目录
[5.1 空天异构网络架构](#5.1 空天异构网络架构)
[5.2 综合评价参数体系](#5.2 综合评价参数体系)
[5.3 基于Q学习的切换判决优化算法原理](#5.3 基于Q学习的切换判决优化算法原理)
[5.4 奖励函数](#5.4 奖励函数)
[5.5 Q值更新](#5.5 Q值更新)
✨1.前言
随着空天地一体化网络(Space-Air-Ground Integrated Network, SAGIN)的快速发展,小型空中飞行平台(如无人机UAV)在通信中继、应急救援、边缘计算等领域的应用日益广泛。空天异构无线网络融合了卫星网络、高空平台(HAP)、低空无人机网络和地面蜂窝网络等多种异构网络接入方式,为用户提供无缝覆盖和多样化的通信服务。然而,当小型空中飞行平台在复杂空天异构环境中高速移动时,频繁的网络切换问题成为制约服务质量(QoS)的关键瓶颈。
传统的切换判决算法(如基于信号强度的切换、基于滞后余量的切换等)通常仅依据当前时刻的单一网络指标进行决策,未能充分考虑下一时刻网络状态的动态变化、用户移动特征以及不同业务类型对传输质量的差异化需求。这种"短视"的决策机制容易导致乒乓切换、切换失败率高、切换阻塞等问题,严重影响用户体验。因此,研究一种能够综合考虑多维网络参数、具备前瞻性预测能力的智能切换判决算法,对于空天异构网络的实际部署具有重要的理论意义和工程价值。
强化学习(Reinforcement Learning, RL)作为机器学习的重要分支,特别适合解决序贯决策优化问题。其中,Q学习(Q-Learning)算法作为经典的无模型强化学习方法,无需事先建立环境模型,能够通过与环境的持续交互自主学习最优策略,非常适合应用于动态变化的空天异构网络切换场景。
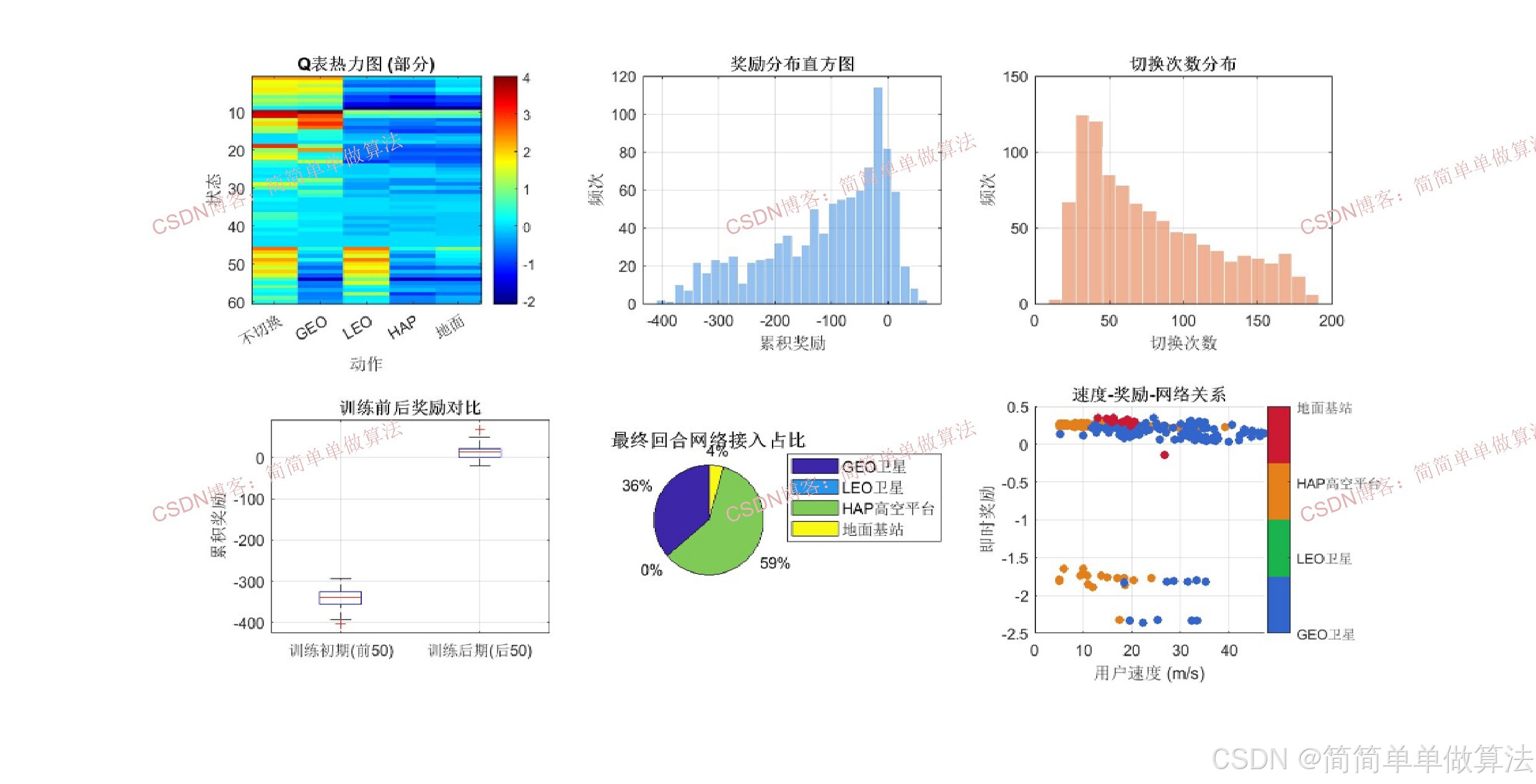
📡2.算法测试效果图预览
🔍3.算法运行软件版本
matlab2024b
✅4.部分核心程序
%网络与环境参数设置 ========================
numNetworks = 4;
networkNames = {'GEO卫星', 'LEO卫星', 'HAP高空平台', '地面基站'};
networkColors = [0.2 0.4 0.8; 0.1 0.7 0.3; 0.9 0.5 0.1; 0.8 0.1 0.2];
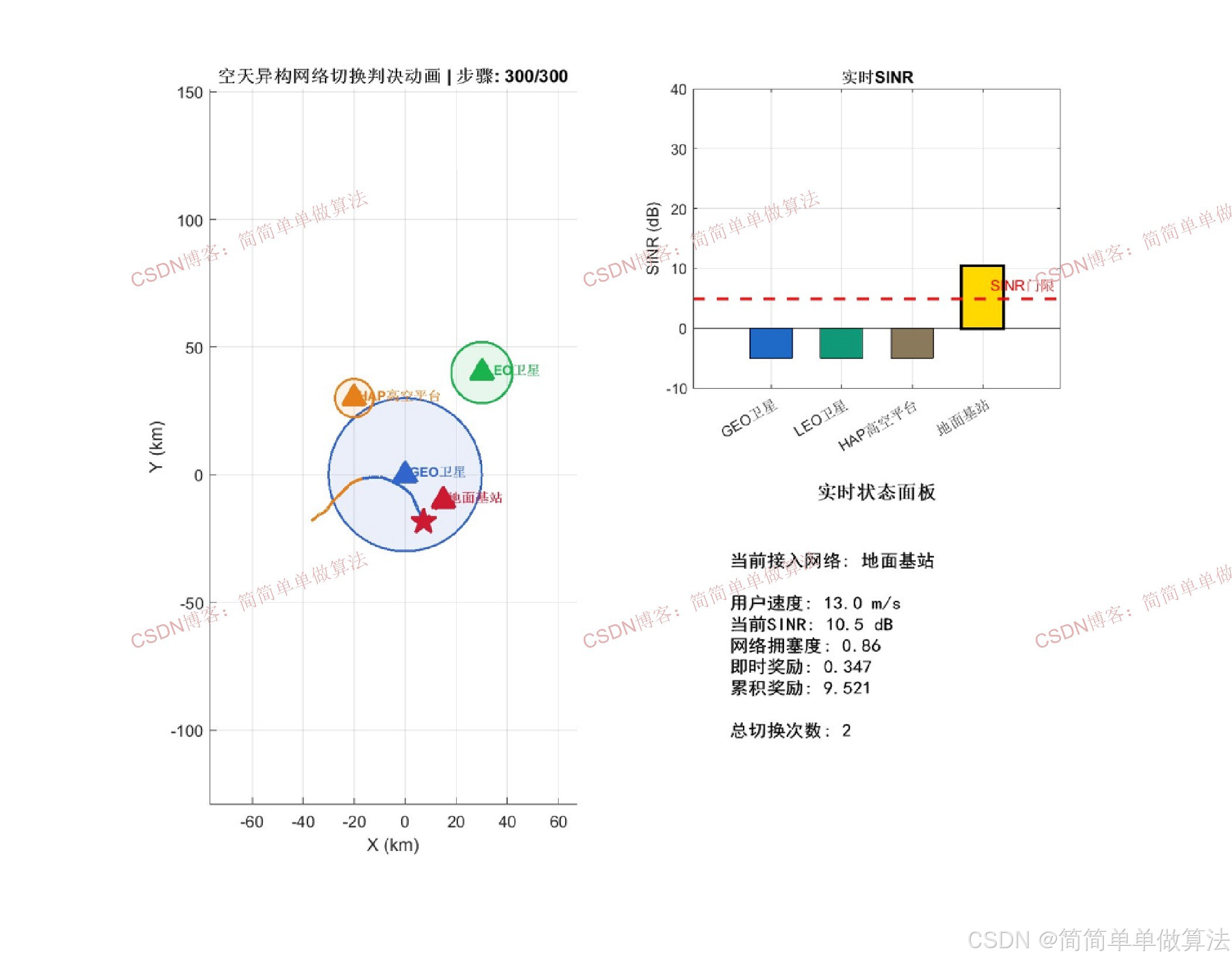
basePos = [0, 0; 30, 40; -20, 30; 15, -10];
coverRadius = [200; 80; 50; 15];
P_tx = [40, 35, 30, 43];
maxCapacity = [50, 100, 80, 200];
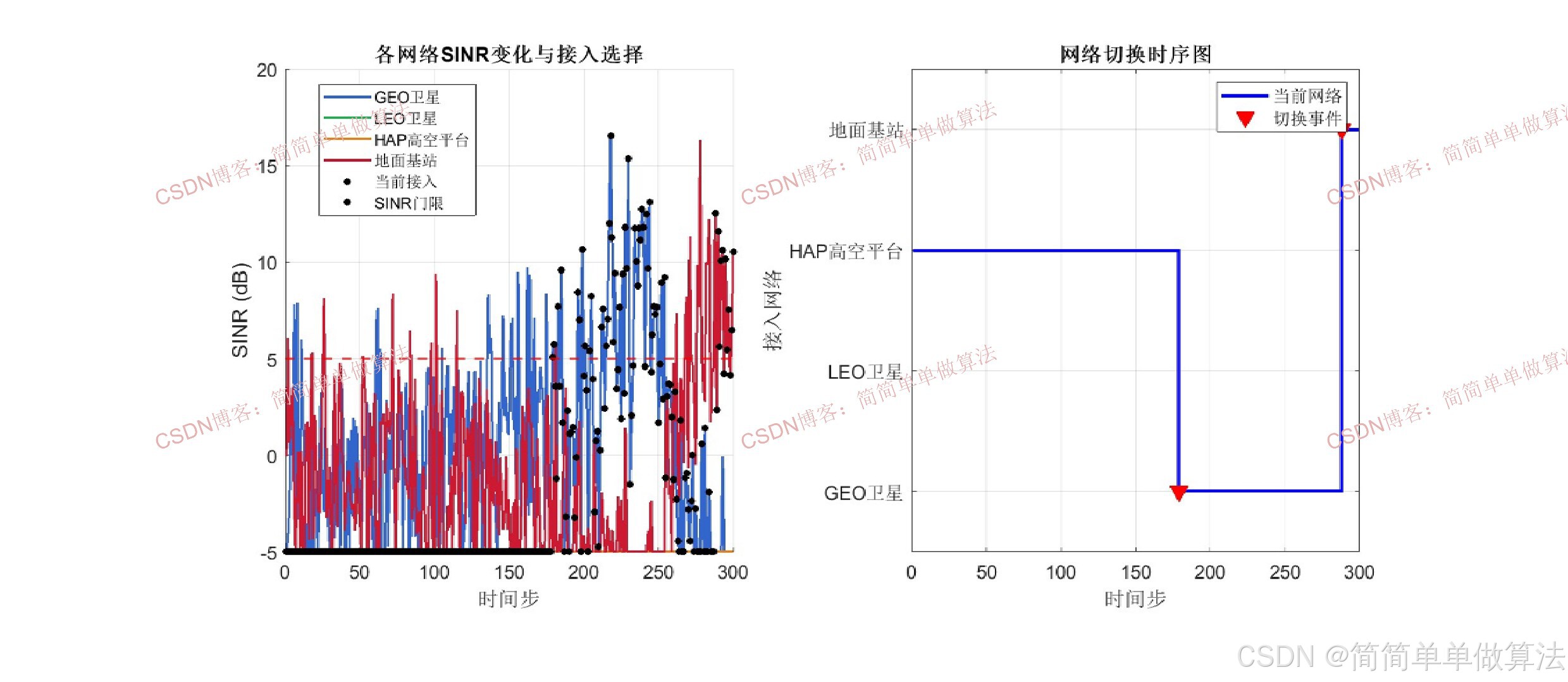
SINR_th = 5;
SINR_max = 35;
D_max = 500;
v_max = 120;
C_max = 100;
C_switch_matrix = [0, 3, 4, 5;
3, 0, 3, 4;
4, 3, 0, 2;
5, 4, 2, 0];
%Q学习参数设置 ========================
SINR_levels = 5;
speed_levels = 3;
congestion_levels = 3;
numStates = numNetworks * SINR_levels * speed_levels * congestion_levels;
numActions = numNetworks + 1;
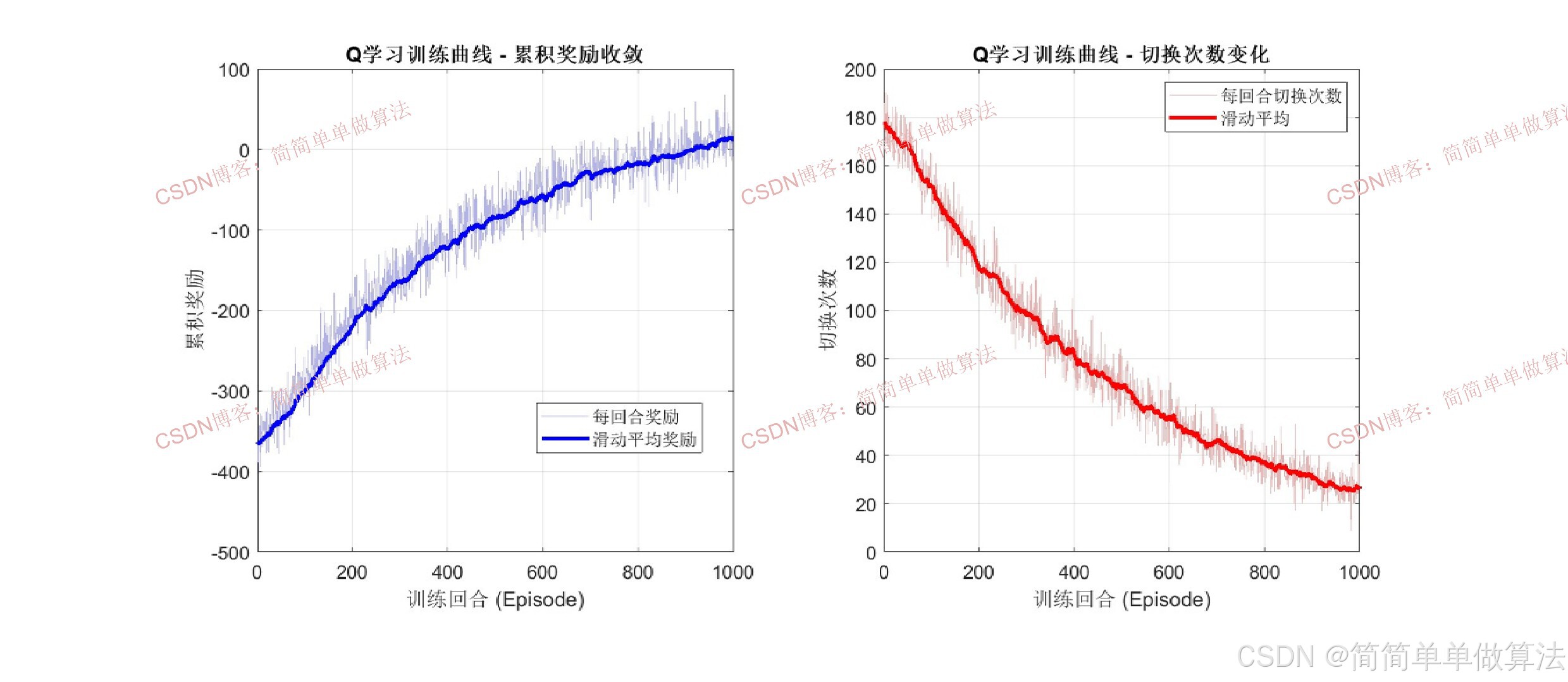
alpha = 0.05;
gamma_rl = 0.9;
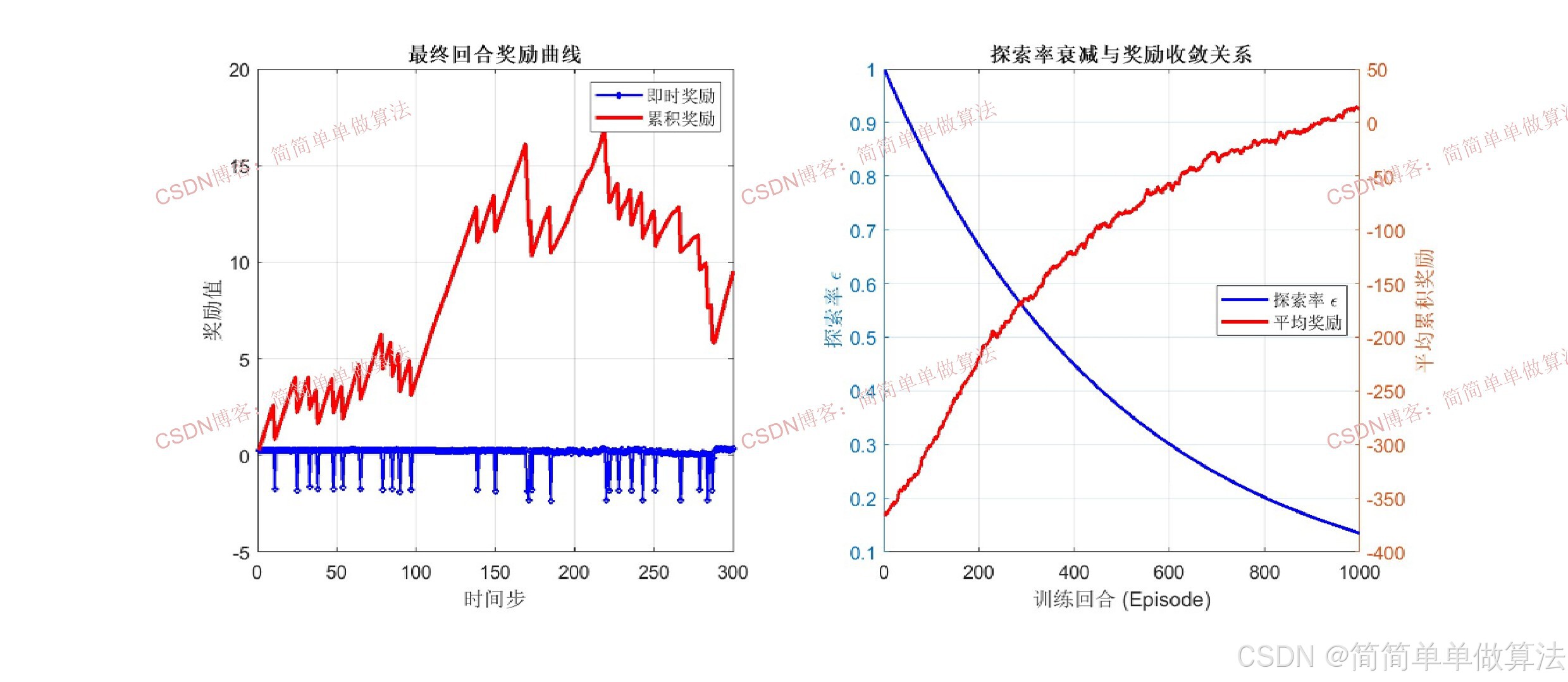
epsilon_0 = 1.0;
epsilon_min = 0.01;
epsilon_decay = 0.998;
numEpisodes = 1000;
maxSteps = 300;
% AHP权重 (实时视频业务)
omega = [0.25, 0.10, 0.15, 0.20, 0.15, 0.15];
256🚀5.算法理论概述
5.1 空天异构网络架构
本文考虑的空天异构无线网络架构包含三层网络结构:卫星层(GEO/LEO卫星网络,提供广域覆盖)、空中层(高空平台HAP及低空无人机中继网络,提供热点增强覆盖)和地面层(宏基站与微基站构成的蜂窝网络,提供高容量热点服务)。设网络集合为N={n1,n2,...,nK},其中K为可用候选网络总数。
小型空中飞行平台作为移动用户终端,在三维空间中沿特定航迹飞行,其在时刻t的位置坐标表示为(xt,yt,zt),飞行速度为vt。由于飞行平台的高动态性,网络拓扑和信道条件均随时间快速变化,切换判决面临极大挑战。
5.2 综合评价参数体系
信干噪比(SINR)
用户终端在时刻t接入网络nk时的信干噪比定义为:
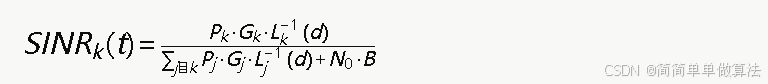
其中Pk为网络nk的发射功率,Gk为天线增益,Lk(d)为距离d处的路径损耗,N0为噪声功率谱密度,B为信道带宽。
网络切换代价
从网络ni切换到网络nj的切换代价综合考虑信令开销和切换时延:
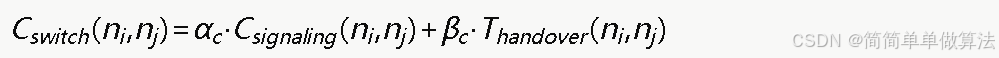
其中αc和βc为归一化权重系数,同层网络间的水平切换代价低于跨层网络间的垂直切换代价。
信息传输时延
用户通过网络nk传输数据的端到端时延为:
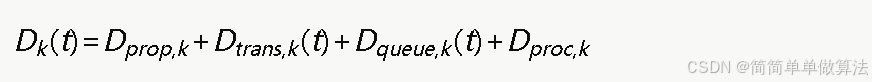
分别对应传播时延、传输时延、排队时延和处理时延。
网络拥塞程度

5.3 基于Q学习的切换判决优化算法原理
将空天异构网络切换问题建模为马尔可夫决策过程(MDP),其四元组定义为(S,A,R,γ):
状态空间S:每个状态st由用户当前接入的网络编号、归一化SINR等级、速度等级和网络拥塞等级联合表征:
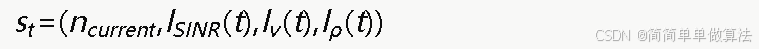
其中各连续参数经过量化离散化处理,映射到有限的等级集合。
动作空间A:动作at 表示切换决策,at∈{0,1,2,...,K},其中at=0表示保持当前网络不切换,at=k (k≥1)表示切换到网络nk。
奖励函数R:这是算法设计的核心,后文详细阐述。
折扣因子γ:γ∈[0,1),平衡即时奖励与未来长期累积奖励的重要性。
5.4 奖励函数
奖励函数的设计直接决定了Q学习算法的优化目标和收敛质量。本算法的奖励函数综合考虑当前与下一时刻网络参数的加权评估值、切换代价惩罚和用户体验反馈:
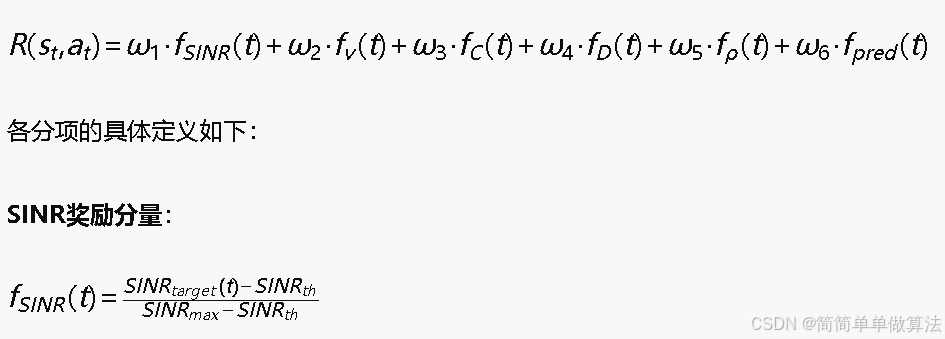
其中SINRtarget(t)为目标网络的当前SINR,SINRth为最低可接受门限,SINRmax为理论最大值。
5.5 Q值更新
Q学习通过维护一个Q表Q(s,a) 来记录每个状态-动作对的累积预期奖励估计。Q值的更新采用时序差分(TD)学习规则:
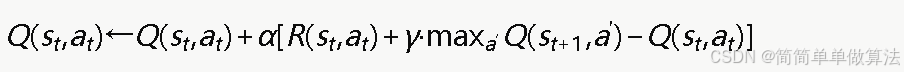
其中α∈(0,1]为学习率,控制新经验对Q值更新的影响程度;γ∈[0,1)为折扣因子;maxa′Q(st+1,a′)表示在下一状态st+1下所有可选动作中Q值最大的那个,体现了Q学习的贪心特性。
💡6.算法完整程序工程
OOOOO
OOO
O
关注GZH后输入回复:0041