一、OKR
O:初步熟悉Prompt,Playwaright,以及Claude code,知道如何利用三者做浏览器自动化测试
KR1:讲得出三者的概念和关系,以及应用场景
KR2:写个demo,你要测试一个网站(比如登录、搜索)
二、基本概念
|---------------|-------------|-------------------|
| 名称 | 概念 | 应用 |
| Prompt | 给AI的"需求文档" | 告诉ai你要什么,怎么写,什么格式 |
| Claude/Cursor | ai 编程助手 | 读prompt -> 生成代码 |
| Playwright | 自动化操作浏览器的工具 | 模拟真人点击、输入、截图、验证 |
三、demo
1、测试流程对比
传统做法:
- 打开 Playwright 文档
- 查 API 怎么写
- 自己敲代码
- 调试跑通
AI 辅助做法:
- 写一个清晰的 Prompt(描述要测什么,好 Prompt → 一次跑通,所以我的prompt也是ai写的(ง ˙o˙)ว)
- AI 直接生成可运行的代码
- 复制粘贴运行
2、步骤
2.1 用Claude code生成prompt
这里举例:我叫他帮我分析我的博客
用 Playwright (Python) 写一个自动化测试脚本,测试 CSDN 博客主页:
【测试目标】
- 测试地址:https://blog.csdn.net/m0_61472704?spm=1010.2135.3001.5343 - 这是一个 CSDN 博客个人主页
【测试步骤】
打开浏览器,访问该博客主页
等待页面完全加载
断言页面标题包含 "CSDN"
验证博主昵称显示在页面上(获取并打印博主名字)
验证文章列表区域存在(class 或 id 包含 "article-list" 或类似)
获取第一篇文章的标题并打印
点击第一篇文章标题进入详情页
断言文章详情页加载成功(URL 变化或出现文章内容)
截图保存 blog_page.png
返回上一页,截图保存 blog_home.png
【技术要求】
用 pytest 框架
用 Playwright 同步 API
headless=False 方便观察
使用 expect 进行断言
适当使用 wait_for_load_state 等待页面稳定
代码要完整可运行,包含 import
添加注释说明每步在做什么
【输出格式】
完整 Python 代码(保存为 test_csdn_blog.py)
安装依赖的命令
运行命令
可能的坑和注意事项(比如 CSDN 可能有反爬、弹窗等)
复制上面的 Prompt 发给 Claude/Cursor,它会给你生成完整代码
2.2 Claude code编码
新建文件 → test_csdn_blog.py
python
"""
CSDN 博客自动化测试 - 修复版
"""
import re
from playwright.sync_api import sync_playwright
def test_csdn_blog():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page(viewport={'width': 1280, 'height': 800})
try:
print("🚀 开始测试 CSDN 博客...")
# 1. 访问博客主页
page.goto("https://blog.csdn.net/m0_61472704?spm=1010.2135.3001.5343")
page.wait_for_load_state("networkidle")
# 关闭可能的弹窗
page.keyboard.press("Escape")
page.wait_for_timeout(1000)
# 2. 验证标题
assert "CSDN" in page.title(), f"标题不含CSDN,实际标题: {page.title()}"
title = page.title()
print(f" ✅ 标题: {title}")
# 3. 获取博主名(从标题提取,避开随机属性)
author_name = title.split("-")[0].replace("*", "").strip()
print(f" ✅ 博主: {author_name}")
# 4. 找文章列表(用更通用的选择器)
# CSDN 文章通常有 article 标签或包含 article/details 的链接
articles = page.locator("a[href*='/article/details/']")
count = articles.count()
print(f" ✅ 找到 {count} 篇文章")
if count == 0:
raise Exception("未找到文章链接")
# 5. 获取第一篇文章标题
first_title = articles.nth(0).inner_text()
print(f" ✅ 第一篇文章: {first_title[:50]}...")
# 6. 点击第一篇文章
print("[6] 点击进入文章...")
articles.nth(0).click()
page.wait_for_load_state("networkidle")
print(f" ✅ 当前URL: {page.url}")
# 7. 截图
page.screenshot(path="blog_detail.png", full_page=True)
print(" ✅ 截图已保存: blog_detail.png")
# 8. 返回并截图首页
page.go_back()
page.wait_for_timeout(1000)
page.screenshot(path="blog_home.png", full_page=True)
print("\n✅ 测试全部通过!")
print(f" 博主: {author_name}")
print(f" 文章: {first_title}")
except Exception as e:
print(f"\n❌ 错误: {e}")
page.screenshot(path="error.png")
raise
finally:
browser.close()
if __name__ == "__main__":
test_csdn_blog()2.3 测试
bash
# 安装pytest-playwright
pip install pytest-playwright
bash
# 安装浏览器驱动
playwright install chromium然后运行脚本就好了(python test_csdn_blog.py)
2.4 结果
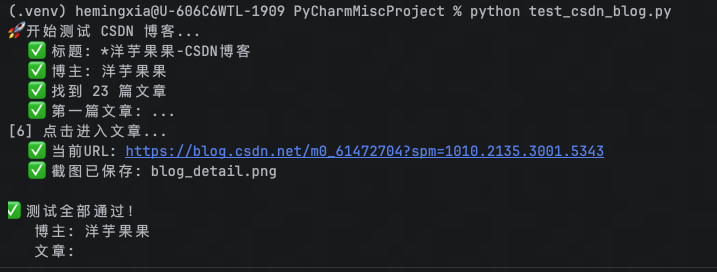
呃呃呃呃.......AI好厉害,我好像什么都没干,ㄟ( ̄▽ ̄ㄟ)