谷歌AlphaGo击败李世石、OpenAI的Dota2 AI碾压人类冠军、特斯拉自动驾驶不断进化------这些AI奇迹的背后,都依赖同一项核心技术:强化学习。
今天,我们不堆砌复杂的数学公式,而是通过一个经典的"倒立摆"小游戏,从零开始把强化学习的每一个核心概念讲清楚、讲透彻。
全文包含完整可运行的Python代码,你可以在自己的电脑上亲手训练出一个会自己"顶杆子"的AI。
建议收藏,慢慢消化。
1 强化学习是什么?一个"训练小狗"的故事就能讲明白
1.1 从狗子学坐下说起
你养了一只小土狗。刚到家时,它什么都不会:乱拉乱尿、扑人、咬拖鞋。
你想让它学会"坐下"。你会怎么做?
-
当它坐下 时,你立刻给一块鸡肉干(正奖励)。
-
当它没坐下 时,你不给零食,甚至轻声说"不"(没奖励/负反馈)。
一开始狗子是乱蒙的。但蒙对几次之后,它发现了一个规律:"只要我屁股一着地,就有肉吃!"
于是它坐下的次数越来越多。最后,不管在客厅、公园还是宠物店,只要你喊"坐",它立刻坐得端端正正。
这个"训练小狗"的过程,就是强化学习的完整写照。
1.2 把故事翻译成强化学习的术语
|-----------------|-----------------|----------|------|
| 狗子学坐下 | 强化学习术语 | 数学符号(可选) | |
| 小狗 | 智能体(Agent) | --- | |
| 你家(包括你、地板、零食) | 环境(Environment) | --- | |
| 你喊"坐"的那一刻 | 状态(State) | ss | |
| 小狗做"坐下"或"不坐下" | 动作(Action) | aa | |
| 你给肉干或"啧"一声 | 奖励(Reward) | rr | |
| 小狗最后学会的"听见坐就坐下" | 策略(Policy) | ( \pi(a | s) ) |
一句话定义强化学习:
强化学习 = 智能体通过不断与环境交互、试错,根据获得的奖励反馈,学会"在什么状态下做什么动作"才能最大化累积奖励。
1.3 强化学习的核心交互循环
强化学习由智能体 和环境两部分组成。它们之间的交互可以用下面这个循环来描述:
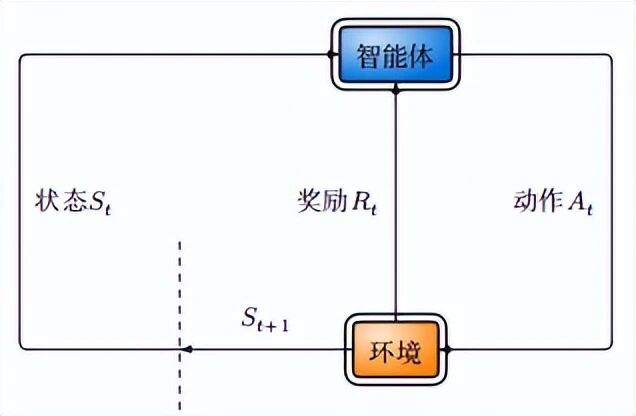
每一步(称为一个时间步):
-
智能体观察当前状态 StSt。
-
智能体根据策略选择一个动作 AtAt。
-
环境执行该动作,返回新的状态 St+1St+1 和一个即时奖励 RtRt。
-
智能体收到奖励,更新自己的策略,然后进入下一轮。
智能体的唯一目标:在长期过程中,从环境里拿到尽可能多的总奖励。
2 强化学习的"Hello World":倒立摆(CartPole)环境
每个领域都有一个最经典的入门例子:
-
编程入门:print("Hello World")
-
电子入门:点亮一颗LED
-
强化学习入门:倒立摆(CartPole)
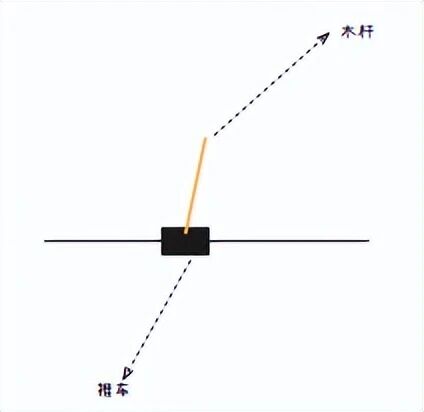
2.1 倒立摆长什么样?
想象一辆小推车,放在一条水平的轨道上。推车上立着一根木杆。
你可以控制推车向左 或向右 移动。
目标:让木杆保持直立,不要倒下。
这跟你小时候用手掌顶铅笔是一模一样的道理:铅笔往左歪,手就往左移;往右歪,手就往右移。
2.2 游戏规则(超简单)
|------------|---------------------------------------------------------|
| 项目 | 具体内容 |
| 智能体 | 小推车 |
| 动作空间 | 两个动作:0 = 向左推,1 = 向右推 |
| 状态空间 | 4个连续数值:小车位置、小车速度、杆子角度、杆子角速度 |
| 奖励规则 | 每存活一步,获得 +1 奖励 |
| 游戏结束条件 | ① 杆子倾斜角度超过12°(倒下) ② 小车偏离中心超过2.4个单位(掉轨) ③ 成功坚持200步(满分通关) |
关键洞察:这是一个典型的"延迟满足"问题。如果智能体只贪图眼前利益(比如总是朝一个方向推),短期内可能没问题,但长远来看必然倒下。
强化学习的精髓,就在于平衡"探索"(探索未知动作)与"利用"(使用已知好动作)。
3 把游戏"翻译"成AI能看懂的数字
AI不认识"左""右""角度",只认识数字。所以我们必须把一切变成数字。
3.1 状态(State)
每一时刻,环境会输出一个状态 ,用 ss 表示。
倒立摆的状态是一个包含 4个浮点数 的数组:
[ 0.02, # 小车位置:0是正中间,负数是左边,正数是右边
0.15, # 小车速度:负数是向左移动,正数是向右移动
-0.03, # 杆子角度:负数是向左歪,正数是向右歪(弧度)
-0.10 ] # 杆子角速度:负数是正在向左倒,正数是正在向右倒对AI来说,整个"世界"就是这4个数字。它看不到杆子,只看到 -0.03 这个数字。
3.2 动作(Action)
动作 aa 只有两个取值:
0 # 向左推
1 # 向右推3.3 奖励(Reward)
奖励 rr 就是分数:每存活一步,r = 1。
如果游戏结束(杆子倒下或小车出界),则不再有新的奖励。
3.4 策略(Policy)------智能体的"大脑"
策略 就是"看到什么状态,就做什么动作"的规则,用字母 ππ(读"派")表示。
在数学上,策略通常输出的是一个概率分布,而不是一个确定的动作。例如:
π(向左推∣s)=0.7,π(向右推∣s)=0.3π(向左推∣s)=0.7,π(向右推∣s)=0.3
也就是说,在状态 ss 下,AI有70%的概率选向左推,30%的概率选向右推。
然后AI按这个概率随机抽样来决定实际动作。
为什么要随机?
如果永远只选概率最大的动作,就可能错过更好的长远策略。就像你天天吃同一家外卖,永远不会发现隔壁新开的店更好吃。
探索(Exploration):偶尔尝试概率低的动作。
利用(Exploitation):大多数时候选择概率高的动作。
平衡两者,是强化学习的核心挑战之一。
3.5 策略的数学表达
π(a∣s)=P(At=a∣St=s)π(a∣s)=P(At=a∣St=s)
这个式子读作:"在状态 ss 的条件下,智能体采取动作 aa 的概率"。
如果这个 ππ 函数是一个神经网络,那么我们就进入了深度强化学习的领域------这也是当今AI界最热门的方向之一。
4 第一个可运行的例子:随机智能体
在让AI学会学习之前,我们先写一个完全不学习 的智能体:不管状态如何,随机向左或向右推。
它肯定玩不好,但可以让我们看清一局游戏的完整流程。
4.1 安装依赖
首先,确保安装了必要的库:
pip install gym==0.25.2 numpy4.2 代码实现
import gym
import random
# 1. 创建倒立摆环境
env = gym.make("CartPole-v0")
# 2. 随机策略:完全不看状态,随机返回 0 或 1
def random_policy(state):
return random.choice([0, 1])
# 3. 玩一局(一个 episode)
state = env.reset() # 重置环境,得到初始状态 S0
done = False # 游戏是否结束
total_reward = 0
while not done:
env.render() # 弹窗显示画面
action = random_policy(state) # 随机选动作
next_state, reward, done, _ = env.step(action) # 执行动作
total_reward += reward
state = next_state
print(f"游戏结束,总共获得奖励: {total_reward}")
env.close()运行结果 :你会看到一个小车在屏幕上左右乱推,杆子很快倒下,得分大概在10~30之间(满分200)。
这个"傻AI"告诉我们:没有学习能力,再简单的任务也完不成。
5 轨迹和回报:怎么定义"玩得好"?
5.1 轨迹(Trajectory)
一局游戏从开始到结束,会产生一串数据:
τ=(S0,A0,R0,S1,A1,R1,S2,A2,R2,... )τ=(S0,A0,R0,S1,A1,R1,S2,A2,R2,...)
这叫做一条轨迹。由于策略和环境都有随机性,从同一个初始状态出发,每次运行得到的轨迹都可能不同。
5.2 回报(Return):未来的钱要打折
假设一局游戏持续了 TT 步,每步奖励都是1,简单加起来是 TT 分。
但是,未来的1分和现在的1分,价值一样吗?
显然不一样------今天给你100块钱,和一年后给你100块钱,你肯定选今天。
在倒立摆中,如果杆子马上就要倒了,那么"现在立刻救一下"比"等两秒再救"重要得多。
因此,我们需要给未来的奖励打个折扣 。这个折扣率叫做 折扣因子 γγ(gamma),通常取 0.9 或 0.99。
折扣总回报(Return) 的定义:
Gt=Rt+γRt+1+γ2Rt+2+γ3Rt+3+...Gt=Rt+γRt+1+γ2Rt+2+γ3Rt+3+...
例如:γ=0.9γ=0.9,奖励全为1,运行4步:
G0=1+0.9×1+0.81×1+0.729×1=3.439G0=1+0.9×1+0.81×1+0.729×1=3.439
越远的奖励贡献越小。
5.3 递推公式(非常重要!)
从上面的定义可以推出:
Gt=Rt+γGt+1Gt=Rt+γGt+1
这个递推关系使得我们可以从最后一步倒着往前计算回报,非常高效。
5.4 代码实现:计算回报
def compute_discounted_return(rewards, gamma=0.99):
"""
逆序计算折扣总回报
rewards: 列表,例如 [1, 1, 1, 1]
"""
G = 0
for r in reversed(rewards): # 从最后一步往前遍历
G = r + gamma * G
return G
# 示例
rewards = [1, 1, 1, 1]
total = compute_discounted_return(rewards, gamma=0.9)
print(total) # 输出 3.439这个计算方法在几乎所有强化学习算法中都会用到,请务必理解。
6 价值函数:如何判断一个状态是"好"还是"坏"?
到目前为止,我们只能计算一整局 的总回报。但AI在学习过程中,需要知道:当前这个状态,到底值不值得?
-
杆子角度 = -10°(快倒了) → 这个状态很糟糕。
-
杆子角度 = 0.5°(很正) → 这个状态很好。
状态价值函数 Vπ(s)Vπ(s) 就是用来量化"状态好坏"的。
6.1 定义
Vπ(s)=EπGt∣St=sVπ(s)=EπGt∣St=s
通俗解释:从状态 ss 出发,按照策略 ππ 一直玩下去,平均能拿到的折扣总回报。
-
由于策略和环境都有随机性,我们取期望值(平均值)。
-
下标 ππ 表示这个价值依赖于策略------换一个策略,同一个状态的价值也会变。
6.2 生活类比
-
V(你当前的职位)V(你当前的职位) = 你现在工资 + 未来升职加薪的期望(打折后)。
-
如果公司前景好,即使当前工资不高,价值也可能很高。
7 贝尔曼方程:强化学习的"心脏"
贝尔曼方程是强化学习里最重要的公式,没有之一。它表达了当前状态价值与下一状态价值之间的关系。
7.1 贝尔曼期望方程(最简洁的形式)
Vπ(s)=EπRt+γVπ(St+1)∣St=sVπ(s)=EπRt+γVπ(St+1)∣St=s
用大白话说:一个状态的价值 = 眼下这一步能拿到的奖励的平均值 + 折扣后的下一个状态的平均价值。
7.2 展开形式(更具体)
Vπ(s)=∑aπ(a∣s)∑s′p(s′∣s,a)r(s,a,s′)+γVπ(s′)Vπ(s)=a∑π(a∣s)s′∑p(s′∣s,a)r(s,a,s′)+γVπ(s′)
这个式子看起来复杂,但意思很直接:
-
对所有可能的动作 aa 求和(乘以选这个动作的概率)。
-
对每个动作,考虑所有可能跳转到的下一个状态 s′s′(乘以跳转概率)。
-
括号里是:即时奖励 + 折扣 × 下一状态的价值。
7.3 为什么贝尔曼方程如此重要?
因为它把当前决策的价值和未来决策的价值联系了起来,形成了递归结构 。
几乎所有强化学习算法(Q-learning、DQN、A2C、PPO......)都直接或间接地使用贝尔曼方程来更新价值估计或策略。
你不需要立刻背下展开形式,但一定要记住核心思想:
现在的好状态 = 现在的收益 + 未来的好状态(打折)。
8 马尔可夫决策过程(MDP)------强化学习的数学框架
8.1 什么是MDP?
马尔可夫决策过程(Markov Decision Process)是强化学习的标准数学模型。它由以下五个要素组成:
MDP=(S,A,P,R,γ)MDP=(S,A,P,R,γ)
|--------------------|--------|-------------|-------------|
| 符号 | 含义 | 倒立摆示例 | |
| SS | 状态空间 | R4R4 (连续) | |
| AA | 动作空间 | {0, 1} | |
| ( P(s' | s,a) ) | 状态转移概率 | 物理引擎决定(确定性) |
| R(s,a,s′)R(s,a,s′) | 奖励函数 | 存活时=1,结束时=0 | |
| γγ | 折扣因子 | 0.99 | |
8.2 马尔可夫性质(Markov Property)
MDP的核心假设是马尔可夫性质:下一个状态只取决于当前状态和当前动作,与历史无关。
P(St+1∣St,At,St−1,At−1,... )=P(St+1∣St,At)P(St+1∣St,At,St−1,At−1,...)=P(St+1∣St,At)
通俗理解:"未来只取决于现在,与过去无关。"
-
在倒立摆中,你只需要知道"当前的位置、速度、角度、角速度",就能决定怎么推;不需要知道10步前小车在哪里。
-
这个假设极大地简化了问题,否则AI需要记住整个历史,计算量会爆炸。
8.3 状态转移和奖励函数
-
状态转移概率
:p(s′∣s,a)p(s′∣s,a) 表示在状态 ss 执行动作 aa 后,跳转到 s′s′ 的概率。
-
奖励函数
:r(s,a,s′)r(s,a,s′) 表示在状态 ss 执行动作 aa 并到达 s′s′ 时获得的即时奖励。
在倒立摆中,状态转移是确定性 的(给定当前状态和动作,下一状态由物理方程唯一确定),所以 p(s′∣s,a)=1p(s′∣s,a)=1 对某个特定的 s′s′,其余为0。
但在其他环境(如棋类游戏,对手下棋有随机性)中,转移概率是随机的。
9 奖励稀疏性:当AI永远拿不到分
9.1 什么是奖励稀疏?
倒立摆中,每一步都有+1奖励,这叫稠密奖励 。
但很多现实问题是稀疏奖励,例如:
让机器人把插头插进插座。
只有完全插进去的那一步才给奖励1,其他所有步都是0。
在这种情况下,AI可能永远也得不到任何奖励,因为一开始完全乱动,永远碰不到"插进去"这个状态。这就是奖励稀疏性问题。
9.2 常见的解决方法
|------------|----------------------------------|
| 方法 | 通俗解释 |
| 奖励塑造 | 设计中间奖励,例如"靠近插座给0.1分""对准插孔给0.5分"。 |
| 课程学习 | 先让插头离插座很近,AI轻松成功;学会了再慢慢拉远距离。 |
| 分层强化学习 | 先学"移动到插座附近",再学"对准插孔",最后学"插入"。 |
| 好奇心驱动 | 鼓励AI探索未见过的状态,即使没有外部奖励,也能获得内部奖励。 |
10 动手实现一个会学习的AI:REINFORCE算法
前面我们写的"随机智能体"不会学习。
现在,我们用神经网络 来写一个能真正学习的AI。算法叫做 REINFORCE(蒙特卡洛策略梯度),是策略梯度方法中最简单的一种。
10.1 策略网络(Policy Network)
策略网络就是一个神经网络:
-
输入
:当前状态(4个数字)。
-
输出
:两个动作的概率(例如 0.3, 0.7)。
网络结构:
输入层(4) → 隐藏层(128) → 隐藏层(128) → 输出层(2) → Softmax → 概率代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class PolicyNetwork(nn.Module):
def __init__(self, state_dim=4, action_dim=2, hidden_dim=128):
super().__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim) # 4 → 128
self.fc2 = nn.Linear(hidden_dim, hidden_dim) # 128 → 128
self.fc3 = nn.Linear(hidden_dim, action_dim) # 128 → 2
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
logits = self.fc3(x)
return F.softmax(logits, dim=-1) # 输出概率,且和为110.2 REINFORCE的核心思想(大白话)
-
用当前的策略网络玩一局,记录每一步的 状态、动作、对数概率、即时奖励。
-
计算每一步的折扣总回报 GtGt(即"从这一步开始以后能拿多少总奖励")。
-
调整网络参数:
-
如果某一步的回报 GtGt 很高 → 让这一步所选动作的概率变大。
-
如果某一步的回报 GtGt 很低 → 让这一步所选动作的概率变小。
一句话:打得好就奖励这个动作,打得不好就惩罚它。
数学上,我们最大化期望回报,等价于最小化以下损失函数:
Loss=−∑tGtlogπ(at∣st)Loss=−t∑Gtlogπ(at∣st)
负号是因为PyTorch默认做梯度下降,而我们要梯度上升。
10.3 完整训练代码(可直接复制运行)
# ==================== 1. 导入必要的库 ====================
# 使用gymnasium替代已废弃的gym库
import gymnasium as gym
import torch
import torch.nn as nn # 关键修复:解决NameError
import torch.optim as optim
from torch.distributions import Categorical
# ==================== 2. 定义策略网络 ====================
class PolicyNet(nn.Module):
def __init__(self):
super().__init__()
# 定义网络层:4个状态输入 -> 128个神经元 -> 128个神经元 -> 2个动作输出
self.fc1 = nn.Linear(4, 128)
self.fc2 = nn.Linear(128, 128)
self.fc3 = nn.Linear(128, 2)
def forward(self, x):
x = torch.relu(self.fc1(x)) # 使用ReLU激活函数
x = torch.relu(self.fc2(x))
logits = self.fc3(x)
# 使用Softmax将输出转换为动作的概率分布
return torch.softmax(logits, dim=-1)
# ==================== 3. 数据收集函数 ====================
def collect_trajectory(env, policy, gamma=0.99):
"""
运行一局游戏,收集训练所需的数据
返回:动作的对数概率列表 和 每个时间步的折扣回报
"""
state, _ = env.reset() # gymnasium的reset返回(state, info)
log_probs = [] # 存储每个动作的logπ(a|s)
rewards = [] # 存储每个时间步的即时奖励
done = False
while not done:
# 将numpy数组转换为PyTorch张量,并添加batch维度
state_t = torch.FloatTensor(state).unsqueeze(0)
probs = policy(state_t) # 获取动作概率分布
dist = Categorical(probs) # 创建分类分布
action = dist.sample() # 根据概率采样一个动作
log_probs.append(dist.log_prob(action)) # 记录对数概率
# 执行动作 (gymnasium返回5个值,而不是4个)
next_state, reward, terminated, truncated, _ = env.step(action.item())
done = terminated or truncated # 游戏结束条件
rewards.append(reward)
state = next_state
# 逆序计算折扣回报 Gt
returns = []
G = 0
for r in reversed(rewards):
G = r + gamma * G
returns.insert(0, G)
returns = torch.tensor(returns)
# 对回报进行标准化,使训练更稳定
returns = (returns - returns.mean()) / (returns.std() + 1e-9)
return log_probs, returns
# ==================== 4. 训练主循环 ====================
# 创建环境 (训练时不渲染,速度更快)
env = gym.make("CartPole-v1") # 使用CartPole-v1,步数上限为500
policy = PolicyNet() # 初始化策略网络
optimizer = optim.Adam(policy.parameters(), lr=0.01) # 使用Adam优化器
for episode in range(500):
# 收集一局游戏的数据
log_probs, returns = collect_trajectory(env, policy)
# 计算损失函数: L = - Σ (Gt * log π)
loss = -torch.cat([lp * G for lp, G in zip(log_probs, returns)]).sum()
# 反向传播,更新网络参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每50个回合打印一次训练进度
if (episode + 1) % 50 == 0:
print(f"回合 {episode+1}, 平均回报 = {returns.mean().item():.2f}")
# ==================== 5. 测试训练好的策略 ====================
# 创建用于测试的环境,并开启渲染模式
test_env = gym.make("CartPole-v1", render_mode="human")
state, _ = test_env.reset()
done = False
total_reward = 0
while not done:
# 测试时直接选择概率最大的动作,不进行采样
with torch.no_grad():
probs = policy(torch.FloatTensor(state).unsqueeze(0))
action = torch.argmax(probs).item()
state, reward, terminated, truncated, _ = test_env.step(action)
done = terminated or truncated
total_reward += reward
print(f"测试得分: {total_reward}")
test_env.close()运行这段代码,你会看到AI的得分从十几分逐渐上升到200分(满分)。
它自己学会了"杆子往左歪就往左推,往右歪就往右推"的平衡技巧------没有人教过它物理公式。
11 总结:一张表记住所有核心概念
|----------|----------------|--------------------------------------|--------|
| 概念 | 通俗解释 | 数学符号 | |
| 智能体 | 做决策的家伙(小推车) | Agent | |
| 环境 | 外部世界(倒立摆游戏) | Environment | |
| 状态 | 当前局势(位置、速度等) | ss | |
| 动作 | 能做的事(左/右) | aa | |
| 奖励 | 做得好不好(+1或0) | rr | |
| 策略 | 决策规则(状态→动作的概率) | ( \pi(a | s) ) |
| 轨迹 | 一局游戏的完整记录 | ττ | |
| 回报 | 打折后的总收益 | GtGt | |
| 价值函数 | 某个状态的好坏程度 | Vπ(s)Vπ(s) | |
| 贝尔曼方程 | 价值函数的自洽关系 | V(s)=ER+γV(s′)V(s)=ER+γV(s′) | |
| 马尔可夫性质 | 未来只取决于现在 | ( P(s' | s,a) ) |
| 探索 vs 利用 | 贪眼前 vs 冒险试新 | --- | |
12 下一步学什么?进阶路线图
如果你已经完全掌握了本文的内容,恭喜你,你已经入门强化学习 了!
接下来可以按以下顺序深入学习:
-
Q-learning 和 DQN
-
适合离散动作空间(如倒立摆、Atari游戏)。
-
DeepMind 打砖块、吃豆人的算法。
-
PPO(近端策略优化)
-
目前工业界最常用的算法。
-
OpenAI 的 Dota2 AI、ChatGPT 的 RLHF 都在使用。
-
SAC(柔性演员-评论家)
-
适合连续动作控制(如机器人关节、自动驾驶方向盘)。
-
多智能体强化学习
-
多个智能体同时学习(如足球机器人、自动驾驶车流)。
无论学习哪个方向,都离不开本文讲的基础:策略、价值函数、贝尔曼方程、探索与利用。
写在最后
强化学习是AI领域中最接近人类"试错学习"方式的分支。
它不需要人类手把手标注数据,只需要告诉AI"什么是对,什么是错",然后让它自己去摔跟头、爬起来。
最终,它能学会我们教不了的东西------就像倒立摆的AI,从未学过牛顿力学,却自己摸索出了平衡的秘诀。
如果你觉得这篇文章对你有帮助,请点赞、收藏、转发,让更多人看到。
有任何问题,欢迎在评论区留言,我会尽力解答。