CNN炼丹师都知道,模型有一个很令人费解的特点,就是在训练即或者实验室的测试集上有着超人的准确率,但是在实际应用中,有着惊人的失败率。
这种现象很多,在研究对抗样本的时候,改变一个像素,就可以改变图像的预测结果。
论文1中的说,每个数据集都有属于自己的偏置,在一个数据集上训练的检测器,当偏置改变的时候,检测器性能会下降,但是在新的数据集进行很小的微调时,性能提高很多,即使在每个类别的少量图片上微调,性能就能提高很多;
论文2中提到了shortcut learning,快捷学习方式,即shortcut是一中决策规则,在标准准则上性能很好,但是在具有挑战性的测试条件下,系能特别差。论文中又指出了很多其他的shotcut例子,例如,DNN似乎可以很好地对奶牛进行分类,但在奶牛出现在典型草地景观之外的图片上进行测试时失败了,揭示了"草"是"奶牛"的意外(快捷)预测因素;一个机器分类器成功地从多家医院的X射线扫描中检测到了肺炎,但对于来自新医院的扫描,它的性能却出奇地低:该模型出乎意料地学会了以近乎完美的精度识别特定的医院系统(例如,通过在扫描中检测医院特定的金属标记。论文中也给出了一个很简单的例子,证明shortcut learning 的存在,如下图:
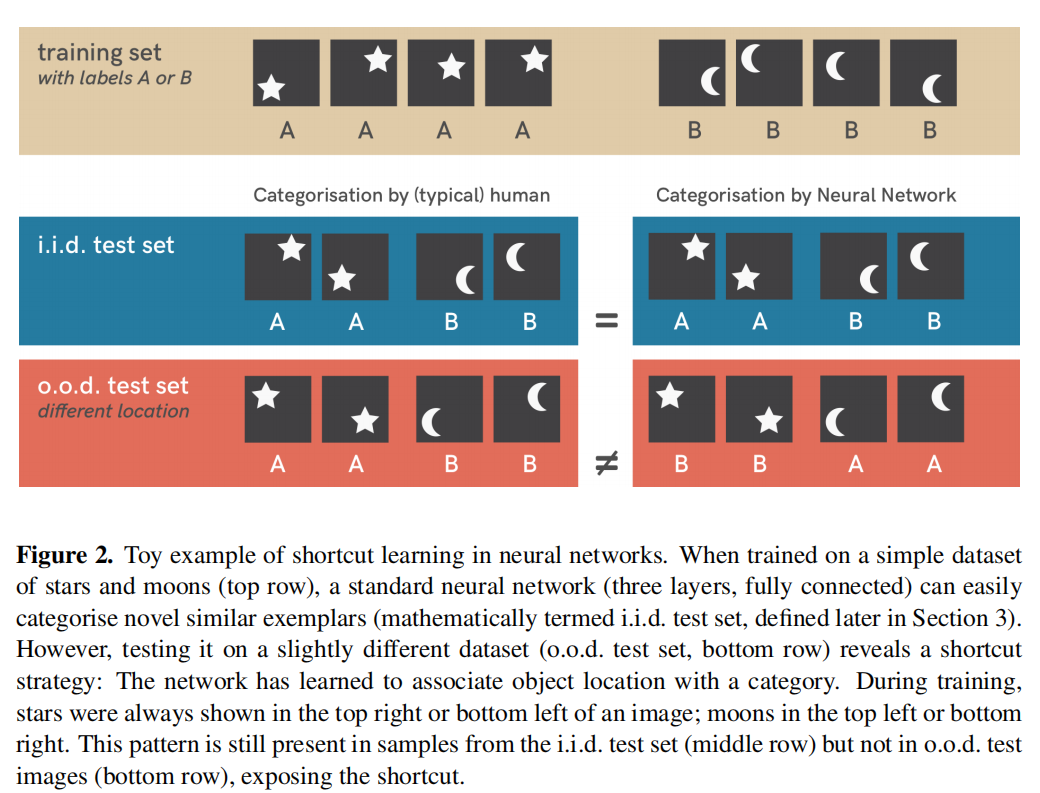
第一行是训练集,只有星星和月亮,星星的标签是A,月亮的标签是B,从人类的视觉判断来看,星星和月亮的重要区分点是形状,但是在训练集中,星星总是出现在图片的左下角和右上角,月亮总是出现在图片的左上角和右下角,于是CNN在学习的过程中出现了shortcut learning,简单粗暴的将目标类别和位置关联在了一起。当测试集是蓝色是,测试集和训练集是独立同分布,测试集准确率很高,当测试集是红色时,测试集合训练集不在时独立同分布的,星星出现在了月亮常出现的左上和右下,月亮出现在了星星常出现的左下和右上,所有出现了,在红色测试集中,CNN预测完全错误的情况。
论文中还有一个很有意思的例子,下图是大象的纹理,猫的形状,标准的CNN判别为大象,对于目标分类来说,目标纹理或者其他局部结构非常重要,下图之所以区分错误,是因为CNN高度依赖目标纹理,而忽略全局形状。

继续来看论文中的例子,下图中,左边上下为一对,对人类来说是一个类别,但是对CNN来说是不同类别,右边上下也为一对,对CNN来说是同一个类别,但是对人类来说,是不同的类别

总结:
1、捷径学习无处不在,论文中提到,捷径学习是学习系统的一个特定,许多深度学习的问题,其实都是模型只选择预测性特征,而不是考虑所有的特征;
2、捷径学习的本质是,对于一个看似很复杂的数据集,发现了一个很容易的解决方案;
3、很多高性能的模型,其结果其实都是在独立同分布的数据集上测试得到的,你无法区分,模型是真的学习到了目标的标志性特征,还是只是捷径学习的一种,如果想测试模型是否真的学习到了本质关系,需要用OOD测试集;
4、需要理解哪些因素导致模型选择了这条捷径学习,这样可以试着破坏这些关联因素,促使模型往深处学习;
5、虽然完全克服捷径学习可能是不可能的,但在缓解捷径学习方面取得的任何进展都将导致所学解决方案与预期解决方案之间的更好协调。
1ObjectNet: A large-scale bias-controlled dataset for pushing the limits of object recognition models
2Shortcut Learning in Deep Neural Networks