目录
[1. 目标函数先别写复杂,先把钱和约束讲明白](#1. 目标函数先别写复杂,先把钱和约束讲明白)
[2. 软时间窗,不只是迟到罚款](#2. 软时间窗,不只是迟到罚款)
[3. 双容量约束是这道题很容易被低估的一点](#3. 双容量约束是这道题很容易被低估的一点)
[4. 到达时间怎么递推,决定了时间窗是不是落得下去](#4. 到达时间怎么递推,决定了时间窗是不是落得下去)
[5. 分时段速度,是这题从"普通 VRP"变复杂的关键一步](#5. 分时段速度,是这题从“普通 VRP”变复杂的关键一步)
[6. 能耗为什么是 U 型,而不是"越快越费油"](#6. 能耗为什么是 U 型,而不是“越快越费油”)
[7. 碳排放不是附属指标,而是成本的一部分](#7. 碳排放不是附属指标,而是成本的一部分)
[8. 公式怎么变成程序结构](#8. 公式怎么变成程序结构)
[9. 第一问最后跑出了什么](#9. 第一问最后跑出了什么)
[10. 这套静态方案稳不稳](#10. 这套静态方案稳不稳)
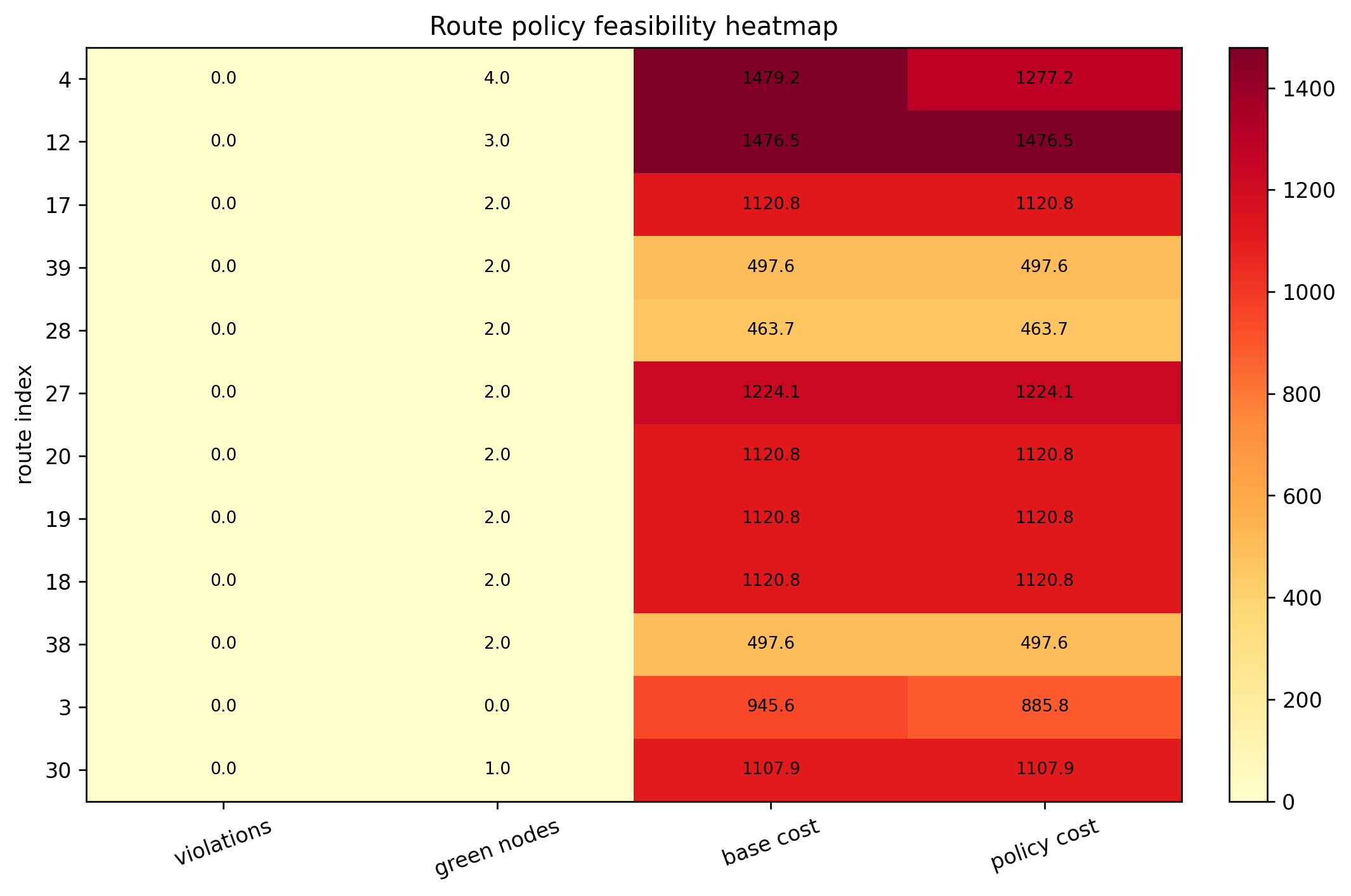
[1. 先把政策约束写对](#1. 先把政策约束写对)
[2. 第二问的求解器为什么切到了 Gurobi](#2. 第二问的求解器为什么切到了 Gurobi)
[3. 问题二不是"把燃油车都换成电动车"](#3. 问题二不是“把燃油车都换成电动车”)
[4. 真正发生变化的,是时序和分组,而不是大换车](#4. 真正发生变化的,是时序和分组,而不是大换车)
[5. 哪些客户最受政策影响](#5. 哪些客户最受政策影响)
[1. 第三问不是从零开始,而是从问题二接着往下走](#1. 第三问不是从零开始,而是从问题二接着往下走)
[2. 动态问题最难的不是"再算一遍",而是"不能全都重来"](#2. 动态问题最难的不是“再算一遍”,而是“不能全都重来”)
[3. 第三问为什么用 NSGA-II](#3. 第三问为什么用 NSGA-II)
[4. NSGA-II 优化的不是路径本身,而是"调整方式"](#4. NSGA-II 优化的不是路径本身,而是“调整方式”)
[5. 动态事件是怎么被组织起来的](#5. 动态事件是怎么被组织起来的)
[6. 第三问最后跑出了什么](#6. 第三问最后跑出了什么)
[7. Pareto 前沿在第三问里不是摆设](#7. Pareto 前沿在第三问里不是摆设)
[1. 先把订单聚合成服务节点](#1. 先把订单聚合成服务节点)
[2. 把时变速度做成一个可调用的行驶时间函数](#2. 把时变速度做成一个可调用的行驶时间函数)
[3. 把能耗函数做成路线弧段评估器](#3. 把能耗函数做成路线弧段评估器)
[4. 把政策约束做成可判定的可行性逻辑](#4. 把政策约束做成可判定的可行性逻辑)
[5. 把动态稳定性做成第四个目标](#5. 把动态稳定性做成第四个目标)
题目到底在解决什么问题
先说结论:这不是一道普通的 VRP。
题目表面上是"城市物流配送",本质上却把几类很容易单独成题的约束叠在了一起:
- 混合车队:燃油车 + 新能源车
- 双容量约束:同时受重量和体积限制
- 软时间窗:早到要等,晚到要罚
- 固定服务时间:每个客户服务 20 分钟
- 分时段速度:早高峰、平峰、拥堵时段不同
- U 型能耗函数:速度太慢和太快都不省能
- 碳排放成本:不是只看钱,还看碳
- 绿色配送区政策:燃油车在特定时段禁入
- 动态事件:新增订单、取消、地址改动、时间窗变化、车辆故障、交通降速
题目 PDF 里给出的原始规模也不小:
- 98 个客户点
- 2169 个订单
- 5 类车辆,共 185 辆
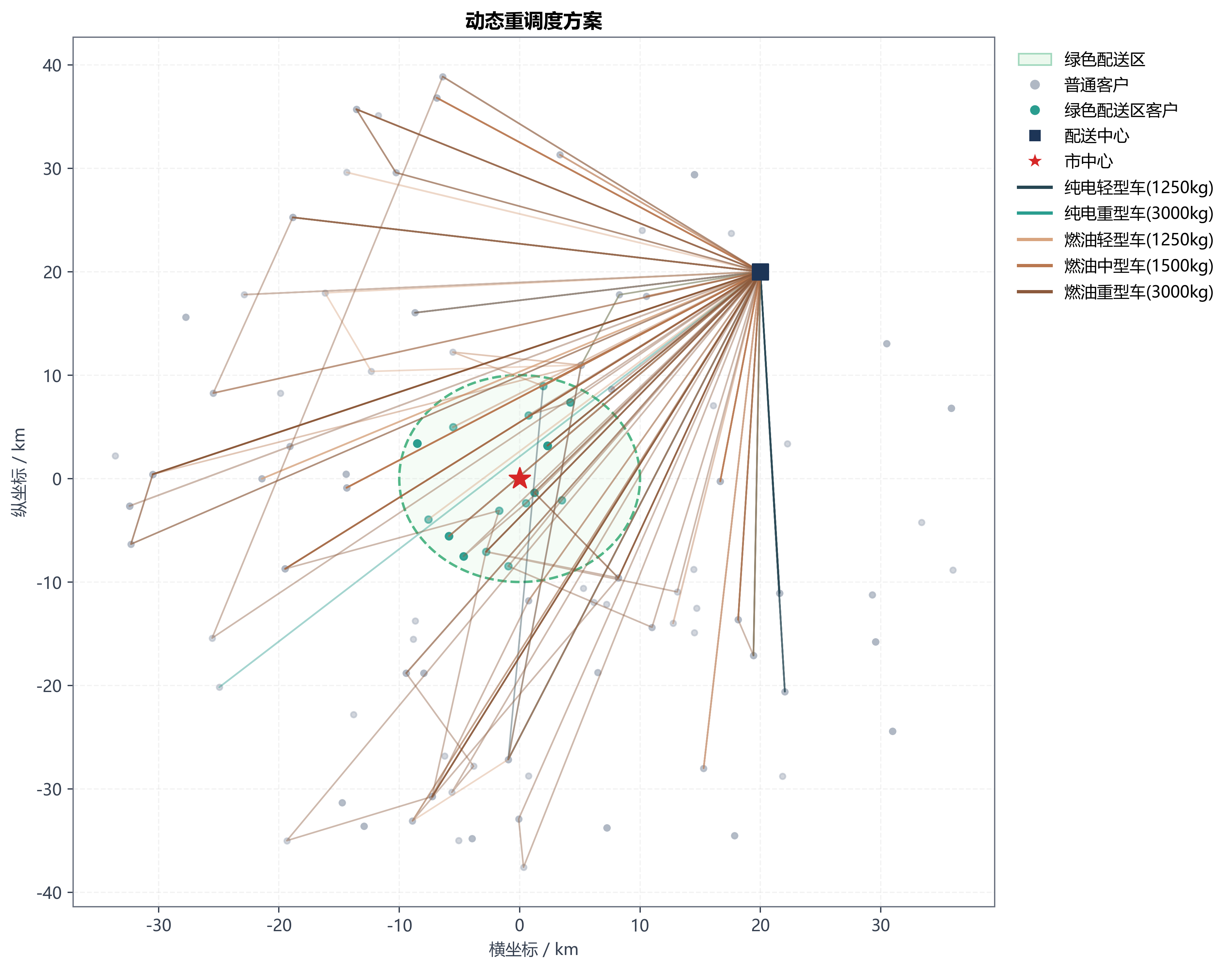
- 配送中心坐标在 (20, 20)
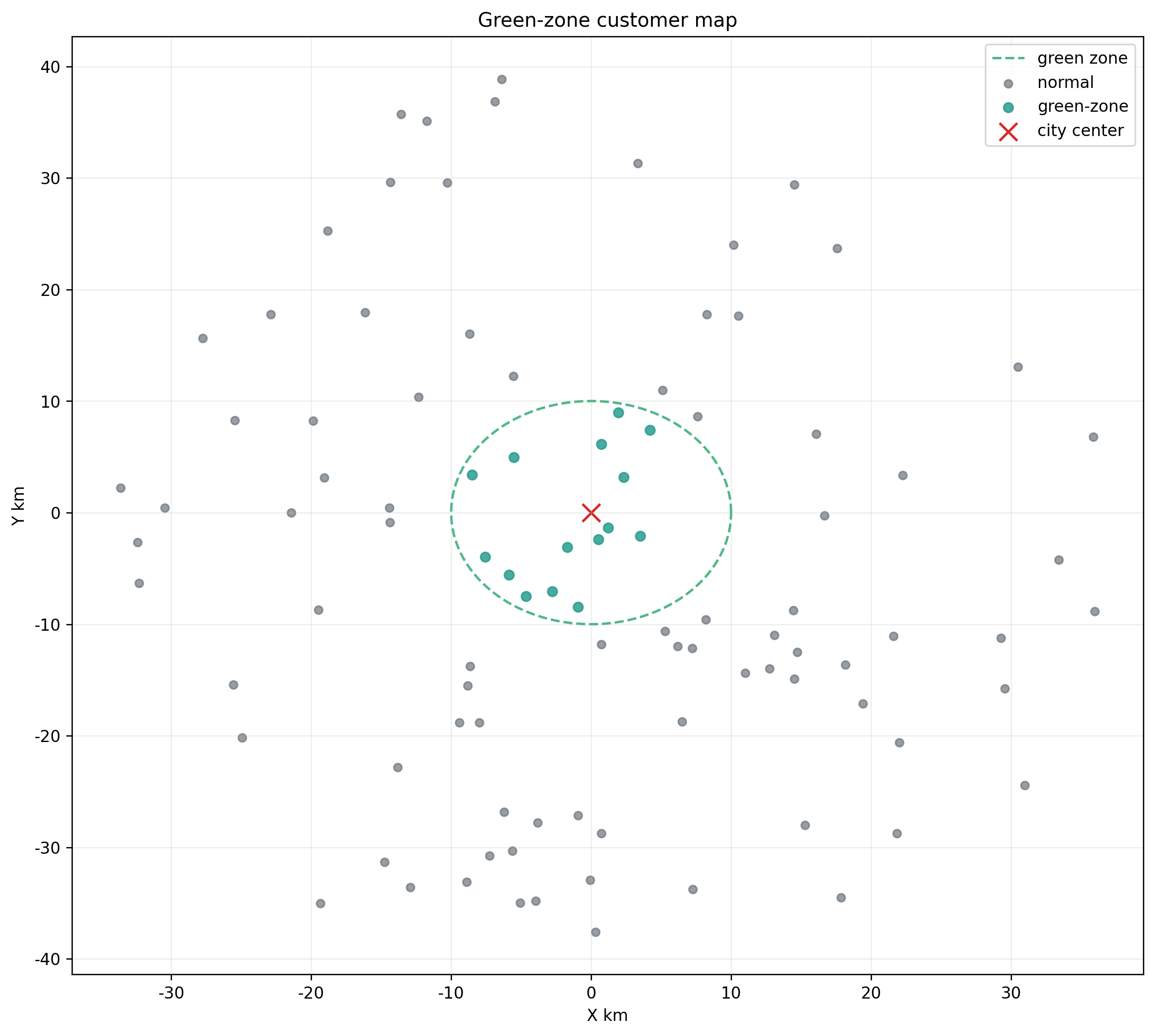
- 市中心坐标在 (0, 0)
- 绿色配送区定义为"以市中心为圆心、半径 10 km 的圆形区域"
如果只把它当成"带时间窗的路径规划",很容易低估它的难度。更准确地说,它是一个带绿色物流、政策约束和动态响应的复合调度问题。
先看数据:我拿到了哪些输入
原始数据在 附件 和每问子目录下的 data 中都有副本。直接看 01_problem1_static/data,四份核心 Excel 很清楚:
| 文件 | 规模 | 作用 |
|---|---|---|
| 客户坐标信息.xlsx | 99 × 4 | 1 个配送中心 + 98 个客户坐标 |
| 时间窗.xlsx | 98 × 3 | 每个客户的最早/最晚服务时间 |
| 订单信息.xlsx | 2169 × 4 | 订单重量、体积和所属客户 |
| 距离矩阵.xlsx | 99 × 100 | 点到点道路距离 |
这里最值得讲的,不是"读 Excel",而是预处理的口径。
项目里的 preprocess.py (line 212) 做了几件非常关键的事:
- 把订单层数据聚合到客户层
- 把时间窗统一转成分钟制
- 如果距离矩阵缺值,用欧氏距离乘 1.25 兜底
- 根据坐标识别绿色配送区客户
- 对超大客户做"拆点"
其中第 5 步直接决定了后面的建模规模。代码不是简单沿用原始 98 个客户,而是把需求过大的客户拆成多个同址、同时间窗的服务节点。拆分目标不是 3000kg,而是更保守的 1500kg / 8.5m³:
python
parts = int(
np.ceil(
max(
row["demand_kg"] / 1500.0 if row["demand_kg"] > 0 else 1.0,
row["demand_m3"] / 8.5 if row["demand_m3"] > 0 else 1.0,
1.0,
)
)
)这一步做完后,问题规模从 98 个原始客户,变成了 247 个服务节点。也就是说,后续求解器真正面对的不是 98 个点,而是 247 个需要调度的服务任务。
这背后其实很合理。比如在 zone_customer_classification.csv 里可以看到:
- 客户 55 总需求约 12197.65kg / 30.80m³,被拆成 9 个服务节点
- 客户 8 总需求约 11749.55kg / 36.03m³,被拆成 8 个服务节点
如果不拆点,这种客户本身就不满足单车服务的物理约束,后面的模型再漂亮也落不了地。
一点很真实的数据口径提醒
题目文字里提到"绿色配送区内有 30 个客户",但当前项目按坐标重新识别后,在 zone_customer_classification.csv 中被标记为绿色区的原始客户是 15 个,边界客户 2 个。
这说明项目实现最终采用的是"按坐标重算"的口径,而不是直接把题面描述当成既定事实。做比赛时这类差异很容易被忽略,但做成项目时反而必须交代清楚:后续政策分析到底是按哪套口径跑出来的。
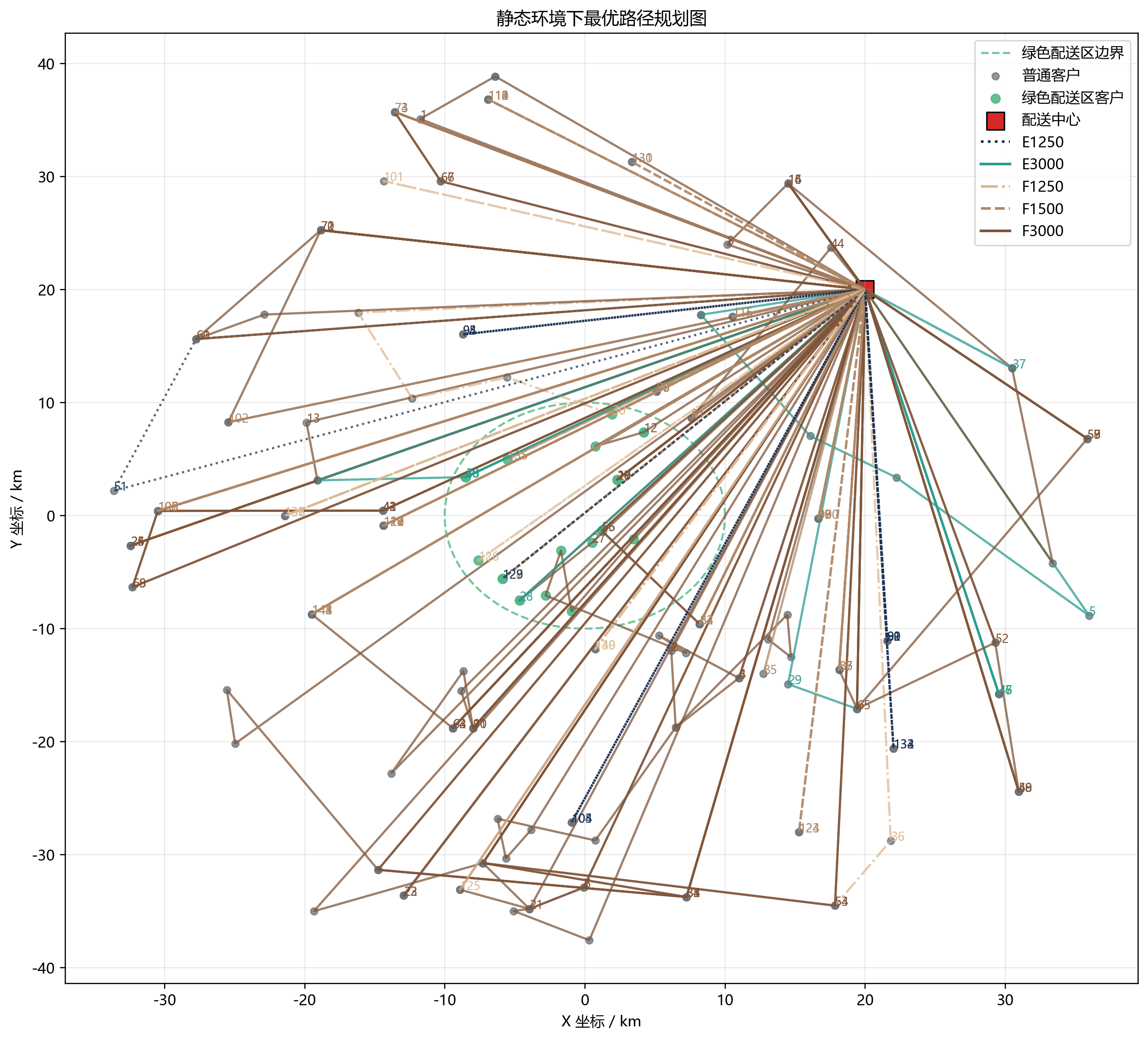
第一问:先把静态环境下的基础路径走对
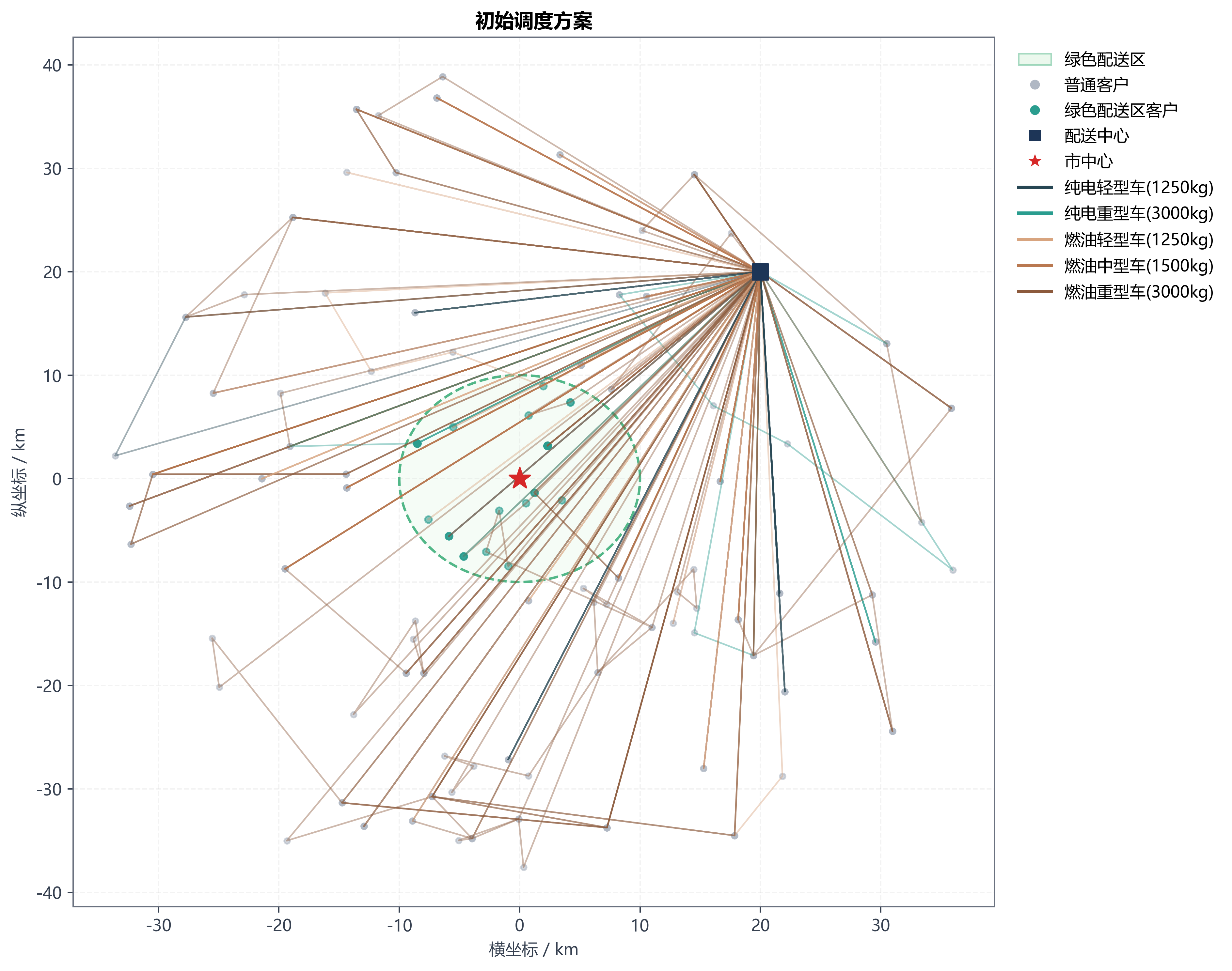
1. 目标函数先别写复杂,先把钱和约束讲明白
第一问的目标很直接:在没有政策限制的前提下,把总配送成本压到最低。
项目里实际采用的总成本结构是:
它在业务上的含义也很直白:
- 启动成本:每启用一辆车,固定花 400 元
- 能耗成本:油费或电费
- 碳排放成本:按排放量折算成钱
- 等待成本:早到不能服务,只能等
- 延误惩罚:晚到要罚
- P:不可行惩罚项,比如漏服务、重复服务、容量违反
在代码里,真正给启发式求解器打分的目标又往前走了一步。evaluator.py 用的是一个加权标量目标:
这解释了为什么问题一的最终输出里会同时出现两个数:
- best_total_cost = 98378.44
- best_objective = 99184.13
前者是财务口径的总成本,后者是求解器搜索时使用的综合目标。做工程时把这两个口径分开,我觉得是对的:一个负责"找解",一个负责"解释解"。
2. 软时间窗,不只是迟到罚款
时间窗在这个项目里不是硬约束,而是软约束。车辆到达客户 ii 的时刻记为 AiAi,时间窗记为 ei,liei,li,服务开始时刻记为 BiBi,则:
等待时间和延误时间分别是:
对应的时间窗成本是:
其中题目给定:
- 等待成本 20 元/小时
- 延误惩罚 50 元/小时
这个公式在项目里的意义,不只是"加一项罚款",而是把调度逻辑从"绝不能迟到"改成"迟到可以,但要付出代价"。对于真实配送问题,这比纯硬时间窗更像现实。
3. 双容量约束是这道题很容易被低估的一点
每辆车不仅有载重约束,还有容积约束。对车辆 k 的一条路径 r,必须满足:
这里:

很多比赛题里,体积只是"顺手一带"的第二容量;但在这个项目里,正是因为重量和体积同时存在,才逼出了前面那一步服务节点拆分。
4. 到达时间怎么递推,决定了时间窗是不是落得下去
每个客户服务时间固定 20 分钟。若车辆在客户 i 完成服务后驶向客户 j,则:
其中:
- s=20分钟
- Tij(⋅)是从 ii到 jj的时变行驶时间函数
这个式子看起来简单,但真正麻烦的是:Tij不是常数,而是出发时刻的函数。
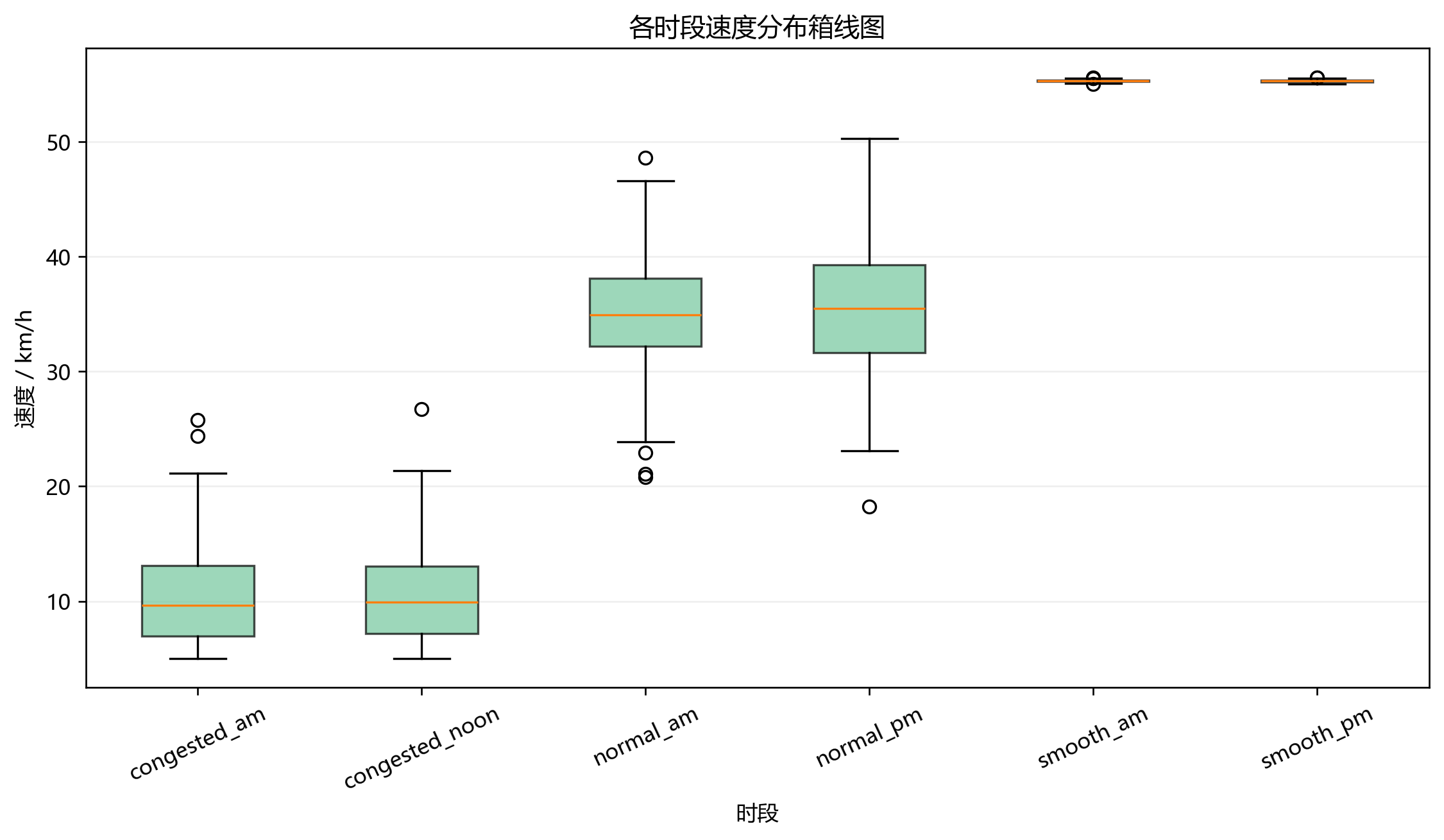
5. 分时段速度,是这题从"普通 VRP"变复杂的关键一步
项目里把一天拆成 6 个时段,对应题目给出的顺畅、一般、拥堵速度分布:
- 08:00-09:00:拥堵,均值 9.8 km/h
- 09:00-10:00:顺畅,均值 55.3 km/h
- 10:00-11:30:一般,均值 35.4 km/h
- 11:30-13:00:拥堵,均值 9.8 km/h
- 13:00-15:00:顺畅,均值 55.3 km/h
- 15:00-17:00:一般,均值 35.4 km/h
因此从 i到 j的路程 dij 不能直接除以一个固定速度,而要按跨越时段逐段积分:
项目里这一步不是靠闭式公式硬推,而是在里做了分段积分:
python
while remaining > 1e-9:
speed = max(self.speed_at(current, stochastic=stochastic), 1e-6)
next_boundary = self.next_boundary_after(current)
dt = max(next_boundary - current, 1e-6)
max_distance = speed * dt / 60.0
if max_distance >= remaining:
used_time = remaining / speed * 60.0
remaining = 0.0
else:
used_time = dt
remaining -= max_distance
current += used_time
total_time += used_time这段代码的意思很朴素:车不是一下子把整段路跑完,而是"先跑到下一个时段边界,再看剩多少路"。
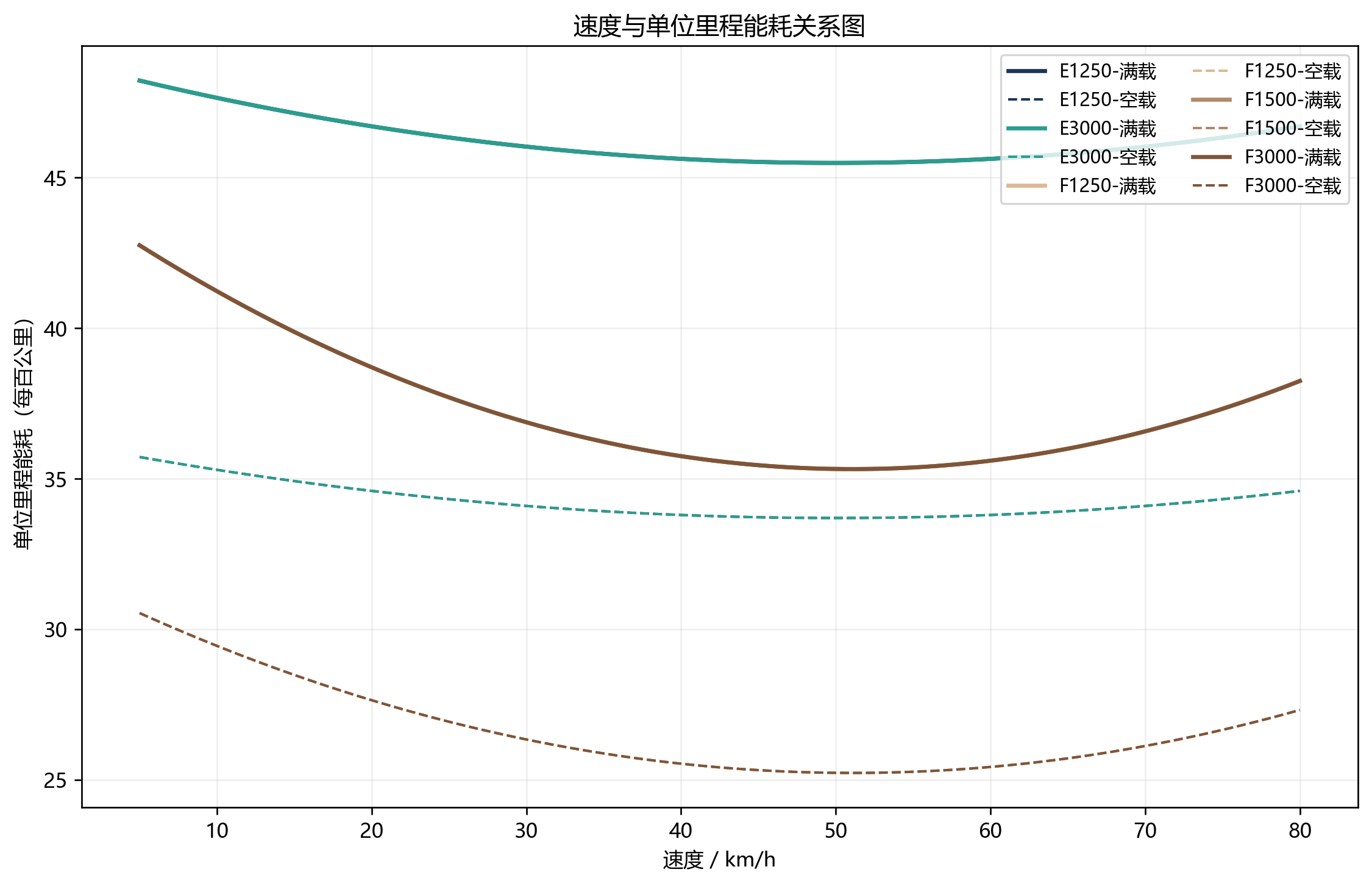
6. 能耗为什么是 U 型,而不是"越快越费油"
题目给出的油耗、电耗函数都是 U 型:
这意味着:
- 太慢时,低速拥堵工况不省能
- 太快时,空气阻力和高负荷也不省能
- 真正省能的是某个中间速度区间
项目还进一步做了载荷修正。设载重率为 λ,则:
也就是说,燃油车满载比空载高 40%,新能源车高 35%。
对应代码在 energy_model.py (line 18) 里非常直接:
python
def fuel_liter_per_100km(speed_kmph: float) -> float:
v = max(float(speed_kmph), 1.0)
return max(0.0025 * v * v - 0.2554 * v + 31.75, 1.0)
def electricity_kwh_per_100km(speed_kmph: float) -> float:
v = max(float(speed_kmph), 1.0)
return max(0.001 * v * v - 0.1 * v + 36.194, 1.0)
def load_correction(self, vehicle, load_ratio: float) -> float:
return 1.0 + vehicle.type_config.full_load_energy_increase * load_ratio7. 碳排放不是附属指标,而是成本的一部分
能耗出来以后,碳排放按线性转换:
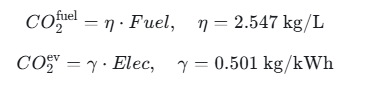
碳成本则是:
这里有一个很值得一提的小细节:当前配置里 distance_cost_per_km = 0,所以"里程"本身并不直接收费,它是通过能耗和碳排放间接进入目标函数的。这也解释了为什么项目里能耗建模做得这么细。
8. 公式怎么变成程序结构
问题一的主流程,在 main.py (line 59) 里是一条很标准的工程链路:
- load_raw_data 读原始 Excel
- preprocess_raw_data 做聚合、拆点、清洗
- TrafficModel 和 EnergyModel 负责时变速度与能耗
- SolutionEvaluator 负责统一算成本、排放、时间窗
- GASolver 或 GurobiSolver 求解
- ResultsExporter 导表
- Visualizer 出图
这比论文式"模型建立-模型求解"更重要的一点是:每一层的职责都分开了,所以后面问题二、问题三能直接复用。
9. 第一问最后跑出了什么
现有 run_summary.json 对应的主结果是:
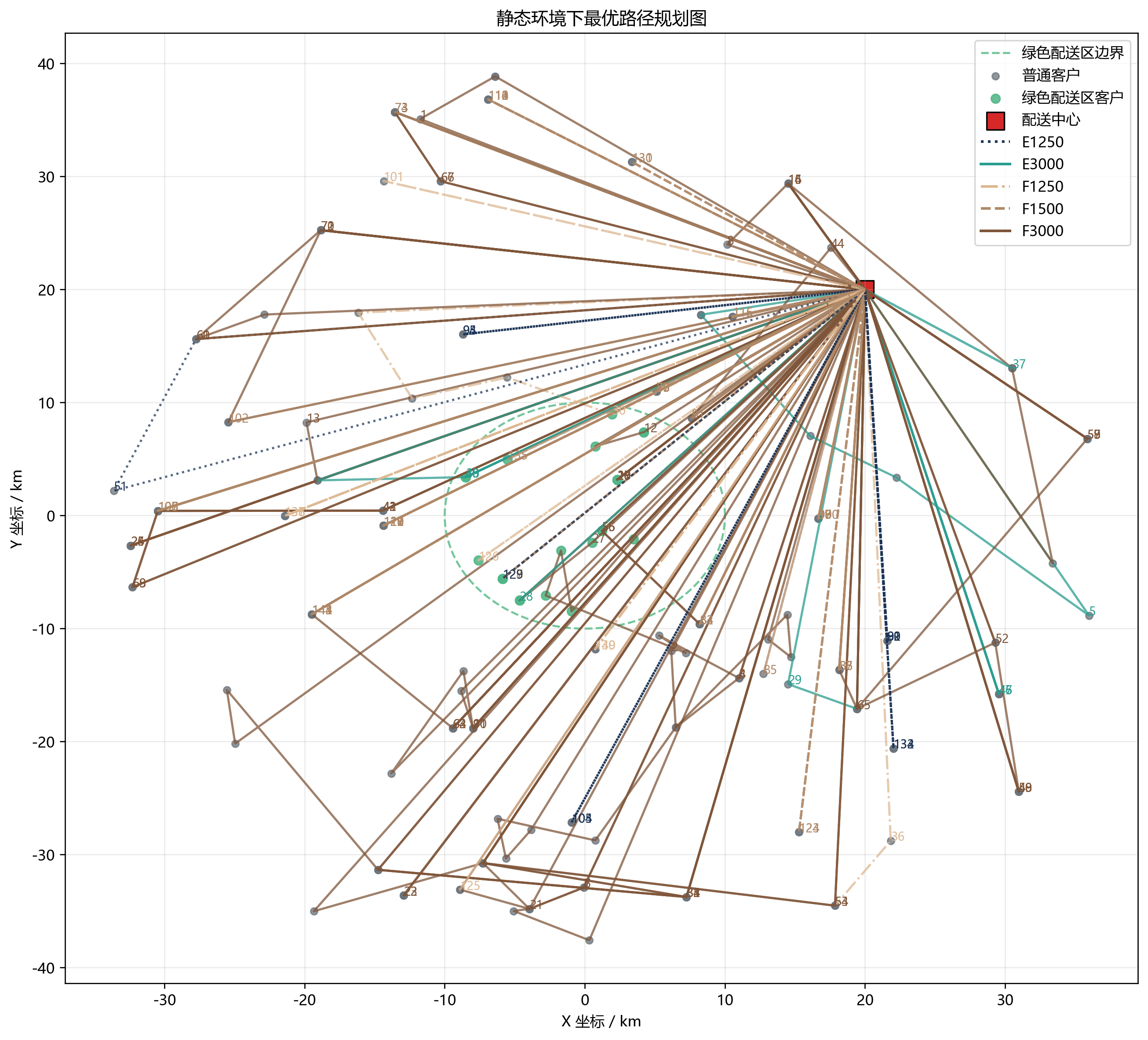
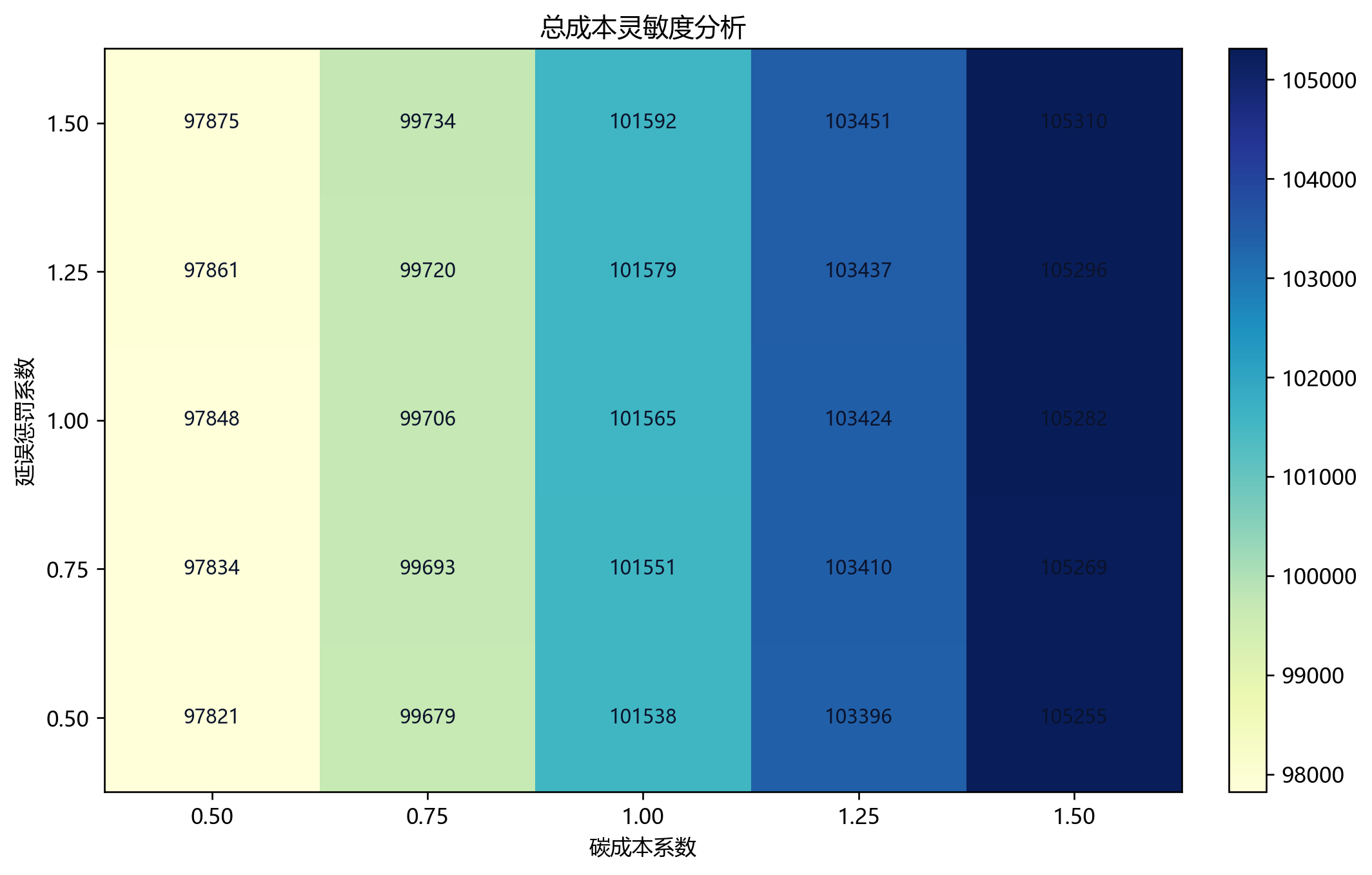
- 总成本:98378.44
- 综合目标:99184.13
- 总碳排放:10893.51 kg
- 总延误:119.72 min
- 准时率:97.98%
- 使用车辆数:143
- 未使用车辆数:42
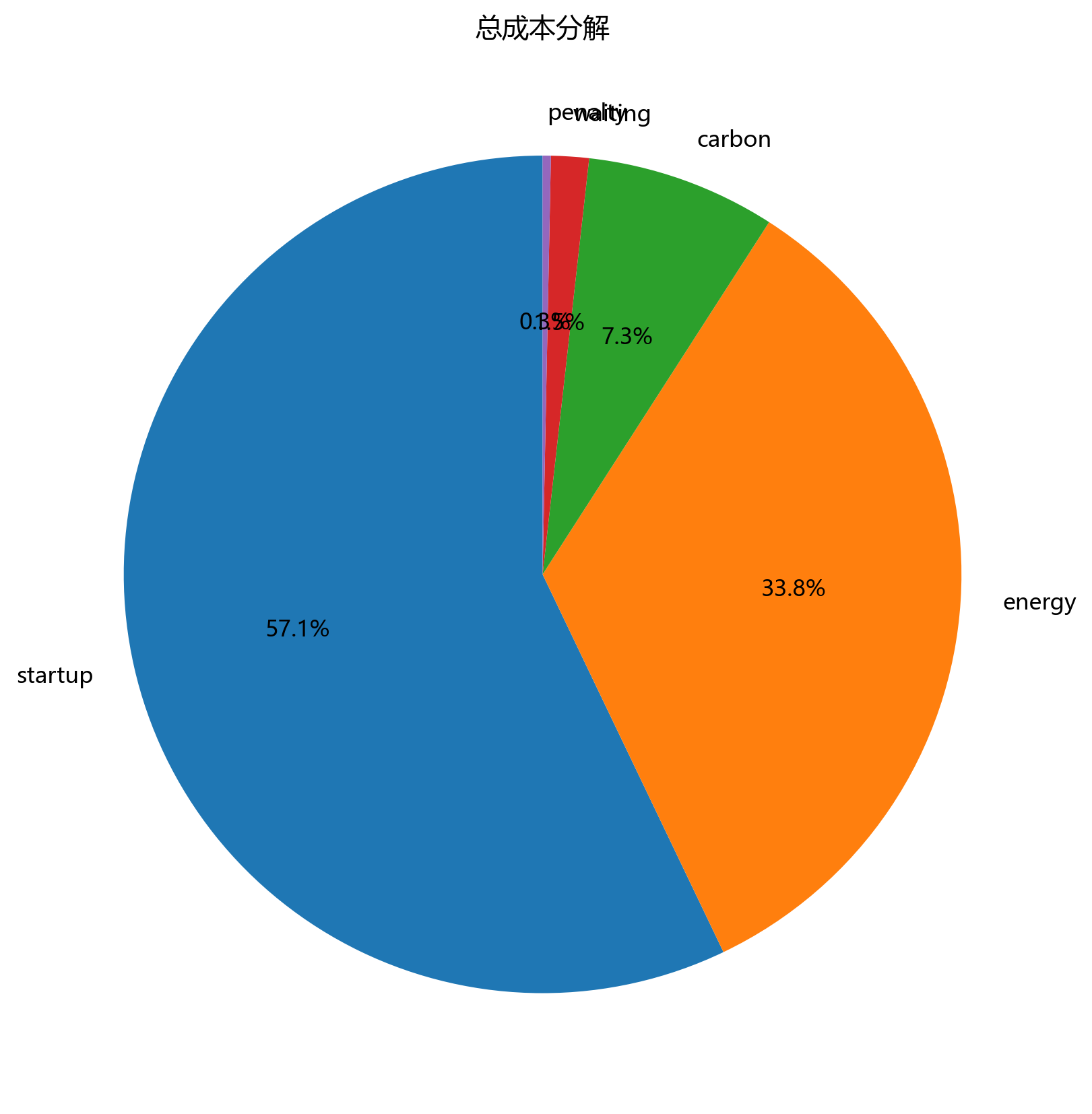
成本分解最能说明这套方案在"怕什么":
| 成本项 | 金额 | 占比 |
|---|---|---|
| 启动成本 | 57200.00 | 58.14% |
| 能耗成本 | 32739.81 | 33.28% |
| 碳成本 | 7080.78 | 7.20% |
| 等待成本 | 1258.08 | 1.28% |
| 延误惩罚 | 99.77 | 0.10% |
这个表很值得细看。
第一,启动成本占比超过一半,说明当前方案里"启太多车"是最大的成本来源。
第二,延误惩罚几乎可以忽略,而等待成本明显更高,说明求解器更倾向于"早到等着",而不是"晚到挨罚"。
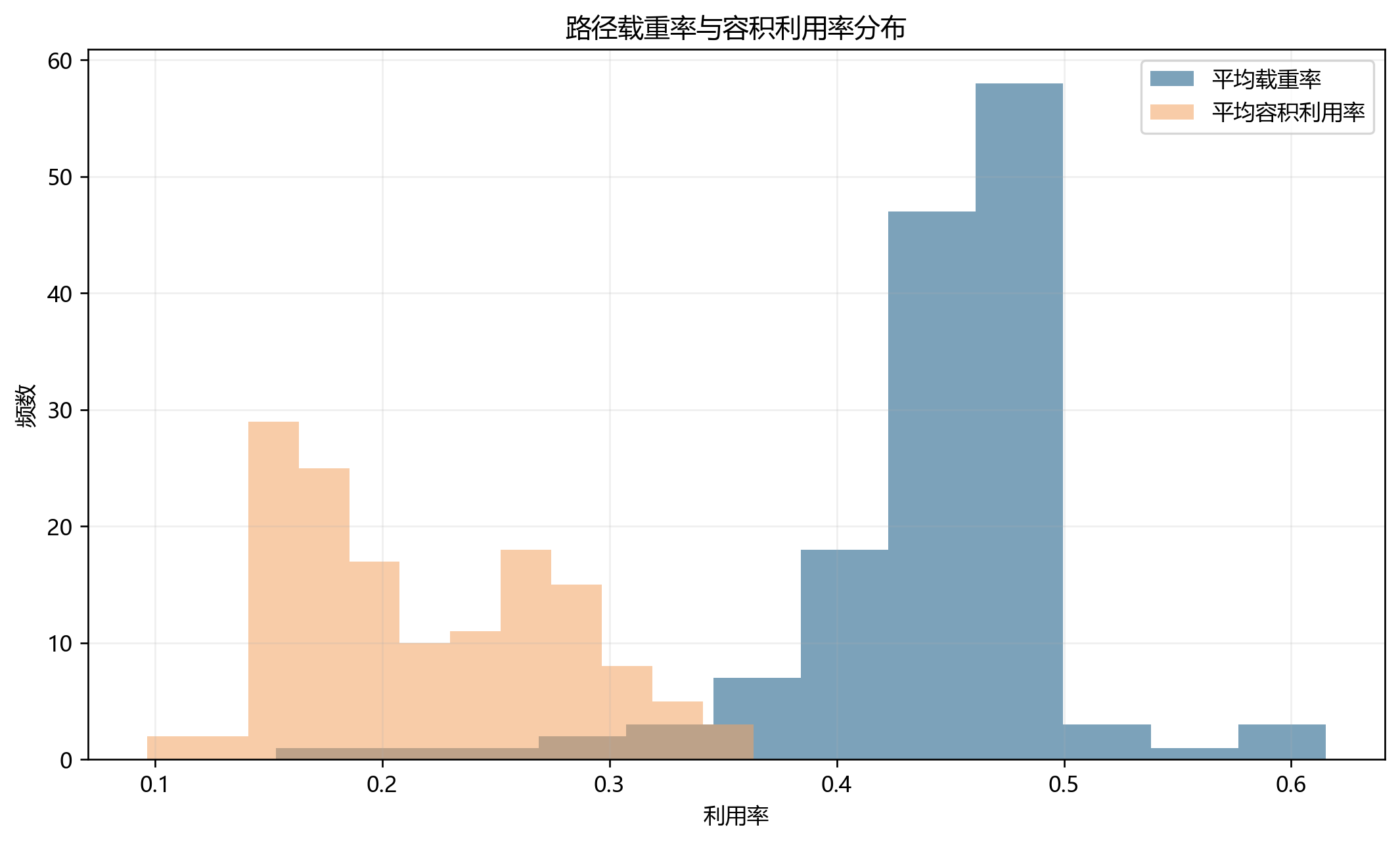
第三,既然平均每车只服务 1.73 个服务节点,那么高启动成本几乎是必然结果。这不是算法偷懒,而是前面拆点 + 时间窗 + 双容量共同作用的结果。
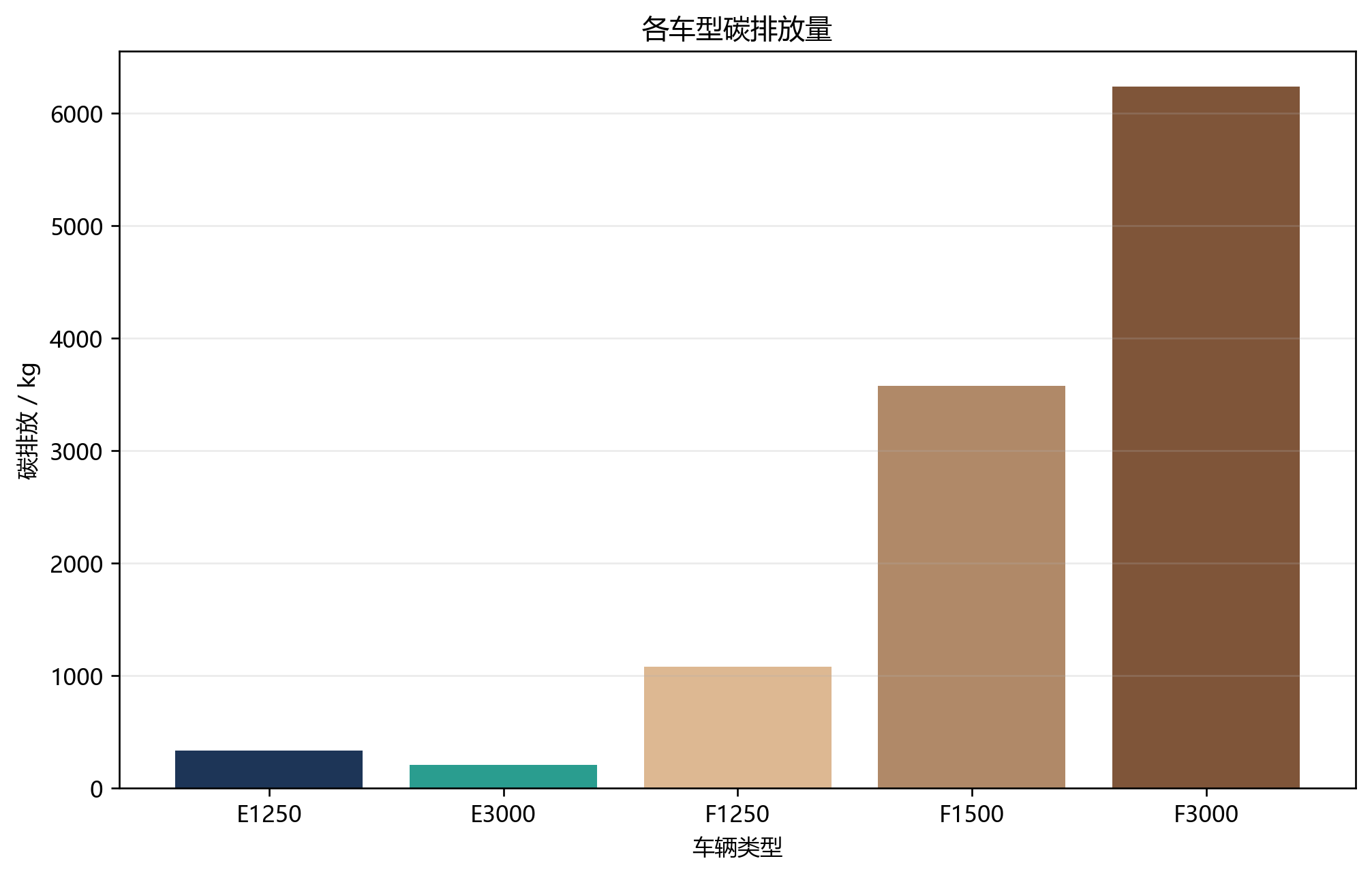
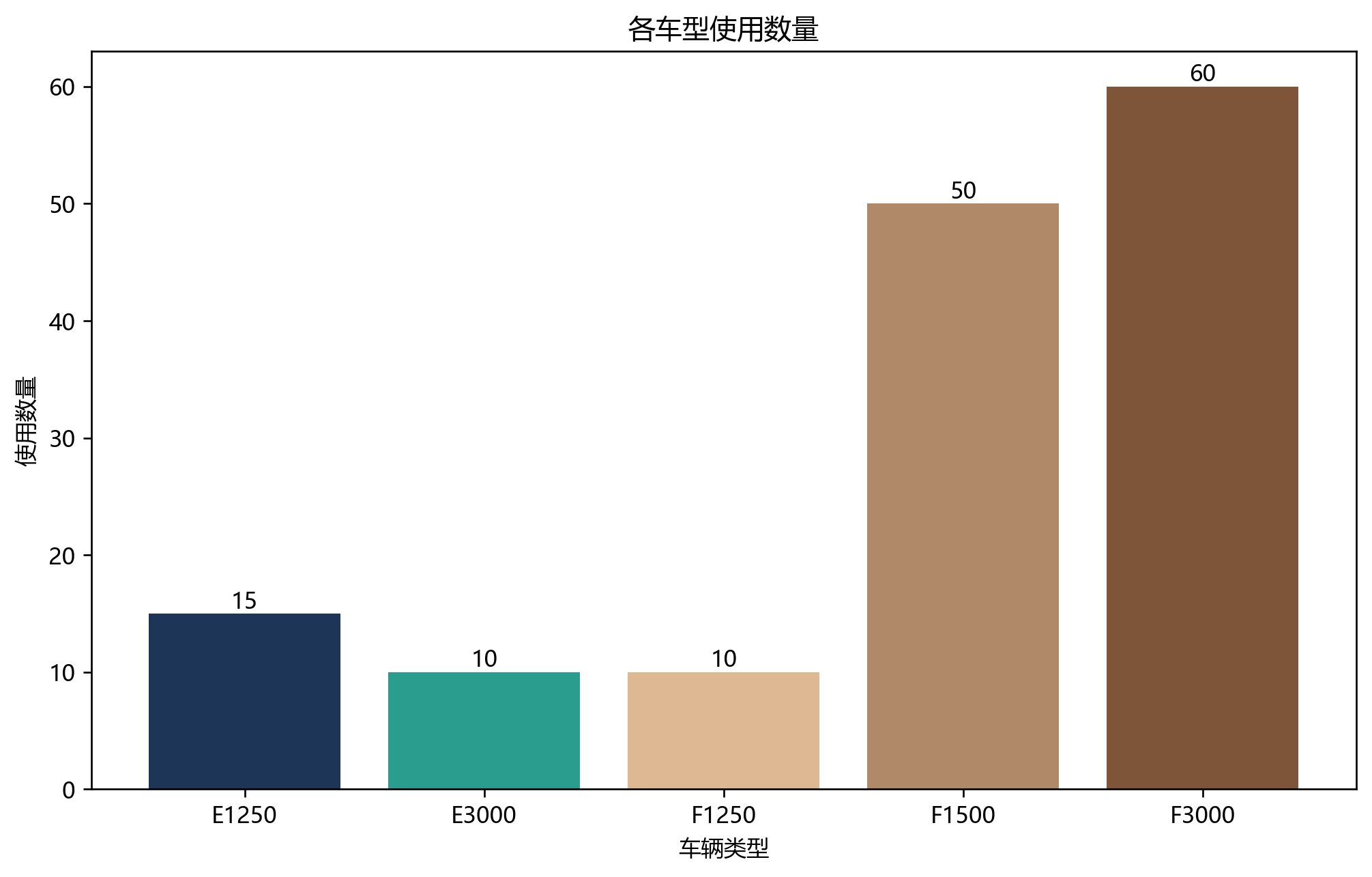
车型使用也很有意思:
- E1250:15 辆,全部用满
- E3000:10 辆,全部用满
- F3000:60 辆,全部用满
- F1500:49 辆,几乎用满
- F1250:只用了 9 辆
这说明当前参数下,最不"划算"的其实是轻型燃油车。相比之下:
- F3000 扛大载重和多服务节点
- F1500 处理中等需求的碎片化客户
- 两类电动车全部被吃满,说明它们在能耗/碳排/区域适配上都很有价值
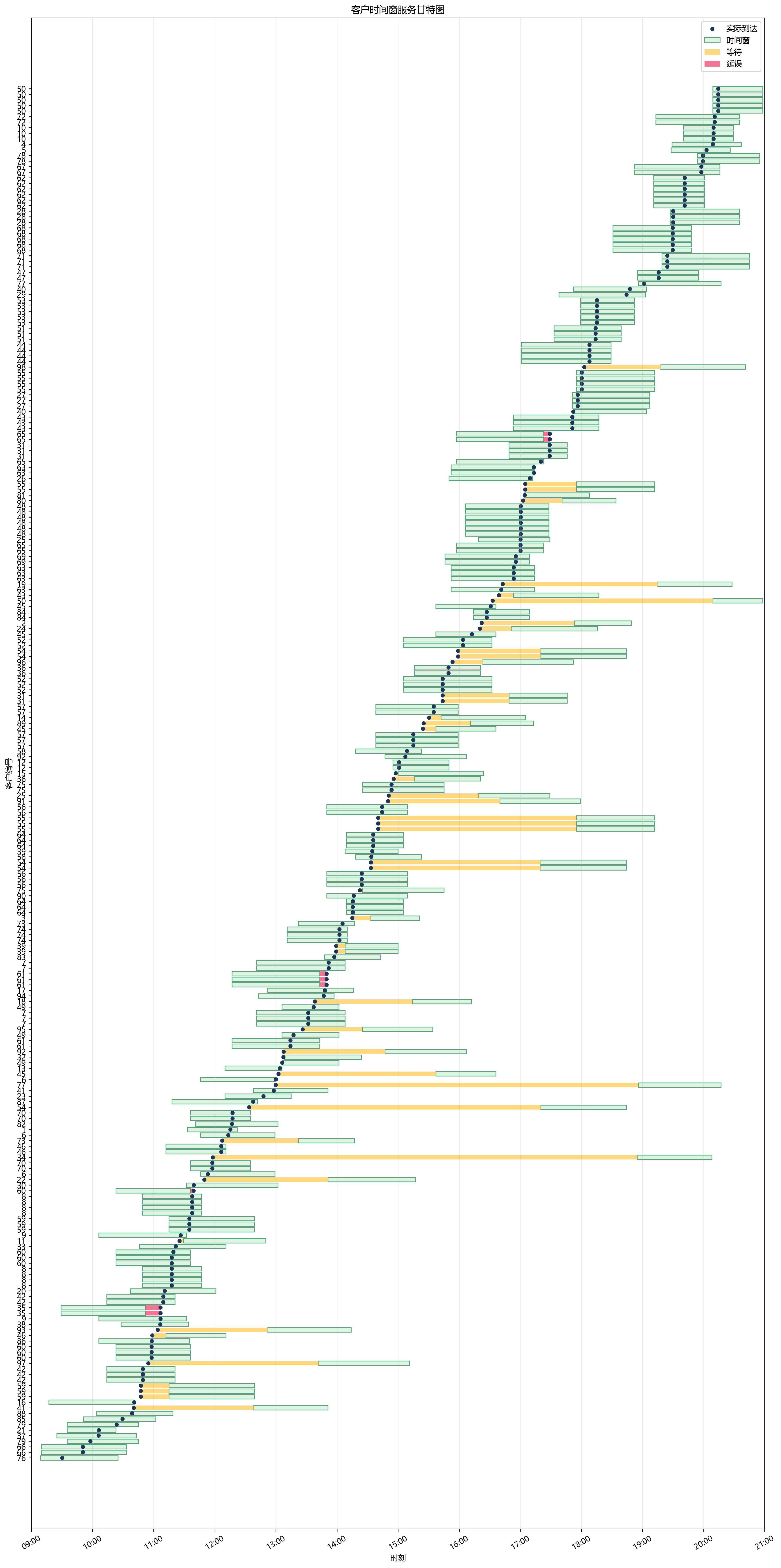
再看服务水平:
- 247 个服务节点里,只有 5 个晚到
- 49 个节点发生等待
- 平均等待 15.28 分钟
- 平均延误只有 0.48 分钟
这组数字很说明问题:模型把"迟到"尽量压到了极少数,把大部分时间窗冲突消化成了等待。
10. 这套静态方案稳不稳
项目里还做了两类补充分析。
第一是 Pareto 样本。pareto_front.csv 里保留了 7 个样本解,说明问题一不是单一最优点,而是存在成本、碳排和延误之间的小范围权衡。
第二是蒙特卡洛稳健性测试。monte_carlo_summary.csv 用随机速度跑了 60 次:
- 平均总成本:98523.78
- 标准差:72.28
这个波动其实很小。至少对这套方案来说,时变速度的随机扰动不会让结果失控。
第二问:加上绿色配送区限行政策后,模型怎么改
如果说第一问解决的是"基础路径怎么走",那第二问真正要回答的是:政策来了以后,这些路径要怎么重构。
题目给的政策很明确:
- 08:00-16:00
- 燃油车禁止进入绿色配送区服务
这条规则看起来像一个简单的 if,但实际上它约束的是"服务发生的时刻",不是"客户属于哪个集合"这么简单。
1. 先把政策约束写对
设客户 i是否位于绿色区由 gi表示,车辆动力类型由 pk 表示,服务开始时刻为 Bi,服务时间为 s。那么燃油车在绿色区的政策可写成:
其中 480 和 960 分别对应 08:00 和 16:00。
项目里判断违规的方式,不是抽象约束,而是直接计算服务区间和禁行时段的重叠分钟数:
当 ωi>0 时,视为违规。
python
overlap = max(
min(departure_min, config.policy.fuel_forbidden_end_min)
- max(service_start_min, config.policy.fuel_forbidden_start_min),
0.0,
)
return overlap > 1e-9, overlap这段实现非常"工程化"。它没有纠结大而全的数学表达,而是直接回答一个业务问题:某辆燃油车在某个绿色区客户上的服务,有没有压到禁行时段。
2. 第二问的求解器为什么切到了 Gurobi
问题二最有意思的地方,不是加约束,而是换了求解方式。
从代码结构看,项目这里用的不是问题一那种直接在全量路径空间里搜索,而是更像一个"候选路径生成 + 主问题选择"的 route-based 模型。其主问题可以写成:
约束包括:
每个客户必须被覆盖一次。
每种车型的使用数不能超过车队上限。
如果某条候选路径在政策下不可行,就不允许被选中。
这就是为什么第二问特别适合 Gurobi。它擅长的不是凭空"发明路径",而是对一批候选路径做全局选择。项目里也确实是这么干的:先根据聚类和 warm start 生成候选路线,再由 Gurobi 解一个主问题。
从 gurobi_solver.py (line 87) 的实现能看得很清楚:
python
for customer_id in self.problem.customer_ids:
model.addConstr(gp.quicksum(covered_vars) == 1)
for vehicle_type in self.vehicle_types:
model.addConstr(gp.quicksum(type_vars) <= int(vehicle_type.count))
for candidate in candidates:
eligible = 1 if (not self.policy_active or candidate.policy_feasible) else 0
model.addConstr(x[candidate.candidate_id] <= eligible)这其实就是一类很典型的 set partitioning / set covering 风格主问题。
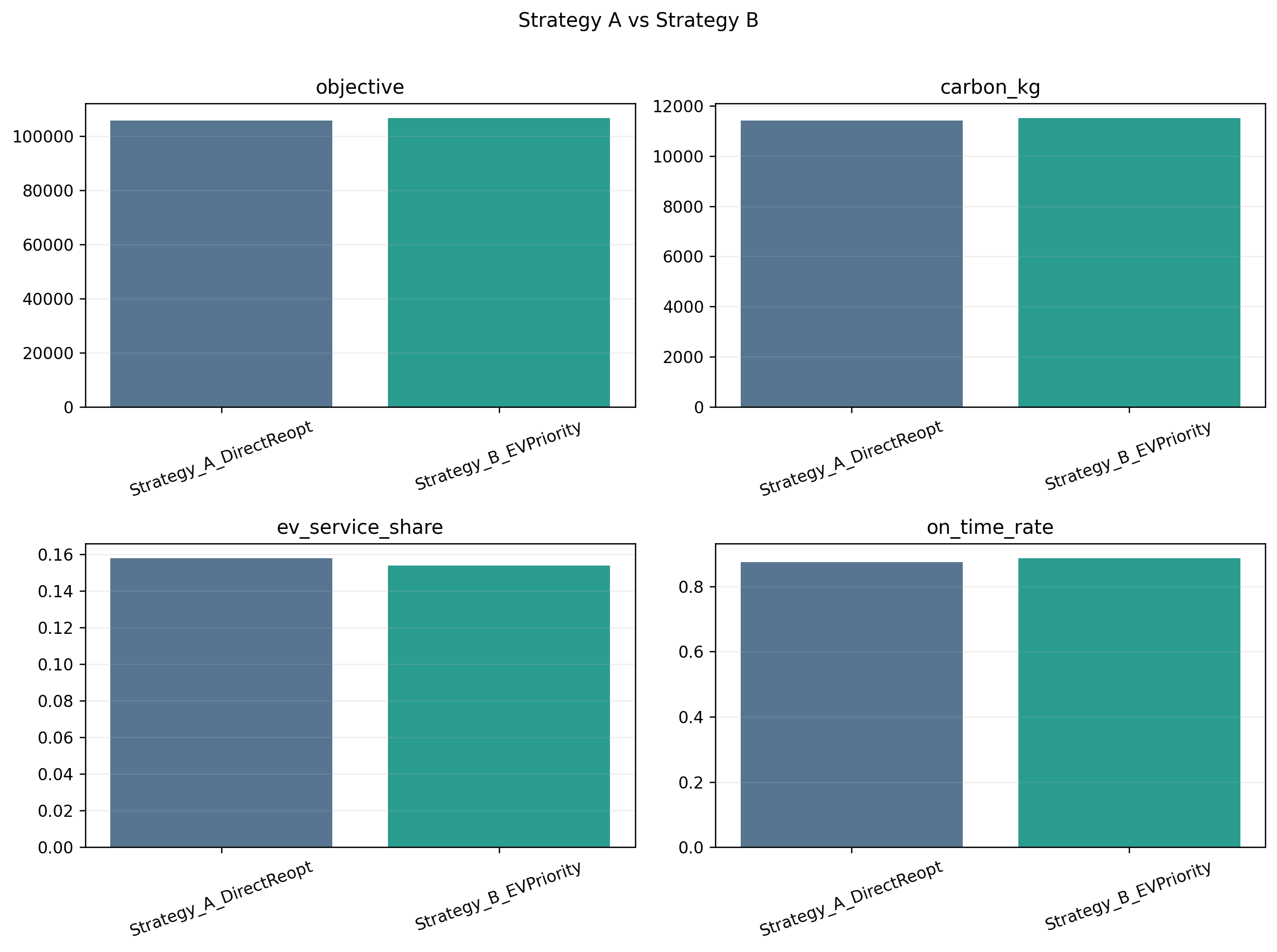
3. 问题二不是"把燃油车都换成电动车"
这是我看完结果以后觉得最值得说的一点。
直觉上,绿色区限行一来,车型结构应该明显向电动车倾斜。但这份项目输出给出的结果更微妙。
当前 outputs/02_problem2_policy 中,最优策略是:
- Strategy_A_DirectReopt
- 目标值:105741.80
备选策略 Strategy_B_EVPriority 的目标值是:
- 106726.30
也就是说,更激进地偏向电动车,并没有得到更优结果。
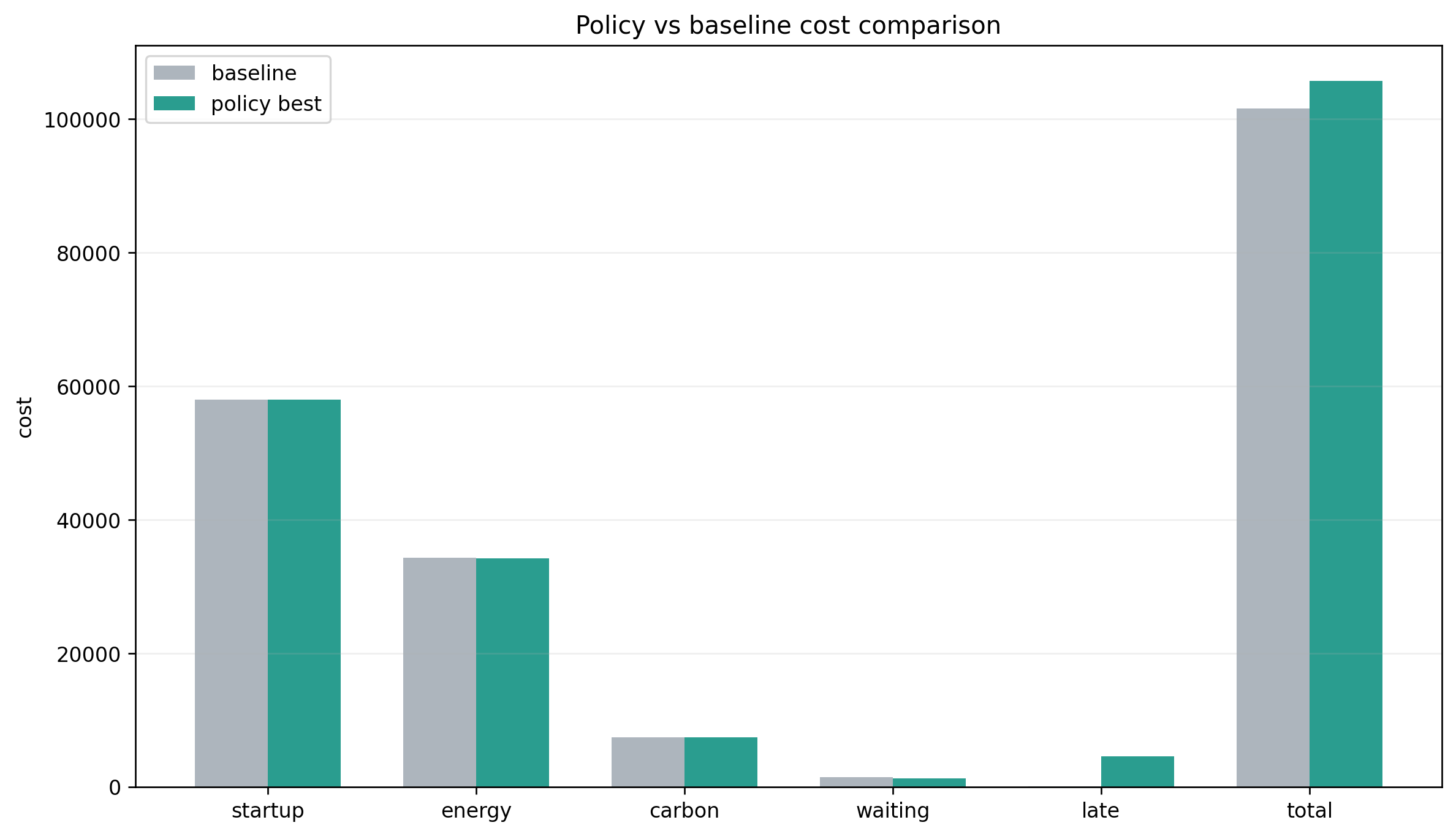
和问题一基线相比,最优政策方案的变化是:
- 总成本 +4176.74
- 碳排放 -25.68 kg
- 总里程 -28.12 km
这组数字其实很有意思。它说明政策约束并没有把系统直接推向"更长路、更高碳"的方向,反而在现有解里通过更精细的路径重排,换来了一点碳排下降和里程下降。
但代价也很明显:
- 基线准时率:0.9636
- 最优政策方案准时率:0.8745
也就是说,这个项目当前权重设置下,问题二更像是在用一部分服务水平换政策适应性与综合目标改进。
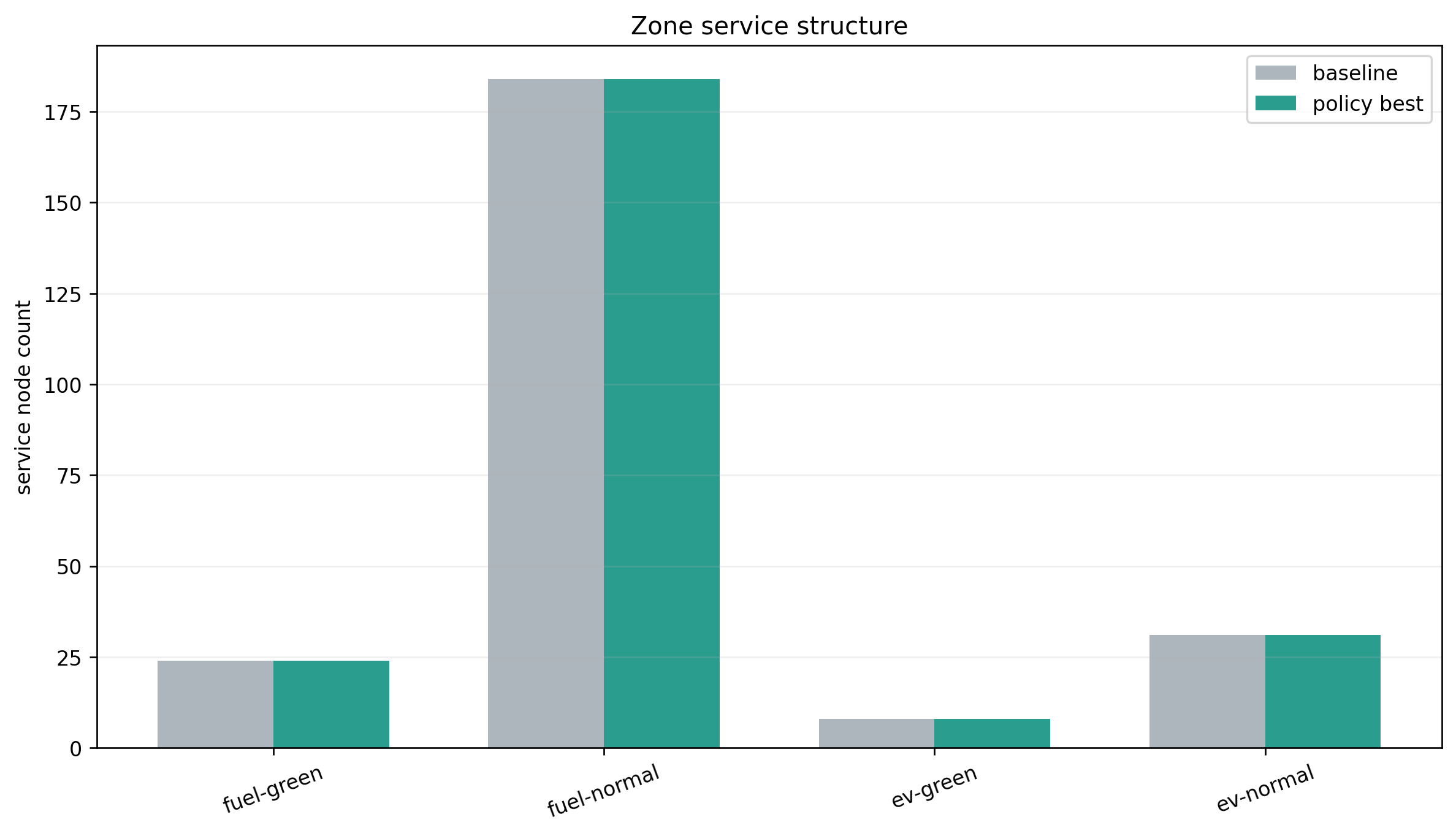
4. 真正发生变化的,是时序和分组,而不是大换车
更有意思的是,当前结果里车型使用数量几乎没有大变化:
- 基线:燃油 120 条路线,电动 25 条路线
- 政策后:燃油 120 条路线,电动 25 条路线
甚至绿色区服务结构也没有出现"全面电动化":
- 绿色区由电动车服务:8
- 绿色区由燃油车服务:24
但这些燃油车服务都发生在政策允许的时段内。
这其实揭示了第二问真正的难点:
它不是"车型替换题",而是"时序重构题"。
换句话说,这份结果告诉我,当前实例里最优策略不是大量换车,而是:
- 调整发车时刻
- 重排绿色区客户的服务顺序
- 改变局部客户分组
- 把本来可能压在禁行时段的服务,挪到允许区间
从这个角度看,第二问比第一问更像"在已有路径骨架上做精细重构"。
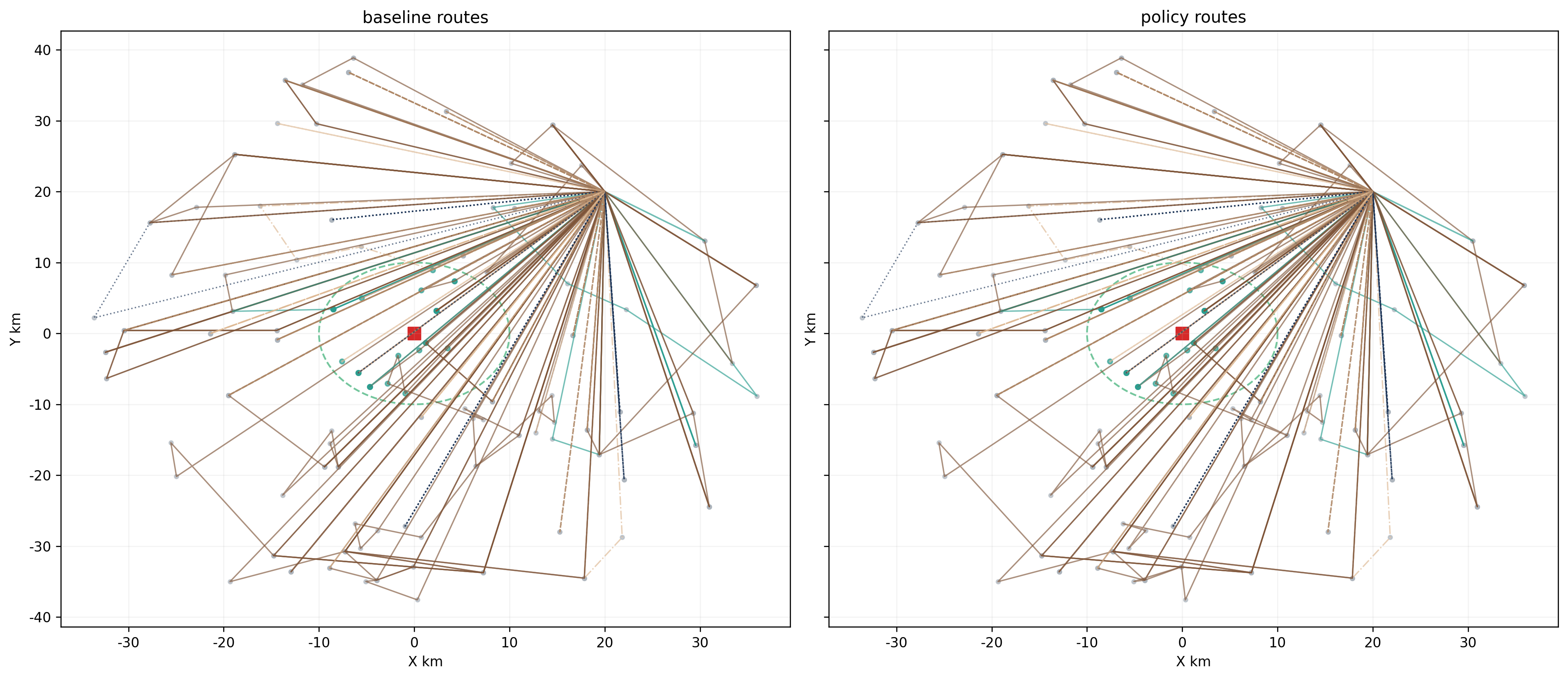
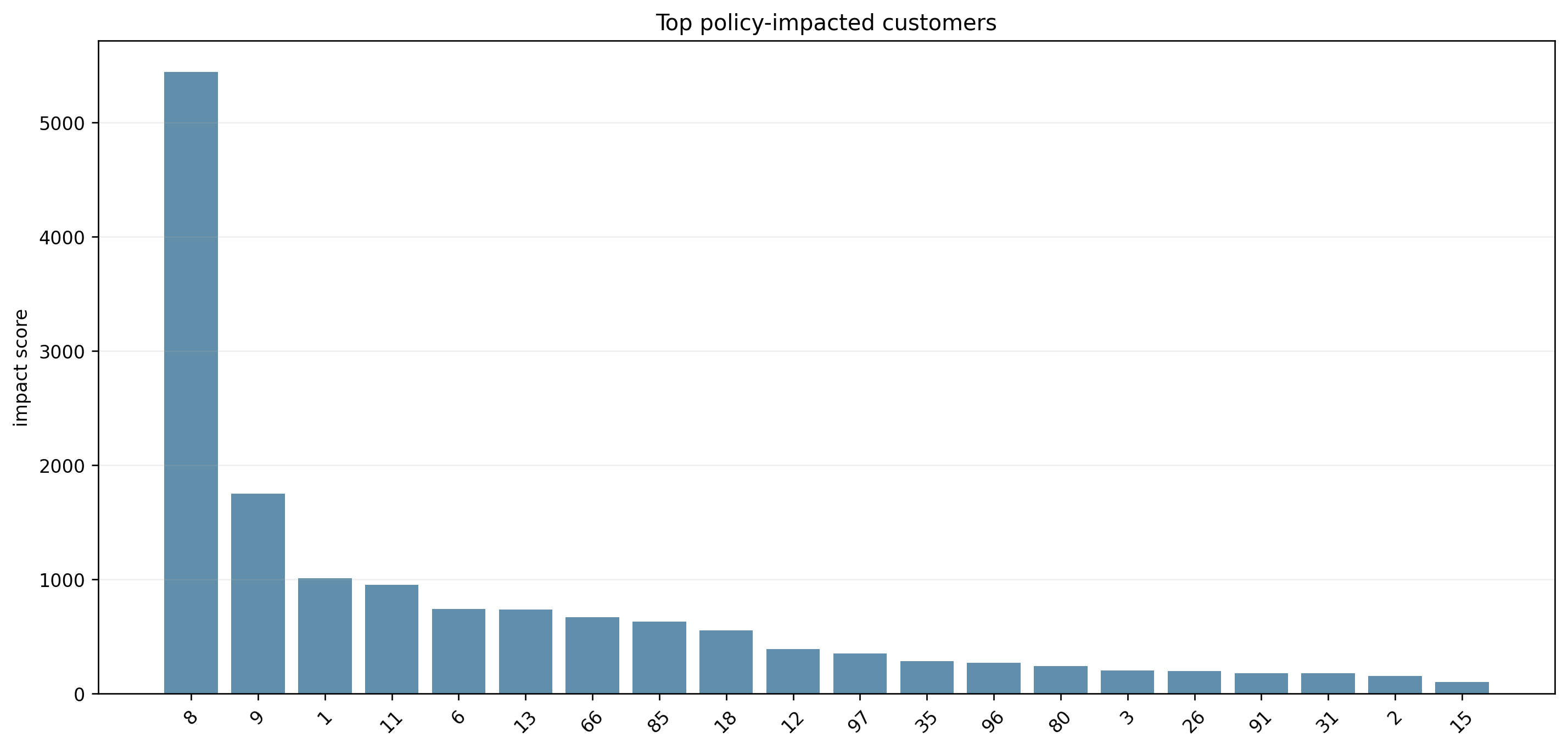
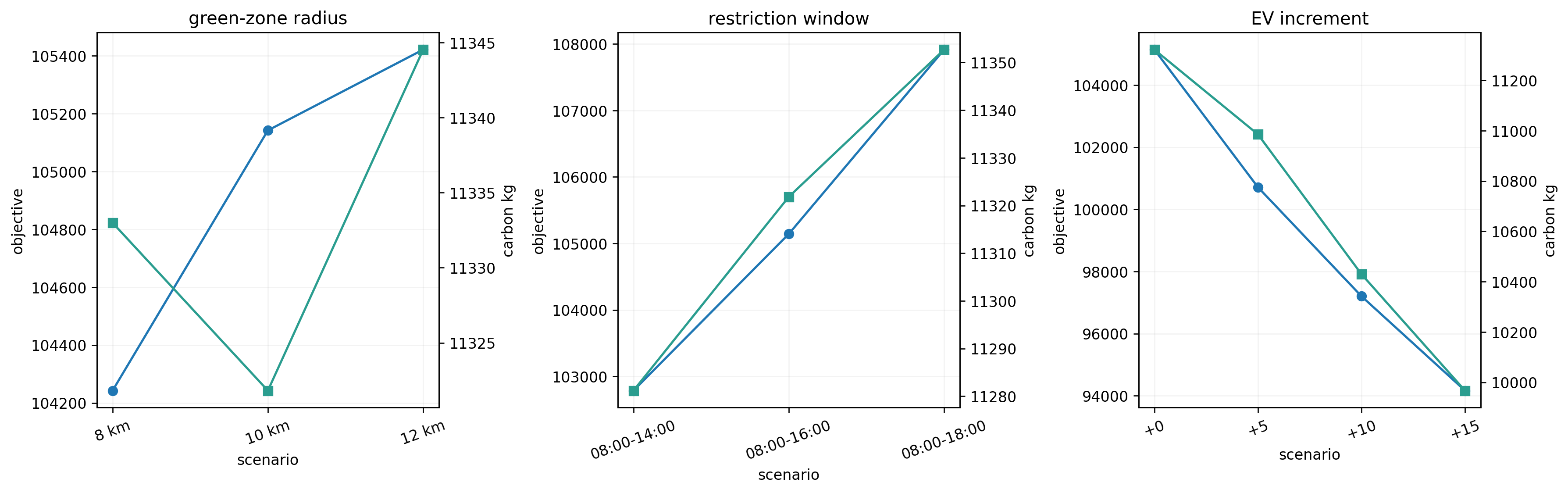
5. 哪些客户最受政策影响
customer_policy_impact.csv 给了很直观的答案。按影响分数排序,受影响最大的几个客户里,高需求的绿色区客户很靠前。
例如客户 8:
- 到达时刻变化约 +338.20 min
- 延误变化约 +2551.83 min
这说明政策冲击首先落在绿色区里需求大、窗口紧、原本服务链又比较集中的客户身上。
而 route_impact.csv 也能看到对应的路线层面变化:那些同时覆盖多个绿色区服务节点的燃油车路径,是重构成本最高的。
第三问:动态事件下,为什么必须做实时重调度
如果说前两问还是"离线优化",第三问就正式进入现实世界了。
现实配送不会乖乖按计划执行到底。题目列出的动态事件包括:
- 新增订单
- 订单取消
- 地址变更
- 时间窗调整
而项目实现又额外补了两类更贴近实际运行的扰动:
- 车辆故障
- 交通降速
到了这一步,问题已经不再是"有没有一条全局最优路径",而是:当系统被打断时,怎样在尽量少扰动原计划的前提下快速恢复可执行性。
1. 第三问不是从零开始,而是从问题二接着往下走
这一点非常关键。
03_problem3_dynamic/run_summary.json 里写得很清楚:
- baseline_source = problem2:Strategy_A_DirectReopt
也就是说,动态重调度不是另起炉灶,而是直接把第二问的最优政策方案当成动态起点。这种递进关系非常合理:
- 第一问:静态基础路径
- 第二问:政策约束下的路径重构
- 第三问:在政策可行方案上做动态响应
这也是我觉得这个项目结构很完整的原因之一。
2. 动态问题最难的不是"再算一遍",而是"不能全都重来"
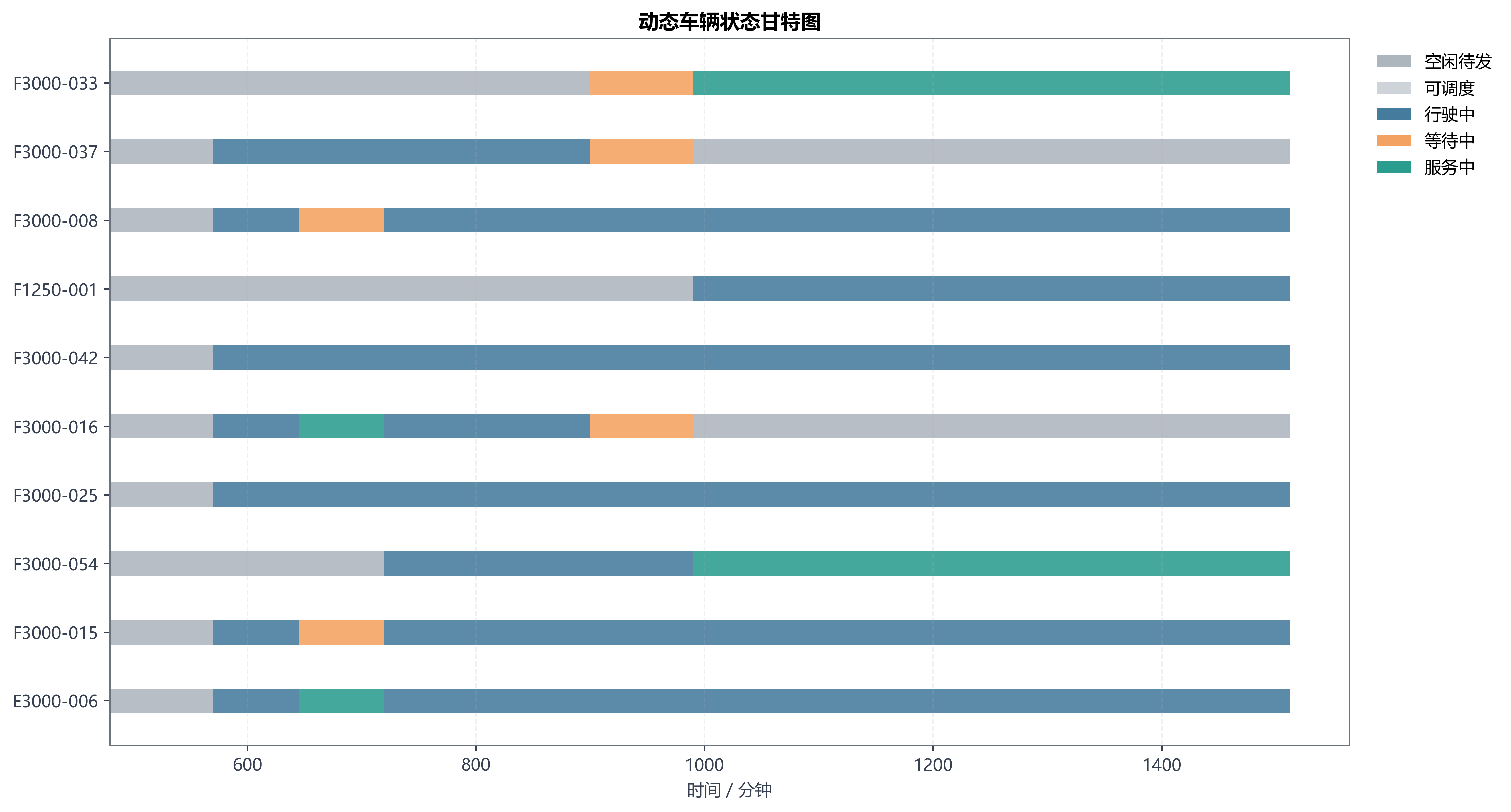
项目里这部分做得最像工程系统的是 state_manager.py。
它没有把动态调度当成"每来一个事件就重新跑一次静态优化",而是显式维护了:
- 车辆当前状态
- 已服务客户
- 待服务客户
- 已锁定前缀路径
- 当前可修改路径段
- 车辆当前位置和可用时刻
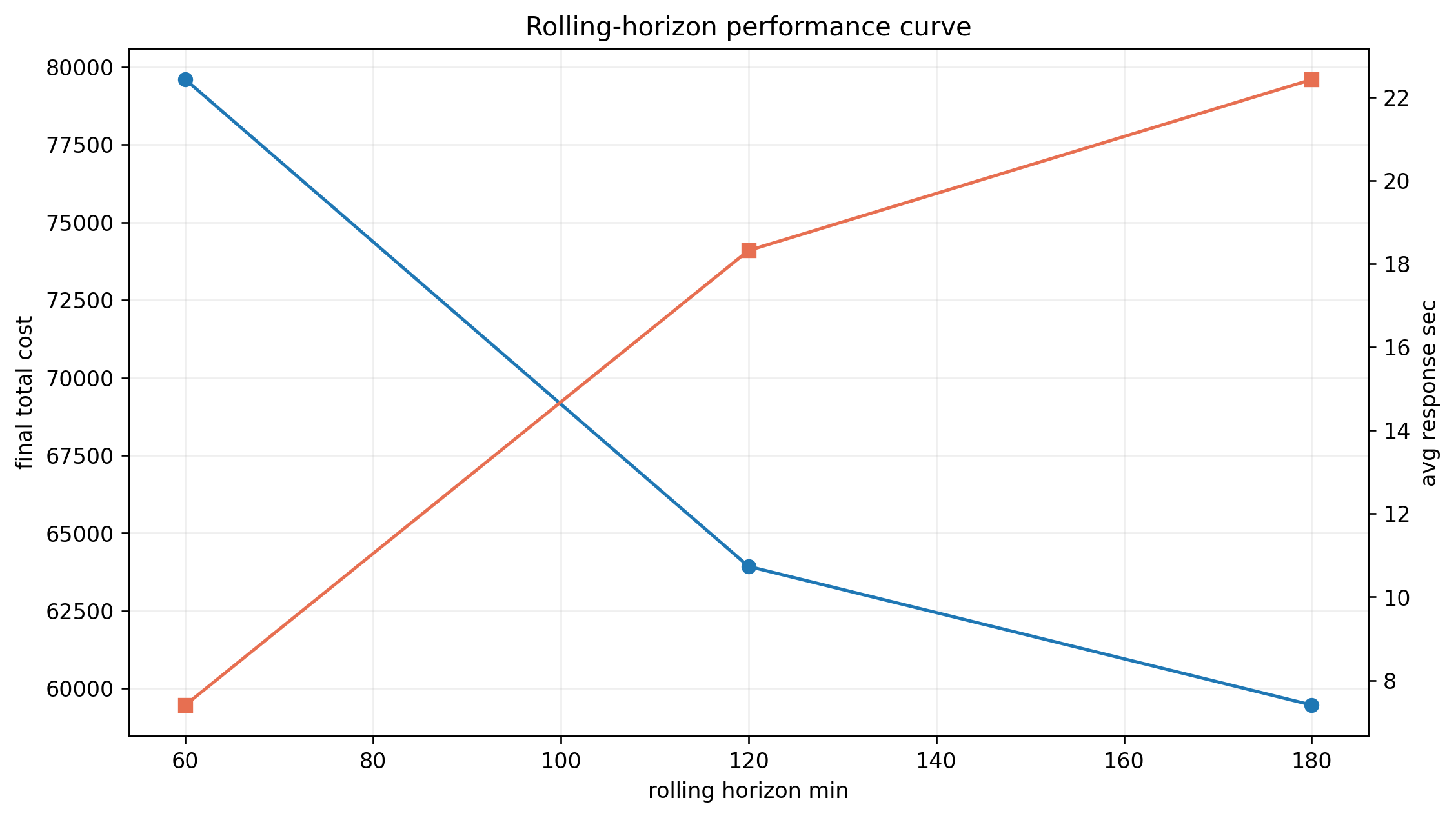
这意味着第三问真正优化的,不是整天的全量路径,而是一个滚动窗口内、可修改范围内的局部问题。默认滚动窗口是 120 分钟,候选客户上限 36,候选车辆上限 14。
这个思路很重要。因为动态调度里最大的忌讳就是"为了修一个局部问题,把整个系统全打乱"。
3. 第三问为什么用 NSGA-II
动态事件发生后,项目里的目标不再只有一个"总成本最低",而是四目标同时考虑:
其中:
- C(π):总配送成本
- E(π):总碳排放
- L(π):时间窗违约损失
- S(π):稳定性损失
这里的第四项最有意思。因为动态调度里,方案"变得太多"本身就是成本。
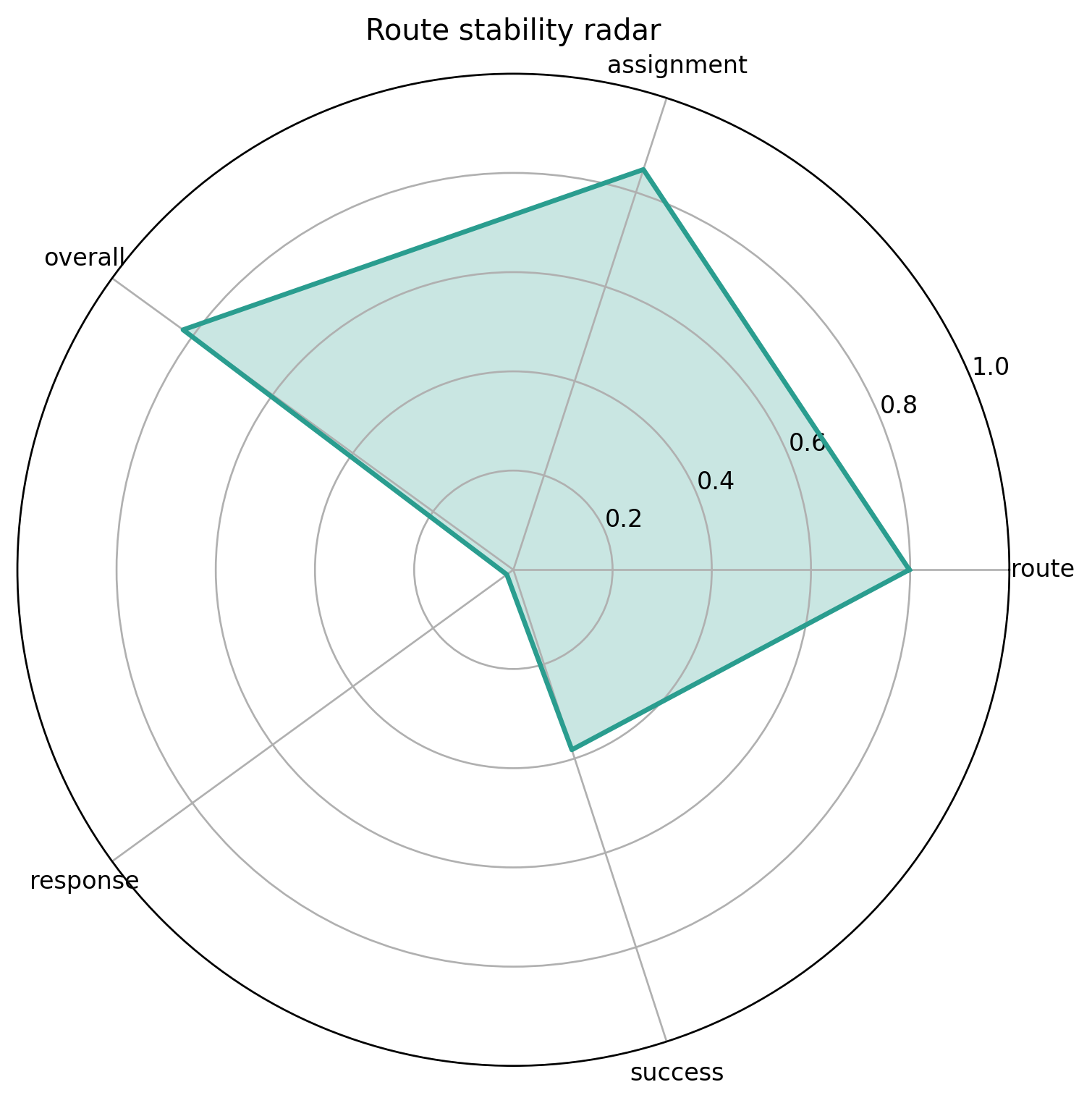
项目用的稳定性定义来自 stability_analyzer.py (line 37):
其中:
- Rs:路径稳定性
- As:分配稳定性
- ρseq:序列变化比例
- ρveh:车辆变更比例
最终优化里用的是稳定性损失:
这套定义的含义很实在:
我不是只问"新方案便不便宜",还问"它把多少车改了、改了多少客户、改动是不是过于剧烈"。
代码里这部分也写得很直白:
python
overall_stability = (
0.35 * route_stability
+ 0.30 * assignment_stability
+ 0.20 * (1.0 - sequence_change_ratio)
+ 0.15 * (1.0 - vehicle_change_ratio)
)
stability_loss = 1.0 - overall_stability4. NSGA-II 优化的不是路径本身,而是"调整方式"
在 nsga2_optimizer.py (line 1) 里,染色体设计不是传统"完整路径编码",而是:
- 待优化客户的优先级顺序
- 客户偏好的车辆选择
也就是说,算法真正做的是:
在当前状态约束下,决定"谁优先插、插给谁、改多少"。
解码后形成的目标元组是:
python
objectives = (
total_cost,
total_carbon,
time_window_loss,
stability_loss,
)这比把整条路径硬编码进染色体更适合动态场景,因为很多前缀已经锁死,真正能优化的只是剩余尾段。
5. 动态事件是怎么被组织起来的
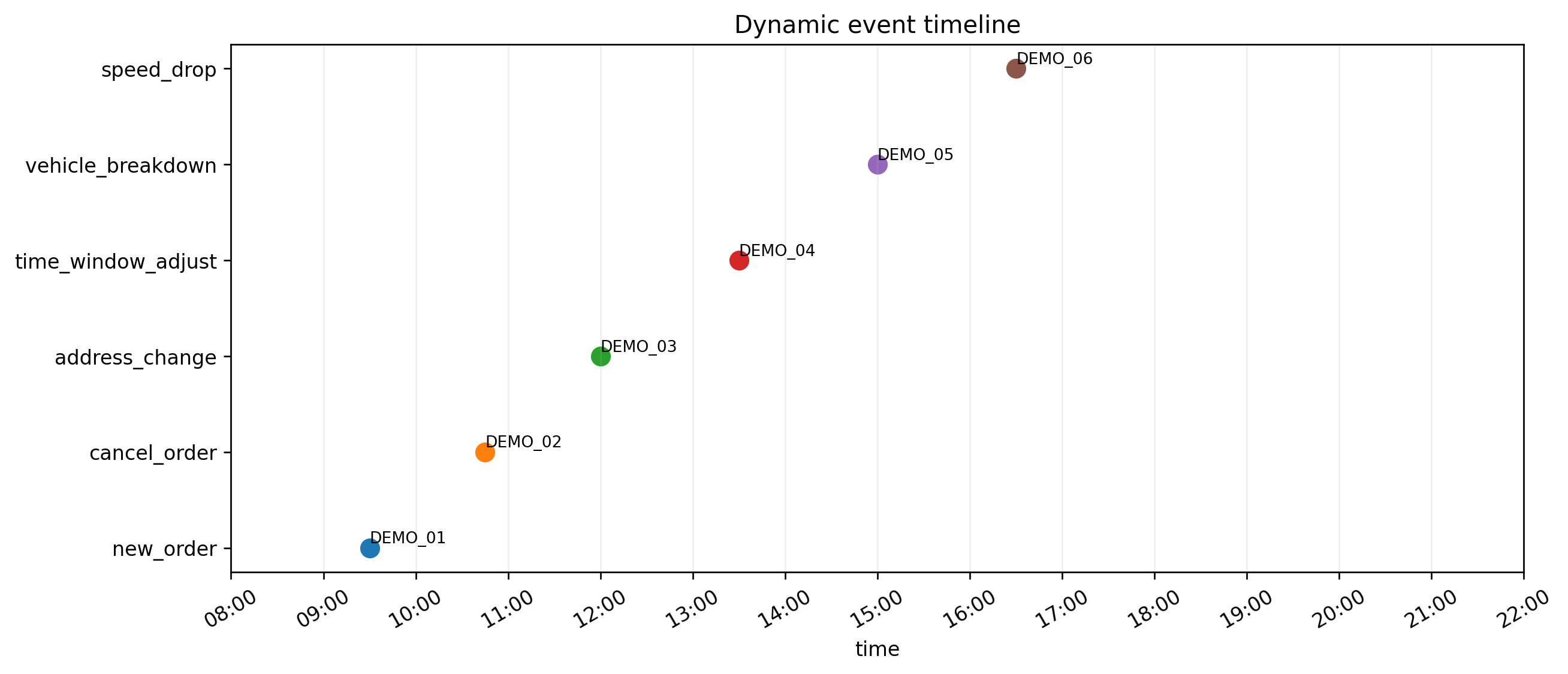
项目里内置了 6 类场景,事件时刻也明确写在配置里:
- 09:30:新增订单
- 10:45:订单取消
- 12:00:地址变更
- 13:30:时间窗调整
- 15:00:车辆故障
- 16:30:交通降速
event_generator.py 会生成单独场景,也会拼成一个综合演示场景 Scenario_Demo_All。这点很好,因为博客里既可以讲单个事件,也可以讲一整天被连续扰动的过程。
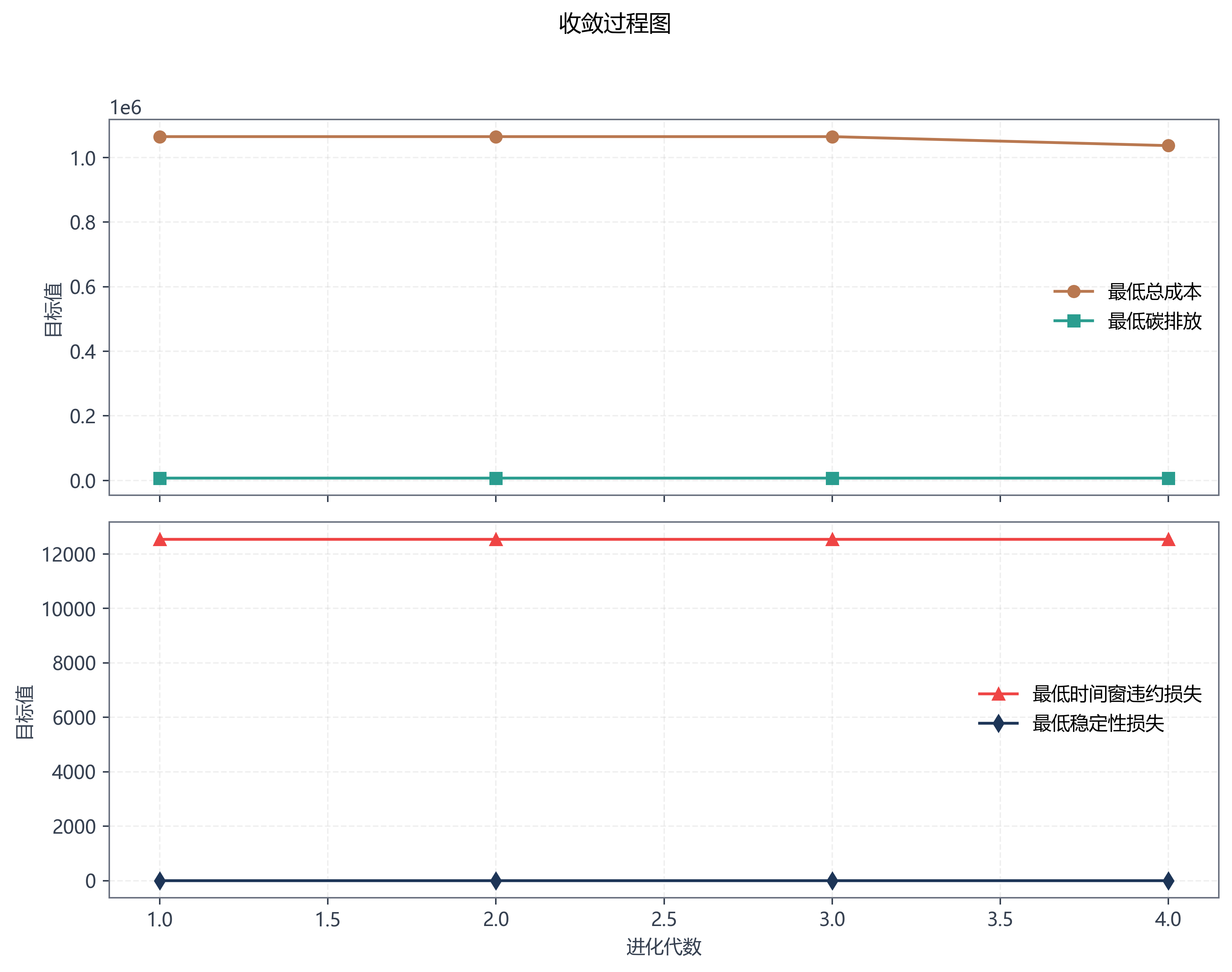
6. 第三问最后跑出了什么
综合演示场景里,一共发生了 6 次事件。现有输出给出的几个核心指标是:
- 平均响应时间:1.4595 s
- 平均 Pareto 前沿规模:6.83
- 平均总体稳定性:0.9537
- 平均修改路径数:8.83
- 平均重分配客户数:5.67
这几个数放在一起,基本可以概括第三问当前方案的特点:
大多数事件都能比较快地做出局部响应,而且整体扰动控制得还不错。
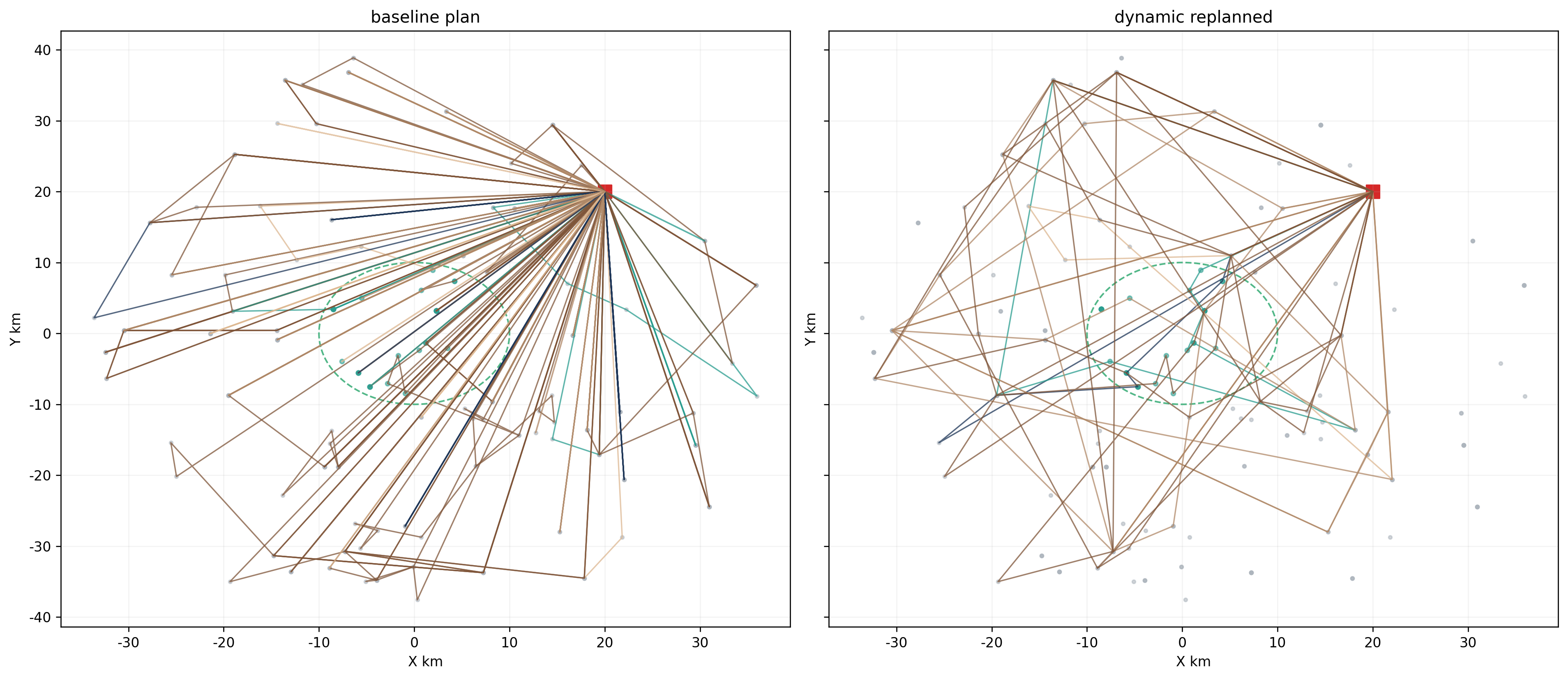
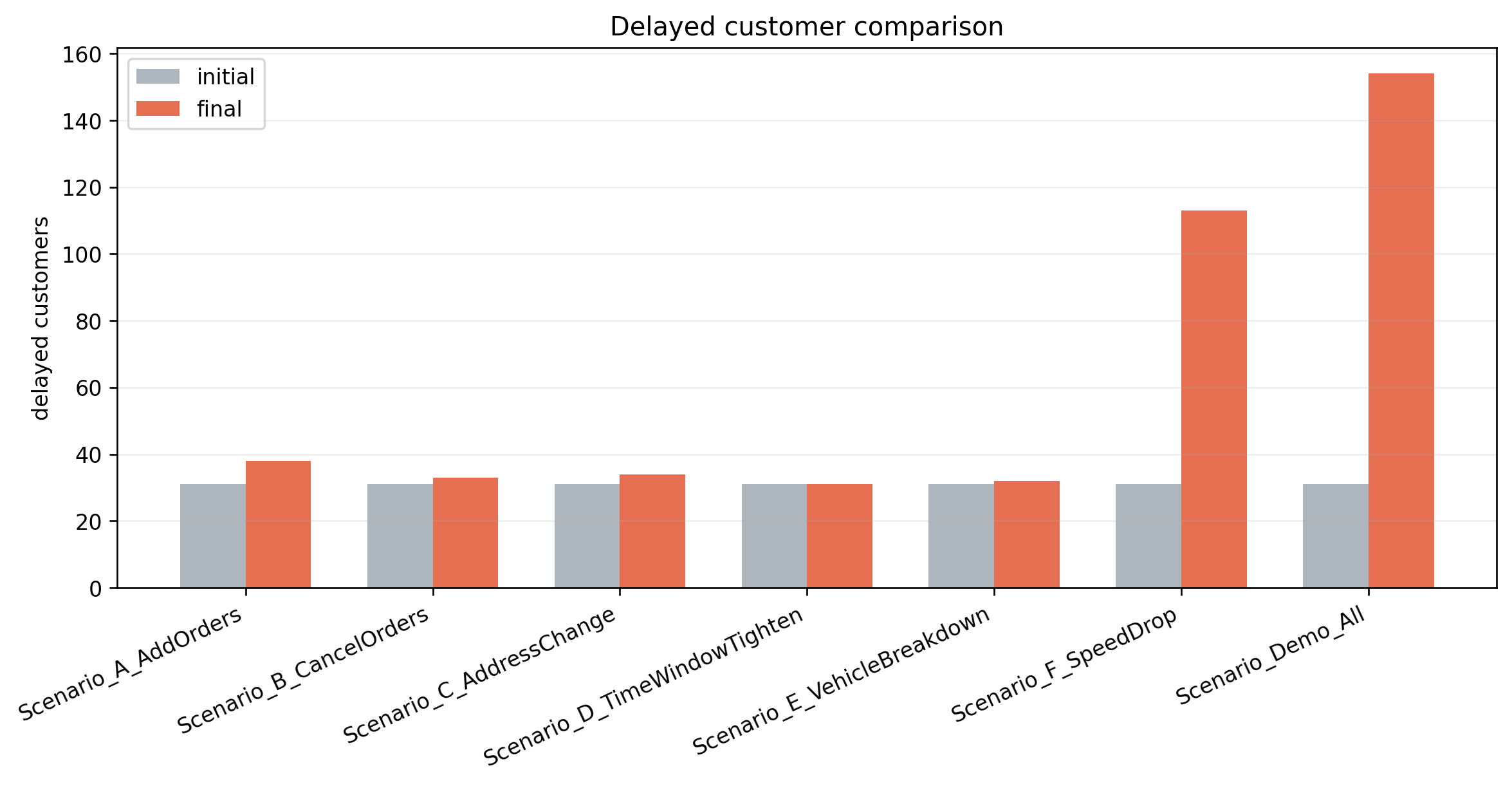
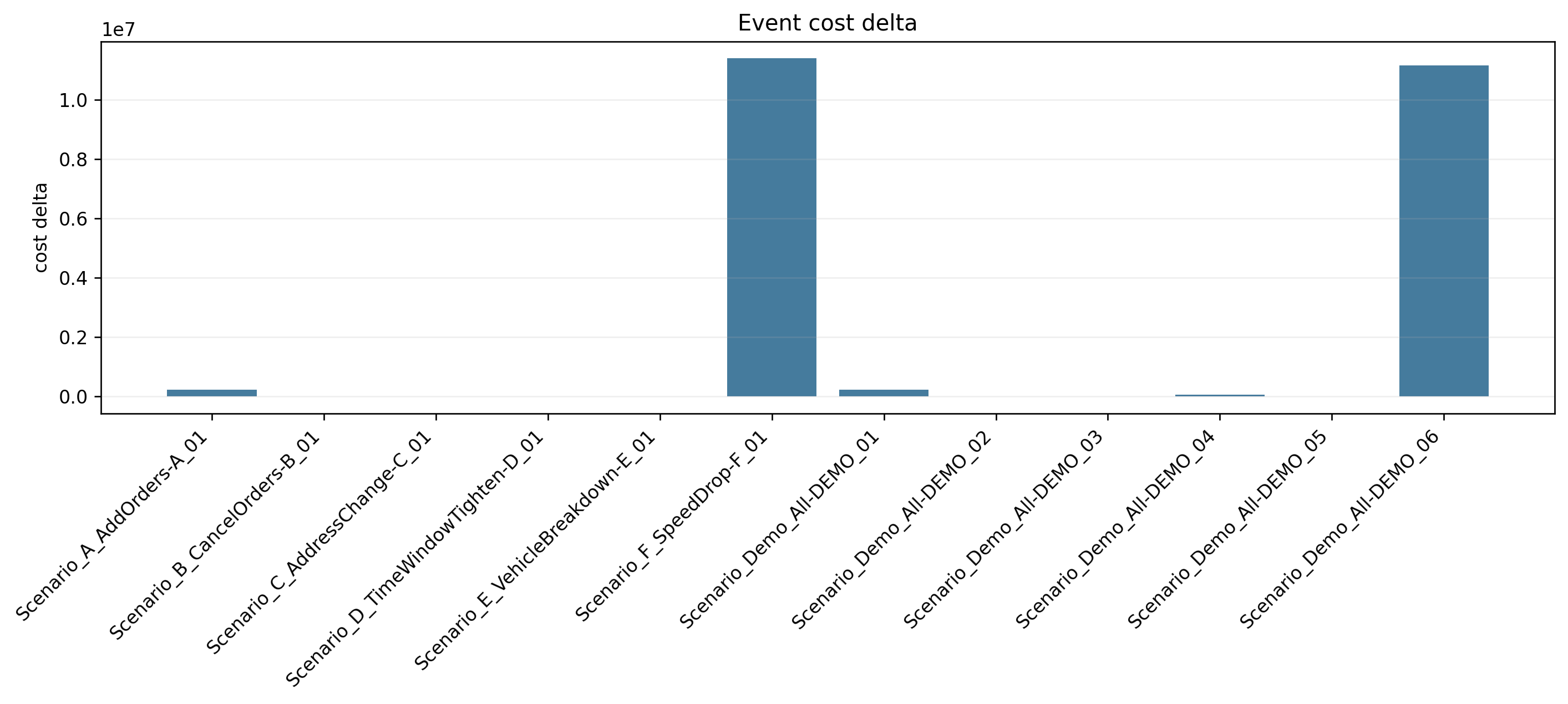

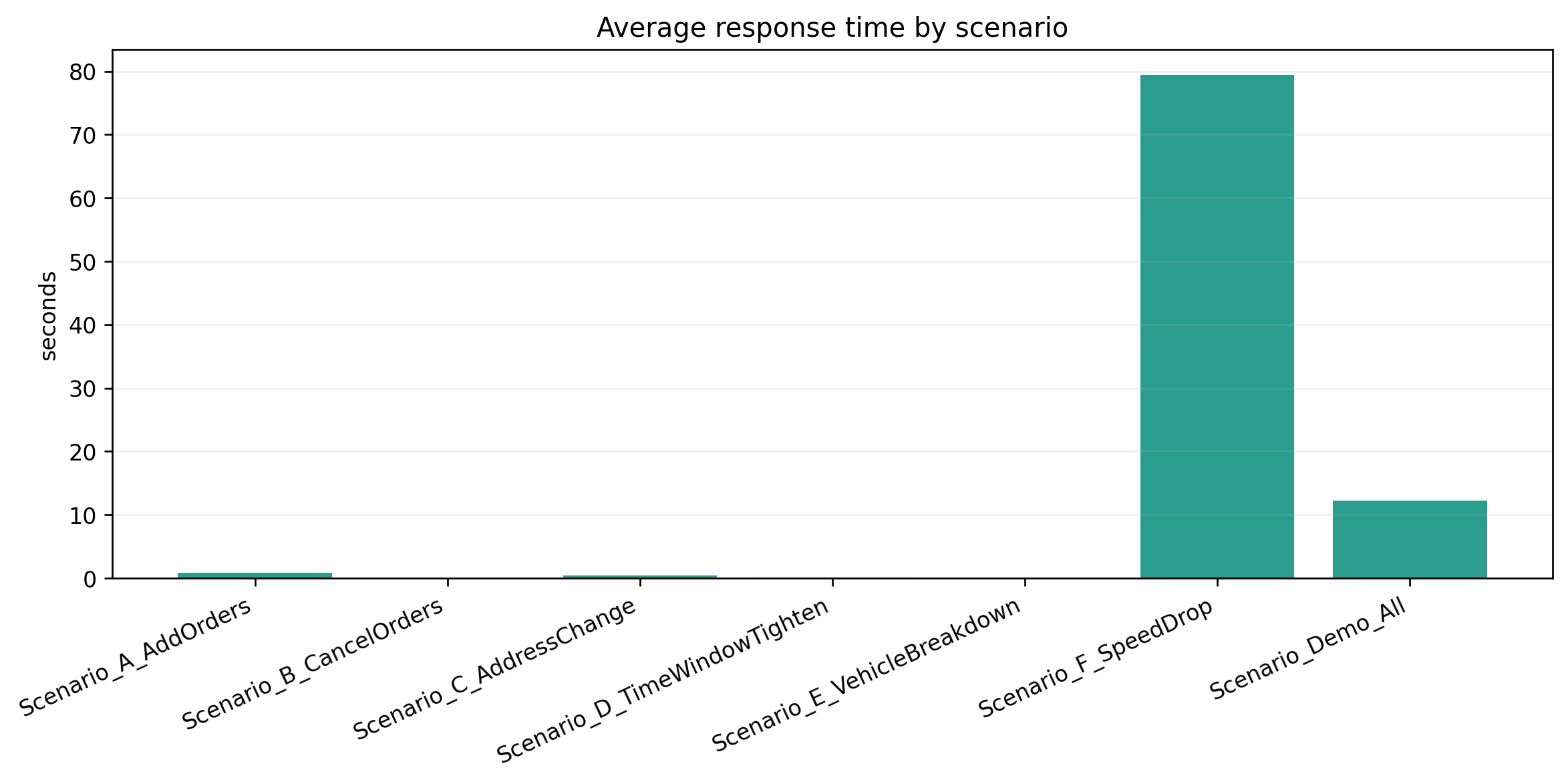

如果把不同事件拆开看,会更有意思:
| 事件类型 | 响应时间 | 修改路径数 | 重分配客户数 | 总体稳定性 | 观察 |
|---|---|---|---|---|---|
| 新增订单 | 0.84 s | 7 | 10 | 0.9597 | 局部扰动明显,但仍能较快修复 |
| 订单取消 | 0.02 s | 3 | 0 | 0.9830 | 最容易处理,基本是删减式调整 |
| 地址变更 | 0.42 s | 12 | 8 | 0.9401 | 对局部路径结构影响较大 |
| 时间窗调整 | 0.16 s | 8 | 5 | 0.9581 | 主要改时序,扰动中等 |
| 车辆故障 | 0.04 s | 3 | 2 | 0.9813 | 局部替换能力不错 |
| 交通降速 | 79.43 s | 25 | 121 | 0.0432 | 最困难,几乎是全局冲击 |
这张表基本把第三问的故事讲清楚了。
为什么取消订单最好处理
因为它通常只是把一部分待服务节点从未来计划里拿掉,不需要新增资源,也不一定需要改动很多路径。
为什么地址变更和时间窗调整会影响中等范围
因为这类事件通常只改一个或几个客户,但它们可能正好卡在路径中段,所以会牵连前后邻接关系。
为什么交通降速最难
这个结果我觉得特别真实。
交通降速不是改一个点,而是把一整段时间里的速度函数都压低了。它破坏的不是一条路线,而是很多路线的时间可行性。当前输出里:
- 响应时间升到 79.43 s
- 稳定性掉到 0.0432
- 重分配客户数达到 121
这说明在当前实现里,全局交通冲击远比局部订单事件更难吸收。这并不是坏结果,反而很真实:它告诉我们这套动态机制对局部扰动很强,但对系统性冲击还不够稳。
7. Pareto 前沿在第三问里不是摆设
动态问题里,多目标才真正有意义。
比如 representative_solutions.csv 里,单个事件会同时给出:
- 最低成本解
- 最低排放解
- 最低违约解
- 最稳方案
- 折中代表解
这说明 NSGA-II 不是"为了用而用",而是真在帮我们回答一个现实问题:
当突发事件来了,我到底是要更便宜,还是更稳,还是更少迟到?
项目最后为了输出一个可执行方案,还会对 Pareto 前沿做一次标准化加权,选出折中解。这个"先保留选择,再选代表解"的设计,我觉得比一开始就把所有目标压成单一加权和更合理。
公式怎么落地成代码
如果只看论文,很多公式都像"模型已经建立好了";真正写项目时,最难的是把公式拆进模块。
这个项目里,我觉得最关键的落地链路有五步。
1. 先把订单聚合成服务节点
python
customer_summary = coordinates.merge(orders, on="node_id", how="left") \
.merge(time_windows, on="node_id", how="left")
service_summary = _split_oversized_customers(customer_summary, config)这一步对应的是"原始业务数据不是直接可建模对象"。
建模对象从来不是 Excel 里的行,而是清洗、聚合、补全、拆分之后的服务任务。
2. 把时变速度做成一个可调用的行驶时间函数
python
travel_time(distance_km, departure_min)这一步对应的是:
论文里它是一个符号,代码里它必须返回一个真的分钟数,还最好能顺手保留跨时段分段记录,方便后面做能耗明细和图表。
3. 把能耗函数做成路线弧段评估器
python
unit = self.unit_consumption_per_100km(vehicle, speed_kmph, load_ratio)
consumption = unit * distance_km / 100.0这一步对应的是:
代码里不能只输出"理论能耗",还要同时给出:
- 能耗
- 能耗成本
- 碳排放
- 碳成本
4. 把政策约束做成可判定的可行性逻辑
python
violates, overlap = service_violates_policy(
powertrain=...,
is_green_zone=...,
service_start_min=...,
departure_min=...,
config=config,
)这一步的价值在于:第二问之后,所有候选路径都可以先被统一打上"政策可行/不可行"的标签,再交给主问题去选。
5. 把动态稳定性做成第四个目标
python
objectives = (total_cost, total_carbon, time_window_loss, stability_loss)这一步非常关键。它把"重调度不要改太多"这件事,从一种经验偏好,变成了显式优化目标。
这也是为什么我更愿意把这个项目看成工程实现,而不是单纯的模型作业。
需要代码的,请在评论区下留言,作者会逐个回复。制作不易,请各位看官老爷点个赞和收藏!!!