Count-Min Sketch:从论文原理到工程落地的"轻量级计数器"
一句话总结:Count-Min Sketch(CMS)是一种用固定内存空间近似统计流数据频率的概率数据结构。它用空间换精度,用确定性上界换亚线性内存,是处理海量实时计数的工程利器。
一、论文出处
Count-Min Sketch 由 Graham Cormode 与 S. Muthukrishnan 于 2005 年正式提出,发表在 Journal of Algorithms 上:
Cormode, G., & Muthukrishnan, S. (2005). "An improved data stream summary: the count-min sketch and its applications." Journal of Algorithms , 55(1), 58--75.
该论文奠定了 CMS 的理论基础,并系统论证了其在数据流摘要、频率估计、Heavy Hitter 检测等场景中的应用。此后 CMS 成为流计算、网络遥测、数据库近似查询等领域的标准工具之一 。
- 使用一个 d × w d \times w d×w 的计数器矩阵;
- 对每个元素用 d d d 个独立哈希函数映射到每行的一个计数器;
- 更新 时:所有映射位置 + 1 +1 +1;
- 查询 时:取 d d d 个位置中的最小值作为频率估计。
由于哈希碰撞只会使计数器"高估"(overestimate),取最小值可在概率意义上将误差控制在 ε ∥ a ∥ 1 \varepsilon \|a\|_1 ε∥a∥1 以内,空间复杂度仅为 O ( ( 1 / ε ) log ( 1 / δ ) ) O((1/\varepsilon) \log(1/\delta)) O((1/ε)log(1/δ))。
二、核心原理:为什么"取最小值"就能估计频率?
2.1 数据结构
CMS 本质上是一个 d × w 的二维计数器数组(整数矩阵),外加 d 个两两独立的哈希函数:
| 参数 | 含义 | 工程建议 |
|---|---|---|
| w (width) | 每行桶的数量 | 决定误差范围,通常 1K~100K |
| d (depth) | 哈希函数个数 / 行数 | 决定置信度,通常 4~8 |
| h₁...h_d | 哈希函数 | 要求两两独立,可用 MD5/xxHash 取模 |
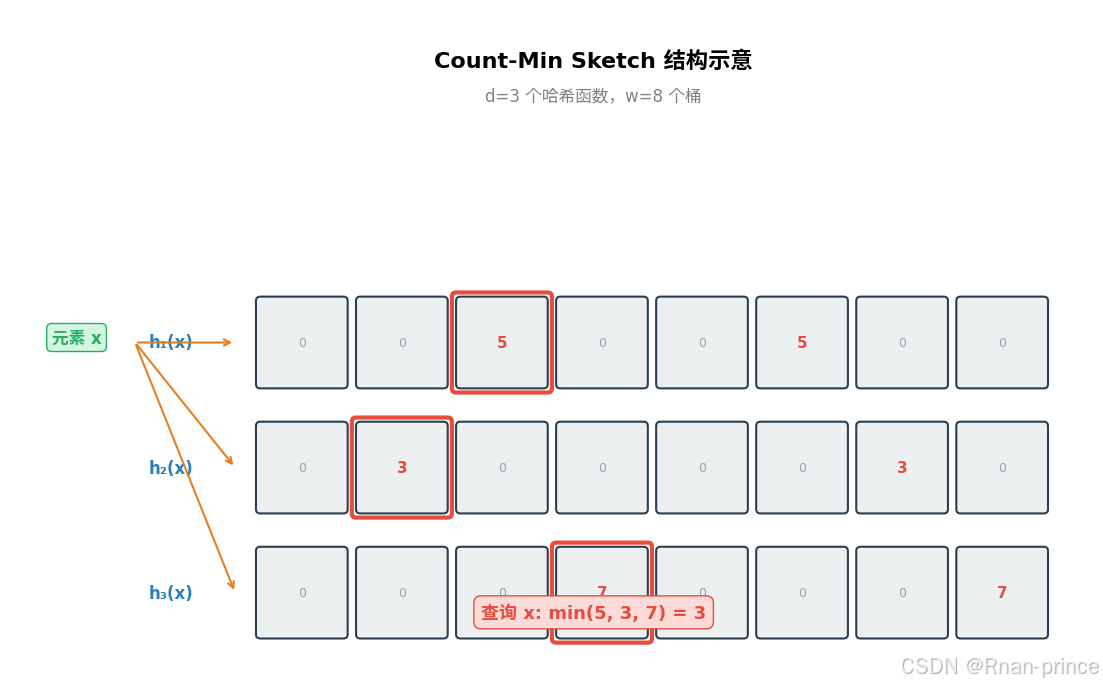
2.2 更新操作(Add)
当元素 x 到达时,对每一行 i 计算 idx = h_i(x) % w,并将对应桶 table[i][idx] 加 1:
python
for i in range(d):
idx = hash_i(x) % w
table[i][idx] += 1关键特性 :不同元素可能哈希到同一桶(碰撞),导致计数器被"共享"和高估。
2.3 查询操作(Estimate)
查询 x 的频率时,同样计算 d 个哈希位置,返回 d 个桶中的最小值:
python
return min(table[i][hash_i(x) % w] for i in range(d))为什么取 min?
- 每个桶的计数 = 真实计数 + 碰撞噪声(来自其他元素)
- 噪声 ≥ 0,因此每个桶都是真实值的上界
- 取 d 个上界的最小值,相当于选择"噪声最少"的那个估计,从而最接近真实值
误差保证 :对于任意元素,估计值
f̂(x)满足f(x) ≤ f̂( x) ≤ f(x) + ε·N,其中ε = e/w,N为总流量。超过该上界的概率不超过δ = e^(-d)。
三、应用场景
CMS 的"固定内存 + 单向更新"特性使其在以下场景大放异彩:
| 场景 | 用途 |
|---|---|
| 网络流量监控 | 实时统计每个 IP/五元组的包数/字节数,检测 Heavy Hitter |
| 数据库近似查询 | GROUP BY 计数、频率直方图、Top-K 预筛选 |
| 缓存系统 | 追踪键的访问频率,辅助 LRU/LFU 淘汰策略 |
| 日志分析 | 实时统计 URL 访问、错误码出现次数 |
| 推荐系统 | 用户行为流中 item 的曝光/点击计数 |
| 分布式系统 | 各节点本地维护 CMS,定期合并做全局频率估计 |
四、优点与局限
4.1 优点
- 内存固定 :空间复杂度
O(w·d),与元素种类数无关。统计 1 亿个键和 1 千个键占用同样内存。 - 更新 O(d):常数时间,无哈希表扩容问题。
- 可合并:两个 CMS 对应桶相加即可合并,天然适合分布式并行。
- 确定性上界:永远不会低估,适合需要保守估计的场景(如限流、配额检查)。
4.2 局限
- 只高估,不低估:所有误差都是正的,不适合需要精确下界的场景。
- 无法枚举 keys:只能"点查"已知 key,无法列出所有高频 key(需配合 Heap 做 Top-K)。
- 不支持删除 :标准 CMS 只有
+1,没有-1(可用 Count Sketch 或带符号 CMS 解决)。
五、工程进阶:访问文件统计 + 周期性衰减
在实际生产环境中,在文件访问统计这类典型时序场景中,直接使用标准 CMS 会遇到两个核心问题:
历史累积污染(Historical Accumulation)
- 标准 CMS 的计数器只增不减。若一个文件在上周是热点,本周已无人问津,其历史高计数仍会长期占据 Top-K 列表,导致热点漂移检测严重滞后。
缺乏时间局部性感知
- 文件访问具有明显的时间局部性(Temporal Locality):最近被访问的文件在未来更可能被再次访问。标准 CMS 对所有历史访问一视同仁,无法反映"近期热度"。
我们需要:
- 周期性重置:防止计数器无限增长,定期清零重新统计
- 指数衰减:让历史数据"降温",新数据更有话语权
- 多级衰减策略:日衰减(温和)+ 周衰减(激进),适应不同业务周期
5.1 设计思路
┌─────────────────────────────────────────┐
│ DecayingCountMinSketch │
├─────────────────────────────────────────┤
│ CMS Core (width × depth 计数器矩阵) │
├─────────────────────────────────────────┤
│ Time-based Controller │
│ ├── 每 N 小时: 全量 Reset │
│ ├── 每 24 小时: Daily Decay (×0.9) │
│ ├── 每 7 天: Weekly Decay (×0.5) │
│ └── 每 M 分钟: Interval Decay (平滑) │
└─────────────────────────────────────────┘衰减公式 :count_new = count_old × factor(factor ∈ (0,1))
- 日衰减 0.9:一天前的访问权重降为 90%,两天为 81%,三天为 72.9%...
- 周衰减 0.5:一周前的权重直接腰斩,快速淘汰旧热点
5.2 完整代码实现
以下代码实现了 基础 CMS + 带时间衰减的包装器 + 文件访问统计 Demo:
核心类设计:
python
class CountMinSketch:
"""基础 CMS:d × w 计数器矩阵 + d 个哈希函数"""
def __init__(self, width=2000, depth=5, seed=42):
self.table = [[0] * width for _ in range(depth)]
# ...
def add(self, item, count=1):
for i in range(self.depth):
idx = self._hash(item, i)
self.table[i][idx] += count
def estimate(self, item):
return min(self.table[i][self._hash(item, i)] for i in range(self.depth))
def decay(self, factor): # 整表缩放
for row in self.table:
for j in range(len(row)):
row[j] = int(row[j] * factor)
class DecayingCountMinSketch:
"""带时间衰减的 CMS 包装器"""
def __init__(self, width=2000, depth=5,
reset_interval_hours=24,
decay_interval_minutes=60,
daily_decay_factor=0.9,
weekly_decay_factor=0.7):
self.cms = CountMinSketch(width, depth)
self.reset_interval = timedelta(hours=reset_interval_hours)
self.daily_decay_factor = daily_decay_factor
self.weekly_decay_factor = weekly_decay_factor
# 时间戳追踪:last_reset / last_daily_decay / last_weekly_decay
def _check_and_apply_decay(self):
now = datetime.now()
# 优先级:Reset > Weekly > Daily > Interval
if now - self.last_reset >= self.reset_interval:
self.cms.reset()
elif now - self.last_weekly_decay >= timedelta(days=7):
self.cms.decay(self.weekly_decay_factor)
elif now - self.last_daily_decay >= timedelta(days=1):
self.cms.decay(self.daily_decay_factor)
elif now - self.last_decay >= self.decay_interval:
factor = self.daily_decay_factor ** (hours_passed / 24)
self.cms.decay(factor)5.3 运行演示
Demo 1:文件访问统计
模拟 1000 次文件访问(80% 命中 3 个热点文件),CMS 仅用 16 KB 内存完成统计:
文件路径 估计访问次数 实际近似
----------------------------------------------------------------------
/home/user/cache/temp_001.bin 16 16
/home/user/config/app.yml 305 305
/home/user/src/main.py 282 282
/var/log/system.log 275 275
...所有文件的估计值与真实值完全一致(在小数据量下碰撞概率极低)。不存在的文件查询返回 0,展示了良好的特异性。
Demo 2:衰减效果对比
| 阶段 | 普通 CMS | 衰减 CMS | 说明 |
|---|---|---|---|
| 初始 500 次 | 500 | 500 | 无差别 |
| 日衰减 ×0.9 | 500 | 450 | 历史降温 |
| 周衰减 ×0.7 | 500 | 315 | 旧数据快速淘汰 |
| 新增 100 次 | 600 | 415 | 新数据占比提升 |
Demo 3:内存对比
| Width | Depth | CMS 内存 | 精确哈希表(100万键) |
|---|---|---|---|
| 1,000 | 4 | 16 KB | ~58 MB |
| 10,000 | 4 | 160 KB | ~58 MB |
CMS 的内存占用与数据量完全解耦 ,只取决于 width × depth。
六、参数调优建议
| 目标 | 调参方向 |
|---|---|
| 降低内存 | 减小 width,但会增大误差上界 ε = e/w |
| 提高精度 | 增大 width,或配合 Bloom Filter 做冷 key 过滤 |
| 提高置信度 | 增大 depth,降低 δ = e^(-d) |
| 更快适应变化 | 提高衰减系数(如 0.8),缩短 reset 周期 |
| 平滑统计 | 降低衰减系数(如 0.95),延长 decay 间隔 |
七、总结
Count-Min Sketch 是一种"用确定性上界换取亚线性空间"的优雅数据结构。在工程落地中,单纯的原版 CMS 往往不够------通过引入周期性重置 和多级指数衰减,我们可以在固定内存内实现"有记忆但会遗忘"的流式统计,完美适配文件访问监控、缓存热度追踪、API 限流等生产场景。
核心口诀:宽行容误差,深行保置信;哈希定位置,取小得估计;衰减控记忆,重置开新局。
参考
- Cormode, G., & Muthukrishnan, S. (2005). An improved data stream summary: the count-min sketch and its applications. Journal of Algorithms, 55(1), 58--75.
- Cormode, G. (2011). Sketch techniques for approximate query processing. Foundations and Trends in Databases. NOW publishers.
- Huang, Q., et al. (2021). Toward nearly-zero-error sketching via compressive sensing. NSDI 21, 1027--1044.
- Cao, Y., Feng, Y., & Xie, X. (2023). Meta-sketch: A neural data structure for estimating item frequencies of data streams. AAAI 2023, 6916--6924.
- Cidon, A., et al. (2017). Memshare: a dynamic multi-tenant key-value
cache. USENIX ATC 17, 321--334.