原文链接:https://arxiv.org/abs/2504.10686
高效超分赛道仅仅有4x超分任务,之前的《NTIRE2025 RAW图像恢复与超分辨率》赛道上三个任务合一:2x超分,去噪,去模糊。三合一的任务更多的trick是分步骤训练,对一个个任务更个击破,高效超分赛道更关注的是如何在进行超分的同时更好的保留细节,因为4x超分相比2x超分,对细节有更高的要求。
高效超分赛道相比4x超分赛道除了画面质量相关的psnr指标外,更关注模型推理速度、模型参数、模型flops,这些在真实的模型工程化上至关重要!
模型提速的主要思路
-
模型蒸馏 模型蒸馏是一种行之有效的方法,能够在不增加推理阶段计算开销的前提下,维持峰值信噪比(PSNR)指标表现。EMSR 团队仅在基础模型中加入类 ConvLora 算子。与之类似,ESPAN 团队结合参考文献 42 的验证结论,提出采用自蒸馏渐进式学习策略。模型蒸馏是非常好用的小模型优化思路,尤其在小模型泛化能力和有些指标不及大模型的时候,而且可以非常灵活的使用,比如蒸馏输出层,蒸馏中心层,蒸馏注意力层;可以蒸馏学习一个教师模型,还可以蒸馏学习多个教师模型,还可以蒸馏学习后续任务模型(比如后面跟的检测识别模型等),总结就是当小模型效果达不到预期的时候,这个策略就很好用!
-
重参数化 重参数化技术在本次竞赛中得到广泛应用。通常在训练阶段,将普通卷积层结合多种基础运算(3×3 卷积、1×1 卷积、一阶与二阶微分算子、跳跃连接等)进行多分支参数化构建;而在推理阶段,可将用于卷积重参数化的多组运算合并为单个卷积。小米 MM、mmSR、HannahSR 等多支顶尖队伍均在其方案中采用了该技术。重参数化可以有效的降低计算量、减小内存/显存读写、算子数量,另外合并后的单个卷积在大部分的npu/bpu等计算平台,非常友好,这点很重要。由于是数学等价代换得到的所以理论上模型推理效果不降,不过这个对量化还是较敏感的。
-
无参数注意力机制 实践证明,无参数注意力机制可有效提升计算效率。其中,小米 MM 团队基于无参数注意力模块,设计了一种轻量化高速无参数注意力网络,在保证良好峰值信噪比的同时,实现了最短运行耗时。无参数注意力机制很实用,冠军方案EMSR也用到了类似的方法-convloras,值得关注!
-
多尺度信息融合与层级化模块设计融合多尺度特征信息、采用层级化模块结构,是实现关键特征有效融合的成熟方案。例如,HannahSR、XuPTBoys、ChanSR 等参赛方案,均通过多尺度残差连接与层级模块设计,有效提升了模型重建性能。
-
网络剪枝网络剪枝发挥了重要作用。ASR、Davinci 等团队采用网络剪枝技术对模型进行适度压缩,在性能无大幅下降的情况下,构建出更加轻量化的网络结构。
-
新型网络架构探索本次竞赛也开展了全新网络架构的探索。除主流的卷积神经网络与 Transformer 架构外,GXZY AI 团队尝试引入状态空间模型(视觉 Mamba),该架构在上一届 NTIRE 实时超分辨率竞赛中也已得到验证。
-
其他各类优化技术各参赛团队还尝试了多种创新方案,包括基于神经网络架构搜索、视觉 Transformer、频域处理、多阶段结构设计以及高级训练策略等优化方法。
第一名:EMSR
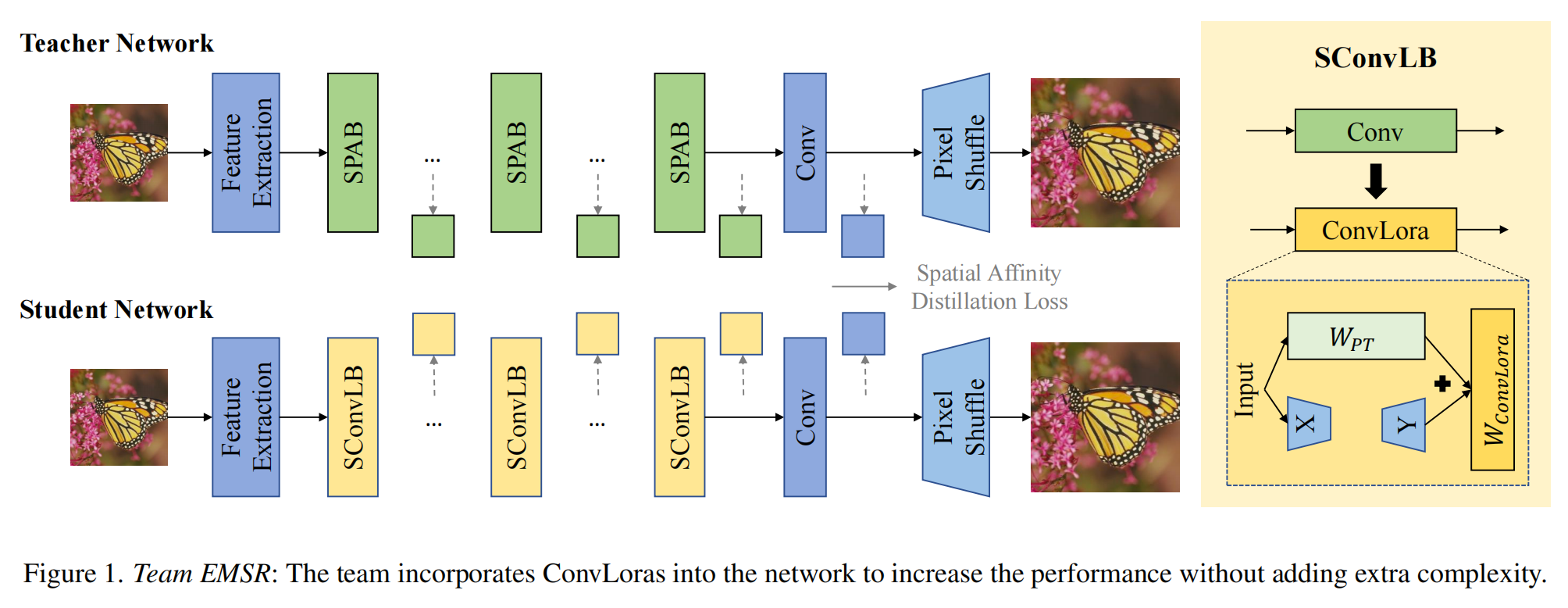
方法
团队EMSR的整体架构如图1所示,该架构基于领先的高效超分辨率方法SPAN111。受ConvLora7的启发,团队提出了SconvLB,该方法将ConvLora整合到SPAB中,在不增加计算复杂度的情况下提升性能。具体而言,给定SPAB中的一个预训练卷积层,他们通过添加Lora层来更新它,并用低秩分解表示:
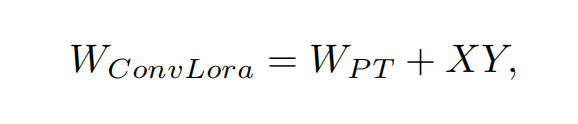
其中WConvLora表示卷积的更新权重参数,WPT表示卷积的原始预训练参数,X通过随机高斯分布初始化,Y在训练开始时为零。需要注意的是,Lora权重可以合并到主干网络中。因此,ConvLora在推理过程中不会引入额外的计算。
他们采用了预训练的SPAN-Tiny模型111,该模型具有26个通道。他们用所提出的SconvLB替换SPAN中的SPAB,并将ConvLora添加到像素洗牌块及其之前的卷积中。在训练过程中,他们冻结卷积的原始权重和偏置,仅更新Lora参数。
优化
为了监督SconvLB的优化,他们采用了一种基于知识蒸馏的训练策略。他们采用基于空间相似性的知识蒸馏37,通过在网络多个层对齐空间特征相似性矩阵,将二阶统计信息从教师模型传递给学生模型。
给定从网络第lll层提取的特征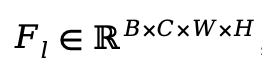 ,他们首先沿最后两个维度展平张量并计算相似性矩阵Aspatial。然后,基于空间特征相似性的蒸馏损失可以表述为:
,他们首先沿最后两个维度展平张量并计算相似性矩阵Aspatial。然后,基于空间特征相似性的蒸馏损失可以表述为:
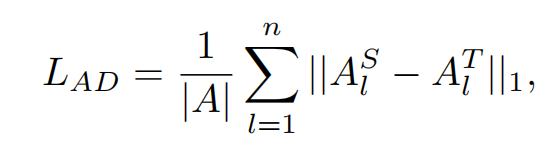
其中AS和AT分别是学生网络和教师网络从第l层特征图提取的空间相似性矩阵,∣A|表示相似性矩阵中的元素数量。具体而言,团队在每个SconvLB之后应用蒸馏损失。
除了特征空间的蒸馏损失外,团队还应用了像素级蒸馏损失:
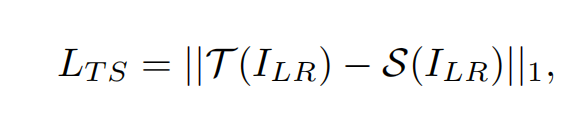
其中T和S分别表示教师网络和学生网络,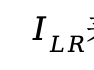 表示低分辨率图像,上面公式是教师网络和学生网络输出层,也就是上采样后的图像的1范数距离损失。
表示低分辨率图像,上面公式是教师网络和学生网络输出层,也就是上采样后的图像的1范数距离损失。
他们还应用了L2损失:
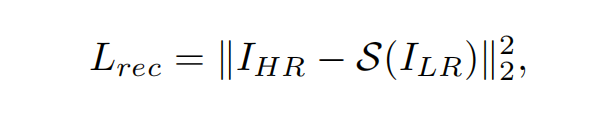
其中IHR表示地面真实高分辨率图像。上面公式是学生网络输出层和真实的ground truth的损失,实用的是2范数。
总损失为:
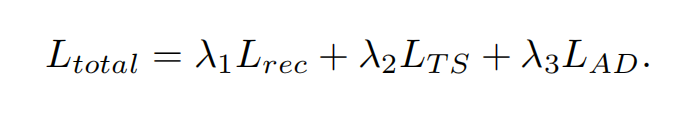
训练细节
团队使用DIV2K和LSDIR进行训练。采用随机翻转和随机旋转进行数据增强。训练过程分为两个阶段:
第一阶段:从HR图像中随机裁剪192×192大小的HR图像块,mini-batch大小设置为8。使用Adam优化器,通过最小化上述Ltotal来训练模型。学习率为1×10−4,总共训练30k次迭代。
第二阶段:在第二阶段,团队将HR图像块的大小增加到256×256,其他设置与第一阶段相同。
在整个训练过程中,他们采用指数移动平均(Exponential Moving Average,EMA)策略来增强训练的鲁棒性。
第五名:mbga
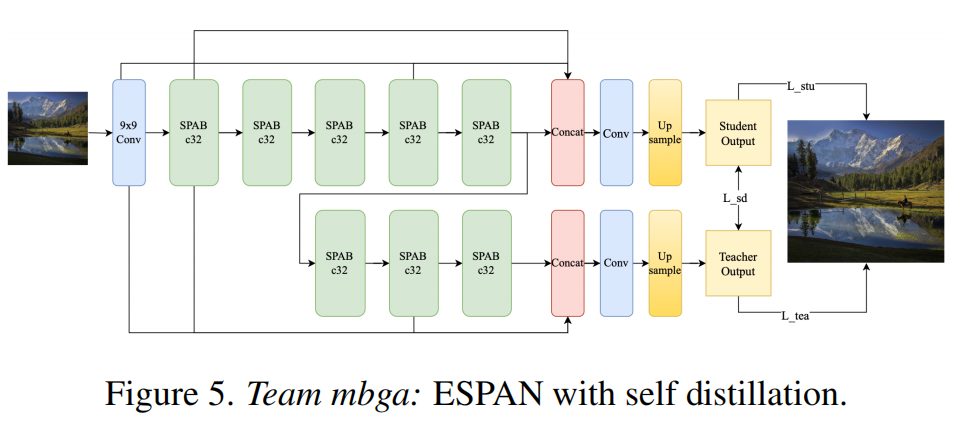
架构
团队提出了 ESPAN,它基于 SPAN 110。通过在 A6000 GPU 上对 SPAN 的深度-通道组合进行评估,他们确定将通道数设置为 32 比 28 个通道具有更高的效率。为了减少参数量和浮点运算次数(FLOPs),采用了 6 的深度。此外,在网络输入阶段,使用 9×9 卷积替代了传统的 3×3 卷积,因为他们发现 9×9 卷积在 A6000 上比 3x3 卷积更快。
**通用重参数化。**受 MobileOne 106 和 RepVGG 23 的启发,团队提出了一个通用重参数化模块(图 4)。该模块由四个 1×1-3×3 卷积分支、一个 1×1 卷积分支和一个 3×3 卷积分支组成。由于经验观察发现跳跃连接会导致训练不稳定,因此省略了跳跃连接。虽然额外的重复分支或 3×3-1×1 卷积分支是可行的,但当前的配置在优化过程中被发现能提供更优越的性能一致性。
自蒸馏与渐进式学习 。受 RIFE 42 的启发,自蒸馏被整合到他们的训练流程中。教师模型与学生模型共享相同的主干,但在学生主干上附加了三个额外的 SPAB 模块(图 5)。采用类似于 RIFE 公式的自蒸馏损失来共同训练教师和学生网络。这种设计使教师模型能够学习鲁棒的主干特征。在蒸馏阶段之后,移除学生损失和蒸馏损失组件,并对整个教师模型进行微调。利用预训练的鲁棒教师,采用渐进式学习:从教师主干中逐渐移除额外的 SPAB 模块,最终得到一个与原始学生模型相同的架构。
频率感知损失。由于小模型参数有限,在训练期间,应使模型更多地关注重要(或困难)区域。在他们的方法中,采用了两种类型的频率感知损失。第一种是 DCT 损失。他们使用离散余弦变换(DCT)将 RGB 域转换为频域,然后应用 L1 损失来计算差异。另一种是边缘损失。他们对图像进行模糊处理,然后用原始图像减去模糊图像以获得高频区域。随后,在这个高频区域计算 L1 损失。
训练细节
训练过程包含两个阶段。训练数据集是 DIV2K LSDIR 训练集。通用重参数化在整个过程中使用。
I. 在第一阶段,使用自蒸馏来训练教师模型。
-
步骤 1 :团队首先训练一个 2 倍超分辨率模型。从 HR 图像中随机裁剪大小为 256x256 的 HR 图像块,迷你批次大小设置为 64。使用 L1 损失和自蒸馏损失以及 AdamW 优化器,初始学习率设置为 0.0001,并在每 100k 次迭代时减半。总迭代次数为 500k。此步骤重复两次。然后他们遵循相同的训练设置,并使用 2 倍超分辨率模型作为预训练模型来训练 4 倍超分辨率模型。此步骤重复两次。不要开始给模型太大的难度,分步骤进行训练。
-
步骤 2 :从 HR 图像中随机裁剪大小为 512x512 的 HR 图像块,迷你批次大小设置为 16。使用 MSE 损失、频率感知损失和自蒸馏损失以及 AdamW 优化器,初始学习率设置为 0.0001,并在每 100k 次迭代时减半。总迭代次数为 500k。此步骤也重复两次。
-
步骤 3 :只训练教师模型。从 HR 图像中随机裁剪大小为 512x512 的 HR 图像块,迷你批次大小设置为 16。使用 MSE 损失和频率感知损失以及 AdamW 优化器,初始学习率设置为 0.00005,并在每 100k 次迭代时减半。总迭代次数为 500k。此步骤也重复两次。
II. 在第二阶段,使用渐进式学习来获得最终的学生模型。
-
步骤 4 :逐一丢弃额外的 SPAB 模块。从 HR 图像中随机裁剪大小为 512x512 的 HR 图像块,迷你批次大小设置为 16。使用 L1 损失和 AdamW 优化器,初始学习率设置为 0.0001,并在每 100k 次迭代时减半。总迭代次数为 500k。
-
步骤 5:多次重复以下训练过程直到收敛。从 HR 图像中随机裁剪大小为 512x512 的 HR 图像块,迷你批次大小设置为 16。使用 MSE 损失和频率感知损失以及 AdamW 优化器,初始学习率设置为 0.00005,并在每 100k 次迭代时减半。总迭代次数为 500k。