背景与价值
在云原生和微服务架构日益普及的今天,可观测性数据(日志、指标、链路追踪)呈爆炸式增长。观测云 OpenAPI 数据查询接口为开发者和运维团队提供了一种编程化、自动化获取这些高价值数据的能力,例如:
- 自动化数据查询:将观测云数据集成到内部系统或第三方平台;
- 构建自定义仪表盘:根据业务需求灵活展示监控数据;
- 实现数据联动:打通观测云与企业内部的数据分析流程;
- 批量数据处理:高效获取大规模监控数据进行离线分析。
OpenAPI 概览
观测云将 OpenAPI 作为开放能力的关键构成,支持工作空间配置和数据查询,通过请求头中附加的基于角色的 API Key 进行认证鉴权,默认请求频率限制为同一 API Key 每分钟最多请求 20 次、同一工作空间每分钟最多请求 200次。接入点和请求头等请参考官方文档 docs.guance.com/open-api/ 。
前置条件
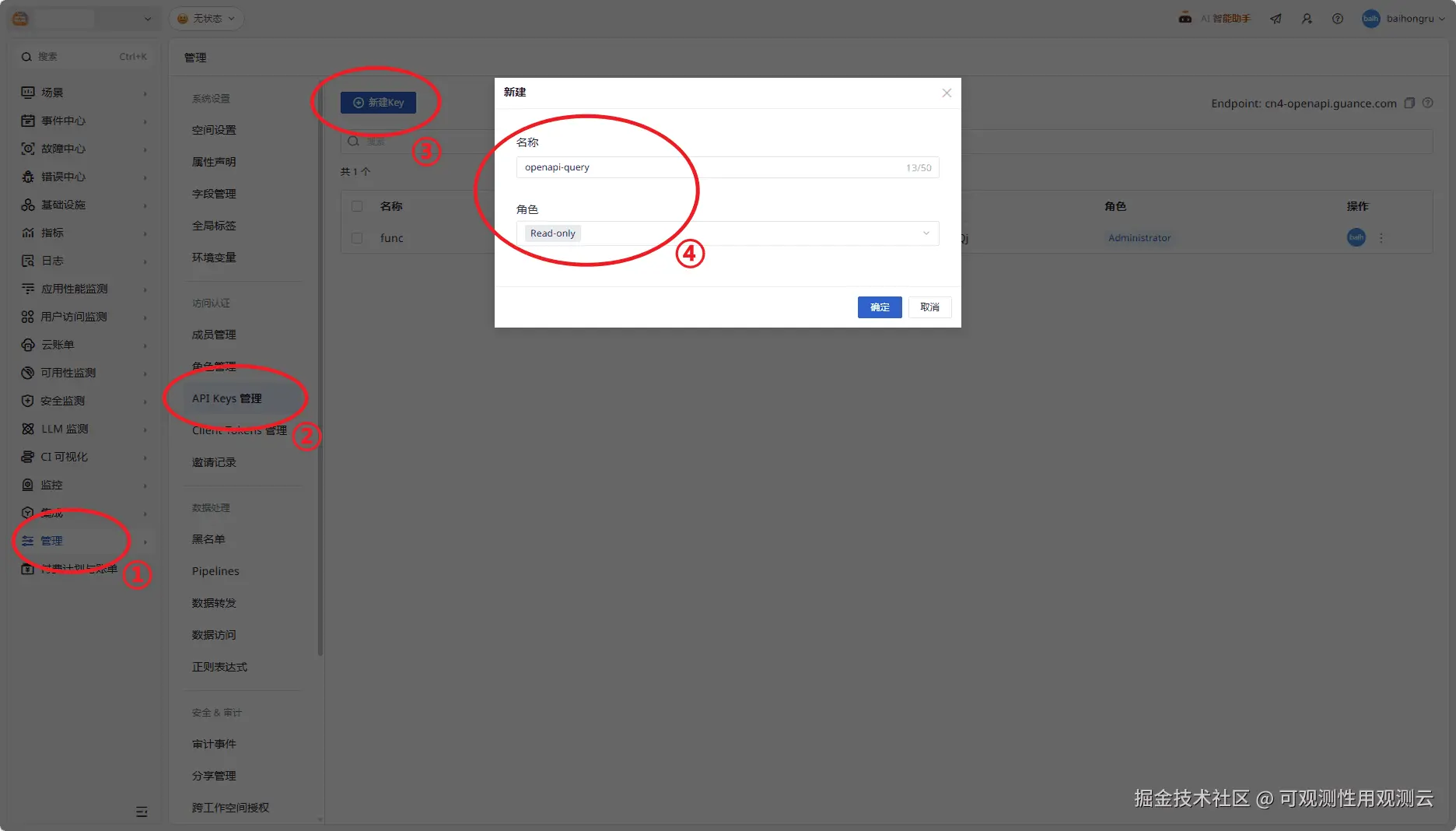
- 创建 API Key:确保登录用户有所需的操作权限。登录观测云控制台,点击【管理】-【API Keys 管理】-【新建 Key】,填写名称与角色,本实践仅使用数据查询接口,因此使用内置角色 "Read-only"。
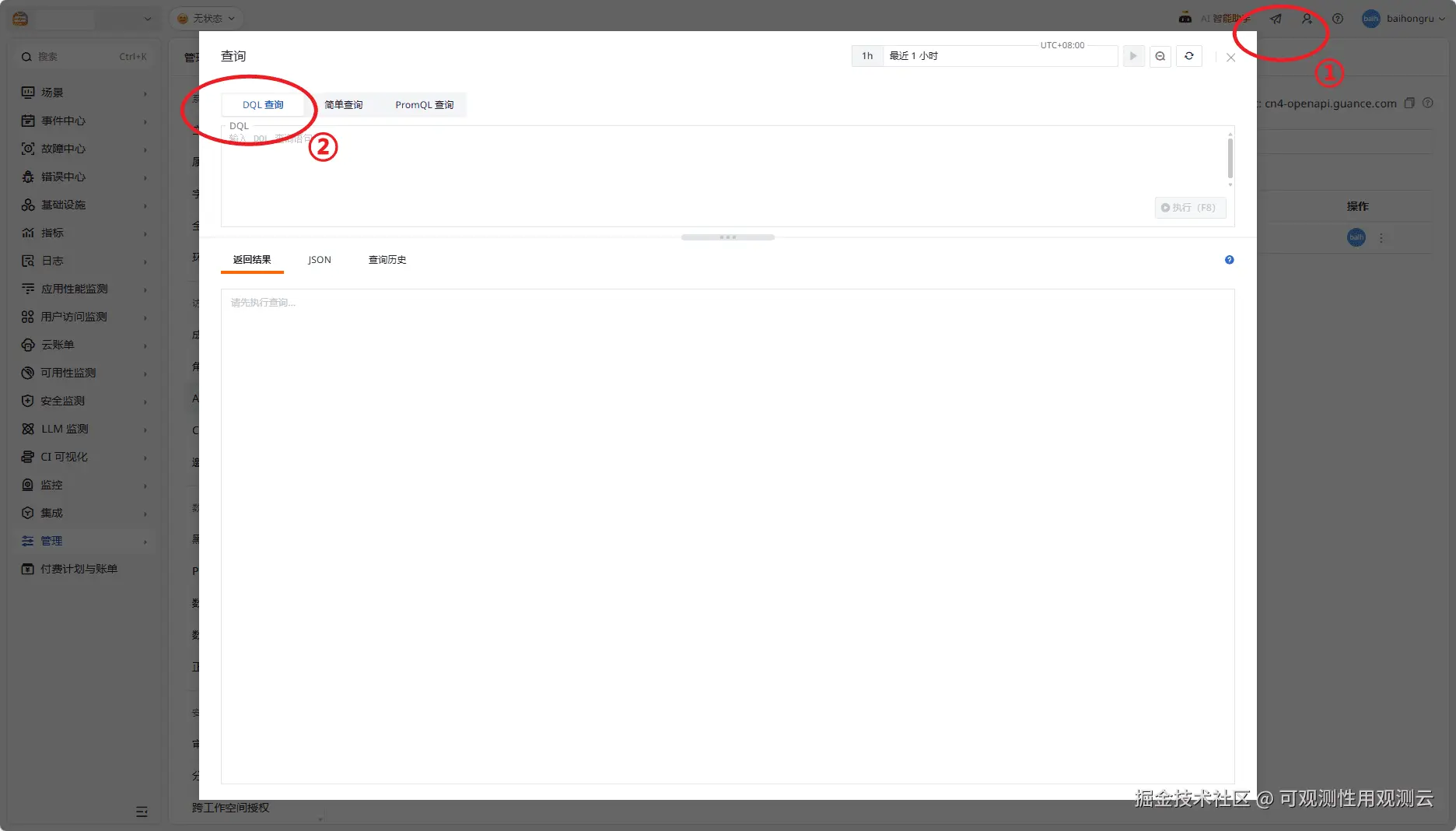
- 调试 DQL:数据查询接口通过传入 DQL 查询语句进行查询,建议在调用接口之前确认查询语句,完整语法请参考 docs.guance.com/dql/ ,可以在观测云界面的查询工具中进行调试,点击快捷方式 -【查询工具】,选择 DQL 查询模式,支持语法校验和自动补全:
数据查询接口
基本信息
- 方法:POST
- 接口:/api/v1/df/query_data_v1
请求参数解析
queries,为 query 对象组成的列表,每个 query 对象中包含独立的 DQL 语句,依次实现单次请求返回多组查询结果,以下是单个 query 对象的关键参数:
| 序号 | 参数 | 类型 | 是否必填 | 描述 |
|---|---|---|---|---|
| 1 | $.queries\*.qtype | String | 否 | 默认为 dql,可选:dql:DQL 类型查询promql:PromQL 类型查询 |
| 2 | $.queries\*.query.q | String | 是 | 查询语句 |
| 3 | $.queries\*.query.timeRange | Array | 否 | 执行查询的时间范围,默认值最近 30 分钟,毫秒时间戳列表:start_time, end_time |
| 4 | $.queries\*.query.interval | Int | 否 | 聚合时间分片间隔,单位秒 |
| 5 | $.queries\*.query.offset | Int | 否 | 分页偏移量,DQL 语句中的子句优先级高于此参数 |
| 6 | $.queries\*.query.limit | Int | 否 | 分页大小,DQL 语句中的子句优先级高于此参数 |
| 7 | $.queries\*.query.orderby | Array | 否 | 排序列表,默认按照输出的 time 字段降序排列,DQL 语句中的子句优先级高于此参数 |
| 8 | $.queries\*.query.cursor_time | Int | 否 | 分段查询阈值,第一次分段查询时设置为 timeRange 中的 end_time,此后的分段查询,将 cursor_time 设置为响应中的 next_cursor_time 字段的值,next_cursor_time 为 -1 时表示无新数据,注意,分段查询仅在存储引擎为 GuanceDB 3.0 时生效 |
| 9 | $.queries\*.query.cursor_token | String | 否 | 在分段查询中,将 cursor_token 设置为响应中的 next_cursor_token 字段的值,以确保相同时间戳的数据不被分段跳过,注意,分段查询仅在存储引擎为 GuanceDB 3.0 时生效 |
| 10 | $.queries\*.query.disable_sampling | Bool | 否 | 是否禁用采样,默认 false,仅对部分聚合类查询生效 |
| 11 | $.queries\*.query.ignore_cache | Bool | 否 | 是否禁用缓存,默认 false |
| 12 | $.queries\*.query.disableMultipleField | Bool | 否 | 是否禁用单列模式,默认为 true,打开单列模式可有效减少返回数据的体积,为 false 时 $.queries\*.query.funcList 参数将失效 |
场景解析
数据查询场景和查询方法分类如下,需根据不同的查询类型合理配置查询参数:
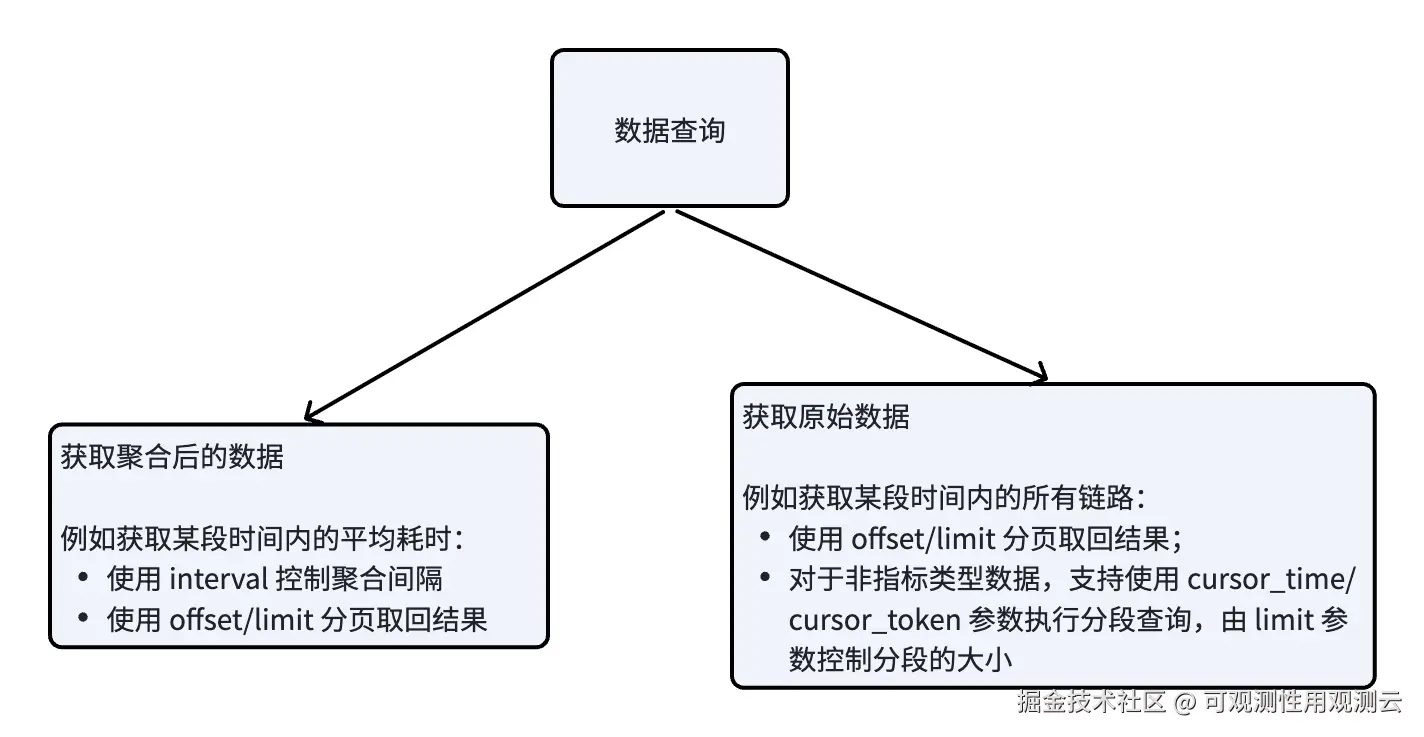
示例一:查询指定 Span 的平均耗时(获取聚合后的数据)
请求体,参数说明见注释:
json
{
"queries": [
{
"qtype": "dql",
"query": {
"q": "R::resource:(AVG(`duration`) AS `avg(duration)`) { `service` = 'demo' AND `resource` = 'GET /health' }",
"interval": 60, // 查询时间范围内每 60 秒聚合一个值
"offset": 0,
"limit": 500,
"orderby": [
{
"time": "desc"
}
],
"timeRange": [
1774144800000, // 2026-03-22 10:00:00
1774145100000 // 2026-03-22 10:05:00
],
"disable_sampling": true // 禁止聚合采样
}
}
]
}响应体,仅包含重要返回数据及其注释:
json
{
"code": 200, // 状态码,与 HTTP 响应码保持一致,无错误时固定为 200
"content": { // 接口响应数据
"data": [
{
// ...
"next_cursor_time": -1, // 下次请求的 cursor_time,因本次查询为聚合查询,返回为 -1
"next_cursor_token": "", // 下次请求的 cursor_token,因本次查询为聚合查询,返回为空
// ...
"sample": 1, // 采样率,为 1 表示采样率 100%,即未采样
// ...
"series": [ // 数据查询结果
{
"column_names": [
"time",
"avg(duration)"
],
"columns": [
"time",
"avg(duration)"
],
"units": [
null,
"time,ns"
],
"values": [ // 每间隔一个 interval 秒聚合一个数据点
[
1774145040000, // 2026-03-22 10:04:00
1462101213.4054055
],
[
1774144980000, // 2026-03-22 10:03:00
520552891.31707317
],
[
1774144920000, // 2026-03-22 10:02:00
403010784
],
[
1774144860000, // 2026-03-22 10:01:00
496579998.11764705
],
[
1774144800000, // 2026-03-22 10:00:00
608395087.6444445
]
]
}
],
"window": 60000
}
],
// ...
},
"errorCode": "", // 错误码,空表示无错误
"message": "", // 错误信息
"success": true, // 接口调用状态,为 true 时表示调用成功
"traceId": "69bfdf42000000001ac3936f1436ac54" // 请求的跟踪 ID
}示例二:获取指定类型的所有 Span(获取原始数据)
采用分段查询方式,请求体,参数说明见注释:
json
{
"queries": [
{
"qtype": "dql",
"query": {
"q": "R::resource:(`*`) { `service` = 'demo' AND `resource` = 'GET /health' }",
"limit": 1, // 分段大小为 1
"cursor_time": 1774145100000, // 初始请求取 timeRange 中的结束时间,后续请求取响应中的 next_cursor_time 的值
"cursor_token": "", // 初始请求取空值,后续请求取响应中的 next_cursor_token 的值
"orderby": [
{
"time": "desc"
}
],
"timeRange": [
1774144800000, // 2026-03-22 10:00:00
1774145100000 // 2026-03-22 10:05:00
]
}
}
]
}响应体,仅包含重要返回数据及其注释:
json
{
"code": 200, // 状态码,与 HTTP 响应码保持一致,无错误时固定为 200
"content": { // 接口响应数据
"data": [
{
// ...
"next_cursor_time": 1774145099284000, // 将值作为下次请求的 cursor_time
"next_cursor_token": "1774145099284000000-R_1774145099284_d6vksl01so5nqftmhv20", // 将值作为下次请求的 cursor_token
// ...
"series": [ // 数据查询结果
{ // 将以单列的方式输出一条原始数据的所有字段,示例响应仅保留了 __block_id 字段,禁用单列模式时,列名、列值等分别作为一个单独的数组
"column_names": [
"time",
"__block_id"
],
"columns": [
"time",
"__block_id"
],
"units": [
null,
null
],
"values": [
[
1774145099284,
2135893696351448600
]
]
},
// ...
],
// ...
}
],
// ...
},
"errorCode": "", // 错误码,空表示无错误
"message": "", // 错误信息
"success": true, // 接口调用状态,为 true 时表示调用成功
"traceId": "69bfec720000000042c950e749998eff" // 请求的跟踪 ID
}最佳实践
- 权限最小化:为不同的应用场景(如报表系统、告警机器人)创建独立的 API Key,并赋予最小必要权限;
- 避免触发 API 限流:一次请求中包含多条查询语句,尽量在应用层增加历史数据缓存;
- 错误处理:必须对 API 返回的错误进行处理,例如实现指数回退重试机制;
- 监控请求 OpenAPI 的服务:确保相关业务健康运行;
- 在接口参数中设置聚合间隔和排序字段,而非在 DQL 中设置:DQL 支持以时间子句设置聚合间隔,但是 API 返回的点数受到优先级规则限制,只有 interval 参数和时间子句中的间隔保持一致时才能获得符合预期的结果,因此,建议使用 API 参数设置聚合间隔和排序方式,在其他场景中,如果 API 参数与 DQL 子句功能重复,仍然建议优先使用 API 参数而非 DQL 子句,利于编码且语义统一;
- 获取原始数据时关闭单列模式,以减小响应体的体积:请求时设置 disableMultipleField=false 即可关闭单列模式,注意,此时用于聚合查询的 funcList 参数将失效。
总结
本文档围绕观测云 OpenAPI 数据查询接口展开,介绍了其在云原生可观测场景下的应用价值,说明了接口认证、限流规则及创建 API Key、调试 DQL 语句等前置准备,详细解析了 /api/v1/df/query_data_v1 接口的请求参数,并通过聚合数据查询、原始数据分段查询两个典型示例展示使用方法,最后给出权限、限流、错误处理等方面的最佳实践,可帮助开发者快速接入并规范使用该接口实现监控数据的程序化获取与应用。