LLM Wiki - 本地知识库管理系统
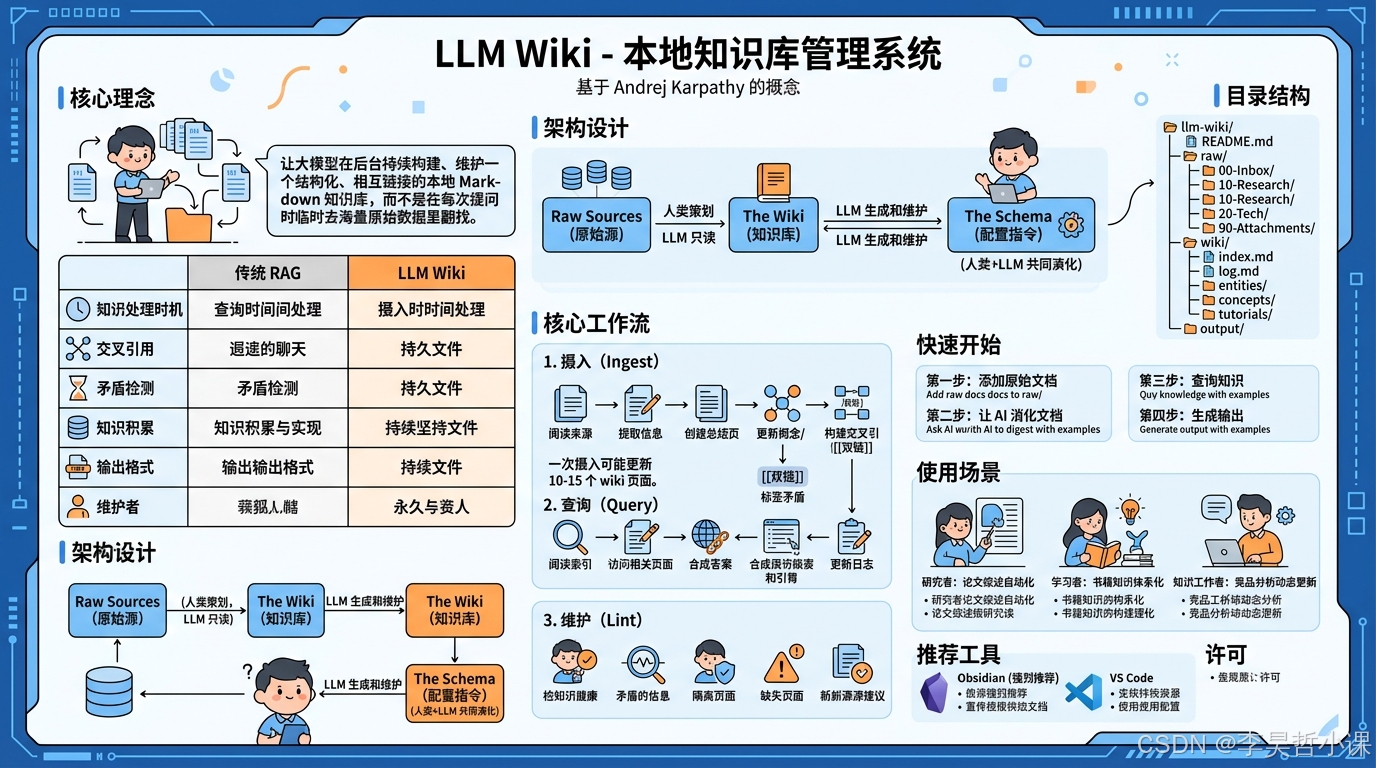
基于 Andrej Karpathy 提出的 LLM Wiki 理念,这是一个由 AI 自动维护的结构化本地 Markdown 知识库。
核心理念
让大模型在后台持续构建、维护一个结构化、相互链接的本地 Markdown 知识库,而不是在每次提问时临时去海量原始数据里翻找。
与传统 RAG 的区别
| 维度 | 传统 RAG | LLM Wiki |
|---|---|---|
| 知识处理时机 | 查询时(每次重新处理) | 摄入时(只处理一次) |
| 交叉引用 | 临时发现 | 预先构建并持续维护 |
| 矛盾检测 | 可能忽略 | 主动标记 |
| 知识积累 | 无(每次从零开始) | 复利式增长 |
| 输出格式 | 聊天回复(转瞬即逝) | 持久化的 Markdown 文件 |
| 维护者 | 系统黑箱 | LLM(透明、可编辑) |
架构设计
三层架构
┌─────────────────┐
│ Raw Sources │ ← 人类策划,LLM 只读
│ (原始源) │
└────────┬────────┘
│ 摄入↓
┌─────────────────┐
│ The Wiki │ ← LLM 生成和维护
│ (知识库) │
└────────┬────────┘
│ 查询↓
┌─────────────────┐
│ The Schema │ ← 人类+LLM 共同演化
│ (配置指令) │
└─────────────────┘目录结构
llm-wiki/
├── AGENTS.md # Schema:LLM 的行为规范
├── README.md # 本文件:使用指南
├── raw/ # 原始素材(人类写入,LLM 只读)
│ ├── 00-Inbox/ # 快速收集箱
│ ├── 01-Daily/ # 每日笔记
│ ├── 10-Research/ # 研究资料
│ ├── 20-Tech/ # 技术文档
│ ├── 30-Business/ # 商业资料
│ ├── 80-Templates/ # 笔记模板
│ ├── 90-Attachments/ # 附件
│ └── 95-Archive/ # 归档区
├── wiki/ # LLM 编译产物(LLM 读写)
│ ├── index.md # 全局索引
│ ├── log.md # 操作日志
│ ├── entities/ # 实体页
│ ├── concepts/ # 概念页
│ ├── sources/ # 源摘要页
│ ├── comparisons/ # 对比分析页
│ └── synthesis/ # 综合分析页
└── output/ # 成品输出
├── posts/ # 博客文章
├── reports/ # 研究报告
├── slides/ # 演示文稿
└── tutorials/ # 教程、指南快速开始
第一步:添加原始文档
将你的文档(文章、论文、笔记等)放入 raw/ 目录的对应子文件夹:
raw/00-Inbox/- 快速收集,稍后整理raw/10-Research/- 研究资料raw/20-Tech/- 技术文档raw/30-Business/- 商业资料
第二步:让 AI 消化文档
在对话中告诉 AI:
请消化这篇文章:[粘贴文章内容或提供文件路径]或者:
请消化 raw/10-Research/ 目录下的所有文档第三步:查询知识
当知识库中有内容后,你可以提问:
什么是 Transformer 架构?
飞行器可靠性有哪些主要方法?
对比一下 RAG 和 LLM Wiki 的区别第四步:生成输出
让 AI 从 wiki 中提炼内容:
基于现有知识,写一篇关于 Transformer 的技术博客
生成一份竞品分析报告
创建一个教程核心工作流
1. 摄入(Ingest)
当你添加新文档时,AI 会:
- 读取源内容
- 提取关键信息
- 创建源摘要页(
wiki/sources/) - 创建/更新概念页(
wiki/concepts/) - 创建/更新实体页(
wiki/entities/) - 建立交叉引用(
[[双链]]) - 标记矛盾信息
- 更新索引和日志
一次摄入可能更新 10-15 个 wiki 页面。
2. 查询(Query)
当你提问时,AI 会:
- 先读
wiki/index.md找相关页面 - 读取相关概念页和源摘要
- 综合回答,带引用
- 如果回答质量高,可存为新的综合页
3. 维护(Lint)
定期检查知识库健康:
请检查一下知识库的健康状况AI 会:
- 检查矛盾(不同源是否有冲突)
- 检查过时(新源是否使旧声明失效)
- 检查孤立(是否有页面无入链)
- 检查缺失(是否有重要概念无独立页面)
- 建议新源(基于知识缺口推荐搜索方向)
使用场景
研究者:论文综述自动化
- 导入 100 篇 PDF 到
raw/10-Research/ - AI 自动生成"领域演进时间线"
- 矛盾结论自动标红
- 自动生成综述报告
学习者:书籍知识体系化
- 每章导入到
raw/00-Inbox/ - 自动生成概念页
- 图谱揭示逻辑链
- 生成学习笔记
知识工作者:竞品分析动态更新
- 导入会议记录和客户反馈
- 自动维护"竞品功能对比表"
- 新功能上线?AI 立即更新对比矩阵
- 生成分析报告
页面格式
所有 wiki 页面都包含:
- YAML Frontmatter:标题、描述、标签、分类、时间戳
- 双链语法 :
[[页面名]]实现交叉引用 - 结构化内容:概述、要点、详细内容、相关概念
- 来源追溯:每个声明都可以追溯到原始来源
标签体系
领域标签
研究 技术 商业 学习 理论 实践
状态标签
待完善 待验证 核心 边缘
类型标签
人物 机构 工具 方法 事件
推荐工具
Obsidian(强烈推荐)
- 纯本地存储,所有数据都是
.md文件 - 原生支持
[[双链]]语法 - 图谱视图可视化知识结构
- 插件生态(Dataview、Web Clipper 等)
配置方法:
- 下载并安装 Obsidian
- 选择
f:\llm-wiki作为 Vault - 启用 Daily notes 插件
- 安装 Dataview 插件(可选)
VS Code
- 安装 Markdown 插件
- 安装 Markdown Preview Enhanced
- 使用搜索功能查找页面
最佳实践
- 保持 raw/ 的整洁:定期整理收集箱,归档旧文件
- 定期查询:通过提问发现知识缺口
- 定期维护:每周让 AI 检查知识库健康
- 善用输出:将 wiki 内容转化为文章、报告、教程
- 版本控制:使用 Git 管理知识库版本(可选)
高级技巧
批量摄入
请批量消化 raw/20-Tech/ 目录下的所有文档主题综合
基于现有知识,综合一下关于"机器学习"的所有内容知识缺口分析
分析一下当前知识库的缺口,建议我应该摄入哪些方面的资料?生成特定格式输出
基于 wiki 中关于 Docker 的内容,生成一份教程注意事项
- 永远不要手动修改 wiki/ 目录的文件(除非你要纠正 AI 的错误)
- raw/ 是你的领地,AI 绝不修改
- 保持文档质量:输入垃圾,输出也是垃圾
- 定期备份:虽然都是本地文件,但建议定期备份
- 耐心:知识库需要时间积累,不要期望一次摄入就完美
扩展阅读
许可
本项目采用本地知识库管理理念,可自由使用和修改。