【集群模式】第一个MapReduce程序------WordCount_在3节点完全分布式Hadoop集群上运行MapReduce任务
前言
上一篇文章我们完成了Hadoop完全分布式集群的搭建,成功启动了HDFS和YARN。本文将在这个3节点集群上,运行我们的第一个MapReduce程序------WordCount 。本文采用集群模式,直接在Linux集群上通过命令行提交作业,让任务真正分布式运行在YARN上。
一、MapReduce核心原理回顾
一个MapReduce程序主要包括三部分:Mapper类 、Reducer类 、执行类(Driver)。
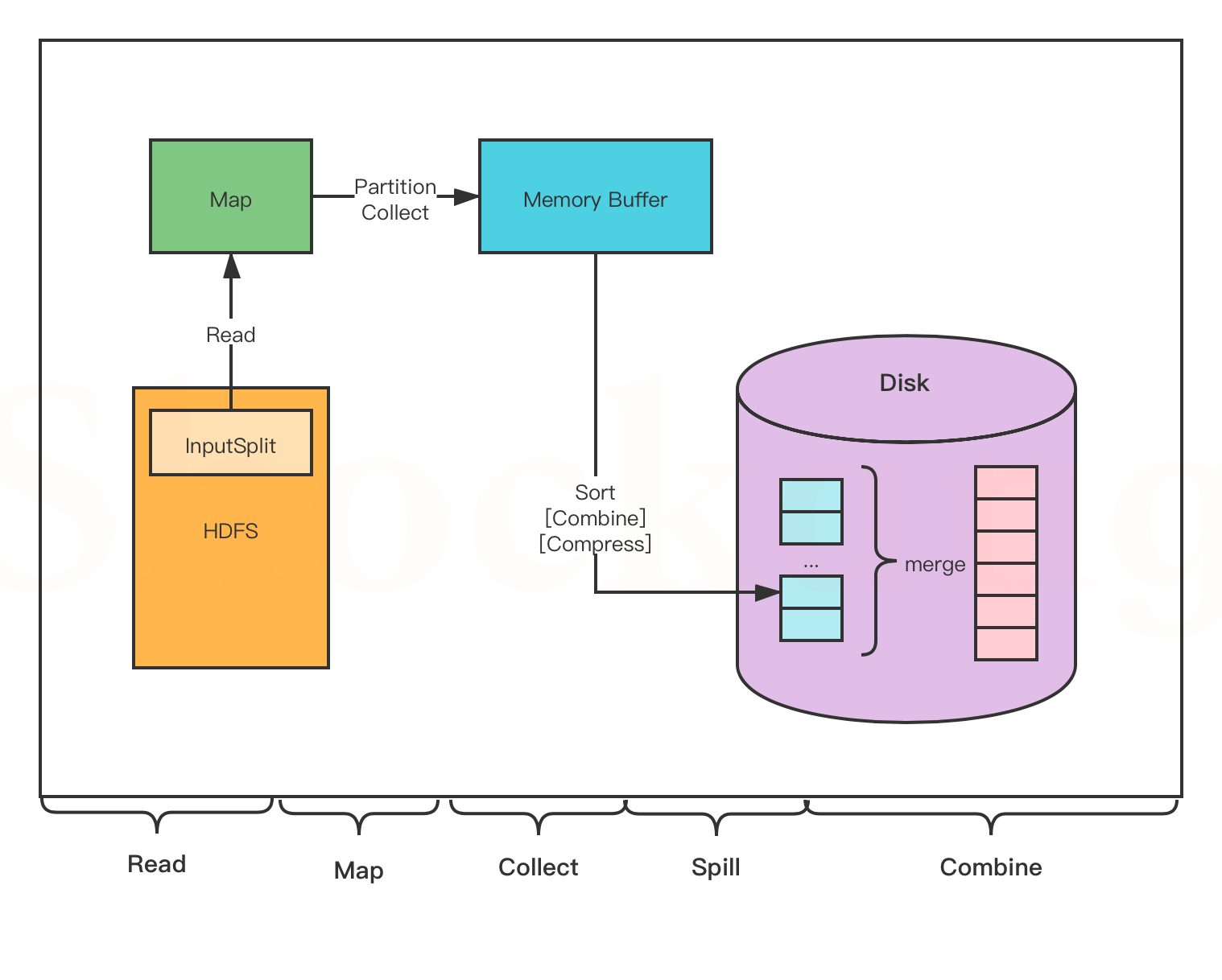
1.1 Map阶段
将输入文件的每一行按空格切分,提取单词,转为 <key, 1> 的形式:
- KEYIN:每行的偏移量(LongWritable)
- VALUEIN:当前行的文本内容(Text)
- KEYOUT:切分后的单词(Text)
- VALUEOUT:固定值 1(LongWritable)
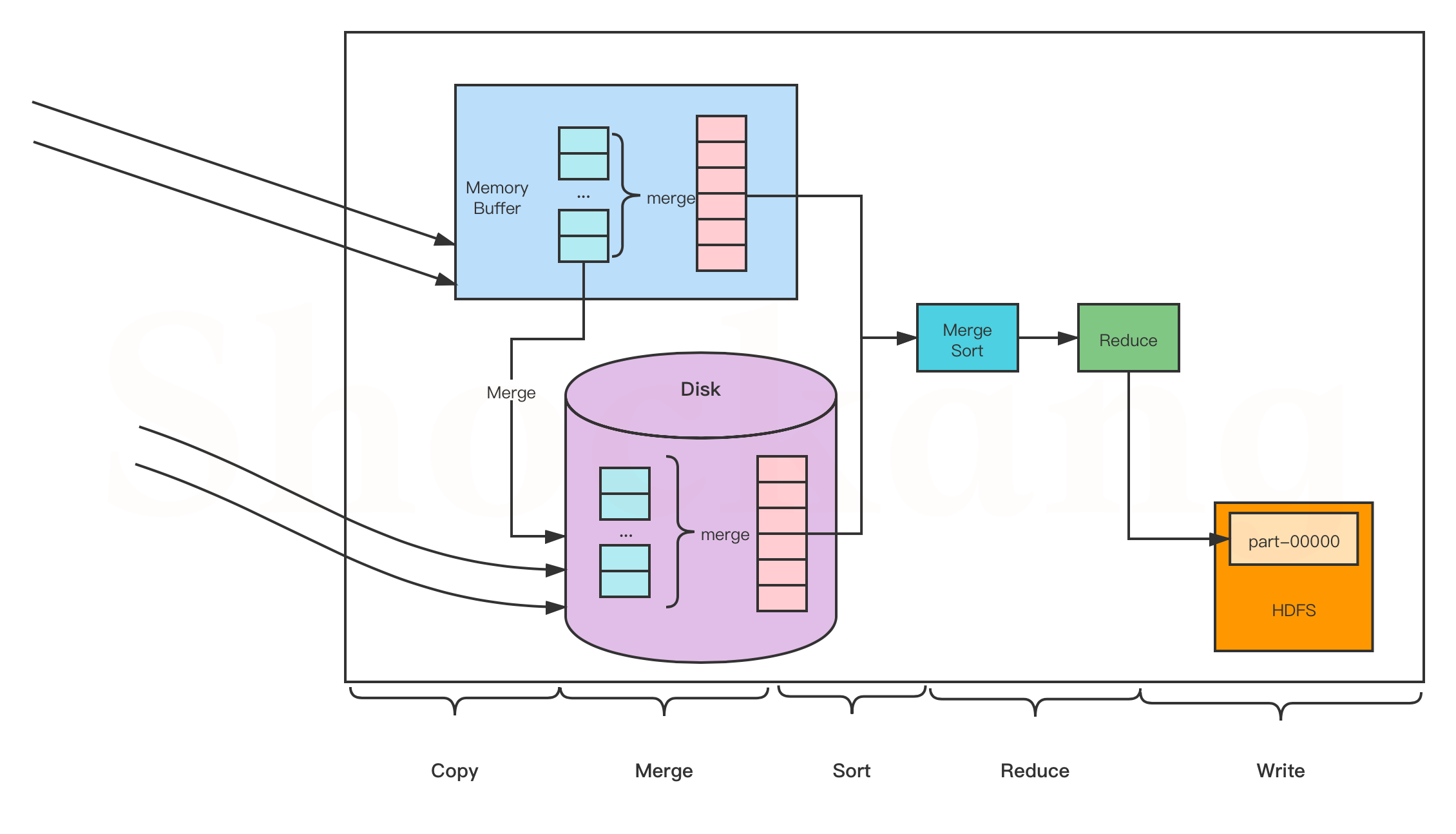
1.2 Reduce阶段
将Map阶段输出的相同key(单词)对应的value(1)进行累加,得到单词出现总次数:
- KEYIN:单词(Text)
- VALUEIN:该单词出现次数的集合(Iterable)
- KEYOUT:单词(Text)
- VALUEOUT:总次数(LongWritable)
二、集群环境确认
在运行程序前,先确认集群状态正常:
2.1 检查HDFS和YARN是否启动
bash
[atguigu@hadoop102 ~]$ jpsall
=============== hadoop102 ===============
1234 NameNode
1567 DataNode
1890 NodeManager
2345 JobHistoryServer
=============== hadoop103 ===============
2341 DataNode
2678 ResourceManager
2890 NodeManager
=============== hadoop104 ===============
3456 DataNode
3789 SecondaryNameNode
3901 NodeManager2.2 Web页面确认
| 组件 | 访问地址 | 状态 |
|---|---|---|
| HDFS NameNode | http://hadoop102:9870 | Live Nodes应为3 |
| YARN ResourceManager | http://hadoop103:8088 | Active Nodes应为3 |
| JobHistory | http://hadoop102:19888 | 正常访问 |
三、准备输入数据
3.1 创建HDFS输入目录
bash
[atguigu@hadoop102 ~]$ hadoop fs -mkdir -p /wordcount/input3.2 创建测试文件并上传
在本地创建测试文件:
bash
[atguigu@hadoop102 ~]$ vim word.txt输入内容(模拟大数据技术栈关键词):
hadoop hdfs yarn mapreduce
hadoop spark flink kafka
hive hbase sqoop flume
hadoop spark hive pig
java python scala sql
hadoop hdfs hive spark上传到HDFS:
bash
[atguigu@hadoop102 ~]$ hadoop fs -put word.txt /wordcount/input/3.3 验证上传成功
bash
[atguigu@hadoop102 ~]$ hadoop fs -ls /wordcount/input/
Found 1 items
-rw-r--r-- 3 atguigu supergroup 120 2024-04-25 09:00 /wordcount/input/word.txt
[atguigu@hadoop102 ~]$ hadoop fs -cat /wordcount/input/word.txt
hadoop hdfs yarn mapreduce
hadoop spark flink kafka
hive hbase sqoop flume
hadoop spark hive pig
java python scala sql
hadoop hdfs hive spark四、运行官方WordCount示例
Hadoop安装包中自带了WordCount示例jar包,我们先运行官方示例,验证集群是否正常。
4.1 执行命令
bash
[atguigu@hadoop102 ~]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wordcount/input /wordcount/output4.2 命令解析
| 部分 | 说明 |
|---|---|
hadoop jar |
提交jar包到Hadoop集群运行 |
/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar |
官方示例jar包路径 |
wordcount |
指定运行WordCount程序 |
/wordcount/input |
HDFS上的输入路径 |
/wordcount/output |
HDFS上的输出路径(必须不存在,否则报错) |
4.3 查看执行日志
执行过程中会输出Map和Reduce的进度:
2024-04-25 09:05:01 INFO mapreduce.Job: Running job: job_1714012800000_0001
2024-04-25 09:05:10 INFO mapreduce.Job: map 0% reduce 0%
2024-04-25 09:05:18 INFO mapreduce.Job: map 100% reduce 0%
2024-04-25 09:05:25 INFO mapreduce.Job: map 100% reduce 100%
2024-04-25 09:05:26 INFO mapreduce.Job: Job job_1714012800000_0001 completed successfully4.4 查看输出结果
bash
[atguigu@hadoop102 ~]$ hadoop fs -ls /wordcount/output/
Found 2 items
-rw-r--r-- 3 atguigu supergroup 0 2024-04-25 09:05 /wordcount/output/_SUCCESS
-rw-r--r-- 3 atguigu supergroup 102 2024-04-25 09:05 /wordcount/output/part-r-00000查看统计结果:
bash
[atguigu@hadoop102 ~]$ hadoop fs -cat /wordcount/output/part-r-00000
flink 1
flume 1
hadoop 4
hbase 1
hdfs 2
hive 3
java 1
kafka 1
mapreduce 1
pig 1
python 1
scala 1
spark 3
sqoop 1
sql 1
yarn 14.5 输出文件说明
| 文件名 | 说明 |
|---|---|
_SUCCESS |
任务执行成功的标志文件,内容为空 |
part-r-00000 |
Reduce任务的输出结果文件,r表示Reduce输出,00000表示第0个Reduce任务 |
如果有多个Reduce任务,会生成
part-r-00000、part-r-00001等多个文件。
五、自定义WordCount程序(Java开发)
官方示例只能按空格切分,实际业务中可能需要自定义分隔符、过滤停用词等。下面我们编写自定义的WordCount程序。
5.1 开发环境准备
在hadoop102上安装Maven(或直接使用IDEA开发后上传jar包):
bash
[atguigu@hadoop102 ~]$ sudo yum install -y maven5.2 创建Maven项目
bash
[atguigu@hadoop102 ~]$ mkdir -p ~/projects/wordcount
[atguigu@hadoop102 ~]$ cd ~/projects/wordcount创建 pom.xml:
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu</groupId>
<artifactId>wordcount</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>3.1.3</hadoop.version>
</properties>
<dependencies>
<!-- Hadoop客户端依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- 单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- 日志 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 打包插件:将依赖一起打包 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>5.3 Hadoop序列化类型说明
| Hadoop类型 | Java对应类型 | 说明 |
|---|---|---|
| Text | String | 可变长度文本 |
| LongWritable | long | 长整型 |
| IntWritable | int | 整型 |
| FloatWritable | float | 浮点型 |
| DoubleWritable | double | 双精度浮点型 |
| BooleanWritable | boolean | 布尔型 |
| NullWritable | null | 空值 |
| ArrayWritable | 数组 | 数组类型 |
| MapWritable | Map | Map类型 |
5.4 编写Mapper类
创建目录结构:
bash
[atguigu@hadoop102 wordcount]$ mkdir -p src/main/java/com/atguigu/mapreduce创建 WordCountMapper.java:
java
package com.atguigu.mapreduce;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
import java.io.IOException;
/**
* WordCount Mapper类
*
* 输入: KEYIN=LongWritable(行偏移量) VALUEIN=Text(一行文本)
* 输出: KEYOUT=Text(单词) VALUEOUT=LongWritable(计数1)
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
// 复用对象,减少GC压力
private Text outKey = new Text();
private final static LongWritable outValue = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 获取一行数据
String line = value.toString();
// 使用Hadoop的StringUtils.split按空格切分(性能优于Java原生split)
// 支持多个空格、制表符等空白字符
String[] words = StringUtils.split(line, ' ');
// 遍历单词,输出 <单词, 1>
for (String word : words) {
// 过滤空字符串
if (word != null && !word.trim().isEmpty()) {
outKey.set(word.trim().toLowerCase()); // 转为小写,统一统计
context.write(outKey, outValue);
}
}
}
}5.5 编写Reducer类
创建 WordCountReducer.java:
java
package com.atguigu.mapreduce;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* WordCount Reducer类
*
* 输入: KEYIN=Text(单词) VALUEIN=Iterable<LongWritable>(计数集合)
* 输出: KEYOUT=Text(单词) VALUEOUT=LongWritable(总次数)
*/
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
private LongWritable outValue = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
// 累加单词出现次数
long sum = 0;
for (LongWritable value : values) {
sum += value.get();
}
outValue.set(sum);
context.write(key, outValue);
}
}5.6 编写Driver执行类
创建 WordCountDriver.java:
java
package com.atguigu.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* WordCount Driver类
* 配置并提交MapReduce作业
*/
public class WordCountDriver {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
// 参数校验:需要输入路径和输出路径
if (args.length != 2) {
System.err.println("Usage: WordCountDriver <input path> <output path>");
System.exit(-1);
}
// 1. 获取配置和Job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Custom WordCount");
// 2. 设置Jar包路径(集群运行必须)
job.setJarByClass(WordCountDriver.class);
// 3. 关联Mapper和Reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4. 设置Map输出KV类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 5. 设置最终输出KV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 6. 设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7. 提交作业并等待完成
boolean result = job.waitForCompletion(true);
// 8. 根据结果退出
System.exit(result ? 0 : 1);
}
}5.7 项目完整目录结构
wordcount/
├── pom.xml
└── src/
└── main/
└── java/
└── com/
└── atguigu/
└── mapreduce/
├── WordCountMapper.java
├── WordCountReducer.java
└── WordCountDriver.java5.8 编译打包
bash
[atguigu@hadoop102 wordcount]$ mvn clean package打包成功后,会在 target/ 目录生成 wordcount-1.0-SNAPSHOT.jar。
六、提交自定义程序到集群运行
6.1 准备新的输入数据
bash
# 删除之前的输出目录(Hadoop不允许输出目录已存在)
[atguigu@hadoop102 ~]$ hadoop fs -rm -r /wordcount/output
# 创建新的输入数据(包含大小写和多余空格,测试我们的自定义程序)
[atguigu@hadoop102 ~]$ vim word2.txt输入内容:
Hadoop HDFS YARN MapReduce
Hadoop Spark Flink
hadoop spark HIVE hive
Java java JAVA
Python scala SQL上传:
bash
[atguigu@hadoop102 ~]$ hadoop fs -put word2.txt /wordcount/input2/6.2 提交作业
bash
[atguigu@hadoop102 ~]$ hadoop jar ~/projects/wordcount/target/wordcount-1.0-SNAPSHOT.jar com.atguigu.mapreduce.WordCountDriver /wordcount/input2 /wordcount/output26.3 查看YARN上的作业
浏览器访问:http://hadoop103:8088
可以看到作业运行状态:
- Application Type: MAPREDUCE
- State: FINISHED
- FinalStatus: SUCCEEDED
6.4 查看输出结果
bash
[atguigu@hadoop102 ~]$ hadoop fs -cat /wordcount/output2/part-r-00000
flink 1
hadoop 3
hdfs 1
hive 2
java 3
mapreduce 1
python 1
scala 1
spark 2
sql 1
yarn 1可以看到:
- 所有单词已转为小写(
Java→java) - 多余空格已被过滤
- 统计结果正确
七、集群模式 vs 本地模式对比
| 对比项 | 本地模式(参考文章) | 集群模式(本文) |
|---|---|---|
| 运行环境 | Windows IDEA | Linux Hadoop集群 |
| 数据存储 | 本地文件系统 | HDFS分布式文件系统 |
| 计算资源 | 单机CPU/内存 | 多节点分布式计算 |
| 提交方式 | 右键运行main方法 | hadoop jar 命令提交 |
| YARN调度 | 不涉及 | ResourceManager统一调度 |
| 适用场景 | 本地开发调试 | 生产环境运行 |
| 扩展性 | 无 | 可扩展至数千节点 |
| 容错性 | 无 | 任务失败自动重试 |
八、常见问题与解决
8.1 输出目录已存在
org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://hadoop102:8020/wordcount/output already exists解决:Hadoop不允许输出目录已存在,先删除或更换输出路径:
bash
hadoop fs -rm -r /wordcount/output8.2 权限不足
org.apache.hadoop.security.AccessControlException: Permission denied: user=atguigu, access=WRITE, inode="/":root:supergroup:drwxr-xr-x解决 :在 core-site.xml 中配置静态用户:
xml
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>或在HDFS上创建用户目录并授权:
bash
hadoop fs -mkdir -p /user/atguigu
hadoop fs -chown atguigu:atguigu /user/atguigu8.3 Container被杀死
Container killed by the ApplicationMaster.
Container exited with a non-zero exit code 143.解决:通常是内存不足,增大任务内存配置:
bash
# 提交时指定内存
hadoop jar wordcount.jar com.atguigu.mapreduce.WordCountDriver \
-Dmapreduce.map.memory.mb=2048 \
-Dmapreduce.reduce.memory.mb=4096 \
/input /output8.4 数据倾斜
某些Reduce任务处理数据量远大于其他,导致整体延迟。
解决:
- 自定义Partitioner打散热点key
- 使用Combiner进行Map端预聚合
- 调整Reduce任务数:
job.setNumReduceTasks(10)
九、作业监控与日志查看
9.1 YARN Web UI查看
访问 http://hadoop103:8088,点击完成的作业ID,可以查看:
| 信息 | 说明 |
|---|---|
| Application Overview | 作业概览,包括启动时间、结束时间、运行状态 |
| ApplicationMaster | AM的日志链接 |
| Logs | 所有Container的日志聚合 |
| Map Tasks | Map任务列表及状态 |
| Reduce Tasks | Reduce任务列表及状态 |
9.2 命令行查看日志
bash
# 查看指定application的日志
yarn logs -applicationId application_1714012800000_0001
# 查看特定Container的日志
yarn logs -applicationId application_1714012800000_0001 -containerId container_xxx9.3 JobHistory查看历史作业
访问 http://hadoop102:19888/jobhistory
可以查看已完成的作业详情,包括:
- 作业配置参数
- 每个Map/Reduce任务的耗时
- 任务失败原因和重试记录
十、总结
本文在3节点完全分布式Hadoop集群上,完成了第一个MapReduce程序------WordCount的开发和运行:
| 步骤 | 内容 |
|---|---|
| 1 | 确认集群环境(HDFS + YARN正常运行) |
| 2 | 准备HDFS输入数据 |
| 3 | 运行官方WordCount示例验证集群 |
| 4 | 自定义Java程序(Mapper + Reducer + Driver) |
| 5 | Maven打包并提交到集群运行 |
| 6 | 查看YARN作业监控和输出结果 |
关键点:
- 集群模式下数据必须存储在HDFS上
- 输出目录不能提前存在
job.setJarByClass()是集群运行的关键- YARN Web UI是排查问题的重要工具
如果这篇文章对你有帮助,欢迎点赞、收藏、评论三连!有问题可以在评论区留言交流~