在进行模型推理时,摄像头以30帧/秒的速度持续采集图像,而模型推理速度相对较慢,难以实时处理每一帧图像,从而导致丢帧现象。这种情况下,部分已完成的动作可能因对应帧被丢弃而未被识别。为解决该问题,我们设计了图像存储队列,设计如下:
frame_queue(图像待处理队列),result_queue(图像处理结果队列),record_queue(记录队列)
每个队列的最大存储数量为10
同时要开启多个线程去进行模型推理,这里max_worker设置为4
python
#定义并开启推理线程
self.process_thread = threading.Thread(target=self._process_loop, daemon=True)
self.process_thread.start()
#定义并开启记录线程
self.record_thread = threading.Thread(target=self._record_loop, daemon=True)
self.record_thread.start()
python
def _process_loop(self):
"""主循环"""
# 初始化线程池
with ThreadPoolExecutor(max_workers=self.max_workers) as self.executor:
frame_id = 0
while self.running:
try:
# --- 步骤 1: 从摄像头/输入源获取帧 ---
if not self.frame_queue.empty():
frame = self.frame_queue.get(timeout=0.1)
frame_id += 1
# --- 步骤 2: 将处理任务交给线程池 ---
try:
self.executor.submit(self._worker_task, frame, frame_id)
except Exception as e:
print(f"提交任务失败: {e}")
# --- 步骤 3: 检查并获取处理结果 (非阻塞) ---
try:
while not self.result_queue.empty():
res_id, annotated_frame = self.result_queue.get_nowait()
# 更新显示帧
with self.lock:
self.current_annotated_frame = annotated_frame
# 录像
if self.is_recording and frame is not None:
try:
self.record_queue.put_nowait(frame)
except queue.Full:
pass
except queue.Empty:
pass
time.sleep(0.001) # 稍微让出CPU
except Exception as e:
print(f"主循环错误: {e}")
continue推理线程可同步执行
python
def _worker_task(self, frame, frame_id):
"""线程池中执行的具体任务"""
try:
# 1. 执行算法处理
annotated_frame = self._process_frame(frame)
# 2. 将结果放入回传队列
try:
self.result_queue.put_nowait((frame_id, annotated_frame))
except queue.Full:
pass # 如果结果队列满了,丢弃旧结果
except Exception as e:
print(f"处理线程出错: {e}")记录线程实现如下,将记录功能单开一个线程,可以有效避免写入延迟
python
def _record_loop(self):
"""录像线程:独立运行,只负责写入"""
while self.running:
try:
frame = self.record_queue.get(timeout=0.1)
if self.is_recording and self.video_writer is not None:
self.video_writer.write(frame)
except queue.Empty:
time.sleep(0.01)
except Exception:
continue当开启多线程推理后,显存占用与利用率对比如下:
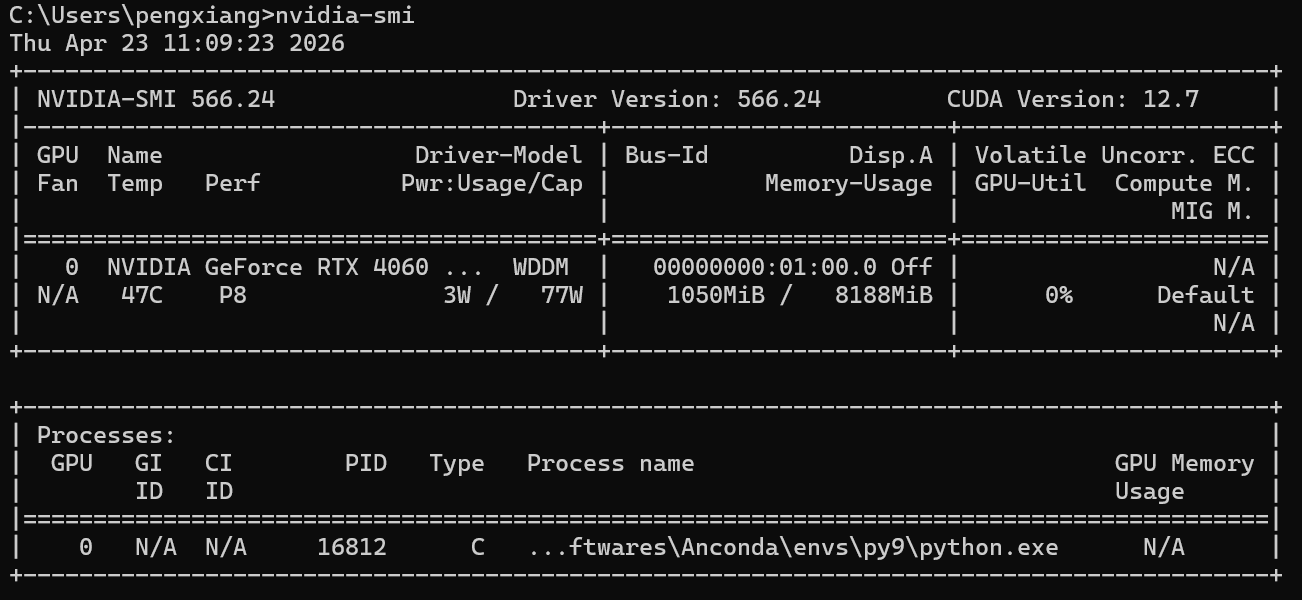
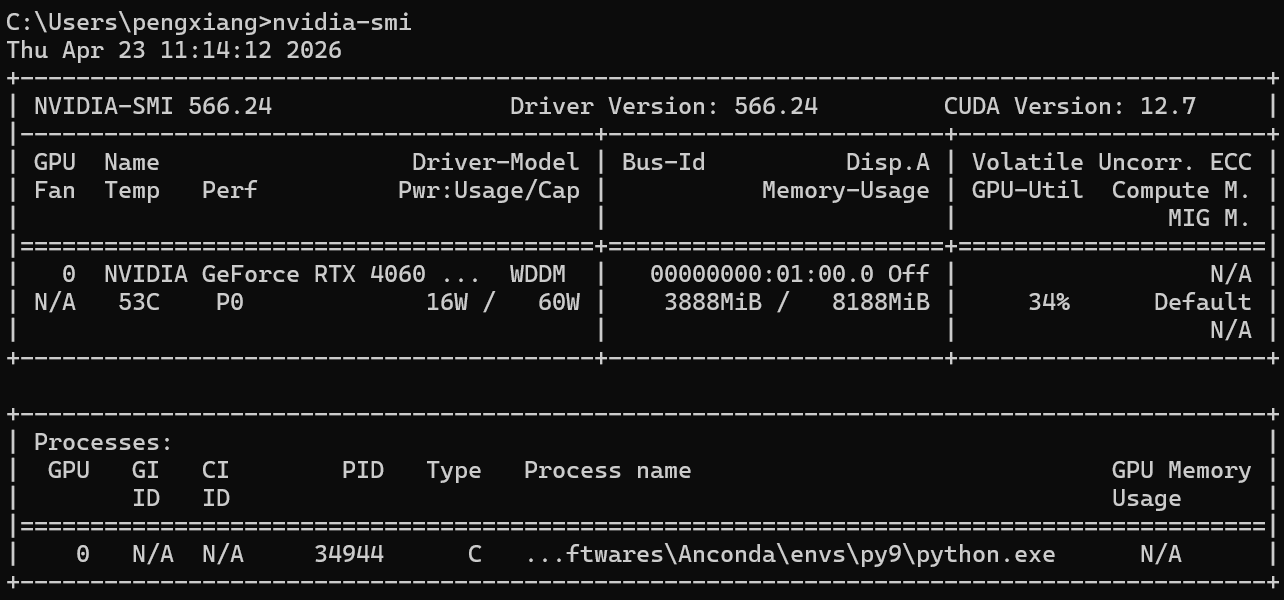
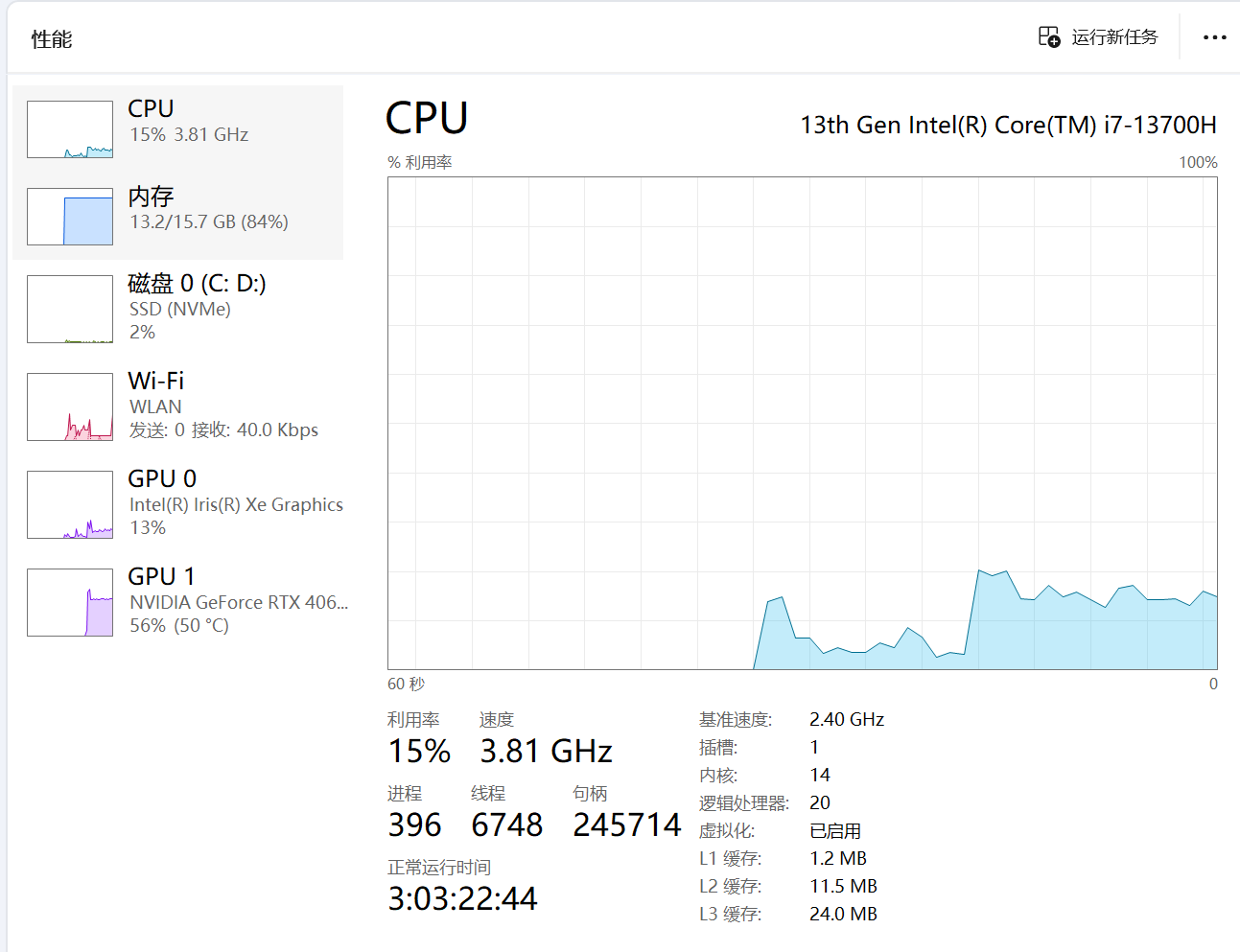
通过任务管理器我们可以看到,CPU依旧坚挺
通过这个方法,可以有效的解决推理延迟导致的丢帧问题,然而,正当我满心欢喜时,发现我保存的图像出现了乱码现象,如下图所示:


这是由于我开启了多线程,每个线程中的模型均检测到了对应动作,此时同时进行了图像写入操作导致的,这是多线程环境下的经典"踩踏"问题:多个线程同时检测通过,然后一起挤向 cv2.imwrite,结果就是文件被覆盖、路径冲突,甚至程序崩溃。
要解决这个问题,核心思路就一个:让"写文件"这件事变成"单行道"。可以用 queue 把保存图片的任务从推理线程里剥离出来,交给一个专门的"后台搬运工"去处理。这样推理线程只管算,算完把图片扔进篮子就走,完全不会堵车。
这是一种典型生产者-消费者模式
推理线程(生产者):只负责计算,算出结果后,把 (图片数据, 文件名) 扔进一个队列,然后立刻返回继续干活。
保存线程(消费者):专门有一个后台线程盯着这个队列,谁把图片扔进来,它就按顺序一张张保存。
设计如下:
python
self.save_queue = queue.Queue(maxsize=20)
# --- 新增:启动后台保存线程 ---
self.save_thread = threading.Thread(target=self._save_worker, daemon=True)
self.save_thread.start()
def _save_worker(self):
"""后台线程:专门负责从队列取图片并保存到硬盘"""
while True:
try:
# 从队列获取任务 (阻塞式,没任务时会等待)
img_data, img_path = self.save_queue.get()
if img_data is None:
break # 收到 None 信号表示退出
# 确保目录存在
os.makedirs(os.path.dirname(img_path), exist_ok=True)
# 执行保存
cv2.imwrite(img_path, img_data)
print(f"[SaveWorker] 保存成功: {img_path}")
# 告诉队列任务完成
self.save_queue.task_done()
except Exception as e:
print(f"[SaveWorker] 保存出错: {e}")效果如下,尽管还是会多次写入,但此时图像每次只保存一张,因此便避免了图像重复写入问题。
