SQL 调优实战:跨表排序性能提升之路
在数据库操作中,跨表查询与排序是常见但性能易出瓶颈的场景。本文将结合实际案例,分享一次跨表排序 SQL 的调优过程,通过优化前后的对比,展现性能提升的显著效果。
一、调优背景
在业务系统中,我们需要从多个关联表中查询有效商品 SKU 信息,并按商品生命周期的修改时间倒序排列。原 SQL 语句在执行时耗时较长,达到了 1 秒,随着数据量增长,性能问题愈发突出,因此需要进行针对性优化。
二、优化前 SQL 分析
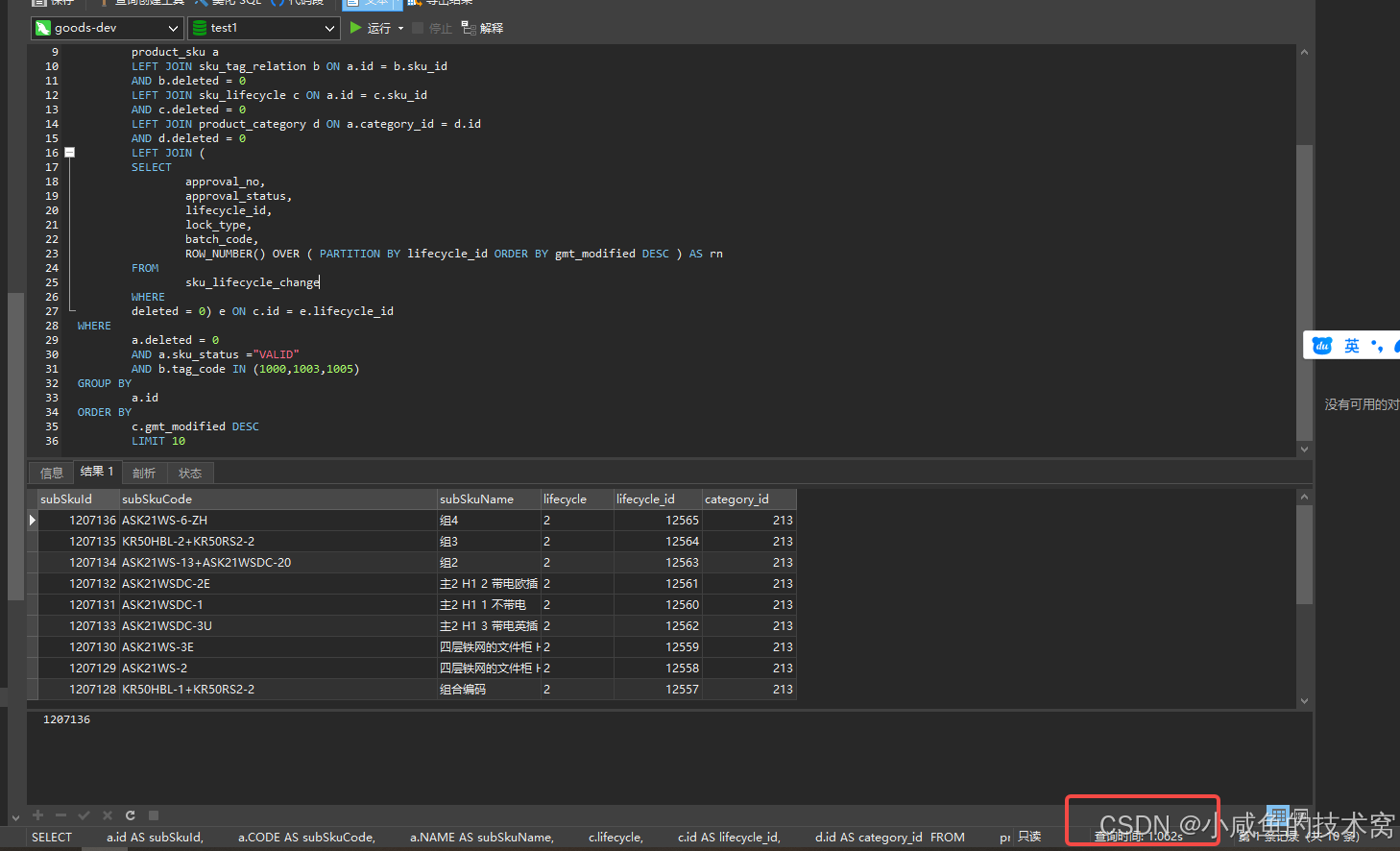
1. 原 SQL 语句
SELECT
a.id AS subSkuId,
a.CODE AS subSkuCode,
a.NAME AS subSkuName,
c.lifecycle,
c.id AS lifecycle_id,
d.id AS category_id
FROM
product_sku a
LEFT JOIN sku_tag_relation b ON a.id = b.sku_id
AND b.deleted = 0
LEFT JOIN sku_lifecycle c ON a.id = c.sku_id
AND c.deleted = 0
LEFT JOIN product_category d ON a.category_id = d.id
AND d.deleted = 0
LEFT JOIN (
SELECT
approval_no,
approval_status,
lifecycle_id,
lock_type,
batch_code,
ROW_NUMBER() OVER ( PARTITION BY lifecycle_id ORDER BY gmt_modified DESC ) AS rn
FROM
sku_lifecycle_change
WHERE
deleted = 0) e ON c.id = e.lifecycle_id
WHERE
a.deleted = 0
AND a.sku_status ="VALID"
AND b.tag_code IN (1000,1003,1005)
GROUP BY
a.id
ORDER BY
c.gmt_modified DESC
LIMIT 10线上耗时:1s

在测试环境复现,也是执行要1s,确实是慢sql
2. 性能瓶颈分析
-
表连接顺序问题 :原 SQL 以
product_sku表为主表进行左连接,后续关联多个表,会先扫描大量product_sku数据,再进行过滤和关联,数据处理量较大。 -
排序效率低 :在最后对
c.gmt_modified进行排序时,由于是基于多表关联后的临时表排序,没法走索引,数据量较大,排序耗时久。
三、优化方案与实施
1. 优化思路
-
调整表连接顺序 :将排序字段所在的
sku_lifecycle表作为主表,通过内连接关联product_sku表,减少初始扫描的数据量。 -
优化连接类型 :将部分左连接调整为内连接,在过滤条件中提前筛选有效数据,缩小结果集范围。
2. 优化后 SQL 语句
SELECT
a.id AS subSkuId,
a.CODE AS subSkuCode,
a.NAME AS subSkuName,
c.lifecycle,
c.id AS lifecycle_id,
d.id AS category_id
FROM
sku_lifecycle c
INNER JOIN product_sku a ON c.sku_id = a.id
AND a.deleted = 0
LEFT JOIN sku_tag_relation b ON a.id = b.sku_id
AND b.deleted = 0
LEFT JOIN product_category d ON a.category_id = d.id
AND d.deleted = 0
LEFT JOIN (
SELECT
approval_no,
approval_status,
lifecycle_id,
lock_type,
batch_code,
ROW_NUMBER() OVER ( PARTITION BY lifecycle_id ORDER BY gmt_modified DESC ) AS rn
FROM
sku_lifecycle_change
WHERE
deleted = 0
) e ON c.id = e.lifecycle_id
WHERE
c.deleted = 0
AND a.sku_status = "VALID"
AND b.tag_code IN ( 1000, 1003, 1005 )
GROUP BY
a.id
ORDER BY
c.gmt_modified DESC
LIMIT 10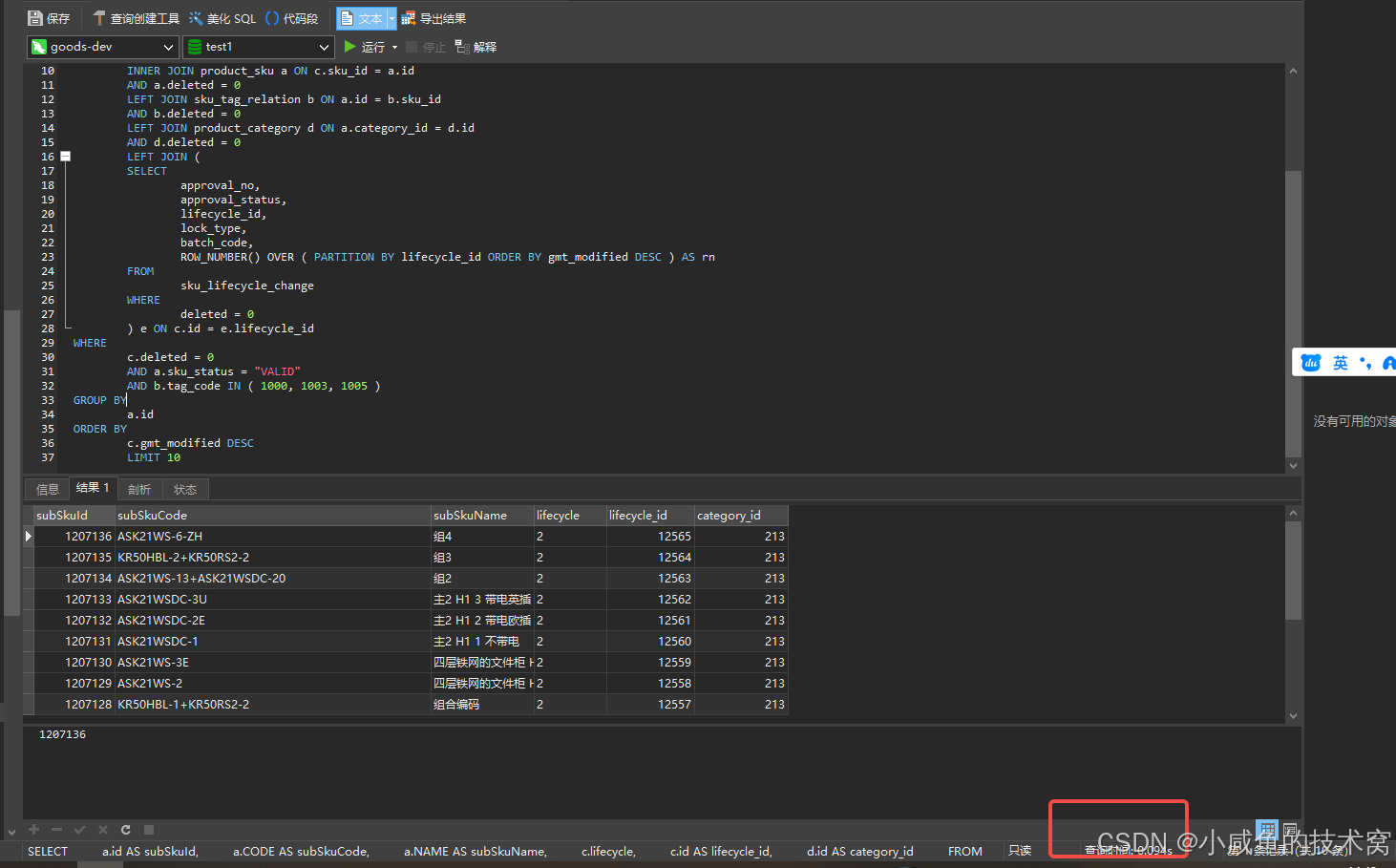
3. 优化点说明
- 主表调整 :以
sku_lifecycle作为主表,通过内连接直接关联有效product_sku数据,排序的话根据sku_lifecycle表走索引排序
四、调优效果对比
| 指标 | 优化前 | 优化后 | 提升比例 |
|---|---|---|---|
| 执行时间 | 1 秒 | 0.09 秒 | 约 91% |
通过本次调优,SQL 语句的执行时间从 1 秒缩短至 0.09 秒,性能提升显著,有效解决了原查询的性能瓶颈,提升了系统响应速度。
五、总结与启示
1、排序字段尽量放到驱动表,不然用临时表排序不走索引的话,即使limit 10,也会慢在排序上面
通过本次实战,我们深刻体会到 SQL 调优对系统性能的关键作用,在日常开发中,应注重编写高效的 SQL 语句,不断提升系统的整体性能。