以下是用达梦数据库的示例数据
达梦数据库有一个特点,会将所有的小写转换成大写运行,如果不加"",加了""就会严格按照大小写进行查询
一、单表查询
(1)查看表结构
方法一:
sql
SELECT DBMS_METADATA.GET_DDL('TABLE','EMPLOYEE','DMHR') FROM dual;
方法二:
sql
SP_TABLEDEF('DMHR','EMPLOYEE')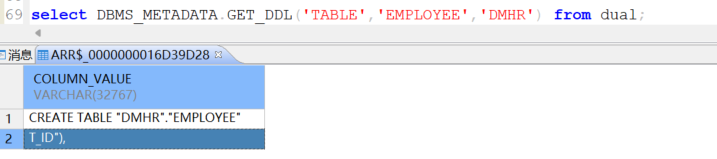
()行过滤
如需按员工入职时间进行筛选,查询 2010 年 8 月 7 日后入职的员工。示例语句如下所示:
sql
select * from "EMPLOYEE" where "HIRE_DATE" > '2010-08-07'(3)查找空值
如需查询工资数据为空的员工,示例语句如下所示:
sql
select * from "DMHR"."EMPLOYEE" where "COMMISSION_PCT" is null
(4)空值与运算
NULL 不支持加、减、乘、除、大小、相等比较,所有查询结构为空
(5)处理空值
因为 NULL 不支持加、减、乘、除、大小、相等比较,所以我们在处理空值之前,需要把空值改为有意义的值。示例语句如下所示:
sql
select "EMPLOYEE_NAME",NVL("COMMISSION_PCT",0) as "COMMISSION_PCT" from "DMHR"."EMPLOYEE";注意
转换函数 (nvl),只能转换 null 值为同类型或者可隐式转换成同类型的值。
只做隐式转换,不是真正将null转换成对应的数值
(6)查找满足多个条件的行
对于需要进行多个条件组合的复杂查询,例如:需查询部门编号为 102 的员工,或者工资大于 20000 的员工,或者部门编号为 105 且工资大于 9000 的员工。示例语句如下所示:
sql
select *
from "EMPLOYEE"
where
"DEPARTMENT_ID" = 102
or "SALARY" > 20000
or (department_id = 102 and salary > 9000);
(7)列别名
列名通常是英文表示,所以可以给列取个别名,增强可读性。可使用 as 关键字或直接跟别名。示例语句如下所示:
sql
SELECT employee_id as "员工id",employee_name as "员工姓名" from "EMPLOYEE"注:as 后面需要用双引号"",不是单引号

(8)检索部分列名
检索部分列需要明确指定要查询的列,而不是用 * 号替代。示例语句如下所示:
sql
select employee_id,employee_name from employee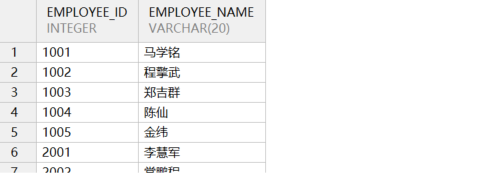
(9)where字句中引用别名列
写报表时,经常会加各种条件,而直接在条件中使用别名(如 C01、C02)要更加的清晰,但是 where 条件引用别名一定要嵌套一层,因为别名是在 select 之后才有效。
错误写法
sql
select employee_id,employee_name,salary as sal
from employee
where sal > 20000;这样会报错:
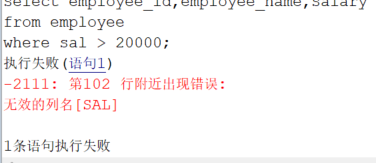
正确语法,需要套一层
sql
select *
from
(
select employee_id,employee_name,salary as sal
from employee
)
where sal > 20000;(10)列拼接
使用 || 可以把字符串拼接起来。示例语句如下所示:
sql
SELECT employee_name || ' salary is ' || salary from employee
(11) select 语句中使用条件逻辑
基本格式
sql
SELECT 字段名
case
when ... then
when ... then
else ''
end as 别名
from 表名;示例:
sql
select employee_name,salary,
case
when salary <= 4000 then 'low'
when salary >= 12000 then 'high'
else 'ok'
end as salary_status
from employee;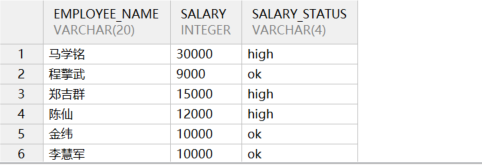
(12)限制返回行数
方法一:
在查询的时候并不是每次都要求返回所有的行,比如抽查的时候只要求返回 10 行,可以使用伪列 rownum 来过滤。示例语句如下所示:
sql
-- 限制返回至少10行
SELECT rownum as rn, *
from EMPLOYEE
WHERE rownum <= 10
方法二:
使用 LIMIT 子句返回十行,示例语句如下所示:
sql
select * from employee limit 10
方法三:
使用 top语句返回十行,示例语句如下所示:
sql
select top 10 * from employee
二、查询结果排序
(1)以指定的次序返回查询结果
为提高查询结果可读性,我们可以对查询结果按照一定顺序排列,例如:按员工生日进行升序排列。示例语句如下所示:
sql
select * from EMPLOYEE
order by hire_date order by:后面如果没有指定排序方式ASC(升序)、DESC(降序),默认ASC

特殊用法,将order by后面的列名替换成数字,意思是按照第几列进行排序,示例语句如下所示:
sql
-- 按照第三列进行排序
select employee_id,employee_name,hire_date
from employee
order by 3 DESC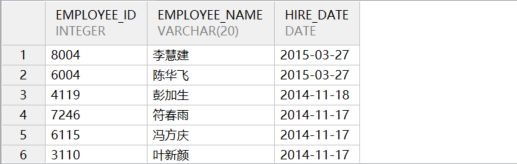
(2)按照多个字段排序
如果想实现按照员工入职日期升序,薪资降序进行排列,可以在 order by 后加两列,并分别标明 ASC, DESC。其中 ASC 表示升序,DESC 表示降序。示例语句如下所示:
sql
-- 按照入职日期升序,薪水降序排序
-- 当入职日期相同时,会按照薪水进行降序排列
select hire_date,employee_name,salary
from employee
order by 1 ASC,3 DESC(3)按子串排列
如果想按照客户手机号尾号的顺序排列,缩小查询范围,可以通过如下函数实现子串排序。示例语句如下所示:
sql
select employee_name,substr(phone_num,-4) as "尾号"
from employee
order by 2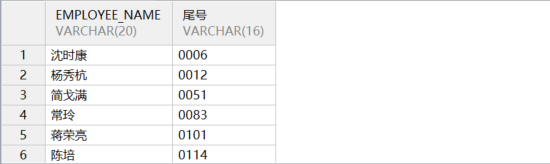
sql
select employee_name,substr(phone_num,4) as "尾号"
from employee
order by 2
注意:substr(字段名,a)从字符串中提取子串
-- 如果a是正数,从第1位开始数,到第4位,第4位之前的都会被去除
-- 如果a是负数,从最后1位开始,到倒数第a位,第a位之前的都会被去除
(4)translate应用
TRANSLATE 应用广泛,可实现字符替换。语法格式如下:
sql
TRANSLATE(expr,from_string,to_string)场景一:字符串替换
from_string 与 to_string 以字符为单位,对应字符逐个替换,它的核心逻辑是**"一对一的逐个字符替换",**示例语句如下所示:
sql
-- 一对一,一一对应
-- a-1;b-2;c-3;d-4;e-5;f-6;g-7
SELECT TRANSLATE ('ab你好bcadefg', 'abcdefg', '1234567') 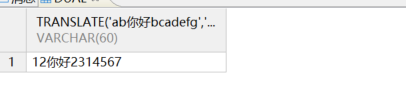
部分替换
sql
-- 一对一,一一对应
-- a-1;b-2;没有对应都会被删除
SELECT TRANSLATE ('ab你好bcadefg', 'abcdefg', '12') 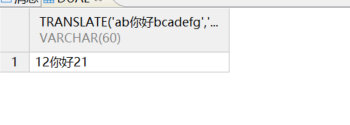
场景二:删除指定字符串
当 from_string 的长度大于 to_string 时,多出来的那些字符在目标集中没有对应项,就会被直接删除
sql
-- 这里巧妙1用作为占用符,1-1,其他的没有对应,都会被删除
SELECT TRANSLATE ('ab你好bcadefg', '1abcdefg', '1') 经典运用:
从一个混合字符串中剔除所有的数字和空格
sql
select translate('武汉2026 你好','- 0123456789','-')如果后面的to_string为空,则输出为空
(5)按数字和字母混合字符串中的字母排序
sql
-- 构建一个视图
create or replace view v as
select postal_code || ' ' || city_id as date from location
-- 查这个视图
select * from v
sql
-- 进行混合查询
select date,translate(date,'- 0123456789','-') as code
from v
order by code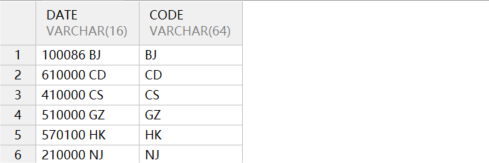
(6)按照指定条件排序
如需将工资在 6000~8000 之间的员工排列在靠前位置,以便优先查看。我们可以在查询中新生成一列,实现指定条件排序。示例语句如下所示:
sql
select job_title,
case
when min_salary >= 6000 and min_salary <= 8000 then 1
else 2 end
as "等级",min_salary
from job
order by 2,3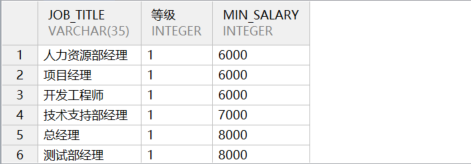
三、多表联合检索
(1)union all 与空字符串
使用 union 或者 union all 关键字合并多个结果集时,对应的列数必须一致,列的数据类型必须匹配。当其中一个结果集的列数不满足要求时,可以使用 NULL 或者 空字符串 填充。示例语句如下所示:
sql
-- 使用NULL填充
SELECT employee_name,department_id
from EMPLOYEE
where rownum < 5
union ALL
select '顾随',null
-- 使用空字符串填充
select employee_name,department_id
from employee
where rownum < 5
union all
select '王飞',''以上输出结果一致
(2)union all 与 or
union all 用于合并两个结果集。比如姓名为常鹏程的员工编号是 2002,所有 or 查询是正确的,但 union all 却重复了。示例语句如下所示:
sql
select * from employee
where employee_id = 2002 or employee_name = '常鹏程'等同于
sql
select * from employees
where employee_id = 2002
union all
select * from employee
where employee_name = '常鹏程'
使用union替换or会使执行计划更高效,出现重复行,使用union去重
sql
select * from employee
where employee_id = 2002
union
select * from employee
where employee_name = '常鹏程'
(3)union与去重
union 也用于合并两个结果集,同时还有去重的功能。union 相当于对 union all 的输出结果再执行一次 DISTINCT 操作。示例语句如下所示:
sql
select * from employee
where employee_id = 2002
union
select * from employee
where employee_name = '常鹏程'
(4)差集函数
EXCEPT 用于从一个表(原表)里查找出某个目标表里不存在的值。
可以先建立一个视图
sql
-- 创建一个视图
create table dept as
select department_id from employee;
-- 添加几个不存在的数据
insert into dept
values
(10010),
(10011),
(10012);
sql
select
department_id
from dept
except
select
department_id
from employee这里就能找到不存在的一些值

(5)in,not in,exists
查询含有 null 值的行时,如果包含 IN、NOT IN 要注意两者的区别。IN 相当于 OR, 而 NOT IN 相当于 AND。示例语句如下所示:
sql
-- in:这里or逻辑 1002 or 1003 or null
select * from
employee
where employee_id
in (1002,1003,null)
-- not in 这里and逻辑 1002 and 1003 and null
select * from
employee
where employee_id
not in (1002,1003,null)第一条语句的结果:

第二条语句的结果:

EXISTS 的作用是**"存在性检查"** ,它不关心子查询查出了什么具体值,只关心有没有查出数据。它前面不需要写字段名,后面必须跟一个完整的子查询。示例语句如下所示:
sql
-- 创建一个视图
create table emp
as
select *
from employee
where employee_id in (1109,1110,1111,1112,1113);
update emp set department_id = 11001 where employee_id = 1109;
update emp set department_id = null where employee_id = 1110;
SELECT * from EMPLOYEE e
where department_id exists (
select department_id from emp
where emp.department_id = e.department_id
);
sql
SELECT * FROM emp
WHERE EXISTS (
SELECT 1 FROM EMPLOYEE e
WHERE emp.department_id = e.department_id
);
-- not exists
SELECT * FROM emp
WHERE not EXISTS (
SELECT 1 FROM EMPLOYEE e
WHERE emp.department_id = e.department_id
); 第一条语句的输出结果:

第二条语句输出结果:

(6)连接类型
连接包括:内连接、左连接、右连接、全连接、自连接 5 种类型,以上连接类型 DM 数据库都支持。
sql
-- 数据准备
-- 创建视图
create table join_emp
as
select employee_name,department_id
from EMPLOYEE
where employee_id in
(SELECT MIN(employee_id) from EMPLOYEE
group by department_id)
LIMIT 10;
INSERT into join_emp values ('黄芪润',9090);- 内连接
结果完全满足连接条件的记录。例如,如需显示员工名称和对应的部门名称。
sql
-- 方法一
select je.employee_name,d.department_name
from join_emp je,department d
where je.department_id = d.department_id
-- 方法二
select je.employee_name,d.department_name
from join_emp je
join department d
on je.department_id = d.department_id以上语句的结果都是一样的
- 左外连接(左连接)
结果不仅包含满足条件的记录,还包含位于左表中不满足条件的记录,此时右表的记录显示为 NULL。示例语句如下所示:
sql
-- 这里的left outer join与left join的区别在于
-- left join是一种常用的写法,收据库引擎会解析成left outer join
select je.employee_name,d.department_name
from join_emp je
left OUTER join department d
on je.department_id = d.department_id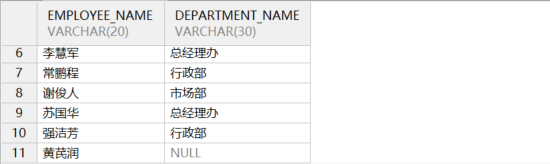
- 右外连接(右连接)
结果不仅包含满足条件的记录,还包含位于右表中不满足条件的记录,对应的左表的记录显示为 NULL。示例语句如下所示:
sql
select je.employee_name,d.department_name
from join_emp je
right join department d
on je.department_id = d.department_id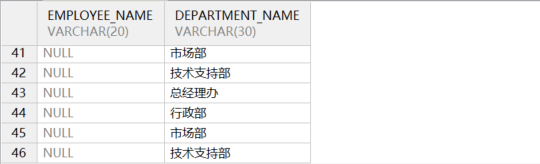
- 全外连接
结果不仅包含满足条件的记录,还会包含位于两边表中所有不满足条件的记录,对应的两边表的记录显示为 NULL。示例语句如下所示:
sql
select je.employee_name,d.department_name
from join_emp je
full join department d
on je.department_id = d.department_id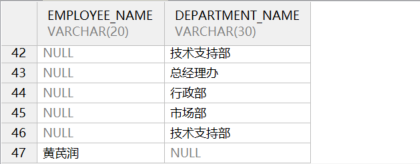
(6)聚集和内连接
首先建立案例用表,示例语句如下所示:
sql
CREATE TABLE dmhr.emp_bonus
(
employee_id NUMBER,
received DATE,
TYPE NUMBER
);
INSERT INTO dmhr.emp_bonus
VALUES (1137, '2020-1-1 8:00', 1);
INSERT INTO dmhr.emp_bonus
VALUES (1137, '2020-3-1 8:00', 2);
INSERT INTO dmhr.emp_bonus
VALUES (1138, '2020-1-1 8:00', 3);
INSERT INTO dmhr.emp_bonus
VALUES (1139, '2020-1-1 8:00', 1);
INSERT INTO dmhr.emp_bonus
VALUES (1140, '2020-1-1 8:00', 1);
COMMIT;以上是员工奖金发放表,type 列决定了奖金的数额。若 type=1,则奖金是工资的 10%;若 type=2,则奖金是工资的 20%; type=3,则奖金是工资的 30%。要求返回上述(部门编号是 105)员工工资和奖金的总额。
- 先关联再聚合,示例语句如下所示:
sql
select
e.employee_id,e.employee_name,salary,type,e.department_id,
(
case
when type = 1 then salary*0.1
when type = 2 then salary*0.2
when type = 3 then salary*0.3
end
) as reward
from employee e
join emp_bonus eb
on e.employee_id = eb.employee_id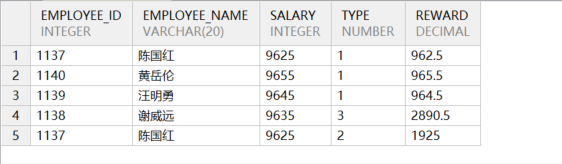
- 聚合后,示例语句如下所示:
sql
select
department_id,sum(salary),sum(reward)
from
(
select
e.employee_id,e.employee_name,salary,type,e.department_id,
(
case
when type = 1 then salary*0.1
when type = 2 then salary*0.2
when type = 3 then salary*0.3
end
) as reward
from employee e
join emp_bonus eb
on e.employee_id = eb.employee_id
)
group by department_id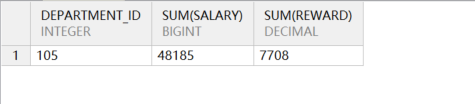
聚合后奖金总额正确,工资总额不对,应该为 38560。示例语句如下所示:
sql
select department_id,sum(salary)
from employee
WHERE employee_id IN (1137,1138,1139,1140)
and department_id = 105
group by department_id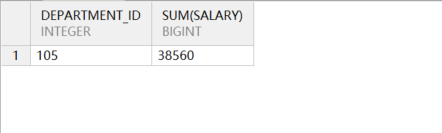
因员工陈国红有两次奖励,其工资重复计算了两次。正确的做法是先把奖金按员工汇总(先聚合),再与员工表关联。示例语句如下所示: