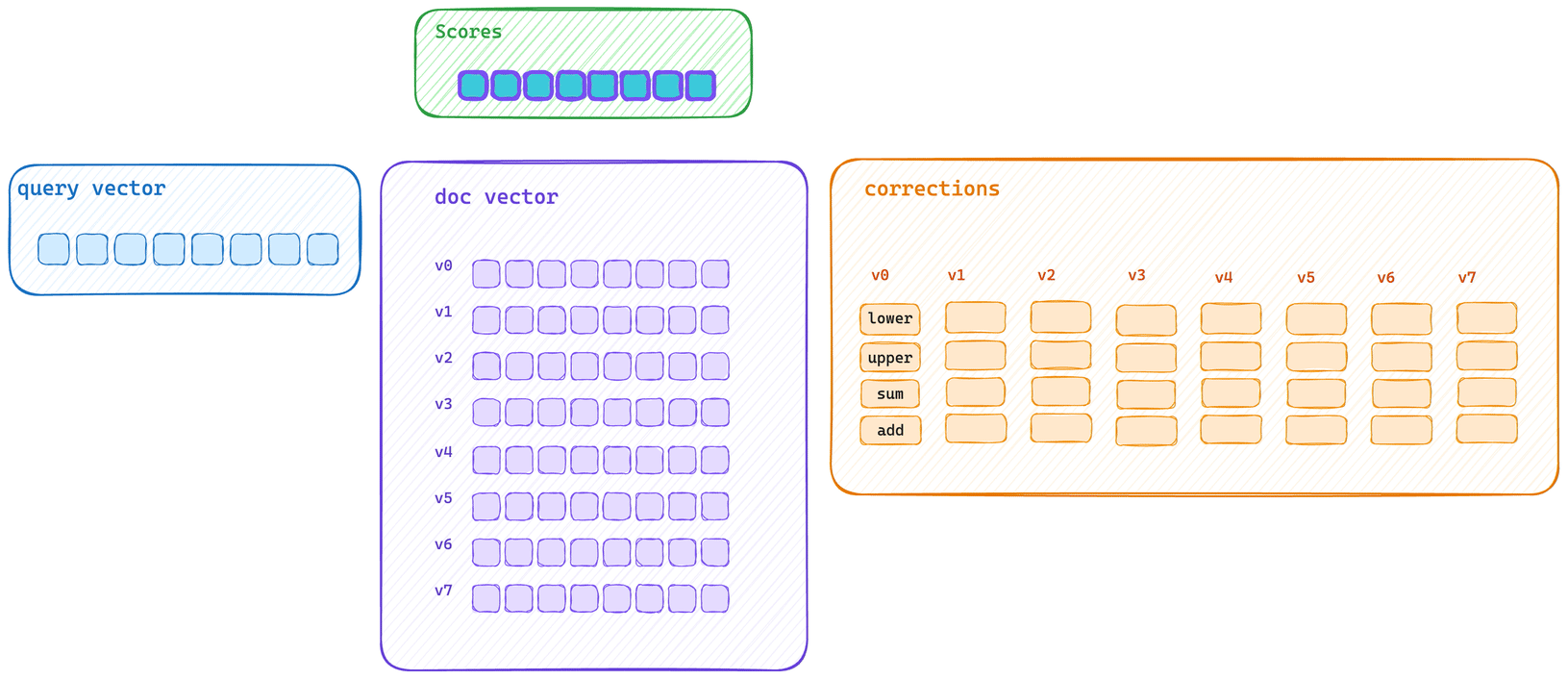 这展示了典型的批量评分路径。查询向量会先为块中的每个向量计算初始分数信息,然后再使用优化的 SIMD 块操作应用每个校正值。
这展示了典型的批量评分路径。查询向量会先为块中的每个向量计算初始分数信息,然后再使用优化的 SIMD 块操作应用每个校正值。
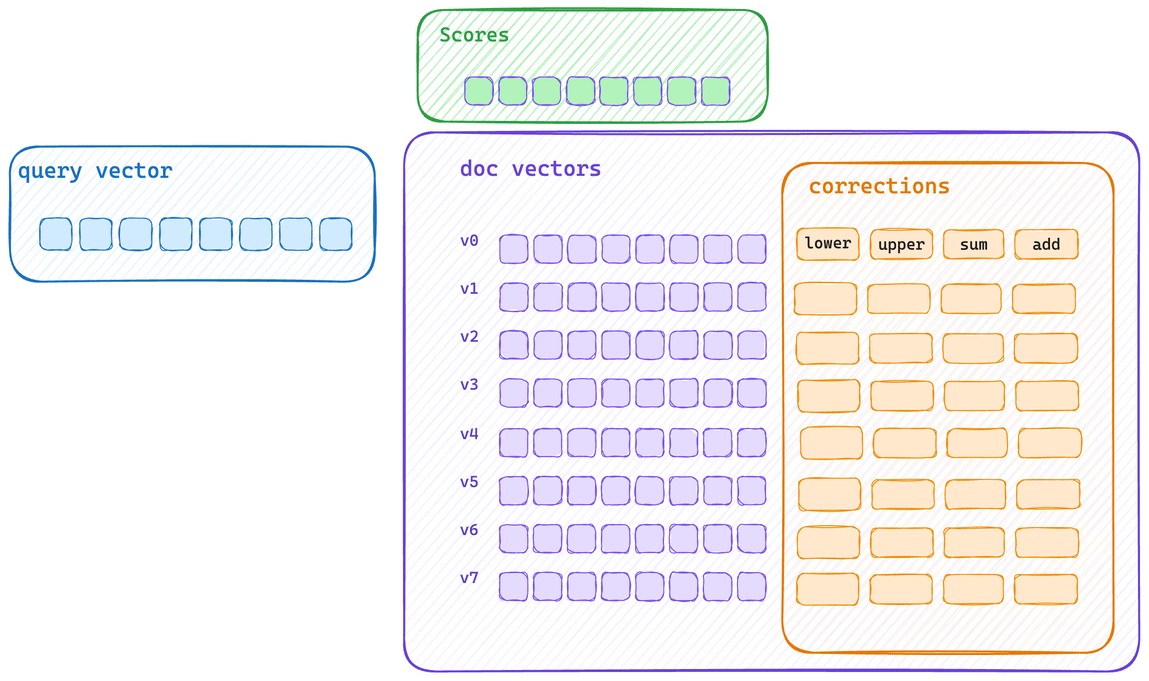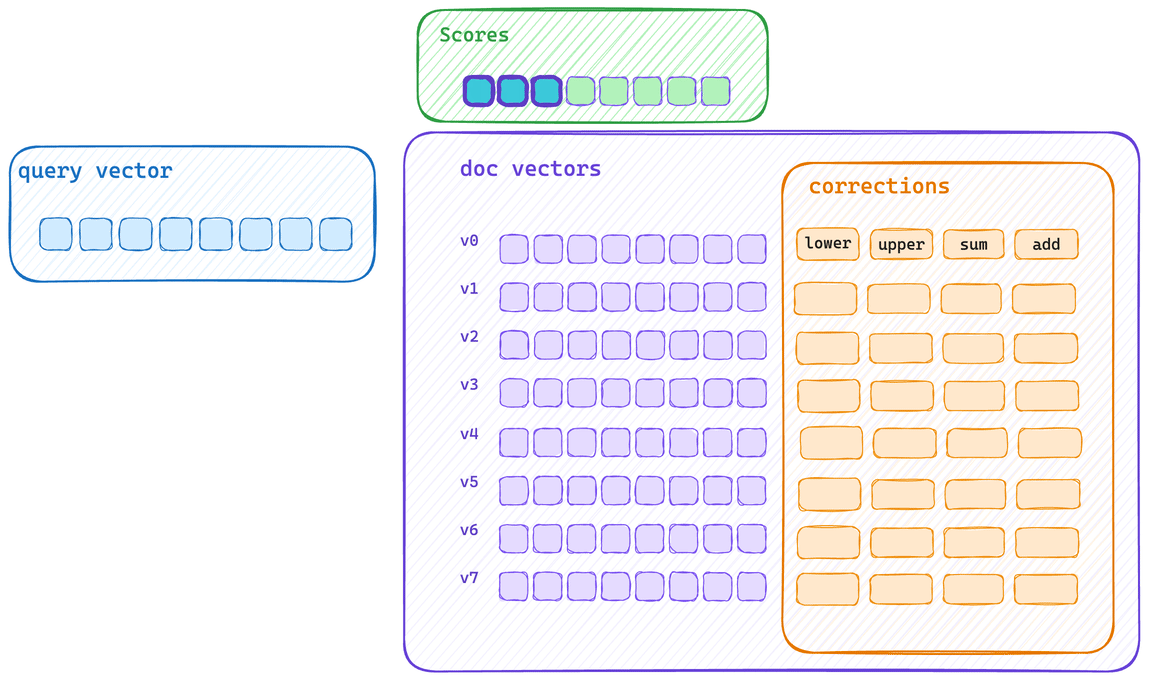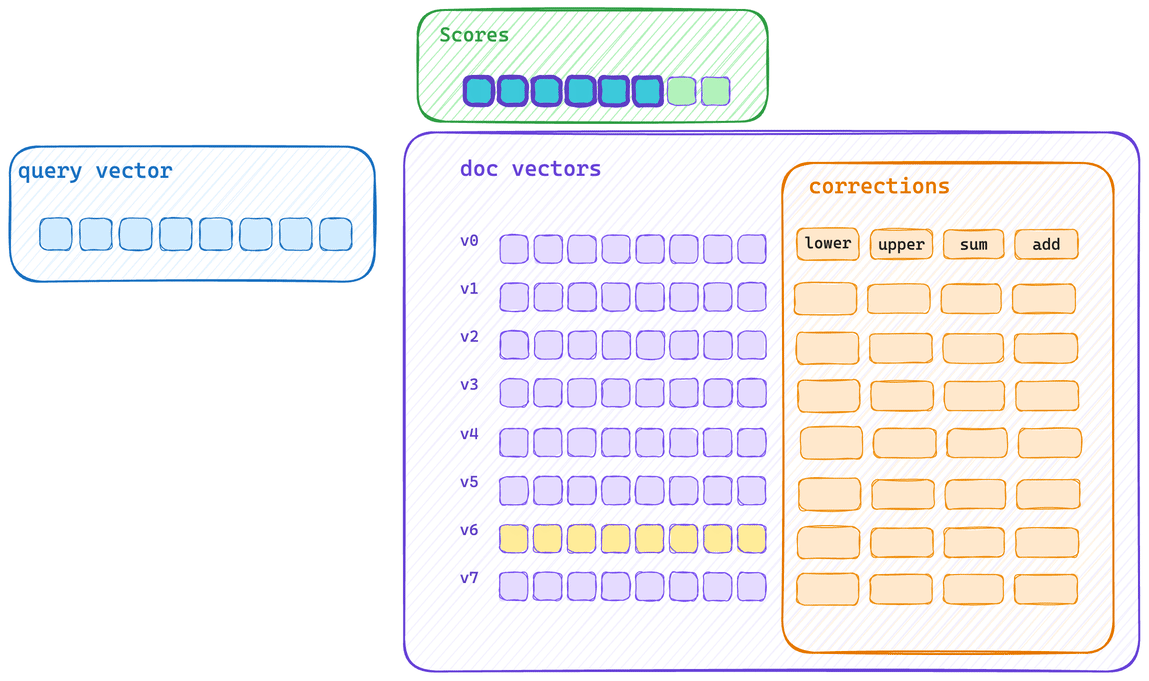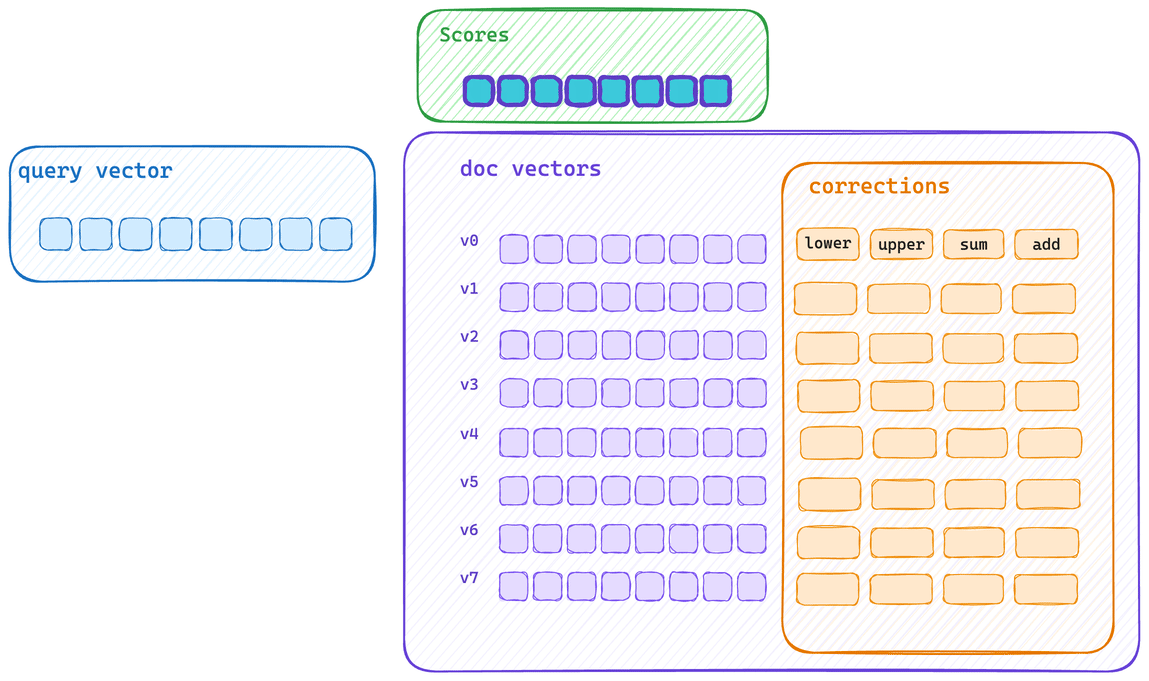 这是典型的单向量评分路径。每个向量都会先被计算得分,然后再应用其校正值。这意味着向量字节无法充分填满 CPU cache,同时校正的应用也无法使用相同的 SIMD 块操作来执行。
这是典型的单向量评分路径。每个向量都会先被计算得分,然后再应用其校正值。这意味着向量字节无法充分填满 CPU cache,同时校正的应用也无法使用相同的 SIMD 块操作来执行。
DiskBBQ 向量搜索性能:原生 SIMD 在实践中的意义
Elasticsearch 9.4 中的原生 SIMD 内核使 BBQ 向量评分速度提升近 3 倍,并且吞吐量达到 float32 操作的 66 倍。我们还没有完成优化;总还有改进空间,但这种原生 SIMD 的块评分模式在所有 CPU 架构上都表现良好,使 DiskBBQ 在任何部署环境中都能保持高速。
这段内容有多大帮助?
原文:Elasticsearch DiskBBQ: 40% faster vector search with native SIMD - Elasticsearch Labs