26年5月来自微软、上海交大、同济大学和复旦的论文"SkillOpt: Executive Strategy for Self-Evolving Agent Skills"。
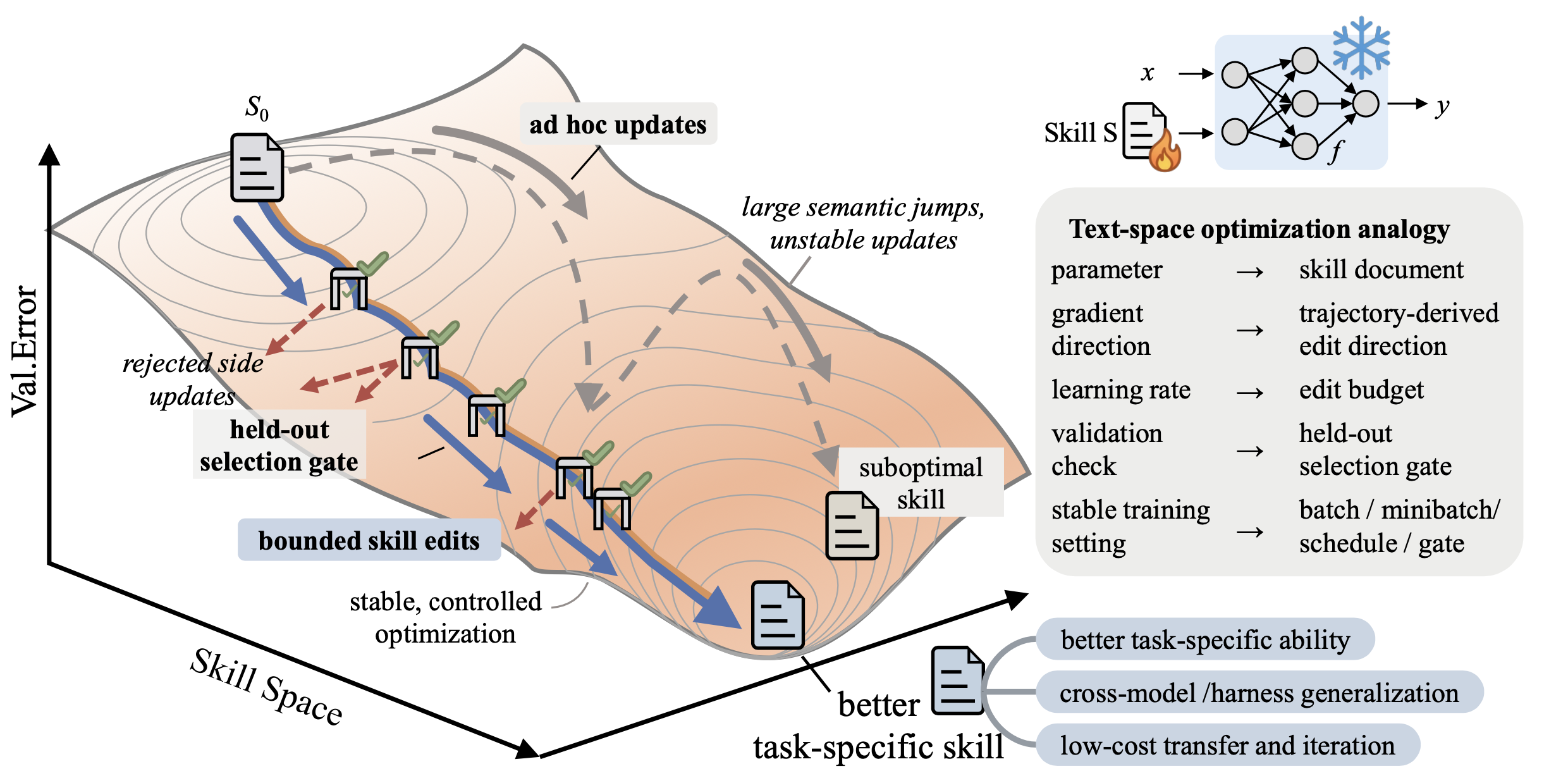
如今,智体技能要么是手工打造,要么是一次性生成,要么是通过松散控制的自我修订演化------这些方法都不像深度学习优化器那样有效,也无法在反馈下可靠地改进初始状态。技能应该像冻结智体的外部状态一样进行训练,并采用与权重空间优化相同的可复现性方法。SkillOpt 是一个系统化的、可控的智体技能文本空间优化器:一个独立的优化器模型将评分后的部署结果转化为对单个技能文档的有界添加/删除/替换操作,并且只有当编辑能够严格提高预留的验证分数时,该编辑才会被接受。文本学习率预算、拒绝编辑缓冲区以及逐轮慢速/元更新机制,使得技能训练稳定,同时在部署时无需增加任何推理时间模型调用。在六个基准测试、七个目标模型和三个执行环境(直接聊天、Codex、Claude Code)中,SkillOpt 在所有 52 个评估单元(模型、基准测试、执行环境)中均表现最佳或并列第一,并且在人类技能、单次 LLM 技能、Trace2Skill 技能、TextGrad 技能、GEPA 技能和 EvoSkill 技能中均优于所有单单元竞争对手。迁移实验进一步表明,优化后的技能模型在跨模型规模、Codex 和 Claude Code 执行环境之间以及迁移到附近的数学基准测试时,即使不进行进一步优化,也能保持其价值。
SkillOpt,是一款专用于智体技能的文本空间优化器。给定目标领域、初始技能以及待适配的模型,SkillOpt 会反复采样轨迹批次,分析其中的成功与失败案例,并指示一个"前沿优化器模型"来提出结构化的增、删、改编辑建议。随后,它会在受文本"学习率"预算约束的前提下,对这些候选编辑进行聚合与排序;接着对技能文档执行一次有界更新;并在最终采纳该技能之前,先在一个预留的独立验证集上对其进行评估。被否决的编辑建议会被保留下来作为负面反馈,而周期性的慢速/元更新机制则有助于捕捉并维持更长期的规律性。如图 1 简要展示这一循环流程的示意图。最终交付的成果是一个精简的 best_skill.md 文件,其篇幅约为 300 至 2000 个tokens;在此过程中,待适配的模型及执行框架均保持固定不变。
1 问题设定
一项技能 s 是一种自然语言策略,在执行前被注入智体的上下文之中;这与近期将技能视为智体可复用程序性知识的相关研究 7, 8 保持一致。在直接对话基准测试中,该技能会被前置于系统指令或开发者指令之前;而在工具使用测试框架中,它则转化为一种持久性的程序性记忆。
训练集提供经验,验证集负责把控更新,而测试集仅用于最终报告。优化器状态包含当前技能、经验证集筛选出的最佳技能、缓存的技能哈希值、当前周期的局部拒绝步长缓冲区,以及可选的慢速/元更新状态。仅经采纳的最佳技能会被导出为 best_skill.md 文件。
2 前向传播:展开证据(Rollout Evidence)
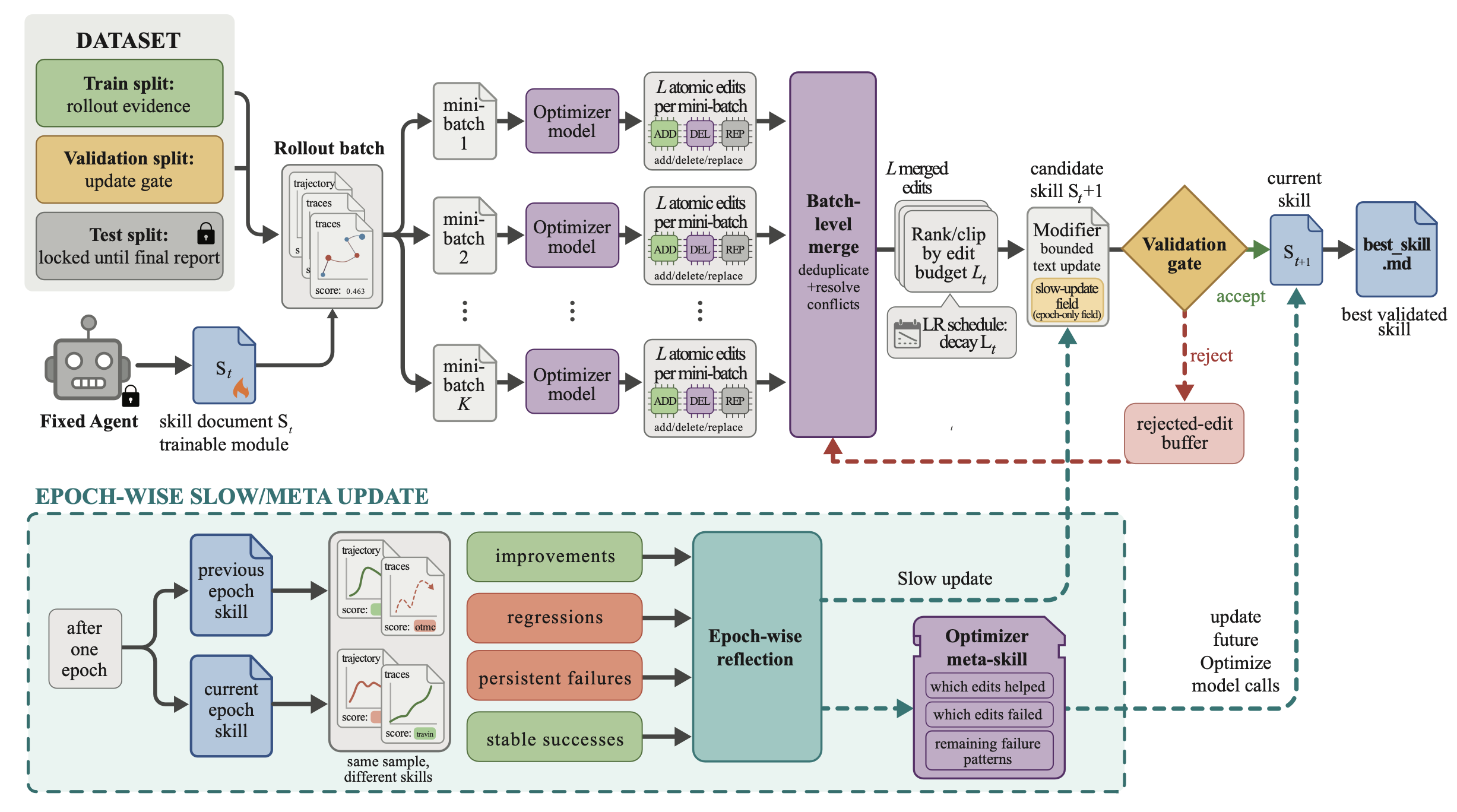
在每一个优化步骤中,目标模型(Target Model)利用当前技能(Skill)从训练数据集 D_tr 中执行一批展开(Rollout)任务。驾驭(Harness)会记录任务元数据、消息、工具调用、观测结果、命令输出、最终答案、验证器反馈,以及特定于基准测试的上下文信息(例如电子表格预览、文档引用或精简的执行轨迹)。这一批次数据构成"证据单元":小批量数据更新速度快但噪声较大,而大批量数据能在技能发生变更之前揭示出更多重复出现的模式。该实现方案还支持"累积"模式,即对多个展开批次分别进行反思,随后合并为一次统一的更新,从而将执行吞吐量与更新频率解耦。
3 后向传播:小批量反思(Minibatch Reflection)
优化器模型(Optimizer Model)将执行轨迹转化为对技能的编辑指令,这一过程遵循了以轨迹驱动的反思与提示词演化这一广义研究路线 13, 27, 28。它首先将失败的轨迹与成功的轨迹区分开来,并将每一组进一步划分为若干个"反思小批量"。这一划分至关重要,因为单一的轨迹往往只能产生针对个别案例的修补方案,而小批量数据则能揭示出那些可复用的程序性错误------例如智体(Agent)总是持续地搜索错误的来源、以错误的格式撰写答案,或者未能正确验证工具的执行结果。针对失败轨迹的小批量反思会提出缺失的规则或修正性规则;而针对成功轨迹的小批量反思则旨在保留那些已被证明行之有效的行为模式。每一次反思过程都会输出结构化的编辑指令(包括添加、删除或替换操作),若处于"重写模式"下,则会输出一组简短的重写建议。
针对局部问题的建议会通过层级化的方式进行合并:首先分别对源自失败轨迹和成功轨迹的编辑指令进行整合,随后将两者合并,并在合并过程中优先采纳针对失败情况的修正建议。在优化器模型选定最终的"受限更新"方案之前,这一步骤会过滤掉那些重复、相互矛盾或仅适用于特定案例的建议。
4 受限文本更新(Bounded Text Updates)
在 SkillOpt 框架中,与传统机器学习中的"学习率"相对应的概念是"编辑预算"L_t,即在第 t 个优化步骤中允许应用的技能编辑指令的最大数量。在完成建议合并之后,优化器模型会依据预期的效用值对合并后的编辑指令池进行排序,并从中截取排名最靠前的 L_t 条编辑指令。这正是 SkillOpt 与那种"即兴式"(ad hoc)提示词重写方法之间的关键区别所在。不受限制的重写操作可能会误删有用的规则、引入相互冲突的指令,甚至导致模型对局部的失败案例产生过拟合;而受限更新机制既能确保技能的连续性得以维系,又能允许技能不断习得新的操作流程与规则。SkillOpt 支持多种编辑预算调度策略,包括常数、线性、余弦以及自适应(autonomous)调度策略。默认采用的余弦调度策略设定为:在优化过程初期允许进行较大规模的编辑,随后随着迭代的深入,编辑规模逐渐衰减,转变为更为精细的整合与微调。
最终选定的编辑指令将被应用于当前的技能描述中,从而生成一个新的"候选技能"。在"补丁模式"(patch mode)下,编辑操作属于局部性操作,例如追加、插入、替换和删除;而在"重写模式"(rewrite mode)下,选定的建议将触发对整个技能(skill)的全面重写。步骤层级的编辑无法覆盖受保护的"慢更新"字段,因此快速的局部变更与较慢的、以周期(epoch)为单位的整合更新得以保持分离。
5 验证门控与被拒-编辑缓冲区
每一个候选技能都会在 D_sel 数据集上进行评估,评估时使用的是同一套已冻结的目标模型和驾驭(harness)。如果该候选技能的得分优于当前的选定技能得分,它便成为新的"当前技能";如果其得分甚至超越了迄今为止的最高分,它便被确立为"最佳技能"(best_skill.md)。否则,该候选技能将被拒绝。这一验证门控将"反思"过程转化为一种"提议-测试"的优化流程,而非无条件的自我编辑;这一点至关重要,因为那些看似合理的文本诊断建议,实际上仍有可能对目标模型造成损害。
被拒绝的更新并非毫无价值。优化器会维护一个"周期局部缓冲区",用于记录观察的失败模式;对于那些被拒绝的编辑步骤,该缓冲区会记录当时尝试执行的编辑操作,以及这些操作所导致的得分跌幅。在同一周期内后续触发的"反思"调用中,优化器模型将接收并查阅该缓冲区的内容,从而避免重复尝试那些已被证实失败的编辑操作,转而集中精力解决尚未解决的故障。这一机制在训练阶段为优化循环提供了负反馈信号,且不会增加推理阶段(inference-time)的计算开销。
6 以周期为单位的慢更新/元更新
"快速更新"从当前批次(batch)数据中汲取经验;而以周期为单位的"慢更新"或"元更新"则从相邻的多个周期数据中进行学习。在一个训练周期结束时,SkillOpt 系统会对同一批训练样本进行采样,分别利用上一周期的技能版本和当前周期的技能版本对这些样本进行处理;随后,系统会将处理结果归类为:表现提升、表现退步、持续性故障以及稳健的成功案例。优化器模型会将一份简明扼要的"纵向指导信息块"写入一个受保护的"慢更新"字段中,而这份包含指导信息的候选更新同样需要通过前述的验证关卡。通过这种方式,"慢更新"机制既能捕捉并固化那些具有长久价值的域级经验,又能确保其像步骤层级的编辑操作一样,同样接受严格的安全校验。
"元技能"(meta skill)仅存在于优化器一侧。它对以下信息进行归纳总结:哪些编辑模式曾带来助益、哪些编辑模式曾被拒绝,以及哪些故障在多个训练周期中持续存在。这份"元指导信息"会被前置(prepend)于优化器后续执行"反思、合并与排序"任务时所使用的提示语(prompts)之前;但值得注意的是,这份元指导信息并不会随同最终的目标模型一同发布或部署。这种设计模式的优势在于实现"关注点分离"(separation of concerns):已部署的技能模型依然保持其紧凑与轻便的特性,而训练过程则得益于一份更为详实、丰富的编辑过程记录。
7 与驾驭无关的部署模式
SkillOpt 借助轻量级的适配器接口,实现了与具体驾驭(harness)的解耦,这与当前智体(Agent)日益嵌入于工具使用及软件执行环境这一大趋势相吻合 1, 2, 4。适配器负责构建训练与评估批次、将当前技能注入智体的上下文环境、运行原生的驾驭(harness),并返回经评分的执行轨迹。因此,同一套优化器可通用于直接问答(QA)、电子表格执行、文档推理、多模态问答、具身环境,乃至 Codex 或 Claude Code 风格的执行循环等多种场景。将"技能"视为一种适配层,其核心的实际优势便在于此:一个性能更强的优化器模型能够离线训练出可复用的技能构件(artifact);随后,生成的 best_skill.md 文件便可直接部署或应用于各类目标模型、驾驭及相关基准测试中,而无需对模型权重进行任何修改。
如图 2所示SkillOpt 的工作流程:一个冻结的目标模型执行一批基于当前技能的"展开"(rollout);一个优化器模型针对展开中的成功与失败案例执行小批量"反思"操作,提出受限的技能增添、删除或替换编辑建议,并在预设的编辑预算下对这些建议进行合并与排序;最终,仅当候选技能通过了独立的"保留验证门控"(held-out validation gate)的检验时,才会被正式采纳。在跨越多个训练周期(epochs)的过程中,一种"慢速/元更新"机制得以保留那些具有长远价值的经验教训,且这一过程不会对目标模型本身进行任何修改。
设置。报告在 SearchQA 29、SpreadsheetBench 30、OfficeQA 31、DocVQA 32、LiveMathematicianBench 33(在表格中简写为 LiveMath)以及 ALFWorld 34 这六个基准测试集上,每个基准在保留测试集拆分上的原生"硬分数"(hard score)或"精确匹配准确率"。实验中使用两个模型系列:GPT 35 和 Qwen 36, 37。该基准测试套件经过精心设计,具有高度的多样性------它涵盖单轮问答(SearchQA、DocVQA、LiveMathematicianBench 的多项选择题模式)、包含多达 24 次工具调用的多轮工具循环(OfficeQA)、包含多达 30 个回合且在真实的 openpyxl/pandas 运行时环境中执行的多轮代码生成任务(SpreadsheetBench,默认模式为 multi),以及每回合包含多达 50 个步骤的持续具身交互任务(ALFWorld)。对于基于数据集的实验,采用确定性的训练集、选择集和测试集拆分,这些拆分均源自同一数据集种子(split_seed = 42);其中,选择集仅用于决定是否接受或拒绝候选的技能编辑,而所有报告的分数均是在与训练集和选择集完全独立的保留测试集上计算得出的。因此,报告的数值衡量的是模型的泛化能力,而非其在验证集上的拟合程度。
驾驭(Harnesses)。 "直接对话"(Direct chat)模式通过单次对话补全调用来调用目标模型,并将技能内容前置于系统提示词(System Prompt)中。Codex 驾驭通过 Codex 命令行接口(CLI)在一个具备写入权限的工作区沙箱 38 中驱动目标模型;SkillOpt 模块会将当前技能渲染为针对特定任务的 SKILL.md 文件(置于任务文件同级目录),并读取回紧凑的执行轨迹摘要(codex_trace_summary.txt);该摘要随后被纳入"教师反思上下文"中,从而使优化器能够从智体(Agent)的实际操作中进行学习,而不仅仅是依据其最终答案。Claude Code 运行驾驭则通过 Claude 命令行接口(CLI) 39 实现了完全相同的工作区交互契约。上述三种模式均采用相同的 best_skill.md 文件格式,正是这一通用格式使得跨-驾驭迁移实验得以实现。
基线模型(Baselines)。选取七种基线模型进行对比,涵盖"无适应"、"人工编写"、"单样本(One-shot)"以及"基于学习"等不同类别:无技能(使用基准测试默认的系统提示词运行冻结的目标模型);人工技能(由专家针对特定基准测试精心编写的技能文档);单样本 LLM 技能(由 GPT--5.5 依据高层级任务描述生成且后续不再更新的单一技能);Trace2Skill 9(轨迹层级的技能蒸馏方法);TextGrad 40(梯度风格的自然语言提示词优化方法);GEPA 13(基于帕累托最优思想的反思性提示词演化方法);以及驾驭(Harness)层面的竞品 EvoSkill 10(基于失败分析的技能文件夹演化方法)。所有基线模型在针对任一基准测试进行评估时,均采用相同的目标模型、相同的保留测试集划分方式以及相同的评分器;因此,这种对比方式能够有效地将评估重点聚焦于"适应过程的选择"这一核心变量上,从而排除诸如提示词模板或评分流程等次要因素的干扰。
设计原则。该实现遵循五项设计原则。首先,任务执行模型是固定的,仅文本技能发生变化。其次,每个候选技能在被采纳前,均需在独立的"选择拆分集"上进行评估,从而防止未经验证的"反思"发生累积。第三,小批量分析结果采用层级式合并,确保最终的编辑内容所依据的是反复出现的证据,而非孤立的个别案例。第四,编辑预算机制充当了"学习率"的类比角色,允许在早期进行幅度较大的修改,而在后期则侧重于精细化的微调。第五,已部署的技能保持轻量化且易于审查;与此同时,位于优化器侧的"元技能"则与呈现给任务执行模型的技能相互独立、互不干涉。