"鸽王"DeepSeek V4 终于来了~!
虽然从物理时间上看,V3 到 V4 只用了一年多时间。 但是整个 AI 界已经天翻地覆了,从我们的心里感受来说,也是过了好久好久了。
好不好的先不说,能更新,就是个好事情了。
最好是能把全球的 Token 价格打下来!
下面就赶紧来看一下,有哪些亮点吧!
目前可以看到的资料是一篇官方的公众号文章。
标题为《DeepSeek-V4 预览版:迈入百万上下文普惠时代》
我们就以这篇文章为准,来看看这次更新到底有什么亮点。
第三方平台和很多媒体号肯定是要尬吹一波的,不要当真!
这篇文章的第一个总结下的描述是:
"DeepSeek-V4 拥有百万字超长上下文,在 Agent 能力、世界知识和推理性能上均实现国内与开源领域的领先。 "
然后来看正文!
两个尺寸
DeepSeek 这次的发布没有 R 系列,而是两个 V 系列的版本!

一个叫 V4-Pro,另一个叫 V4-Flash。
这种搭配非常常见,谷歌也是一直这么来的,国内 GLM 也有专门 Flash 版本。
我把这个表格扔给了"豆包和千问",问它们这个参数在目前的国产模型中是什么级别。
它们都告诉我是顶级。
1.6T 的参数、49B 激活以及 1M 的上下文,在当前来看应该都是TOP级别的存在了!
Pro 性能拉满
然后他们重点介绍 Pro 这个模型,描述用词为"性能比肩顶级闭源模型"!
并给出了一张基准图:
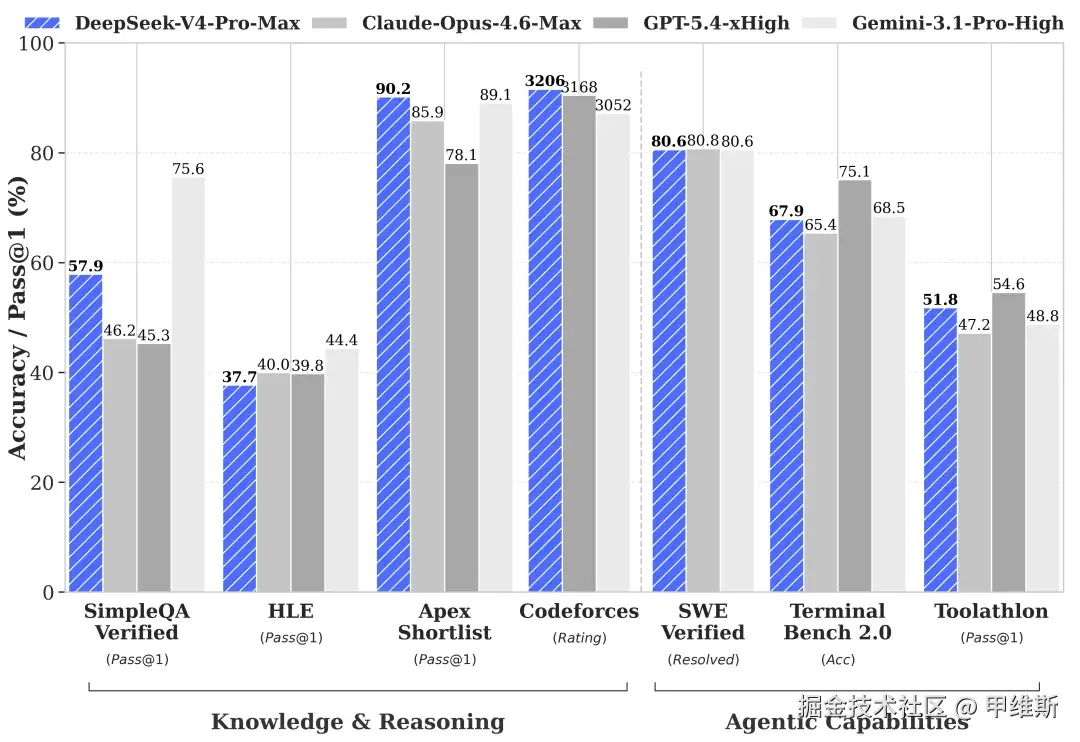
这个图表风格还是很朴实的,数据表现也很不错。
这张图主要展现了Agent 能力、世界知识、推理能力这三个维度。
世界知识和推理能力主要作为日常使用模型的核心能力。
而对于我们这种比较关注编程和工程实践的人,最关注的是智能体的能力。
更加详细的基准数据如下:
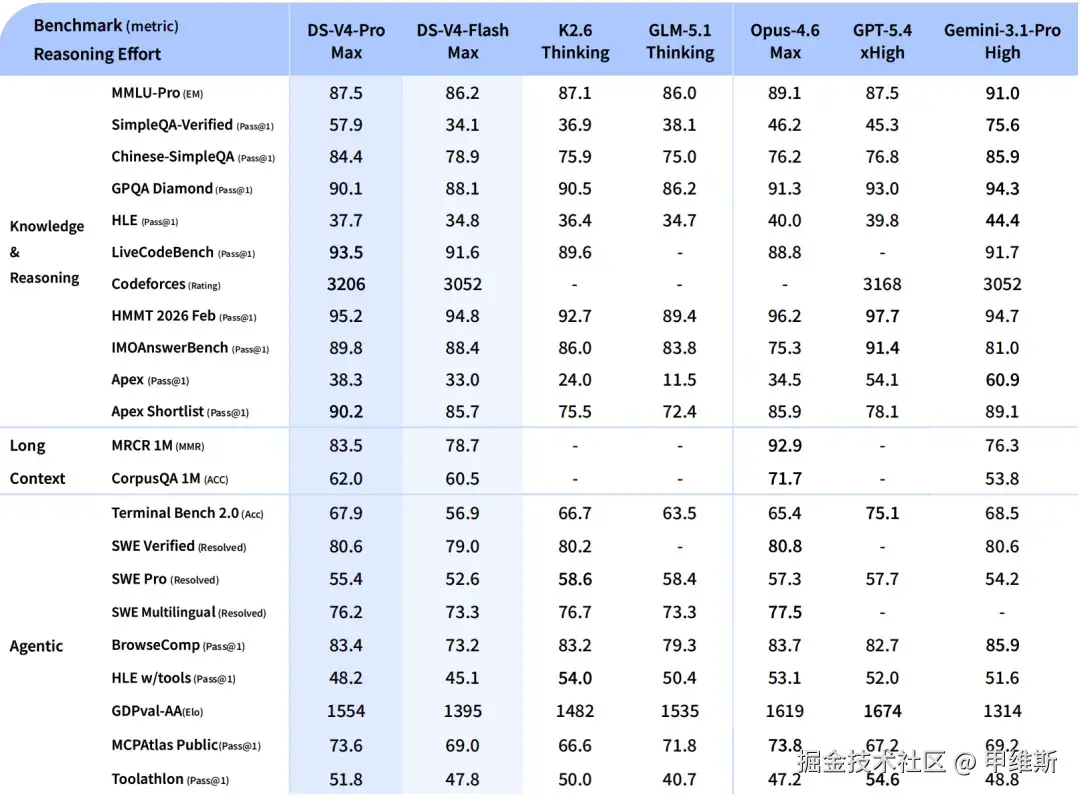
我们把目光聚焦到 Agentic 这一栏目。
这次的对比选手有 K2.6、GLM5.1、Opus4.6、GPT5.4、Gemini3.1 Pro。这些模型的配置全都拉到了 xhigh 或者 Max,也就是最强的那一档。
DeepSeek V4 的基准数据还比较全面的,有些模型发布的时候基准很少。
我们可以快速了解一下几个基准含义。
SWE 系列 主要体现代码工程能力 ,全称叫Software Engineering Benchmarks。
Terminal Bench 2.0 (Acc) ------ 终端/系统操作能力
BrowseComp (Pass@1) ------ 网页浏览与信息检索
Toolathlon (Pass@1) & MCPAtlas ------ 工具调用能力
HLE w/tools & GDPval-AA ------ 逻辑与综合评分
从图中可以看到几个亮点:
代码能力很强(SWE Verified 80.6%),这是目前行业内最难啃的骨头,比 K2.6 和 GLM5.1 高。
系统操作能力极强(Terminal Bench 67.9%),比国外的 Opus4.6 和国内的 K2.6 和 GLM5.1 高。
其他参数也非常亮眼,看起来是一个全能型的智能体模型。
当然,我也一直强调,基准测试是开卷考,有多少水分全看节操。
Flash 高效省钱
对于大模型厂商来说,Pro 一般是来秀肌肉的,而对用用户来说,真正拿来用的很可能是 Flash。因为很多时候,快和省很重要。
Flash模型的官方介绍:
Flash 在世界知识储备方面稍逊一筹,但展现出了接近的推理能力。而由于模型参数和激活更小,相较之下 V4-Flash 能够提供更加快捷、经济的 API 服务。
另外还说到了在 Agent 场景中,简单任务上与 Pro 旗鼓相当,但是高难度任务上仍有差距。
结构创新和1M
说了模型的尺寸和特点之后,就说到了 V4 开创了一种全新的注意力机制。
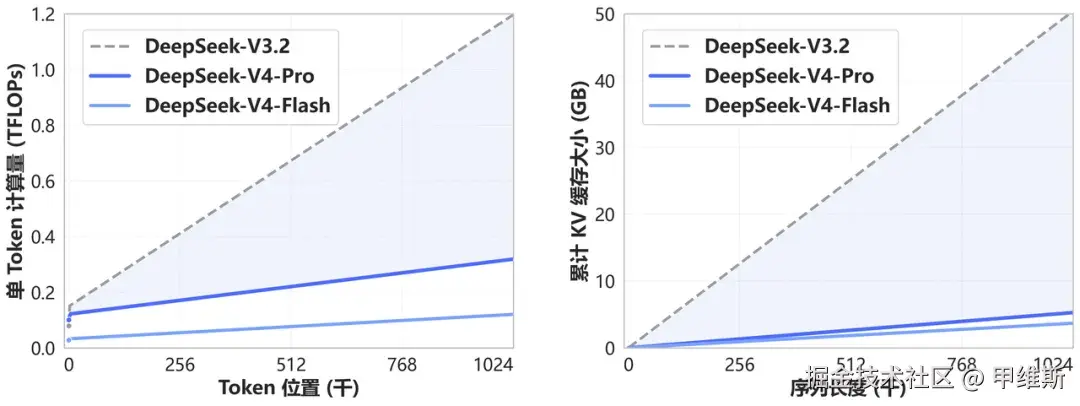
这种机制在 token 维度进行压缩,结合 DSA 稀疏注意力,实现了全球领先 的长上下文能力,并且相比于传统方法大幅降低了对计算和显存的需求。
如果真的能做到既降低技术和显存,有能提示能力,这真的是大好消息。
智能体专项优化
当前的大模型更新,没有一个不谈 Agent 的,V4 也不例外。
上面已经说了好几次了,官方文章中还是专门拿出一个大标题来讲这个事情。
主要是表达了 DeepSeek-V4 针对 Claude Code、OpenClaw、OpenCode、CodeBuddy 等主流的 Agent 产品进行了适配和优化,在代码任务、文档生成任务等方面表现均有提升。
然后举了一个 PPT 的例子:

我对 PPT 无感,大家可以看一下效果!
价格问题
这是一个非常关键的问题,尤其是对DeepSeek而言。
它刚开始大火,让大家爱不释手,其中一个重要原因就是成本低。训练成本使用成本也低。
下面来看下V4的价格:
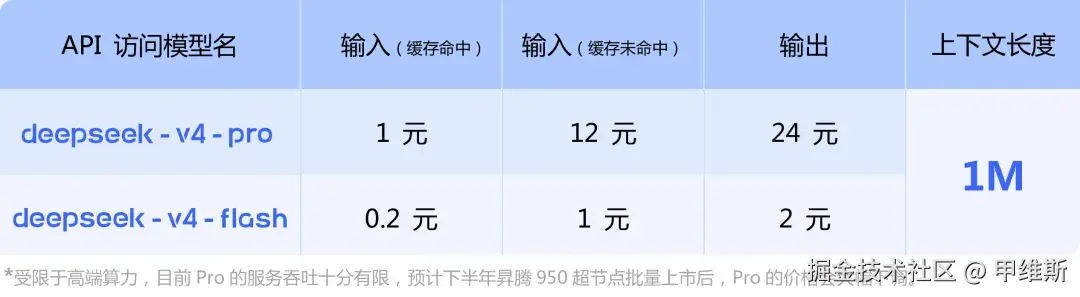
注意小字部分,昪腾950批量上市之后,Pro价格会大幅下调。压力来到了华为这边,不要拖后腿哦!
未来的事情我们未来再说,先来看看当下这个价格有没有竞争力。
我让AI帮我做了一个表格:
| 模型 | 缓存命中 | 缓存未命中 | 输出 | 上下文长度 |
|---|---|---|---|---|
| DeepSeek V4-Pro | 1 元 | 12 元 | 24 元 | 1M |
| DeepSeek V4-Flash | 0.2 元 | 1 元 | 2 元 | 1M |
| GLM-5.1 | 1.3 元 | 6 元 | 24 元 | 200K |
| Kimi K2.6 | 1.15 元 | 6.8 元 | 28.8 元 | 256K |
从这个价目表来看:
Flash 价格还是非常有竞争力的,毕竟是 1M 上下文。
Pro 的话"输入"是比较贵的,"输出"基本上和其他家的顶级模型差不多!
开源问题
DeepSeek 另一大杀手锏就是开源,最初就是因为它的开源,导致了整个国外大模型厂商的恐慌,以及国内生态的繁荣。
这一次也不例外,依旧大方开源,目前已经同步开源!
既然开源了,那么稍微有点实力的,都可以部署起来了。
供给就变多了,那么是不是Token要便宜一些了呢?
接下来可以期待下,看看能不能给我们这些小显存用户,蒸馏几个小模型来玩玩了。
目前信息并不多,大概就是这些了!
有了这个基础概念和数据,我们接下来就可以搞起来了。
钱已经充好了,开发工具也配置好了,准备开搞!
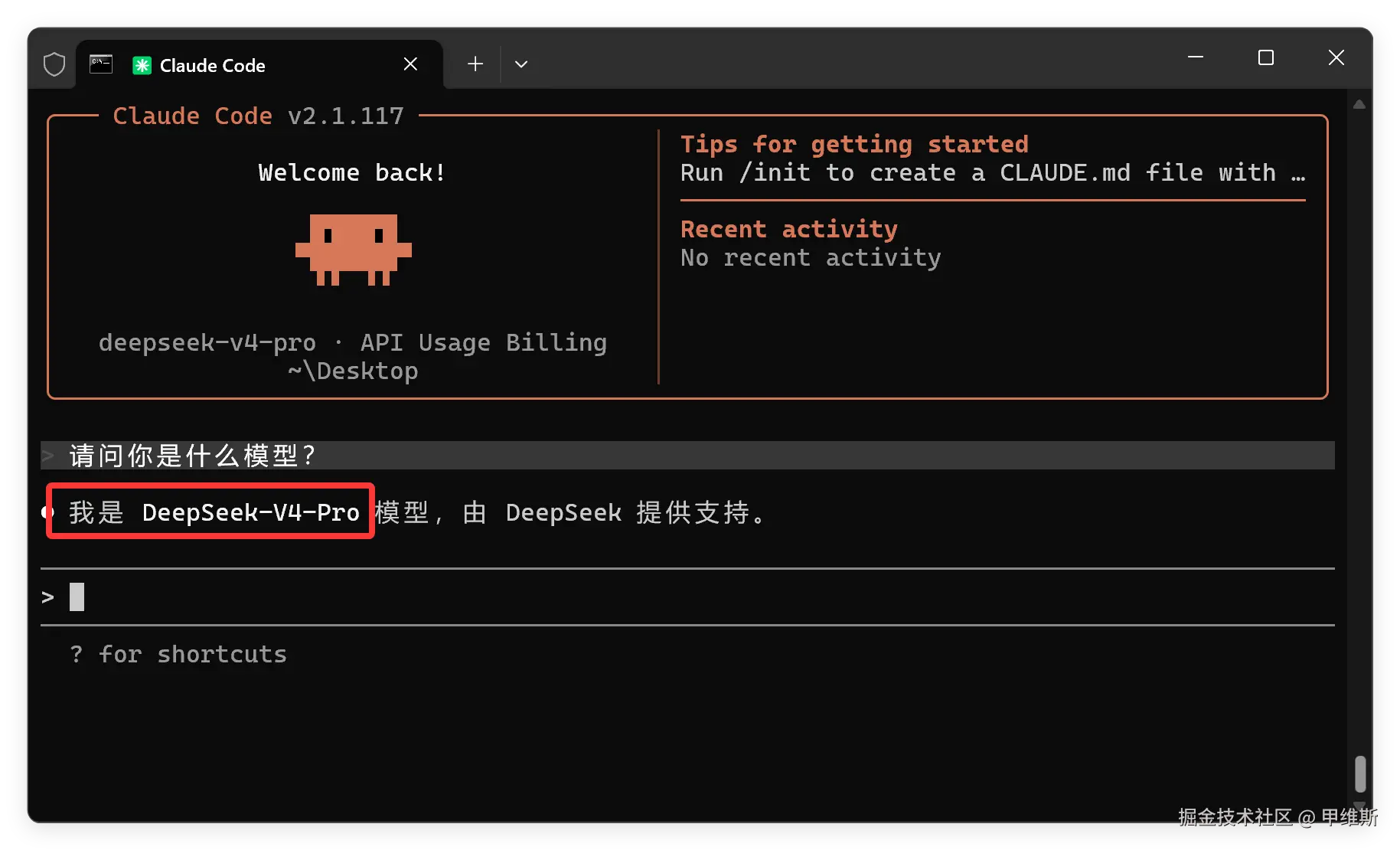
从基准数据来看,妥妥多国内第一梯队啊!
希望一切都是真的,是真的很猛!
参考链接
开发者平台:platform.deepseek.com/