本文主要介绍了Selenium 4自动化测试中,新手容易踩坑的几个点:
-
网页元素排查方法 :手把手教Ctrl+Shift+I打开开发者工具,讲解如何查看、复制网页最新元素属性,解决元素找不到问题。
-
反爬伪装与ChromeOptions配置:区分普通启动与深度伪装启动,说明新版百度网页反爬检测机制及规避方法。
-
元素定位与显式等待:详解WebDriverWait智能等待,对比time.sleep()呆板等待,解释老式定位代码失效原因。
-
JavaScript注入交互:解释元素不可点击报错成因,利用JS绕过页面遮挡,稳定操作网页元素。
最后补充说明:结合本人真实排查排错经历,纠正网上老旧百度定位代码,强调不要死抄代码,要学会自己抓最新元素,明白代码是死的、网页是活的核心逻辑。
前言:踩坑真实经历
最近跟着网上教程和一些前辈的博客做百度自动化搜索案例。第一次运行报错的时候,我反复对比了一下我的代码和网上教程的代码,一开始我的代码有些跟教程不一样(其实只是代码风格不同,其实我一开始这样写也没问题了),后来我把代码改的一模一样,还是报错抛出 ElementNotInteractableException(元素不可交互) 。
在这里插入图片描述
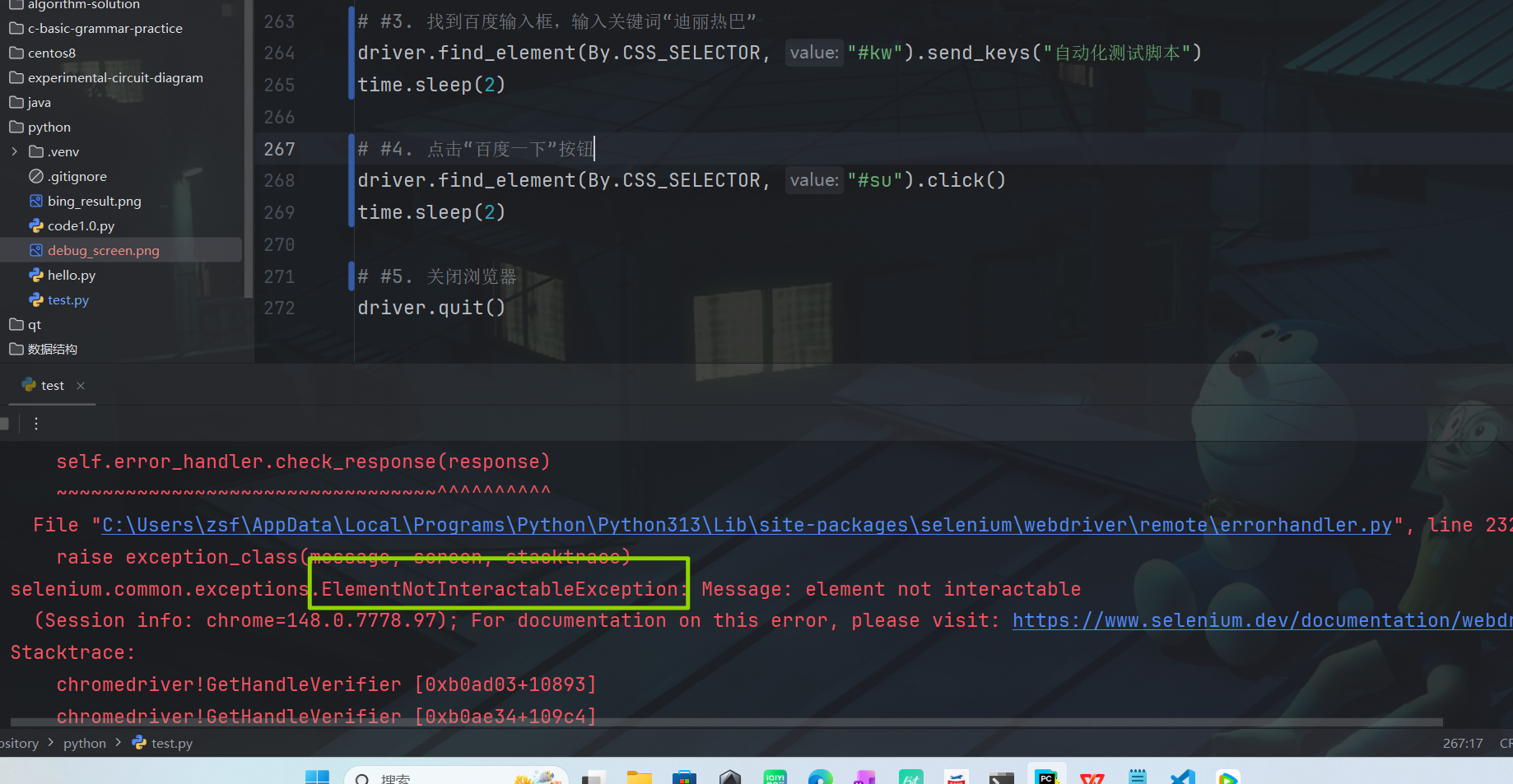
我第一反应:是不是我代码打错了?反复检查标点、大小写、语法,确认没有任何逻辑和语法相关错误。
后来让deepseek帮我检查一下错误,deepseek只是改变了一下写法,改成模拟键盘输入回车的写法,但还是报一样的错误。
反复对比了视频教程,又搜了好几篇博客,确认跟我的代码没有区别,我就觉得问题不是出在代码上,而是百度上。我改成必应,脚本执行就成功了。
因为我看的教程视频和博客都是24、25年发布的。
我意识到一定是网页版本发生了变化,这时候我不会排查,网上到处查资料,才知道浏览器自带开发者工具可以查看网页源码。
Ctrl+Shift+I 或者 鼠标右键->检查 ,打开开发者工具,查看新的元素信息,终于发现关键问题:
百度早已更新元素属性,老旧的 kw、su 对新版页面已经无效了,目前最新有效属性,例如:
-
搜索输入框CSS选择器:chat-textarea
-
搜索按钮CSS选择器:chat-submit-button
但是 !!改完元素属性后,本以为直接通关,没想到还是一样报同样的错误。我也确定了我加入了sleep保证网页百分百完全刷新出来了。
后来又了解到,是百度识别出自动化脚本,人为拦截操作。
这一趟踩坑,我从找不到元素→改最新属性→被网站反爬拦截,全程排查摸索。今天把完整思考过程、排查方法、实例代码分享出来,帮助大家避坑。也让未来的我印象更深刻不再踩坑。
一、网页元素排查:开发者工具使用教程
很多新手报错找不到元素,最大的问题:只会抄别人代码,不会自己抓取最新网页元素。网页每周都会微调,别人的永久代码永远不通用。
1.1 核心
开发者工具:浏览器自带的网页源码查看工具,不需要下载软件,快捷键一键打开,用来查看网页标签、ID、class等元素属性,是自动化排错的第一工具。
1.2 小白实操步骤(手把手教学)
以百度首页为例,教大家抓取最新元素,全程简单无脑操作:
-
打开浏览器,按下快捷键Ctrl + Shift + I 也可以鼠标右键->点击检查 ,直接唤起开发者工具面板;
-
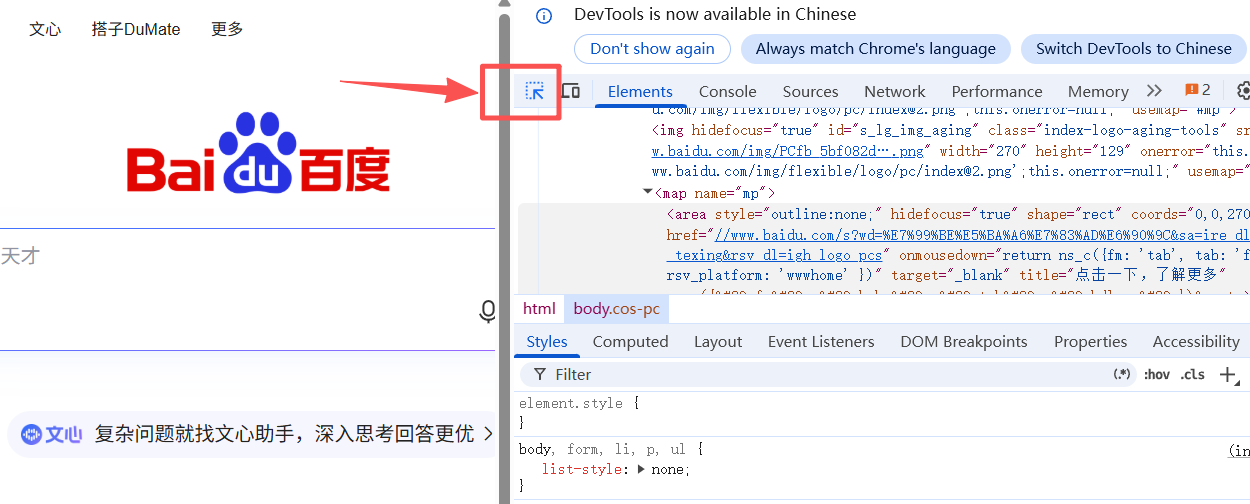
点击面板左上角箭头图标(元素选择器) ,鼠标变成选中状态;
-
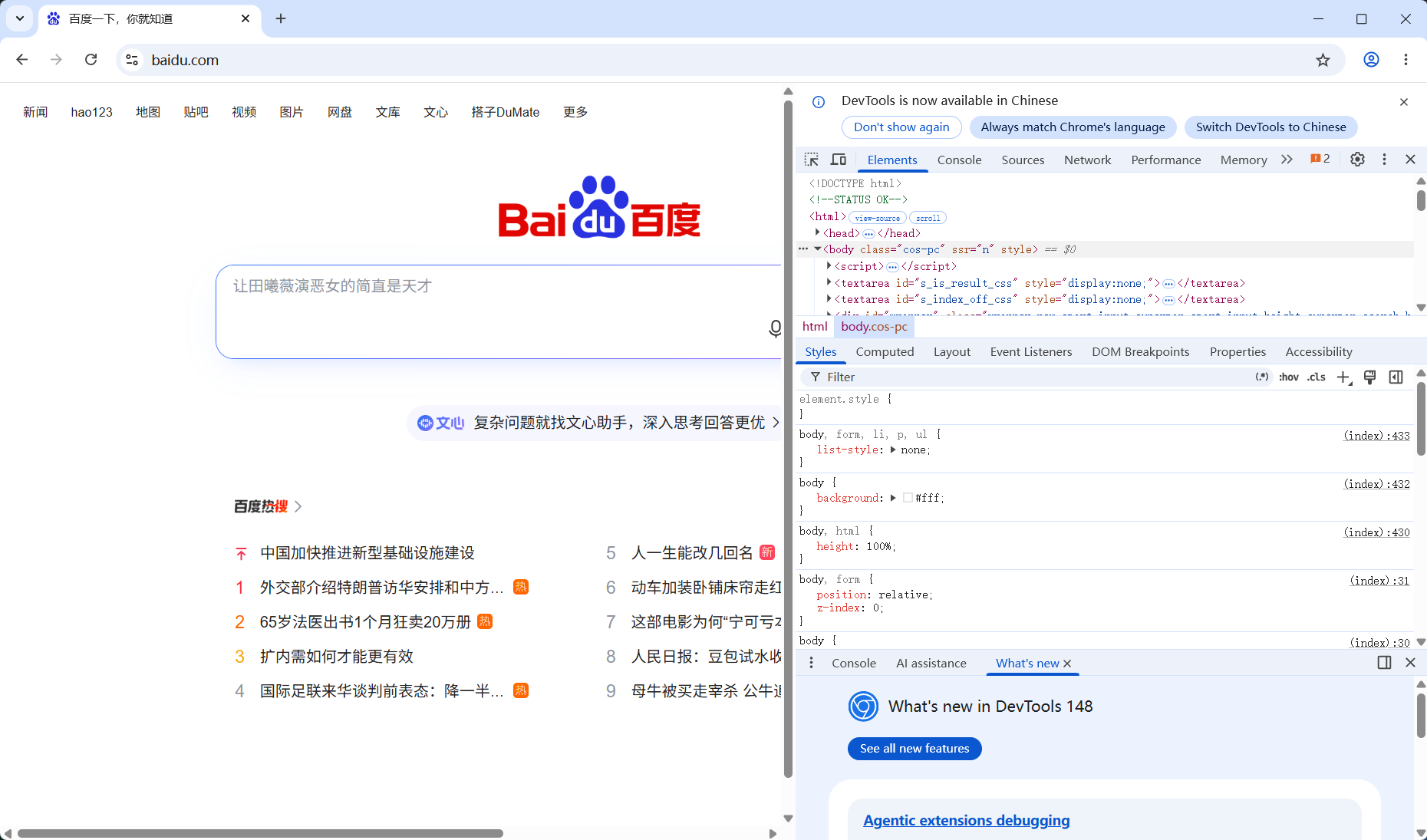
移动鼠标,点击网页上的百度一下,右侧源码会自动定位到对应代码行;
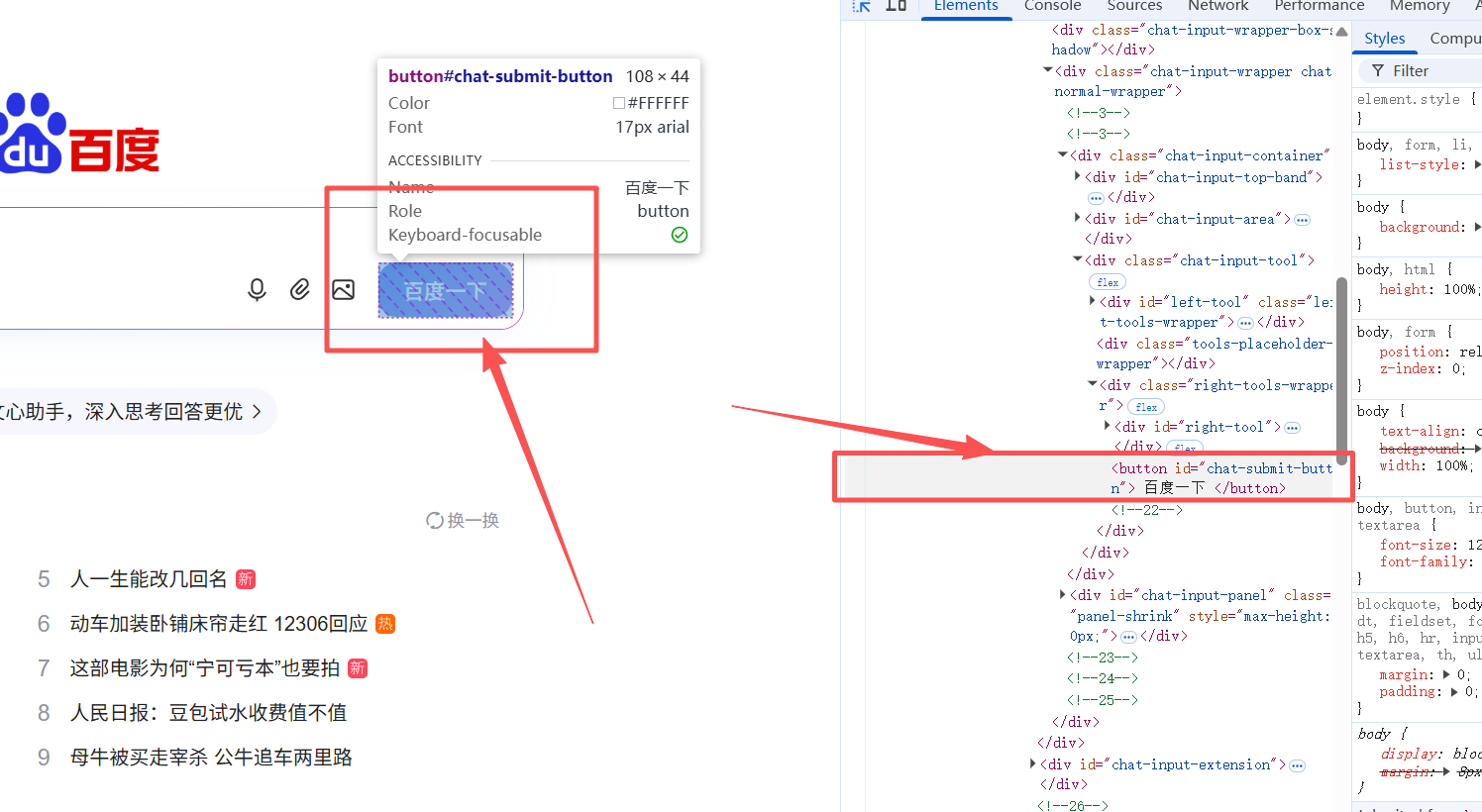
-
查看该行代码,找到id属性,复制 chat-submit-button
(鼠标上去的时候已经有提示了);
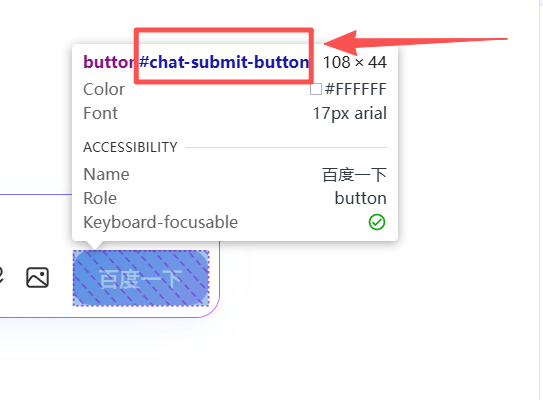
-
同理,点击百度一下按钮,复制最新id:chat-textarea;
-
免手打快捷方式:右键源码对应行 → Copy → Copy selector,直接复制可使用的选择器,杜绝手写出错。
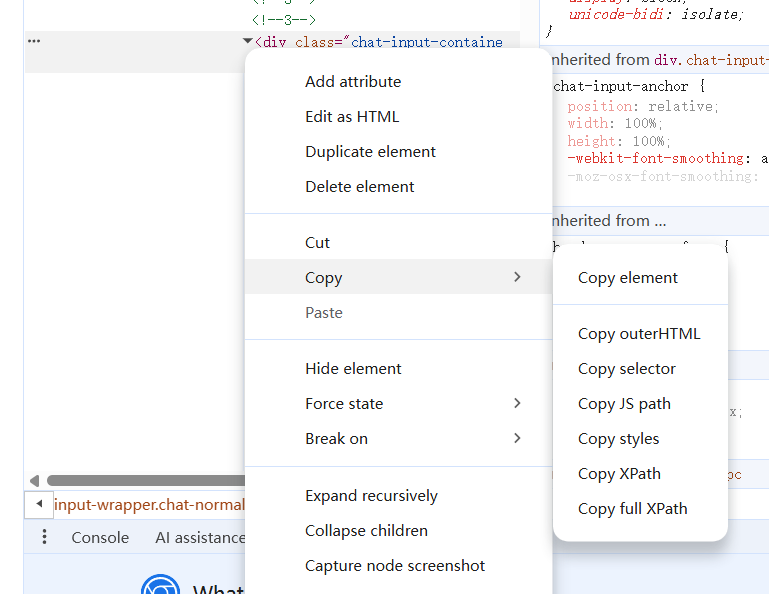
1.3 常见问题
问:复制XPath还是selector?选哪个?
答:百度这种简单网页优先CSS selector(#开头),简洁稳定、不易失效,复杂网页再用XPath。
1.4 小白通俗解释
把网页想象成一栋房子,每个按钮、输入框都是房间。开发者工具就是一把万能钥匙,让你打开房门,看清每个房间的门牌号(id属性)。别人给你的旧门牌号失效了,你自己用钥匙查最新门牌号,永远不会迷路。
二、 反爬伪装与ChromeOptions配置
2.1 概念
声明为反爬伪装的配置称为ChromeOptions伪装 ,用 options\.add\_argument\(\) 添加隐藏参数,用options\.add\_experimental\_option\(\) 关闭自动化提示,骗过网站反爬检测。
2.2 特性
-
\-\-disable\-blink\-features=AutomationControlled:禁用浏览器自动化专属特征; -
excludeSwitches:关闭浏览器上方"正在被自动化控制"提示条; -
伪装后浏览器检测不到webdriver特征,模拟真人手动操作;
-
百度、淘宝等大厂网站,不写伪装代码大概率拦截脚本。
2.3 常见疑问
问:修改完元素不做伪装,代码能跑吗?
答:不能。就算找到正确元素,百度识别到机器人脚本,会屏蔽点击、输入行为,直接报错不可交互。
2.4 通俗大白话解释
脚本就像机器人,直白站在百度面前会被保安拦下。伪装代码就是给机器人穿人类衣服、戴口罩,让百度后台识别不出来,以为是真人手动操作。
三、 元素定位与等待方式
3.1 概念
目前有两种等待方式:time.sleep()死板等待 、WebDriverWait显式等待。
sleep等待:固定休眠时间,无论网页是否已经加载完成,程序都必须等待指定时间后才继续执行。
python
# 打开百度
driver.get("https://www.baidu.com")
# sleep等待页面加载
time.sleep(3)显式等待:不是死等时间,而是持续检测目标元素是否加载完成,一旦满足条件立即继续执行。
python
# 打开百度
driver.get("https://www.baidu.com")
# 创建显式等待对象
wait = WebDriverWait(driver, 10)3.2 优缺点对比
- sleep等待:
优点
- 写法简单,容易理解
- 适合 Selenium 初学者
- 调试时方便观察页面变化
缺点
- 不智能,容易浪费时间
- 页面提前加载完成也会继续等待
- 页面加载慢时可能依然报错
- 稳定性较差
- 显式等待:
优点
- 更智能、更高效
- 页面加载完成立即执行
- 稳定性更高
- 更适合动态网页
- 自动化测试常用方案
缺点
- 写法比 sleep 更复杂
- 初学阶段理解成本略高
- 需要掌握等待条件
建议:新手写简单脚本可以少量用sleep,正式代码优先显式等待。
3.3 通俗大白话解释
sleep就像定闹钟,必须等闹钟响才能动;显式等待就像盯着快递,快递到了直接拿,不用傻傻等待。
四、 JavaScript注入交互
4.1 概念
JavaScript注入是一种绕过浏览器物理限制的手段,网页出现弹窗、遮罩、层级遮挡导致元素点不动时,直接修改DOM树,强制给元素赋值、触发点击。
注意:JS注入不要滥用,能正常点击就正常点击,解决特殊报错再使用。
4.2 核心代码
python
driver.execute_script("arguments[0].value = '搜索内容';", element) # 强制输入
driver.execute_script("arguments[0].click();", element) # 强制点击4.3 通俗大白话解释
按钮前面有透明玻璃挡住、手点不到,正常代码没法操作。JS注入就是穿墙术,无视遮挡,直接控制按钮完成输入和点击。
五、 简单示例:2026.5最新百度搜索自动测试代码(修正版)
本人亲自排查、修改、实测,替换最新百度元素 chat-textarea、#chat-submit-button,无报错可直接运行。
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from webdriver_manager.chrome import ChromeDriverManager
# 创建浏览器配置对象
options = webdriver.ChromeOptions()
# 关闭自动化检测
options.add_argument("--disable-blink-features=AutomationControlled")
# 创建浏览器驱动对象
driver = webdriver.Chrome(
service=Service(ChromeDriverManager().install()),
options=options
)
try:
# 浏览器最大化
driver.maximize_window()
# 打开百度
driver.get("https://www.baidu.com")
# 创建显式等待对象
wait = WebDriverWait(driver, 10)
print("正在定位输入框...")
# 定位搜索输入框
search_input = wait.until(
EC.presence_of_element_located(
(By.XPATH, "//input[@name='wd' or contains(@class, 's_ipt')]")
)
)
print("输入搜索内容...")
# 使用 JS 输入内容
driver.execute_script(
"arguments[0].value = '自动化测试脚本';",
search_input
)
# 触发输入事件
driver.execute_script(
"arguments[0].dispatchEvent(new Event('input', { bubbles: true }));",
search_input
)
time.sleep(1)
# 定位搜索按钮
search_btn = driver.find_element(
By.XPATH,
"//input[@value='百度一下'] | //button[text()='百度一下']"
)
print("点击搜索按钮...")
# 使用 JS 点击按钮
driver.execute_script(
"arguments[0].click();",
search_btn
)
print("搜索成功")
# 等待查看结果
time.sleep(5)
except Exception as e:
print(f"运行失败: {e}")
# 保存错误截图
driver.save_screenshot("fail_again.png")
finally:
# 关闭浏览器
driver.quit()📸截图位置3(收尾佐证):此处粘贴【代码运行成功、百度搜索结果页面截图】,对比开头报错,完整闭环,证明排查修改后的代码真实有效。
六、 补充内容:新手排错总结
6.1 排错万能流程(我的思考总结)
-
代码报错找不到元素:优先按 Ctrl+Shift+I,重新抓取最新属性,不要死抄旧代码;
-
代码找到元素但是点不动:添加Chrome伪装代码,绕过网站反爬;
-
页面加载卡顿:删掉sleep,换成显式等待,提升代码稳定性;
-
排查无头绪:添加截图代码 driver.save_screenshot("fail_again.png"),查看页面真实状态。
6.2 个人感悟
这次百度自动化测试代码编写踩坑,我最大的收获:代码是死的,网页是活的。教程与博客会滞后于网页更新,不要无脑复制粘贴使用。
自动化测试的本质不是背代码、抄代码,而是学会排查问题、看懂源码、灵活修改。哪怕以后再出新的版本,再次修改id,学会合理利用工具,发散性思考问题所在,逐一排查,相信所有问题都能迎刃而解。排查问题的能力,也是测试人员不可或缺的职业必备素养。