前言
在目标检测领域,YOLO(You Only Look Once)系列算法无疑是改变行业格局的存在。作为 YOLO 家族的开山之作,YOLOv1 首次将目标检测任务转化为端到端的回归问题,打破了传统两阶段检测算法的桎梏,实现了实时性与精度的平衡。
本文将从核心思想、网络架构、损失函数、NMS 后处理四个维度,深度拆解 YOLOv1 的原理。
一、YOLOv1 整体定位:One-Stage 检测的先驱
在 YOLOv1 诞生之前,目标检测主流是Two-Stage(两阶段)算法,如 R-CNN、Fast R-CNN、Faster R-CNN。这类算法流程繁琐:先生成候选框(Region Proposal),再对候选框分类与回归,导致检测速度较慢。
YOLOv1 的核心创新:将目标检测转化为回归问题 ,仅通过一个卷积神经网络(CNN),直接预测目标的边界框坐标 、置信度 和类别概率,实现 "看一眼就完成检测"。

YOLOv1 的FPS(帧率)达到 45 ,远高于 Faster R-CNN 的 7、Fast R-CNN 的 0.5,实现了实时检测;虽然 mAP(平均精度均值)略低于 SSD 和 Faster R-CNN,但兼顾了速度与精度,是 One-Stage 检测算法的里程碑。
二、核心思想:网格划分(Grid Cell)机制
YOLOv1 最核心的设计是网格划分,这是理解其原理的关键。
1. 核心规则
将输入图像划分为 S×S 个网格(Grid Cell) ,YOLOv1 中默认 S=7,即7×7 网格。
关键规则:如果某个目标的中心点落在某个网格中,该网格就负责预测这个目标。
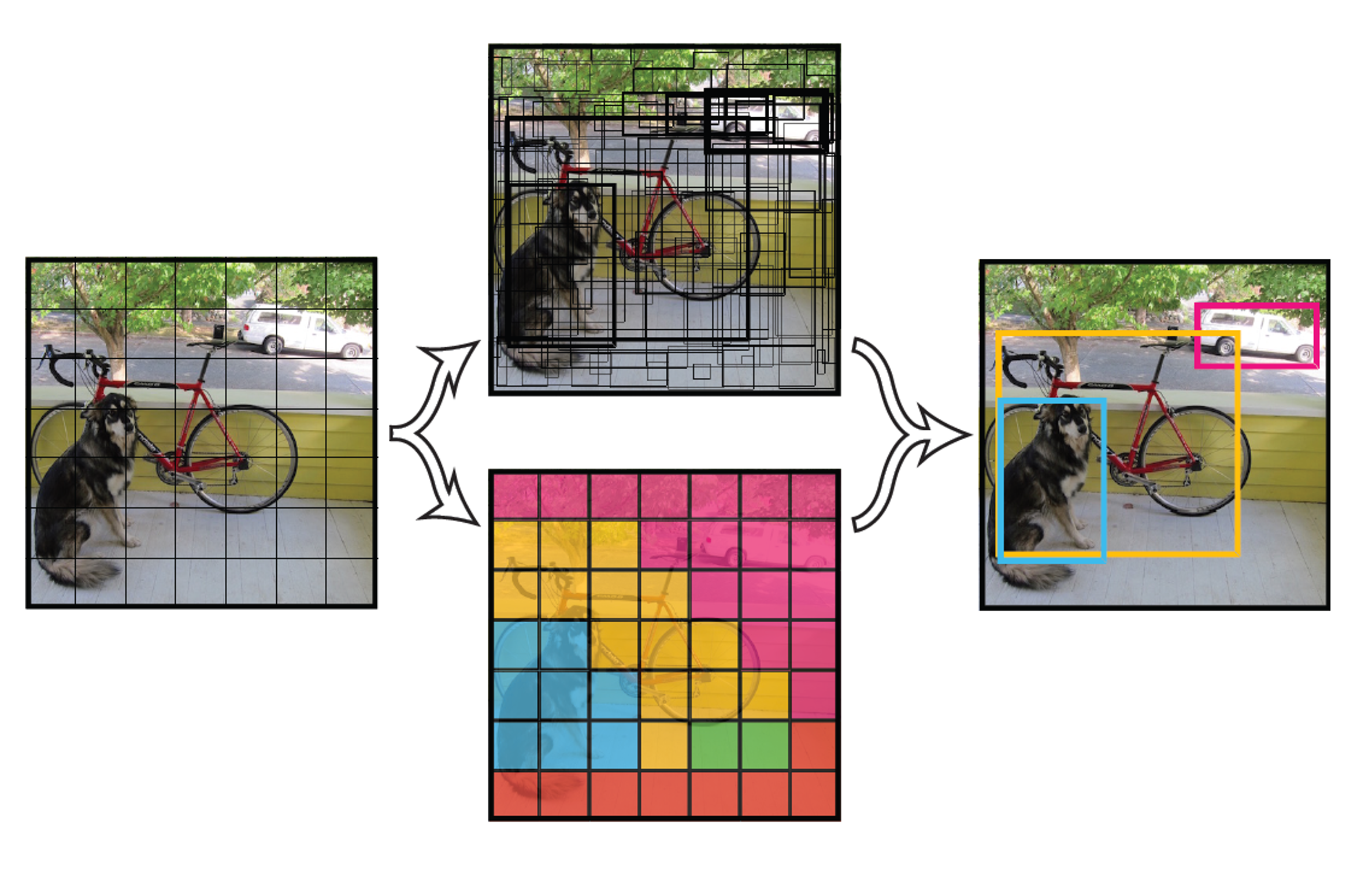
小狗的中心点落在黄色网格内,因此该网格负责预测小狗;右图中,自行车的中心点落在对应网格,由该网格负责预测。这种 "中心归属" 机制简化了检测任务的复杂度。
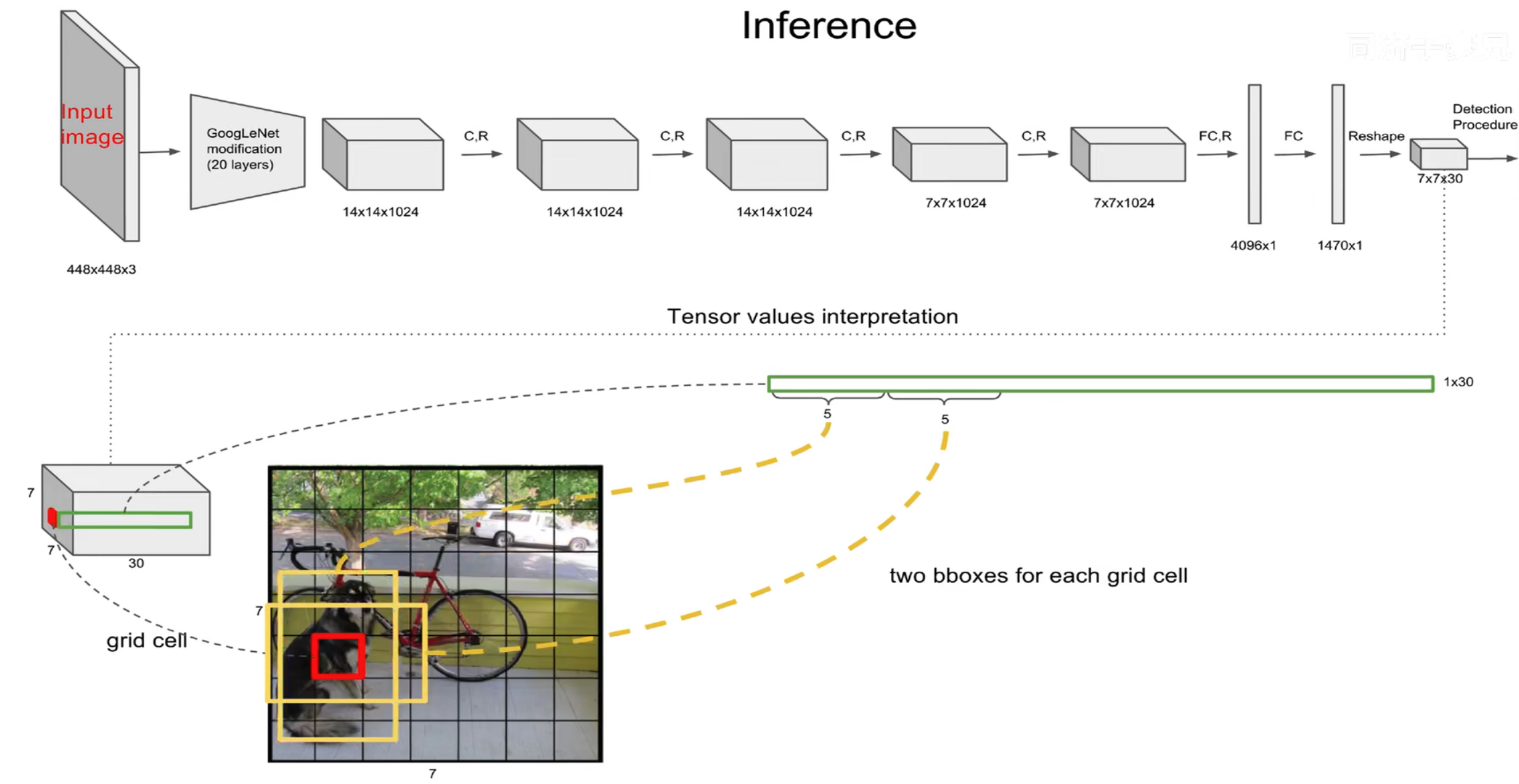
三、网络架构:从特征提取到 7×7×30 输出
YOLOv1 的网络架构借鉴GoogLeNet ,采用 "卷积层 + 全连接层" 的结构,最终输出7×7×30的张量,这是其检测结果的核心载体。
1. 网络结构细节
- 卷积层:24 个卷积层 + 2 个全连接层;
- 创新替换 :用1×1 reduction layers + 3×3 convolutional layers 替代 GoogLeNet 的 Inception 模块,减少参数并提升特征提取效率;
- 输入尺寸 :固定为 448×488×3(RGB 图像)。
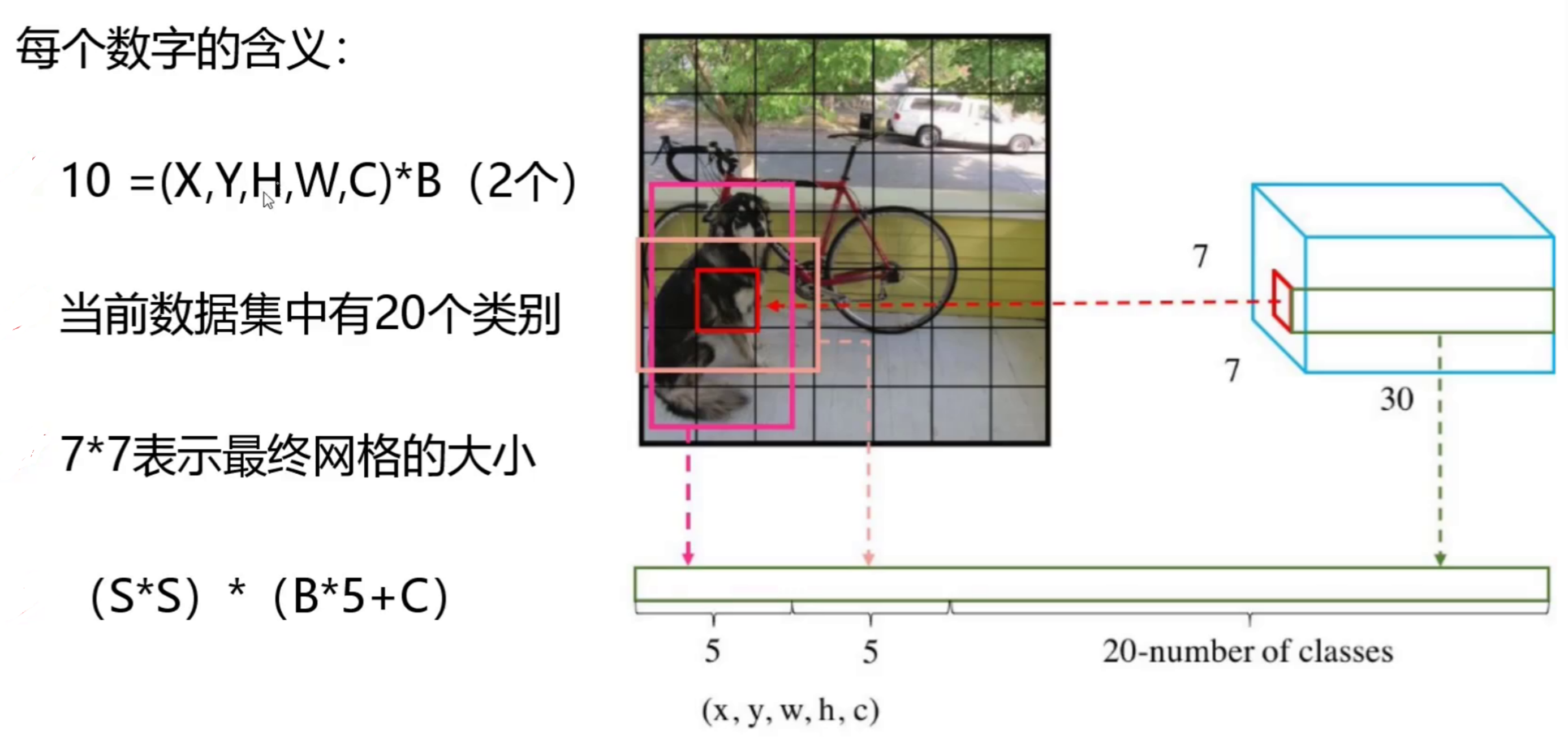
2. 输出张量解析:7×7×30 的含义
这是 YOLOv1 的核心考点,图中详细拆解了 30 维向量的构成:
维度拆解公式
输出维度=S×S×(B×5+C)
- S=7:7×7 网格;
- B=2:每个网格预测2 个边界框(Bounding Box);
- C=20:VOC 数据集的 20 个目标类别;
- 单个边界框包含 5 个信息:(x,y,w,h,confidence)
30 维向量具体构成
30=2×5+20
- 前 10 维:2 个边界框的信息(x,y,w,h,c);
- 后 20 维:20 个类别的概率(该网格包含目标的类别概率)。
坐标归一化规则
- x,y:相对于当前网格左上角归一化到 0,1 区间;
- w,h:相对于整幅图像归一化到 0,1 区间。归一化的目的是让网络训练更稳定,快速收敛。
3. 张量值解读
每个网格(Grid Cell)包含 30 个信息,其中 2 个预测框各占 5 维,剩余 20 维为类别概率,清晰对应了检测任务的三大需求:定位、置信度、分类。
四、损失函数:平衡定位、置信度与分类
YOLOv1 的损失函数是其训练的核心,设计目标是平衡位置误差、置信度误差、分类误差,通过权重系数调整不同误差的重要性。
1. 损失函数整体构成
将损失分为三大部分:位置误差、Confidence 误差、分类误差。
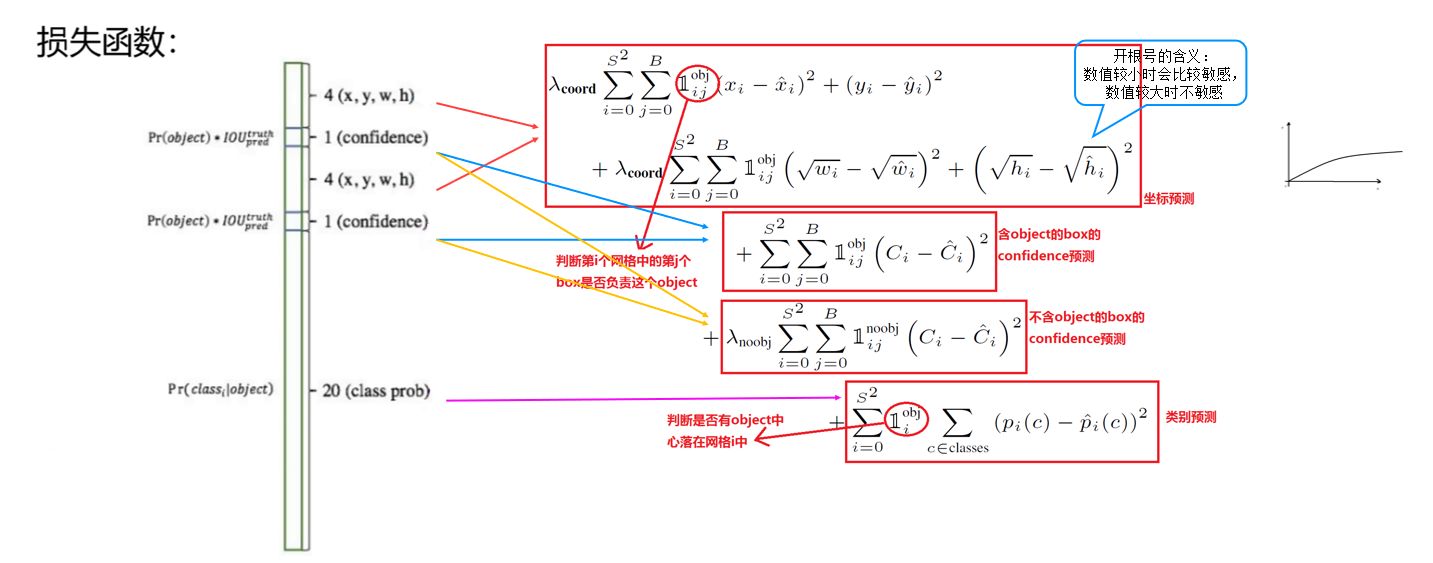
- 完整损失函数公式与解析
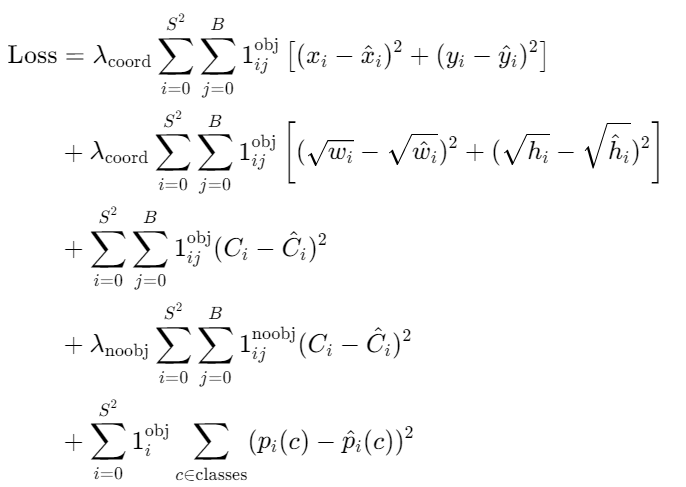
核心参数与含义
表格
| 参数 | 取值 | 含义 |
|---|---|---|
| 5 | 坐标损失权重,放大定位误差的重要性 | |
| 0.5 | 无目标置信度损失权重,降低背景误差的影响 | |
| 0/1 | 第i个网格的第j个框负责预测目标时为 1,否则为 0 | |
| 0/1 | 第i个网格的第j个框不负责预测目标时为 1,否则为 0 |
各部分误差解析
- 坐标损失 :分为中心坐标(x,y)损失和宽高(w,h)损失;宽高取平方根后计算误差,解决 "相同误差对小目标影响更大" 的问题。
- 置信度损失 :分为有目标 和无目标两部分;有目标时,置信度为预测框与真实框的 IoU(交并比);无目标时,置信度为 0。
- 分类损失:仅对包含目标的网格计算,计算类别概率的均方误差。
五、NMS(非极大值抑制):去除冗余框
YOLOv1 输出的 98 个预测框(7×7×2)中,存在大量重叠的冗余框,需要通过NMS筛选出最优框。
1. NMS 核心逻辑
NMS 的核心是 "保留置信度最高的框,抑制重叠度高的框",步骤如下:
- 计算每个框的得分(置信度 × 类别概率);
- 按得分降序排序,取出得分最高的框;
- 计算该框与其他框的 IoU,若 IoU 大于阈值(如 0.5),则抑制重叠框;
- 重复上述步骤,直到所有框处理完毕。
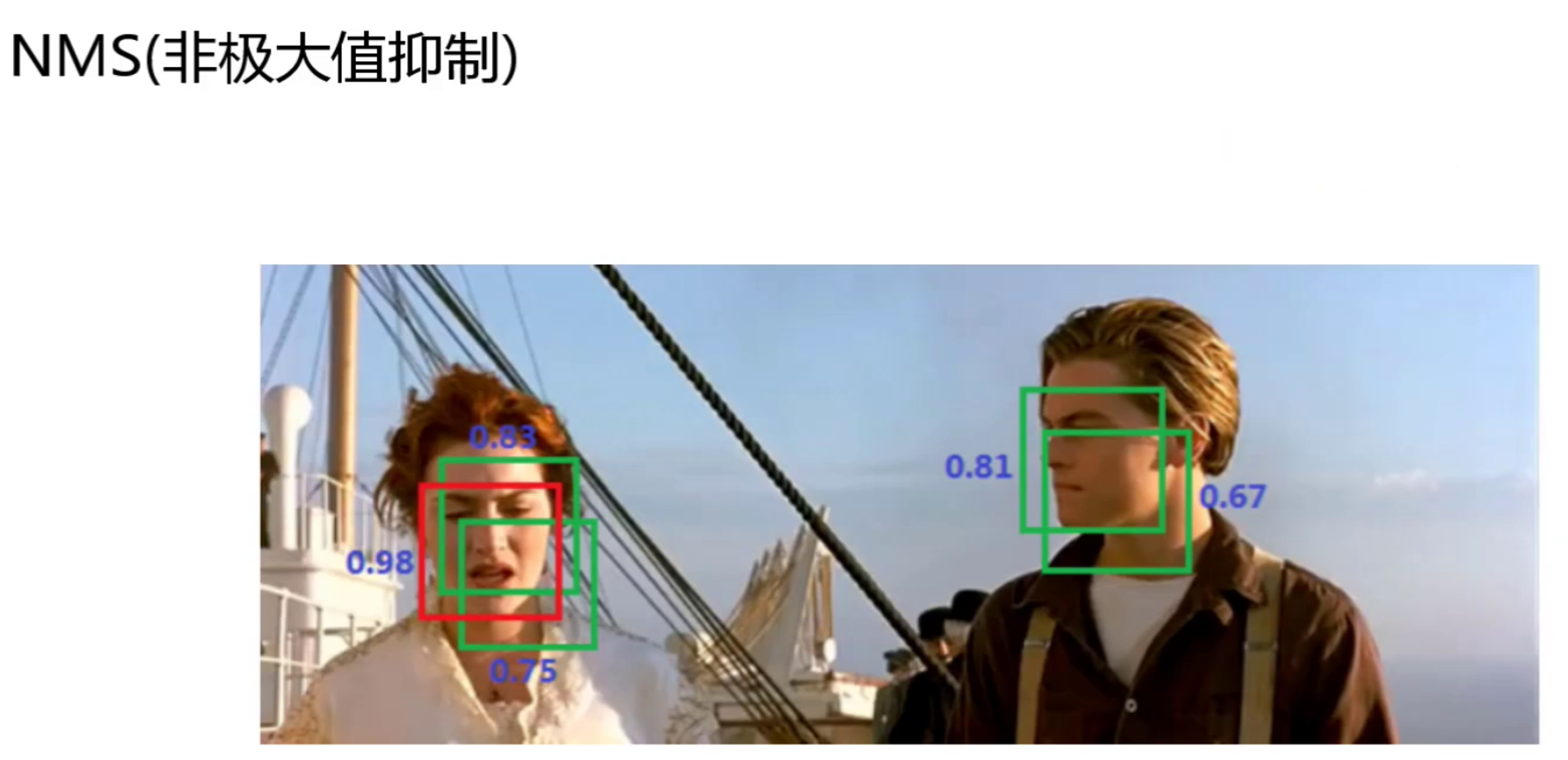
图中同一人物出现多个重叠框,经 NMS 处理后,仅保留置信度最高的框(如人物面部置信度 0.98),去除冗余框,保证检测结果的简洁性。
六、YOLOv1 优缺点总结
优点
- 速度快:One-Stage 架构,无需生成候选框,实时检测(FPS=45);
- 简单直接:端到端训练,逻辑清晰,易实现与部署。
缺点
- 网格限制:每个网格仅预测 1 个类别,无法检测同一网格内的多个重叠目标;
- 小目标检测效果差:对小目标的定位精度较低,鲁棒性不足;
- 框设计单一:仅预测 2 个框,长宽比选择有限,对复杂形状目标的适配性差。
总结
YOLOv1 作为目标检测领域的经典算法,首次实现了端到端的实时检测,通过网格划分机制将检测转化为回归问题,损失函数的设计平衡了定位、置信度与分类的需求,NMS 则优化了最终检测结果。
虽然 YOLOv1 存在小目标检测、多目标重叠检测的缺陷,但它为后续 YOLOv2、YOLOv3 等算法奠定了基础,推动了 One-Stage 检测算法的发展。