大家好,我是子昕。
DeepSeek V4,本来是 2 月发布的。
现在是 4 月。
中间这三个月,整个行业往前冲了一轮。Claude 4.7 发了,GPT-5.5 发了,国内的 MiMo 2.5 Pro 发了,Kimi K2.6 发了。
所有人都在等 DeepSeek,然后所有人都先走了。
只有它没来。
不是出了问题,是它在做一件必须做成的事。
它为什么迟到了三个月
先说这个,因为这才是这次发布最重要的线索。
V4 推迟的原因,官方没有正面解释,但有几条信息可以拼在一起看。
官方技术报告里明确写道:V4 在英伟达 GPU 和华为昇腾 NPU 两个平台上都完成了方案验证。路透社此前报道,DeepSeek 没有给英伟达或 AMD 提供早期访问权限,而是将早期版本开放给了国内供应链,尤其是华为。
发布当天,华为昇腾 CANN 官方直播了 V4 在昇腾平台的首发,寒武纪同日确认完成 Day 0 适配并开源代码。
36kr 的报道援引知情人士称,延迟与将训练框架适配国产芯片有关,内部也曾出现过训练失败和方向分歧。这条信息来自第三方,不是官方披露,但结合上面那几条放在一起,方向是对得上的。
这不只是一个芯片适配的技术决策,这是一个赌注。
美国的出口管制一直在收紧,中国开发者能买到的英伟达芯片越来越少。
如果 V5、V6 还依赖英伟达,整个技术路线就建立在一个随时可能被掐断的供应链上。这件事必须在 V4 上做成,否则就没有下一步。
它做成了。
如果这条路被验证可行,意味着什么?
国内一众大模型厂商都可以沿着这条路走。整个中国 AI 产业有了一条不依赖美国芯片的技术路径。
这件事,比 V4 跑了多少分更值得关注。
两个模型,定位完全不同
扯完背景,回到模型本身。
这次发了两个版本,都是 MoE 架构,都标配 1M 上下文。
官网和 App 同步上线,专家模式对应 V4-Pro,快速模式对应 V4-Flash,直接可用。
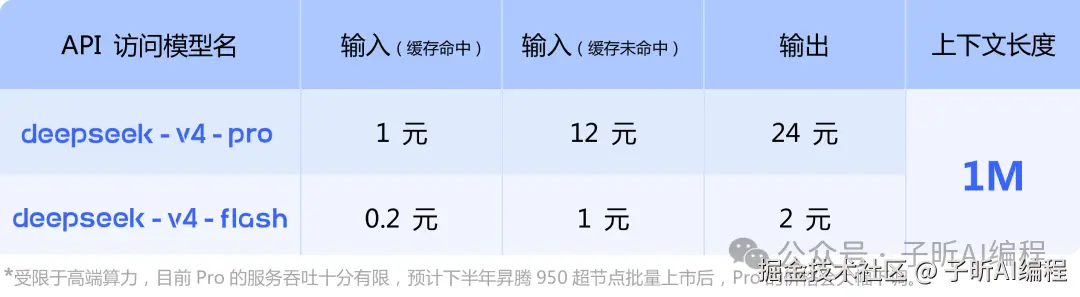
V4-Pro:1.6 万亿总参数,49B 激活参数
- 定位:复杂推理、长链路 Agent、高质量输出场景
- API 定价:输入 12 元/百万 tokens,输出 24 元
- 缓存命中后输入降到 1 元
V4-Flash:284B 总参数,13B 激活参数
- 定位:快速响应、经济型任务、简单 Agent
- API 定价:输入 1 元,输出 2 元
- 缓存命中后输入仅需 0.2 元

1.6 万亿的总参数刷新了国产开源模型的纪录,比上一代 V3.2 的 671B 大了 2.4 倍。
但激活参数只从 37B 增加到 49B------参数规模扩了,但每个 token 实际用到的算力没有等比增长。
知识容量更大,推理效率不掉,这就是 MoE 做大参数的玩法。
Benchmark 怎么看
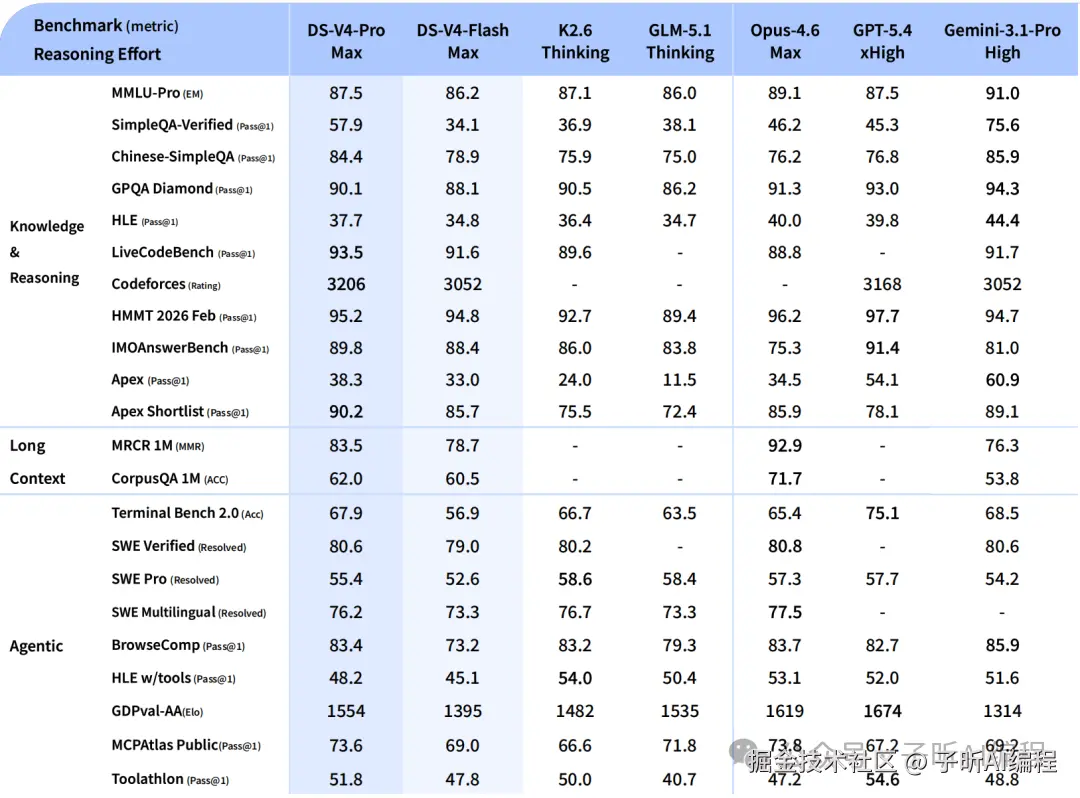
各模型横向对比,含 DS-V4-Pro、DS-V4-Flash、K2.6、GLM-5.1、Opus-4.6、GPT-5.4、Gemini-3.1-Pro
把这张表里的成绩分层来看:
V4-Pro 的强项
- LiveCodeBench:93.5,表里第一
- HMMT 2026 Feb(数学竞赛):95.2
- SWE Verified:80.6,和 Claude Opus 4.6(80.8)基本打平
相对弱的地方
- Terminal Bench 2.0:67.9,GPT-5.4 是 75.1,差距不小
- SimpleQA-Verified:57.9,Gemini 3.1 Pro 是 75.6,世界知识这块还有差距
官方的表述是:V4-Pro 已成为公司内部的 Agentic Coding 主力模型,使用体验优于 Claude Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式,但仍与 Opus 4.6 思考模式存在差距。
没有往高了吹,这句话说得挺实在。
如果只看能力,V4 不是第一梯队的绝对领先者。但如果看成本结构,它可能是这代模型里最重要的一个。
真正值得看的技术:长上下文的成本被打下来了
V4 在技术报告里把自己定义为"基础设施级别的发布"------目标不是能力跃升,而是把长上下文的成本结构重写一遍。
长上下文难落地有个根本原因:
传统 Transformer 每个 token 要和前面所有 token 算一遍相似度,上下文从 10 万 token 拉到 100 万,计算量不是 10 倍,是 100 倍。这是它一直只能当展示参数、不能当标准配置的原因。
V4 在三个地方动了刀:
① 稀疏注意力(DSA)
在 token 维度做压缩,结合 DSA 稀疏注意力机制。
结果是:在 1M 上下文设置下,V4-Pro 的单 token 推理算力消耗只有 V3.2 的 27%,KV Cache 只有 10%。
V4-Flash 更激进,压到 10% 和 7%。上下文拉大 8 倍,单 token 成本反而降了。
② mHC 超连接
解决 1.6 万亿参数模型训练时的不稳定性,通过数学约束让深层网络的前向和反向传播更稳定,训练开销只增加了 6.7%。
③ Agent 专项训练
这次把 Agent 提升为和数学、代码并列的独立专家方向单独训练。
具体改动:工具调用从 JSON 换成带特殊 token 的 XML 结构,降低转义错误;跨轮次推理痕迹完整保留,不再像 V3.2 那样每轮清空------模型能记住它上一步在想什么,长 Agent 任务不容易断链。
DeepSeek 还自建了名为 DSec 的沙箱平台,单集群可并发管理数十万个沙箱实例,专门支撑 Agent 强化学习训练和评测。
V4 已针对 Claude Code、OpenClaw、OpenCode、CodeBuddy 等主流 Agent 产品进行适配优化。
速度和体感
官方数据:首 token 延迟约 800ms,输出约 60 tokens/s。
开发者实测通过聚合接口调用:首 token 约 1.1s,输出约 55 tokens/s。
体感和 V3 差不多,参数量增大到 1.6 万亿,速度没有明显下降------MoE 架构的好处就在这里。
Pro 现在贵,但有个明确的时间节点
V4-Pro 目前 12 元输入、24 元输出,比国内其他旗舰模型贵一些。
官方在定价表备注里说了一句话:预计下半年昇腾 950 超节点批量上市并部署之后,Pro 版本的价格也会大幅度下调。
这句话是关键。
Pro 现在的价格是受算力产能限制的过渡价,不是最终价。等国产芯片产能上来,这条线会被重新划定。
真正打到地板的是 Flash:1 元输入,2 元输出,缓存命中后输入 0.2 元,1M 上下文全线标配。
从今天起,普通开发者可以把 1M 上下文当成默认配置来用,而不是当成 feature 展示。这件事改变的不只是成本,是你写代码时一次能喂进去多少上下文的默认假设。
还没稳定的地方,也要说清楚
这次是预览版,不是正式版。有几点还需要时间验证:
昇腾生态的稳定性:在华为芯片上跑通是第一步,但工具链、生态成熟度和英伟达生态还有差距,实际工程体验需要更多时间验证。
推理成本的真实情况:官方说 1M 上下文下成本结构改善明显,但目前独立复现数据还不多,实测结论需要等社区跑出更多数据。
Pro 的供应瓶颈:官方明确说了高端算力产能有限,Pro 目前吞吐受限。高并发场景下是否稳定,还是个问号。
最后
V4 不是那种让你看完 benchmark 就兴奋的发布。
它做的事情更底层,也更难被感知:
把长上下文的推理成本打下来,让 1M 上下文不再只是参数展示,让国产芯片第一次进入正式技术文档里的硬件验证清单。
更重要的是它证明的那件事------在芯片受限的条件下,中国可以训出世界一流的大模型,可以走一条不依赖英伟达的路。
这件事如果成立,影响的不只是 DeepSeek,是整个中国 AI 产业的下一步。
至于它的模型能力够不够强,这个问题会有答案------等 Pro 的价格打下来,等生态跑稳,等社区跑出更多实测数据。
那时候再说。
更多内容,欢迎关注微信公众号【子昕AI编程】~