Vegeta 工具
接口性能测试是日常工作中不可或缺的环节------上线前需验证服务承载能力,迭代后需排查性能瓶颈,而一款高效、易用的压测工具,能帮我们省去大量繁琐操作。今天就给大家分享一款"战斗力超过9000的HTTP压测神器Vegeta,结合实战案例,带你快速上手;
1. vegeta 介绍
Vegeta 是一款用Go语言开发的开源 HTTP 负载测试工具,既能作为命令行工具使用,也能作为 go 库集成到项目中,主打"简易易用、功能强大",尤其适合快速验证接口的性能上限和稳定性。
2. 快速安装
bash
# 下载链接
wget https://github.com/tsenart/vegeta/releases/download/v12.11.1/vegeta_12.11.1_linux_amd64.tar.gz
# 解压
tar -xzvf vegeta_12.11.1_linux_amd64.tar.gz
#移动到系统的可执行路径
sudo mv vegeta /usr/local/bin/发行版本的下载链接
bash
# 可以在浏览器访问该地址,寻找自己的需要的版本
https://github.com/tsenart/vegeta/releases/tag/v12.13.0
验证安装成功
安装完成后,在终端输入以下命令,能显示版本信息即代表安装成功:
bash
vegeta -version
3. 核心用法
Vegeta 的核心命令非常简洁,主要围绕「发起压测(attack)」和「生成报告(report)」两个核心操作,配合少量参数就能完成大部分压测场景,无需记复杂命令,记住以下几个案例即可上手。
命令简介:
- attack:发起测试,可配置压测速率,持续时间,超时时间等核心参数;
- report: 生成压测报告,支持文本、Json、直方图等多种格式;
- plot: 将压测结果生成 HTML 可视化图表,直观查看延迟分布;
- **encode:**将压测结果转换为指定格式(如json、csv),方便后续分析。
3.1 基础压测
对本地的 80 端口服务,发起 5 秒压测,查看接口基本的性能(请求成功率、延迟等)
bash
echo "GET http://localhost/" | vegeta attack -duration=5s |tee result.bin | vegeta report命令解析:
- echo "GET http://localhost/":指定压测的HTTP请求(方法+URL),请求方法必须大写(GET、POST等);
- vegeta attack -duration=5s: 发起压测,
-duration指定压测持续时间(5s=5秒,支持m=分钟、h=小时); - tee result.bin:将压测原始数据保存到
result.bin文件(后续生成多种报告) - vegeta report:生成默认文本报告,直观展示压测结果。

当前本地并未开启任何服务,因此不能连接上去;
3.2 自定义压测速率
需求:对目标接口(http://api.example.com/users),每秒发起100个请求,持续30秒,请求超时时间设置为10秒,生成JSON格式报告用于自动化分析。
bash
echo "GET http://api.example.com/users" | \
vegeta attack -rate=100/s -duration=30s -timeout=10s | \
vegeta report -type=json > metrics.json关键参数:
- rate=100/s:指定每秒请求速率(100/s=每秒100个请求,可以根据需求调整,如 500/s)
- -timeout=10s:指定为单个请求的超时时间,避免印接口响应过慢导致测试卡住;
- -type=json:指定报告格式为 JSON,输出到
metrics.json文件,方便后续用脚本解析或导入监控系统。
额外补充(可选观看):压测大模型服务
前提说明:vllm部署glm5模型后,默认提供HTTP接口(通常为POST请求,接口地址默认 http://localhost:8000/v1/chat/completions,具体以你的vllm部署配置为准),以下所有Vegeta压测命令、配置文件,均适配glm5模型的接口规范,可直接修改接口地址后使用。
如果只测试单个接口的简单测试可以
bash
echo 'POST http://localhost:8000/v1/chat/completions
Content-Type: application/json
{"model":"glm5","messages":[{"role":"user","content":"简述vllm部署glm5的优势"}],"max_tokens":150,"temperature":0.7}' | vegeta attack -rate=3/s -duration=20s | vegeta report比较大规模的压测如下所示
**步骤1:**准备压测目标文件
由于glm5模型接口为POST请求,需携带请求体(prompt、参数等),因此优先使用「目标文件」方式压测,避免命令行过长,同时方便修改模型参数。
创建文件:glm5-targets.txt(文件名可自定义),内容如下(复制即可,重点修改接口地址和prompt):
bash
# 第一个测试用例:基础文本生成(适配glm5 chat接口,最常用)
POST http://localhost:8000/v1/chat/completions
Content-Type: application/json
@./glm5-prompt.json
# 第二个测试用例:短prompt快速响应测试(用于验证接口吞吐量),感觉不是很好用
POST http://localhost:8000/v1/chat/completions
Content-Type: application/json
{"model":"glm-5","messages":[{"role":"user","content":"请简单介绍一下自己"}],"temperature":0.7,"max_tokens":100}
# 第三个测试用例:长prompt测试(模拟复杂请求,验证模型稳定性)
POST http://localhost:8000/v1/chat/completions
Content-Type: application/json
{"model":"glm-5","messages":[{"role":"user","content":"详细解释Vegeta压测工具的核心原理,结合vllm部署的glm5模型,说明压测时需要注意的性能瓶颈点,要求逻辑清晰、重点突出,不少于300字"}],"temperature":0.5,"max_tokens":500}**步骤二:**准备请求体文件
若需要频繁修改prompt或模型参数,可单独创建请求体文件,方便维护,内容如下:
json
{
"model": "glm-5", // 模型名称,必须与vllm部署的glm5模型名称一致
"messages": [
{
"role": "user",
"content": "请使用Vegeta压测工具测试vllm部署的glm5模型,输出压测核心命令和注意事项,语言简洁实用"
}
],
"temperature": 0.6, // 模型生成温度,0-1之间,按需调整
"max_tokens": 300, // 最大生成token数,避免生成过长内容导致压测超时
"top_p": 0.9, // 可选参数,控制生成多样性
"stream": false // 压测时建议关闭流式输出,避免响应格式复杂
}**步骤三:**开始压测
依赖的两个配置文件(glm5-targets.txt、glm5-prompt.json)放在同一目录下。
-
基础压测
需求:每秒发起5个请求,持续30秒,测试glm5接口基本响应能力,生成文本报告。
bashvegeta attack -targets=glm5-targets.txt -rate=5/s -duration=30s -timeout=30s | tee glm-result.bin | vegeta report说明:
- timeout,glm5模型生成内容需要时间,超时时间设置为30秒(可根据max_tokens调整,token越多,超时时间需越长);
- tee glm5-results.bin:保存压测原始数据,后续可用于生成可视化图表;
- 若接口地址不是localhost:8000,需修改
glm5-targets.txt中的POST地址(如http://192.168.1.100:8000/v1/chat/completions)。
-
高并发压测
需求:每秒发起20个请求,持续1分钟,测试glm5模型在高并发下的性能(吞吐量、延迟、成功率),生成JSON报告用于后续分析。
bashvegeta attack -targets=glm5-result.bin -rate=20/s -duration=1m -timeout=60s -insecure | vegeta report -type=json > glm5-metrics.json说明:
- -rate=20/s:并发请求速率,可根据vllm部署的服务器配置调整(如CPU/GPU性能强,可提升至30/s、50/s);
- -insecure:若vllm部署了HTTPS接口,添加此参数绕过TLS证书验证;
- glm5-metrics.json:JSON格式报告,可查看详细的延迟分布、状态码、吞吐量等指标。
-
可视化图表压测
需求:基于基础压测的数据,生成HTML可视化图表,清晰查看glm5模型在压测过程中的延迟变化、请求成功率等,方便汇报和优化。
bash# 1. 先执行压测并保存原始数据 vegeta attack -targets=glm5-targets.txt -rate=10/s -duration=40s -timeout=40s > glm5-results.bin # 2. 生成可视化HTML图表 cat glm5-results.bin | vegeta plot > glm5-plot.html使用方法:执行完成后,直接打开glm5-plot.html文件,即可看到延迟分布曲线、请求速率、成功率等直观图表,重点关注P95、P99延迟(若过高,说明vllm部署或glm5模型需优化)。
-
关键注意项:
- 接口地址确认:vllm部署glm5后,默认接口为 /v1/chat/completions(对话场景)或 /v1/completions(补全场景),需确认自己的部署地址,避免报错;
- 超时时间设置:glm5模型生成内容的时间与max_tokens正相关,max_tokens越大,超时时间需越长(建议设置为30-60秒),否则会出现大量超时失败;
- 并发速率控制:vllm部署的并发能力取决于服务器 GPU/CPU性能,建议从**低速率(5/s)**开始逐步提升,避免一次性并发过高,导致vllm服务崩溃;
- 请求体规范:glm5的请求体必须包含 model、messages 字段,temperature、max_tokens 为可选参数,需与vllm部署的模型参数兼容;
- 失败排查:若压测中出现大量500状态码,需检查vllm服务是否正常运行、glm5模型是否部署成功;若出现400状态码,需检查请求体格式是否正确。
3.3 多接口压测
实际工作中,我们常需要测试多个接口的并发性能,此时可通过「目标文件」指定多个接口,无需逐个输入命令。
**步骤 1:**创建目标文件(targets.txt),格式如下(空行分割多个接口,可添加请求头、请求体):
bash
GET http://api.example.com/users
Header-X: token123
POST http://api.example.com/login
Header-Content-Type: application/json
@/path/to/login-body.json说明:POST 请求可以通过@指定请求体文件(login-body.json为请求体内容),也可以直接在文件中编写请求头信息。
**步骤2:**执行压测,指定目标文件
bash
# 设置请求间隔为 1 min
vegeta attack -targets=targets.txt -rate=50/s -duration=1m | vegeta report3.4 生成可视化图表
文本报告不够直观?Vegeta可生成HTML图表,清晰展示延迟分布、请求成功率等指标,方便汇报和分析。
bash
# 利用之情保存的 result.bin 文件, 生成 HTML 图表;
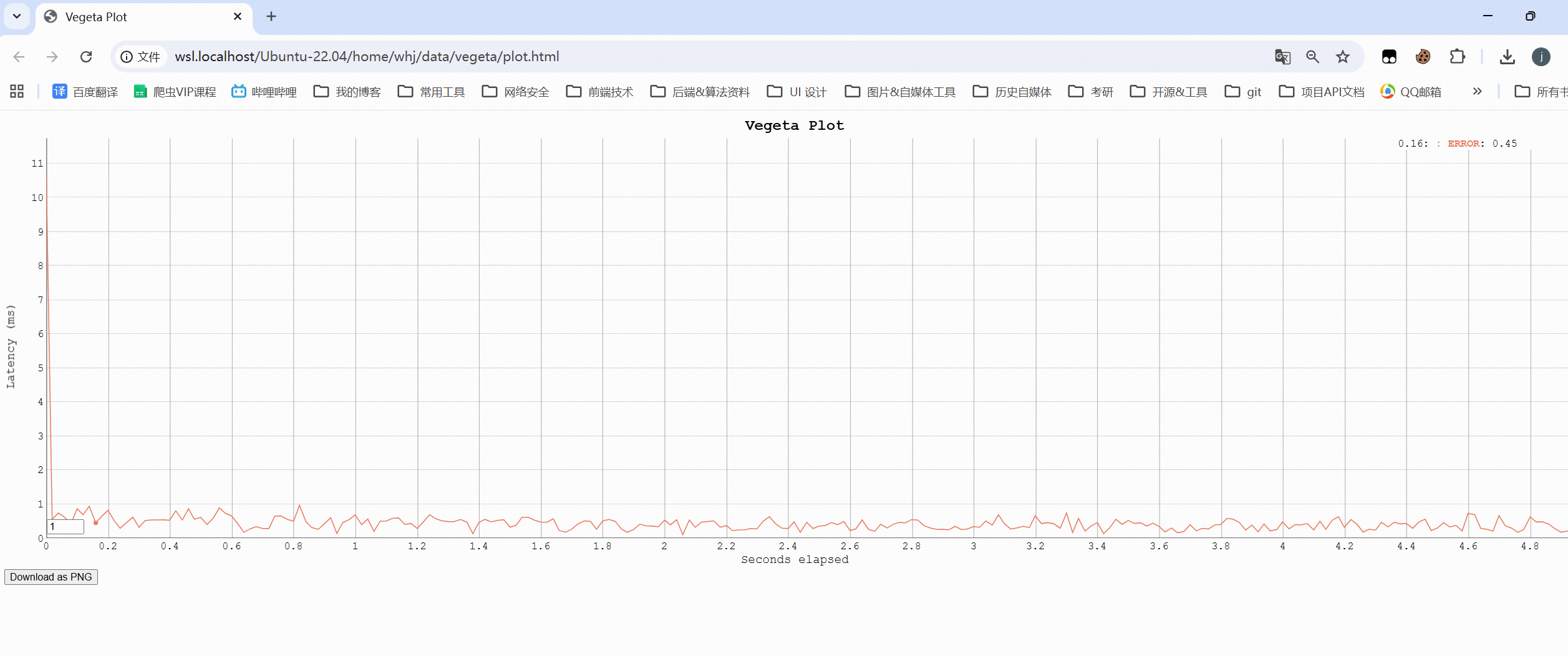
cat results.bin |vegeta plot > plot.html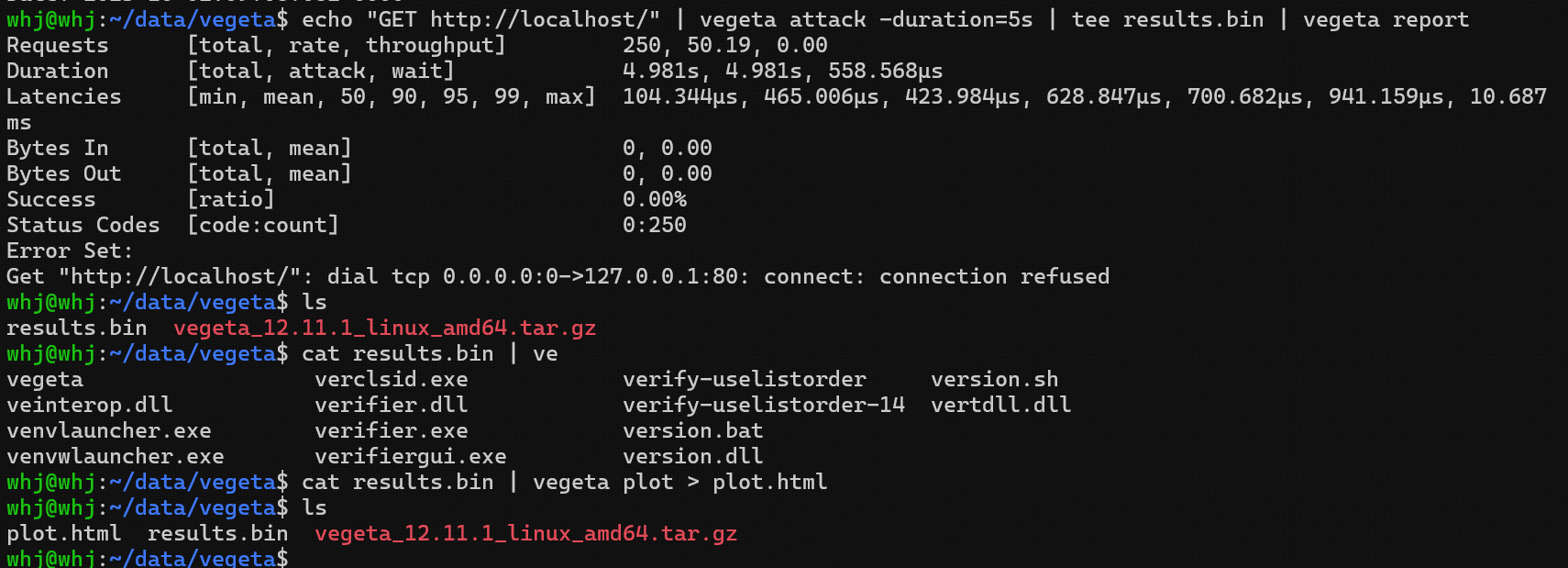
执行完成后,打开plot.html文件,即可看到直观的延迟分布曲线、请求速率变化等图表,一目了然。
3.5 分布式压测
当单机性能达到瓶颈,无法模拟超高并发(如每秒10万+请求)时,Vegeta支持分布式压测,多台机器同时发起压测,最后汇总结果。
**步骤1:**在每台机器上执行压测命令,保存结果文件:
bash
echo "GET http://target/" | vegeta attack -rate=20000/s -duration=60s > result.bin步骤2:收集所有机器的result.bin文件,汇总生成报告:
bash
vegeta report *.bin4. 压测报告解读
执行压测后,Vegeta的文本报告包含多个核心指标,重点关注以下5个,就能快速判断接口性能:
bash
Requests (total, rate, throughput) 500, 501.00, 498.00 # 请求总数、每秒请求速率、实际吞吐量
Duration (total, attack, wait) 998.57ms, 997.99ms, 571.85µs # 总时长、压测时长、等待时长
Latencies (mean, 50, 95, 99, max) 1.08ms, 561.99µs, 2.41ms, 12.11ms, 22.10ms # 延迟分布(重点看P95、P99)
Bytes In (total, mean) 306000, 612.00 # 接收字节总数、平均每个请求接收字节数
Success (ratio) 100.00% # 请求成功率
Status Codes (code:count) 200:500 # 状态码分布(200代表成功)指标解读:
-
吞吐量(throughput):实际每秒处理的请求数,越接近请求速率,说明接口性能越好;
-
延迟分布(P50、P95、P99):P50表示50%的请求延迟不超过该值,P95、P99是核心指标------若P99延迟过高,说明接口在高并发下存在瓶颈,需优化;
-
成功率:必须达到100%(或符合业务预期),若出现失败,需排查接口报错、超时等问题;
-
状态码分布:重点关注非200状态码(如404、500),出现异常状态码需排查接口可用性或参数问题。
5. 特别注意
- 请求方法必须大写:Vegeta 严格区分请求方法大小写,写
Get、Post会报错,必须写GET、POST; - 避免测试机器成为瓶颈:压测前确保测试机器的CPU、内存充足,否则会导致测试结果失真;
- TLS证书问题:测试HTTPS接口时,若出现证书错误,可添加*-insecure*参数绕过TLS验证;
- 循序渐进压测:从低速率(如10/s)开始,逐步增加速率,避免一次性发起过高并发,导致目标服务崩溃;
- 保存原始数据:尽量用tee命令保存压测原始数据(.bin文件),方便后续重新生成报告或进行二次分析。
6. 总结
Vegeta的核心优势的在于"轻量、高效、灵活"------无需复杂配置,5分钟就能上手,既能满足新手快速验证接口性能的需求,也能支撑资深工程师的复杂压测场景(分布式、自动化集成)。
对于开发/运维人员来说,掌握Vegeta,能快速排查接口性能瓶颈、验证服务稳定性,大大提升工作效率。
继续努力,终成大器;