摘要 :
2026年4月,腾讯正式发布了其新一代旗舰AI模型 Hy3-preview 。这是自前OpenAI研究员 姚顺雨 加入腾讯并领导基础AI研发以来的首个重要成果。该模型以仅 2950亿参数 的"小规模"逆势突围,在元宝、ima及CodeBuddy中均已上线。本文将结合官方架构文档与最新报道,剖析其技术亮点与落地逻辑。
体验Demo :https://huggingface.co/spaces/tencent/Hy3-preview
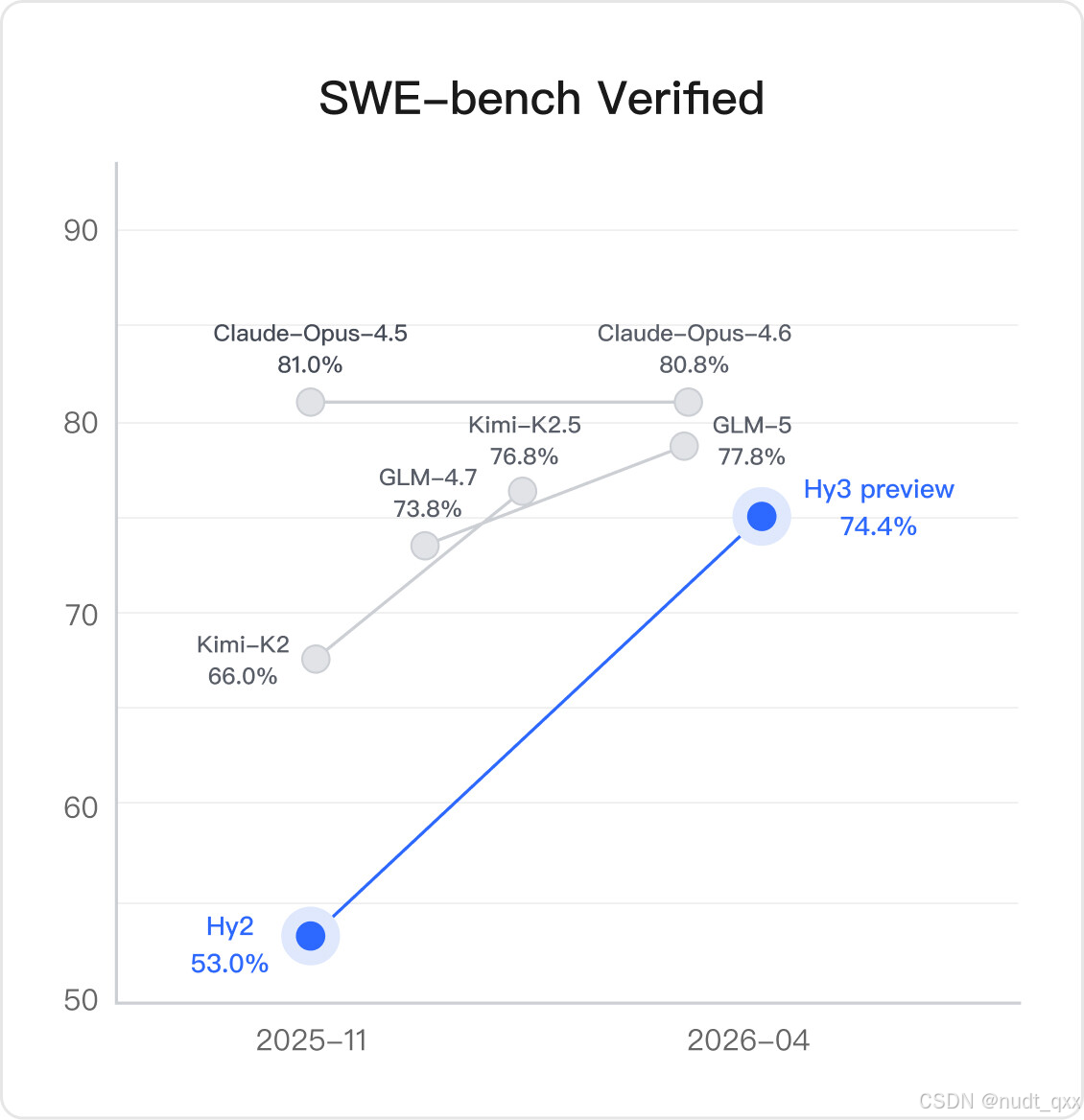
和竞品的指标对比:
一、 研发背景与战略定位:姚顺雨首秀
据《南华早报》报道,Hy3-preview 是腾讯自 姚顺雨 加盟并执掌混元团队基础模型研发后的首次亮相。这位前 OpenAI 研究员的加入,标志着腾讯在大模型底层技术上的进一步聚焦。
关键信息梳理:
- 性能定位:腾讯官方表示,Hy3-preview 是目前最强大的闭源模型,与中国本土顶尖模型持平,但仍落后于 OpenAI、Google DeepMind 等美国顶尖模型。
- 逆势缩参 :与业界动辄万亿参数的潮流不同,Hy3-preview 的参数量仅为 2950亿,远低于腾讯于2025年12月发布的上一代旗舰 HY 2.0(参数超4000亿)。
- 核心逻辑 :参数减少并非降级,而是为了 适配真实商业场景。较小的参数量显著降低了推理计算成本与延迟,使其能够大规模部署于高并发消费端产品。
二、 模型架构核心解析
Hy3-preview 由腾讯混元团队开发,在 Hugging Face 上的架构文档揭示了其高效运行的秘密。
- Dense-MoE 混合架构 :
- 第一层使用标准 Dense FFN 保证输入特征稳定性。
- 后续所有层均为 MoE 层,拥有 192 个路由专家 和 1 个始终激活的共享专家。推理时仅需激活 Top-K(默认 K=8)专家,实现高效稀疏计算。
- Sigmoid 路由与无辅助损失 :
- 采用 Sigmoid 函数替代 Softmax 进行路由打分,决策更独立。
- 引入专家偏置校正负载均衡,无需计算辅助负载均衡损失,简化训练流程。
- QK-Norm 稳定机制:对 Query 和 Key 应用 RMSNorm,提升长文本训练稳定性。
三、 代码调用示例
开发者可通过 Hugging Face Transformers 库调用:
python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "tencent/Hy3-preview"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype="auto"
)
inputs = tokenizer("人工智能的未来是", return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=64)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))四、 普通用户体验入口:元宝 App、网页端 与 ima
根据官方表态,Hy3-preview 的开发强调 产品需求与底层技术的无缝对齐。目前该模型已部署在腾讯系核心应用中:
| 平台 | 可用性说明 | 场景优势 |
|---|---|---|
| 腾讯元宝 App / 网页 | 在对话界面的模型切换栏中,可选择 "Hy3-preview" 版本。 | 复杂逻辑推理、长文总结、实时对话。 |
| ima.copilot | 作为智能工作台的底层算力支持,处理上传的 PDF、Word 等文档。 | 基于 295B MoE 架构,长文档解析速度更快,显存/算力消耗更经济。 |
| CodeBuddy | 已集成 Hy3-preview,辅助编程代码生成。 | 代码补全与 Debug 推理。 |
五、 总结
Hy3-preview 的发布不仅是技术的迭代,更反映了腾讯在大模型策略上的务实转变------以 295B 的"小身材"换取在元宝、ima 等亿级用户产品中的流畅体验。对于普通用户而言,无需关注参数大小,打开元宝 App 或 ima,体验的便是由姚顺雨团队带来的最新 AI 能力。
参考资料:
- Hugging Face Transformers Documentation - Hy3-preview.
- South China Morning Post - Tencent unveils first flagship AI model since former OpenAI researcher took helm.
- https://huggingface.co/docs/transformers/main/en/model_doc/hy_v3
- https://www.scmp.com/tech/big-tech/article/3351101/tencent-unveils-first-flagship-ai-model-former-openai-researcher-helm