DeepSeek‑V4 预览版发布

4 月 24 日,DeepSeek 正式发布新一代系列模型 DeepSeek‑V4 预览版,并同步开放 API 与开源权重,主打「1M 超长上下文 + 顶级推理 + 高性价比」。
这一代模型分为 DeepSeek‑V4‑Pro 和 DeepSeek‑V4‑Flash 两个版本:前者对标顶级闭源旗舰,后者走极致性价比路线,二者都把 1M 上下文做成了"默认配置"。
下面这篇文章,我会结合官方技术报告+价格/评测图,从 价格、架构、能力、场景和接入方式 五个维度,把 DeepSeek‑V4 讲清楚,也顺带聊聊它对开发者意味着什么。
一句话看懂 DeepSeek‑V4
如果只能用一句话概括 DeepSeek‑V4:
在开源阵营里第一次,把「百万级长上下文 + 顶级推理 + 可负担价格」同时做到工程可用的水准。
从官方公开信息和技术报告来看,DeepSeek‑V4 的几个核心标签是:
- MoE 架构 + 1M 上下文:Pro 总参数约 1.6T,激活参数约 49B;Flash 总参数约 284B,激活约 13B,二者都支持 1M token 长上下文。
- 推理 & 代码能力拉满:在 MMLU、SWE‑bench 等关键基准上,已经接近甚至对标部分顶级闭源模型。
- 全链路开放:提供官方 Chat、API、开源权重和多家云平台支持,基本覆盖从个人开发者到企业自建集群的所有需求。
价格:1M 上下文真的"普惠"了吗?
先上很多人最关心的一张图:V4 系列的 API 计费表(单位:元/百万 token)。
从图中可以看到价格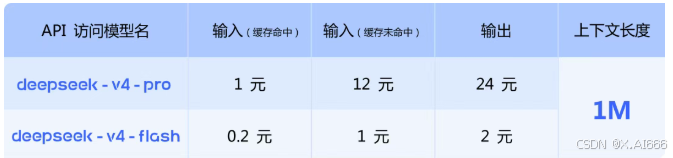
相比于gpt,gemini的价格这个太便宜了。结合缓存机制理解这张表更有意思:对长上下文场景,命中缓存后的增量 token 成本被压得很低, 这意味着只要合理拆请求,就可以在保证 1M "大记忆"的前提下,把实际费用控制在可接受的区间里。如果你之前用过 V3 或其他大模型,会非常直观地感受到:**在同等价位下,你能喂给 V4 的上下文量级直接上了一个数量级。
架构与算力效率:为什么 1M 上下文能"跑得起"?
很多模型也宣传长上下文,但真正上生产时,不是显存打爆就是吞吐崩掉。DeepSeek‑V4 能把 1M 做成标配,关键在于 结构创新 + 稀疏注意力 + KV 矩阵压缩。
官方技术报告中给出了和 V3.2 的计算量、显存对比图:你提供的这张图非常直观。
左图是每 token 计算量(TFLOPs)随上下文长度增长的变化 ,右图是累计 KV 缓存大小(GB)。 可以看到,在 1M 级别上下文下,V4 的计算和显存曲线远低于 V3.2,这意味着:
- 同样的显卡规格下,可以把上下文拉得更长;
- 同样的上下文长度下,V4 的 QPS 更高、延迟更低,部署成本更友好。
这背后主要依赖几项关键技术:
- Compressed Sparse Attention + Heavily Compressed Attention:在 token 维度做强压缩,把不重要的 token 低成本编码,从而减少注意力计算。
- DeepSeek Sparse Attention (DSA):通过稀疏模式处理超长距离依赖,既保留长程信息,又避免全局注意力的平方级开销。
- Manifold‑Constrained Hyper‑Connections(mHC)+ Muon 优化器:在 1T 级 MoE 架构中保证训练稳定和梯度传递效率,为"深 + 长"的模型结构保驾护航。
一句话总结:V4 不是用蛮力堆显卡,而是用结构和稀疏机制把 1M 上下文做成"工程可用"的能力。 ^3^1
能力评测:和 Claude / GPT / Gemini 正面刚
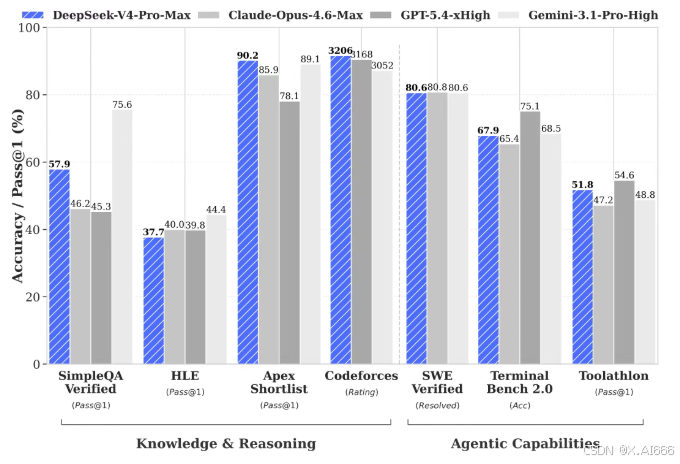
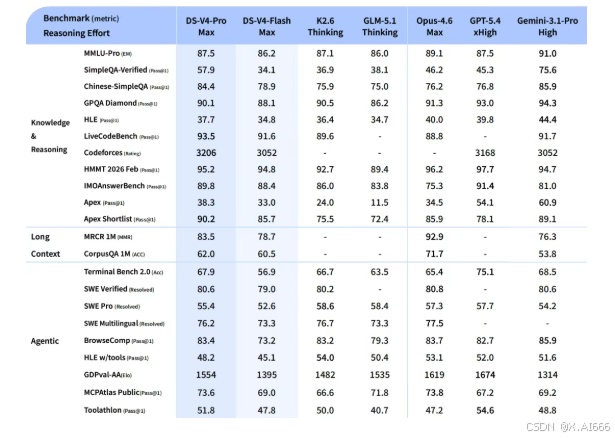
能力到底如何?官方技术报告里给出了一张大的 benchmark 表,你的这张截图几乎把重点评测都囊括了。
从这张表可以看到,在 知识 & 推理、长上下文、Agent 能力 等多个维度上,DeepSeek‑V4‑Pro‑Max 基本站在第一梯队,和 Claude‑Opus、GPT‑5.4、Gemini‑3.1‑Pro 等闭源旗舰处于同一张表上直接 PK。
- 在 MMLU‑Pro 等综合知识与推理测试中,V4‑Pro 已经能和主流闭源模型打平甚至略有领先。
- 在 MRCR、CorpusQA 等长上下文评测中,得益于 1M 窗口和高效注意力结构,V4‑Pro 有明显优势。
- 在 Terminal Bench、SWE‑bench 等工程级任务中,V4 在"从需求到可运行代码"这一链条的完成度上也非常亮眼。
可以看到,在 SimpleQA、Apex、Codeforces、SWE‑bench、Toolathon 等任务上,蓝色的 DeepSeek‑V4‑Pro‑Max 经常处于最高或接近最高的位置,尤其是 Codeforces Rating 和 SWE Verified 这类更接近真实工程的基准上,表现相当扎眼。
模型规格:Pro vs Flash 怎么选?
在实际项目中,最常见的问题就是:到底该用 Pro 还是 Flash? 你提供的这张"规格总览表"非常适合作为选型参考。
从表里可以看到:
- DeepSeek‑V4‑Pro
- 参数量:1.6T
- 激活参数:49B
- 预训练数据:33T
- 上下文长度:1M
- 支持开源 & API
- 官方定位:专家模式(适合复杂推理、关键业务)
- DeepSeek‑V4‑Flash
- 参数量:284B
- 激活参数:13B
- 预训练数据:32T
- 上下文长度:1M
- 同样开源 & 提供 API
- 官方定位:快速模式(适合高 QPS、大规模调用)
结合上文的计费表来理解:Flash 是高频调用的主力干活模型,Pro 是关键链路上的"王牌大脑"。
一个比较推荐的组合策略是:
- 默认用 V4‑Flash 处理大部分简单问答、日常代码补全和常规 RAG 请求;
- 当任务涉及关键业务逻辑、复杂多步推理、重要合同/报告审阅时,再切换到 V4‑Pro,并开启思考模式(reasoning_effort=high / max)。
典型实战场景:哪些项目值得第一时间上 V4?
从我的视角,DeepSeek‑V4 最适合优先"上车"的几个场景是:
- 超长文档 RAG / 知识库问答
- 1M 上下文可以一次性容纳整本手册、规范或长合同,减少传统 RAG 中切片、重组带来的语义裂缝。
- 对于那种"跳来跳去查上下文"的问题(比如:交叉引用、附录定义),V4 能更好地在不同位置间建立关联。
- 大仓库级代码理解与重构
- 把一个单体仓库的核心文件直接扔进上下文,让模型在"看完整仓库"的前提下做重构建议、Bug 定位、接口迁移。
- 在 SWE‑bench 这类更贴近真实工程的任务上,V4 的表现说明它不仅能写函数,还能处理跨文件、多模块的修改。
- 复杂 Agent / 自动化开发伙伴
- Agent 需要长期记住"世界状态":需求、任务列表、执行日志、中间结果等,以前很容易被上下文长度卡死,现在 1M 基本够用。
- 结合思考模式,Agent 可以在一次对话中做完整的任务拆解、规划、调用多个工具,然后再根据返回结果动态调整策略。
- 法律、金融、审计等高价值专业领域
- 对于动辄几百页的招股书、合约、年报,以前要靠"分段 + 多轮问",现在可以直接一次性塞进上下文,让模型帮忙做条款比对、风险点标记和摘要提取。
API 接入与迁移:三分钟从 V3 升级到 V4
在接入层面,DeepSeek‑V4 完全兼容 OpenAI ChatCompletions 和 Anthropic 风格接口,迁移成本非常低。
把迁移步骤拆开来看,大致只需要三步:
- base_url 指向 DeepSeek 网关 :如
https://api.deepseek.com/v1。 - 修改模型名为
deepseek-v4-pro或deepseek-v4-flash。 - 如需思考模式,在请求中增加
reasoning_effort字段(high或max)。
下面是一个使用 Python OpenAI SDK 调用 V4‑Pro 的示例代码,可以直接搬进你的项目或 CSDN 文中:
python
from openai import OpenAI
client = OpenAI(
api_key="YOUR_DEEPSEEK_API_KEY",
base_url="https://api.deepseek.com/v1",
)
messages = [
{
"role": "system",
"content": "你是一个资深全栈工程师, 善于在大规模代码仓库中定位问题并给出可执行方案。"
},
{
"role": "user",
"content": """
我已经把一个单体仓库的核心文件拼接成了长文本发给你,
请你先整体阅读, 总结当前架构, 然后列出可以在两周内完成的三项重构任务,
并给出每一项的具体修改建议和潜在风险。
"""
},
]
resp = client.chat.completions.create(
model="deepseek-v4-pro",
reasoning_effort="max", # 启用思考模式, 适合复杂分析
temperature=0.2,
messages=messages,
)
print(resp.choices[^0].message.content)如果你之前用的是 deepseek-chat / deepseek-reasoner,官方也已经声明未来会统一迁移到 V4 系列,所以 现在就开始把模型名替换为 V4,是一件迟早要做的事。
开源与本地部署:从云端到自建集群的一致体验
除了在线 API,DeepSeek‑V4 还同步开放了预览权重:
- Hugging Face 模型集合:
deepseek-ai/deepseek-v4-*。 - ModelScope 等国内平台也提供了镜像和权重下载,方便在国内网络环境部署。
这意味着你可以有三种典型使用方式:
- 云端 API:最快上手、无需自管基础设施,适合个人和小团队。
- 云上自建(vLLM / TGI / LMDeploy 等):对延迟、合规或成本有更细粒度要求的团队,可以直接用权重在 GPU 云上跑自己的推理服务。
- 完全本地化部署:在有算力的情况下,把模型落地到自己的机房/数据中心,实现数据完全不出网的私有化方案,但是1.6T参数量的模型,一般企业级别也很难部署。
对于有「隐私 + 长文档 + 复杂业务」三重需求的企业来说,V4 开源 + 1M 上下文 这个组合非常具有吸引力。
写在最后:为什么这次 V4 值得认真试一试?
从技术路线来看,DeepSeek‑V4 并不是简单的参数加量,而是在 MoE + 长上下文 + 稀疏注意力 + 稳定训练 这几个方向上做了系统化设计,使得 1M 上下文真正具备了工程可用性。
从能力评测来看,它在 推理、代码、Agent 能力 等方面已经站上了开源阵营的天花板,并且在多个关键基准上,和 Claude / GPT / Gemini 这些闭源旗舰可以直接对线。
从开发者视角来看,统一的 API、可选的 Pro/Flash 组合、开源权重和多平台部署支持,也让我们在做选型时第一次有了一个真正可以和闭源方案平起平坐的国产自研选项。