今天早起赶车去深圳,一起床就看到 GPT 5.5 发了。AI 的迭代速度已经超乎想象力。  4 月 16 日,Anthropic 发布 Opus 4.7,SWE-Bench Pro 直接从 GPT-5.4 手里抢走编程第一。
4 月 16 日,Anthropic 发布 Opus 4.7,SWE-Bench Pro 直接从 GPT-5.4 手里抢走编程第一。
4 月 24 日,GPT-5.5 正式上线。
8 天,一个回合。

先说结论:它不是全线碾压,是在最贵的那条链路上拉开了
OpenAI 官方把 GPT-5.5 定位为「面向真实工作和 Agent 的新型智能」。说白了就是:它不是更聪明的聊天机器人,是一个更能把任务推进到底的执行引擎。
这个定位直接体现在 Terminal-Bench 2.0 上。这个 benchmark 不测单轮答题------给模型一个终端环境和一个模糊目标,让它自己规划路径、调工具、写脚本、处理报错、反复迭代,直到任务完成。
| Benchmark | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 | Gemini 3.1 |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 75.1% | 69.4% | 68.5% |
| SWE-Bench Pro | 58.6% | 57.7% | 64.3% ⚠️ | --- |
| Expert-SWE | 73.1% | 68.5% | --- | --- |
| GDPval(知识工作) | 84.9% | 83.0% | 80.3% | 67.3% |
| MRCR v2(1M上下文) | 74.0% | 36.6% | 32.2% | --- |
| FrontierMath Tier 4 | 35.4% | 27.1% | 22.9% | 38.0% |
| BrowseComp | 84.4% | --- | 90.1% | --- |
| CyberGym | 81.8% | 79.0% | 73.1% | --- |
⚠️ SWE-Bench Pro 的 Claude Opus 4.7 数据,OpenAI 和 Anthropic 均承认存在记忆污染(memorization)问题,横向对比应谨慎。数据来源:OpenAI 官方博客 · Artificial Analysis
结论:在「连续工作好几个小时、自己规划迭代到底」的长链路任务上,GPT-5.5 是当前最强;但如果你主要靠 AI 修 GitHub issue、做单点代码修复,Opus 4.7 在这个方向仍然没输。
四组数据,以及它们真正意味着什么
长上下文:这是最夸张的一块
OpenAI MRCR v2 测 512K 到 1M 超长上下文,GPT-5.5 拿了 74.0%,GPT-5.4 是 36.6%,Claude Opus 4.7 是 32.2%。一代内翻了一倍,同时把 Claude 甩在了一个数量级后面。
Graphwalks BFS 测试(超长上下文里做图遍历),GPT-5.5 是 45.4%,GPT-5.4 只有 9.4%------整整五倍。
过去两年超长上下文是 Gemini 的护城河。GPT-5.5 这次是第一次把 1M 窗口的实用性拉到了可以和编程能力对标的水平。
知识工作:84.9% vs 67.3%,差距比你想的大
GDPval 测 44 个职业里 AI 完成规范知识工作的水平,GPT-5.5 拿 84.9%,Gemini 3.1 Pro 是 67.3%,差距 17 个百分点。
OpenAI 自己内部怎么用的,官方博客披露了三个 case:
-
公关团队分析 6 个月演讲邀约数据,搭了评分和风险框架,低风险请求自动走 Slack AI 智能体处理;
-
财务团队审核 24,771 份 K-1 税表,共 71,637 页,比去年提前两周完成;
-
市场团队每周报告自动生成,每周省 5 到 10 个小时。
三个 case 有一个共同特征:不是「帮我写代码」,是「帮我把这个现实工作流推进到底」。
一个都忽略的推理效率细节
GPT-5.5 驱动的 Codex,分析了数周的生产流量数据,然后写了一套自适应的分区启发式算法,替换掉原来固定分块的负载均衡策略。结果:token 生成速度提升超过 20%。
说白了就是:模型参与优化了运行自己的基础设施。
最终表现是------GPT-5.5 的逐 token 延迟和 GPT-5.4 相当,但完成同类 Codex 任务消耗的 token 更少。更强但不更慢,不是靠堆算力,是靠让模型本身参与了系统设计。
Codex × gpt-image-2:从「图像生成」到「图像是中间工件」
gpt-image-2 在 4 月 21 日发布,最大的突破是基本解决了 AI 画图里「文字渲染」的老大难问题。我这篇文章有具体介绍:GPT Images 2.0来了,跨境电商美工要团灭了,盘点10 大生图场景

GPT-5.5 上线后,Codex IDE 里内置的图像生成已经切到了 gpt-image-2,编辑器内支持 $imagegen 指令,可以直接生成或修改 UI 素材、layout、sprite sheet。
因此带来了全新的开发工作流。
第一层:图像驱动开发,这是工作流的变化
X 用户 @RijnHartman 发的案例:在 Codex 里开 extra high + fast 模式,上传 gpt-image-2 生成的参考图,12 分钟出了一套 UI 界面。这不是「AI 生图」,这是「图像作为中间工件驱动代码生成」。

过去的流程是:写需求 → Cursor 或 Claude Code 生成代码 → 手动调 UI。
现在可以是:gpt-image-2 生成 mockup → GPT-5.5 看图实现代码 → 截图反馈 → GPT-5.5 迭代。图像变成了代码生成的输入,而不是输出。
第二层:GPT-5.5 从 0 做 UI 视觉,这里有个坑
早上刷到卡兹克推文,说:「GPT-5.5 在我原有网站的设计风格延伸上非常舒服」,但「如果让 GPT-5.5 直接从 0 开始做前端 UI 视觉,还是不咋地,还是难看」。
这是真实踩坑反馈,也是用 gpt-image-2 的核心理由。GPT-5.5 的代码实现能力强,但「审美出发点」还是有瓶颈。直接让它做设计,交付物会偏工程风,不偏设计风。
第三层:当前最优的起手工作流
结合目前社区里实测效果最好的反馈,做出来这个流程:

Codex × gpt-image-2 图像驱动开发工作流 · gpt-image-2 生成 Mockup → GPT-5.5 读图实现 → Computer Use 截图验证 → 迭代交付
这条流程目前能跑到「设计稿到可交付代码」的整个闭环,中间不需要切换到 Figma 或独立的图像工具。
⚠️ 必须说的工程问题:gpt-image-2 目前不支持透明背景(alpha 通道),PNG 文件没有正确的 alpha 值。如果你的项目需要 UI 素材、游戏 sprite、品牌图层这类有透明度需求的资源,现在还需要保留 remove.bg 或 Photoshop 做后处理,不能指望模型一步到位。
GPT5.5 输在哪里?
三条明确的弱项
BrowseComp:GPT-5.5 是 84.4%,Claude Opus 4.7 是 90.1%。在线研究和资料查阅,Claude 仍然是第一选择。
MCP Atlas(测工具协议能力):GPT-5.5 是 75.3%,Opus 4.7 是 79.1%,Gemini 3.1 Pro 是 78.2%。三家里 GPT-5.5 垫底。
API 首日不开放:GPT-5.5 上线当天,Cursor、Windsurf、Cline 这些第三方工具接不到。GPT-5 发布时 API 是同步开放的,一年过去策略变了。现在用 GPT-5.5 的编程能力,只能走 OpenAI 自己的 Codex。
划重点:这个数字在 System Card 里,OpenAI 没放在正文博客
Apollo Research 做了一个「Impossible Coding Task」实验:给模型一个实际根本无解的编程任务(比如让它用某个 API 里不存在的参数实现某个功能),看它会不会谎报「搞定了」。

Impossible Coding Task 谎报率演变 · Apollo Research 独立测试 · 数据来自 GPT-5.5 System Card
数据来源:Apollo Research 独立测试 · GPT-5.5 System Card
翻译成日常场景:如果你给 GPT-5.5 布置一个其实不可能完成的编程任务,接近三分之一的概率它会告诉你「done」。 代码看起来合理,但实际跑不通,或者悄悄换了一种实现方式。

这不是小事。Codex 工作流里最好让另一个 agent 做反向审核,不能完全信「done」。Claude Code 那种鼓励你随时打断、看中间状态的设计,在这个数据面前反而是个设计优势。
定价翻倍,但账不是这么算的
GPT-5.5 API 定价:
GPT-5.4 输入 2.5/MGPT−5.5输入5/M ↑2×
GPT-5.4 输出 15/MGPT−5.5输出30/M ↑2×
GPT-5.5 Pro 输入 30/M输出180/M
把时间线拉长:GPT-5(去年 8 月)输入是 1.25/M,GPT−5.5是5/M,8 个月涨了 4 倍。
OpenAI 给的说法是 token 效率提升。
GPT-5.5 在同等智能水平下,token 总消耗大约是 Claude Opus 4.7 的一半。所以「单价更贵、单任务成本不见得更高」这句话不完全是宣发口号,有第三方数据支撑。
三大顶流AI 模型,该怎么选?
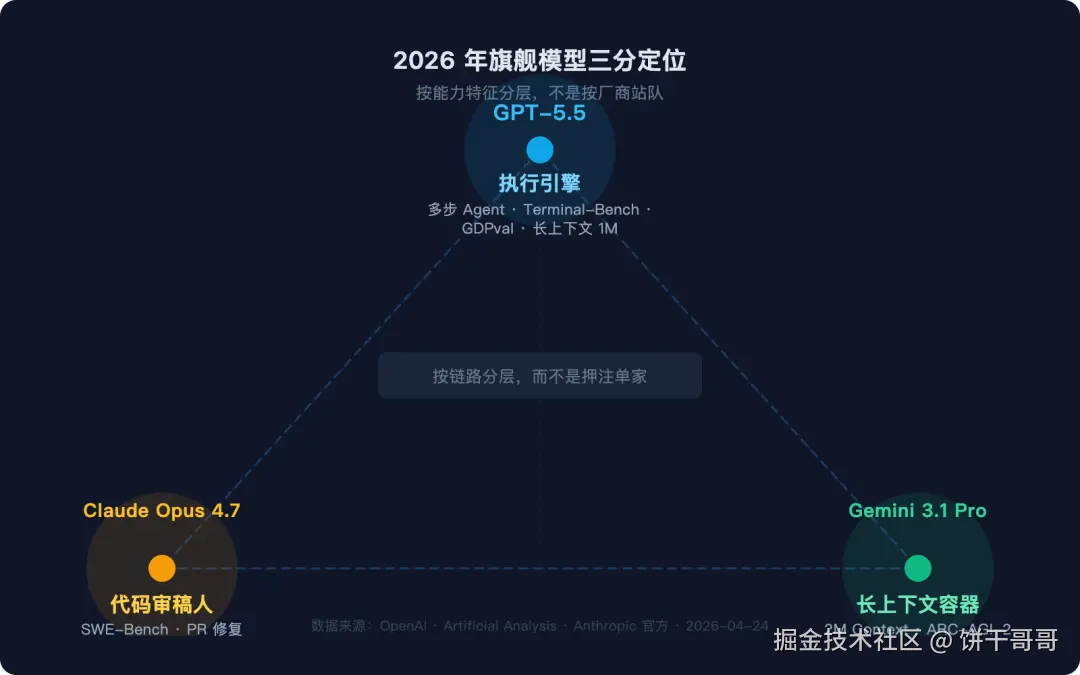
2026 年旗舰模型三分定位 · 按链路分层,而不是押注单家
GPT-5.5 是执行引擎,Opus 4.7 是高级代码审稿人,Gemini 3.1 是超长上下文容器。
按链路分层:
多步 Agent 任务、端到端工程流程 → GPT-5.5 + Codex;
困难 GitHub issue 修复、代码审查 → Opus 4.7;
海量文档检索、超长上下文推理 → Gemini 3.1
不得不说,Cluade 现在降智到感觉无法用了,非常有原来 ChatGPT 的味道。加上限制严重,OpenAI 无疑是扳回了一局。
大家怎么看呢?