快速了解部分
基础信息(英文):
- 题目: DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
- 时间: 2026.02
- 机构: NVIDIA
- 3个英文关键词: World Model, Latent Action, Video Diffusion
1句话通俗总结本文干了什么事情
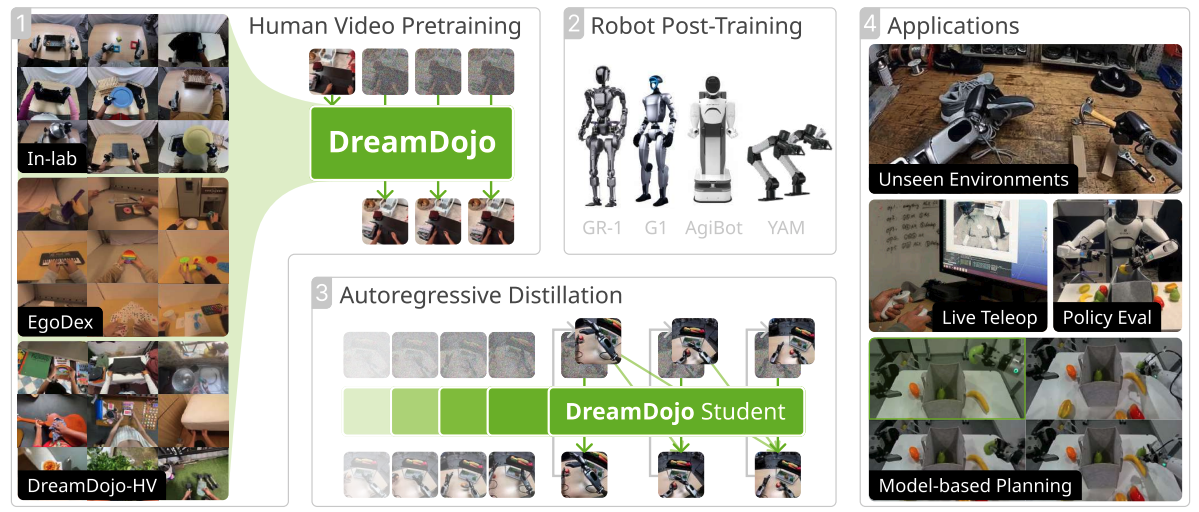
NVIDIA搞了一个叫DreamDojo的"机器人模拟器",它通过看几万小时人类第一人称视频学会了物理常识和动作逻辑,能让机器人在脑子里"做梦"预演未来,从而学会各种没见过的复杂动作。
研究痛点:现有研究不足 / 要解决的具体问题
- 数据太少太贵:机器人自己收集带动作标签的数据太慢,覆盖的场景和物体非常有限(In-distribution)。
- 泛化不行:现有的机器人模型只能在见过的环境里干活,换了个没见过的物体或者稍微复杂点的接触动作(Dexterous tasks),模型就直接"断片"了,无法模拟。
- 动作缺失:虽然网上有人类视频,但没人给视频标动作数据,机器人没法从这些视频里学会"怎么做"。
核心方法:关键技术、模型或研究设计(简要)
- 看片学习:用44,000小时的人类第一人称视频(Ego-centric videos)做预训练。
- 潜动作(Latent Action):发明了一种通用的"动作语言",把视频里的人类动作翻译成机器人能理解的数学向量,解决了没动作标签的问题。
- 蒸馏加速:把一个慢吞吞的大模型蒸馏成一个能实时运行(10.81 FPS)的小模型,让机器人能一边操作一边预测画面。
深入了解部分
作者想要表达什么
作者想证明,不需要昂贵的机器人实操数据,只需要通过大规模学习人类的视觉经验(看视频),配合一种通用的动作编码,就能训练出一个能理解物理世界、并且能精确控制的通用机器人世界模型。这种"预训练+微调"的路子是通往通用机器人的捷径。
相比前人创新在哪里
- 数据量级的碾压:以前的机器人世界模型数据量级很小,DreamDojo用了4.4万小时的人类视频,比之前的机器人数据集大了几个数量级,且涵盖了6000多种技能。
- 跨形态的理解:以前的方法很难把人类视频里的动作直接迁移到机器人的身体上(Embodiment Gap),本文通过"潜动作"实现了这种跨形态的通用理解。
- 真正能用的实时性:以前的视频生成模型(Diffusion Models)推理速度极慢,本文通过Self-Forcing蒸馏技术,做到了全分辨率视频的实时生成,这是能用于实际机器人控制的关键。
解决方法/算法的通俗解释
想象一下,你想教一个没见过猫的机器人抓猫。
- 以前的方法:你得买一堆猫,让机器人反复试错,摔坏几百次才能学会。
- DreamDojo的方法 :
- 先让机器人看几万部人类抓东西的电影(人类视频),虽然电影里没写"左手抬高5度",但机器人自己总结出了一套"潜动作密码"来理解这些动作。
- 然后,你给机器人看一眼猫的照片,它就能在脑子里用这套"密码"模拟出抓猫的画面,算出怎么动才不会抓空。
- 最后,为了让它脑子转得够快,研究人员把它的大脑压缩了一下,让它能一边动一边实时预演,而不是想一秒动一下。
解决方法的具体做法
- 构建数据集:收集了44,711小时的人类第一人称视频(DreamDojo-HV),包含各种场景和技能。
- 预训练(学常识) :
- 训练一个潜动作模型,把视频帧之间的变化压缩成32维的向量(Latent Action),作为通用动作标签。
- 用Cosmos-Predict2.5视频生成模型架构,输入"潜动作",预测下一帧画面。
- 微调(学控制):拿到具体的机器人后,用少量的机器人操作数据微调模型的动作层,让机器人学会用自己的身体。
- 蒸馏(提速):用"老师教学生"的方法(Self-Forcing),把慢速的生成模型蒸馏成一个能自回归、少步数的快速模型。
基于前人的哪些方法
- Cosmos-Predict2.5:作为基础的视频生成模型架构。
- Latent Action (Adaptive World Models):参考了之前用潜变量表示动作的研究,但本文将其扩展到了大规模人类视频和机器人控制上。
- Self-Forcing:基于Xun Huang等人提出的视频生成蒸馏方法,实现了从慢模型到快模型的转换。
实验设置、数据、评估方式、结论
- 数据:44k小时人类视频 + 少量机器人数据(GR-1, G1等)。
- 评估方式 :
- 指标:PSNR, SSIM, LPIPS(看生成的画面像不像)。
- 人类打分:看物理逻辑对不对,动作跟不跟手。
- 下游任务:策略评估(Policy Evaluation)、基于模型的规划(Planning)、实时遥操作(Teleoperation)。
- 结论 :
- 泛化强:在没见过的物体和场景(OOD)上,效果远超没有预训练的模型。
- 实时性:蒸馏后的模型在单卡上能达到10.81 FPS,能实时生成640x480的视频。
- 有用:在水果装袋任务中,它预测的成功率和真实世界成功率高度相关(Pearson r=0.995),证明它能当"模拟器"用。
提到的同类工作
- Cosmos-Predict2.5:本文的基础模型,没有动作控制能力。
- RT-1, BridgeData V2:典型的机器人数据集,但规模和多样性远不如本文。
- EgoDex:一个公开的人类操作数据集,被本文用作数据来源之一。
- VAP, AdaWorld, DexWM:同样是利用人类视频或潜动作进行机器人学习的研究,但本文在规模和通用性上更进一步。
和本文相关性最高的3个文献
- Cosmos-Predict2.5 model (Ali et al., 2025):本文的基座模型,没有它就没有后续的改造。
- AdaWorld: Learning Adaptable World Models with Latent Actions (Gao et al., 2025):本文潜动作概念的核心来源,解决了动作表示的问题。
- Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion (Huang et al., 2025):本文实现实时推理的关键蒸馏技术来源。
我的
- 搞了一个Value model,用途:主要用于在线策略引导(Online Policy Steering),流程如下:
生成候选:系统集成多个策略模型,生成多个不同的动作提案(Action Proposals)。
模拟未来:将这些动作输入 DreamDojo,生成对应的未来视频。
价值评估:Value Model 观看这些视频,计算每个视频的"剩余时间步"得分。
择优执行:系统选择 Value 最低(即最接近完成任务)的那个动作提案,发送给真实机器人去执行