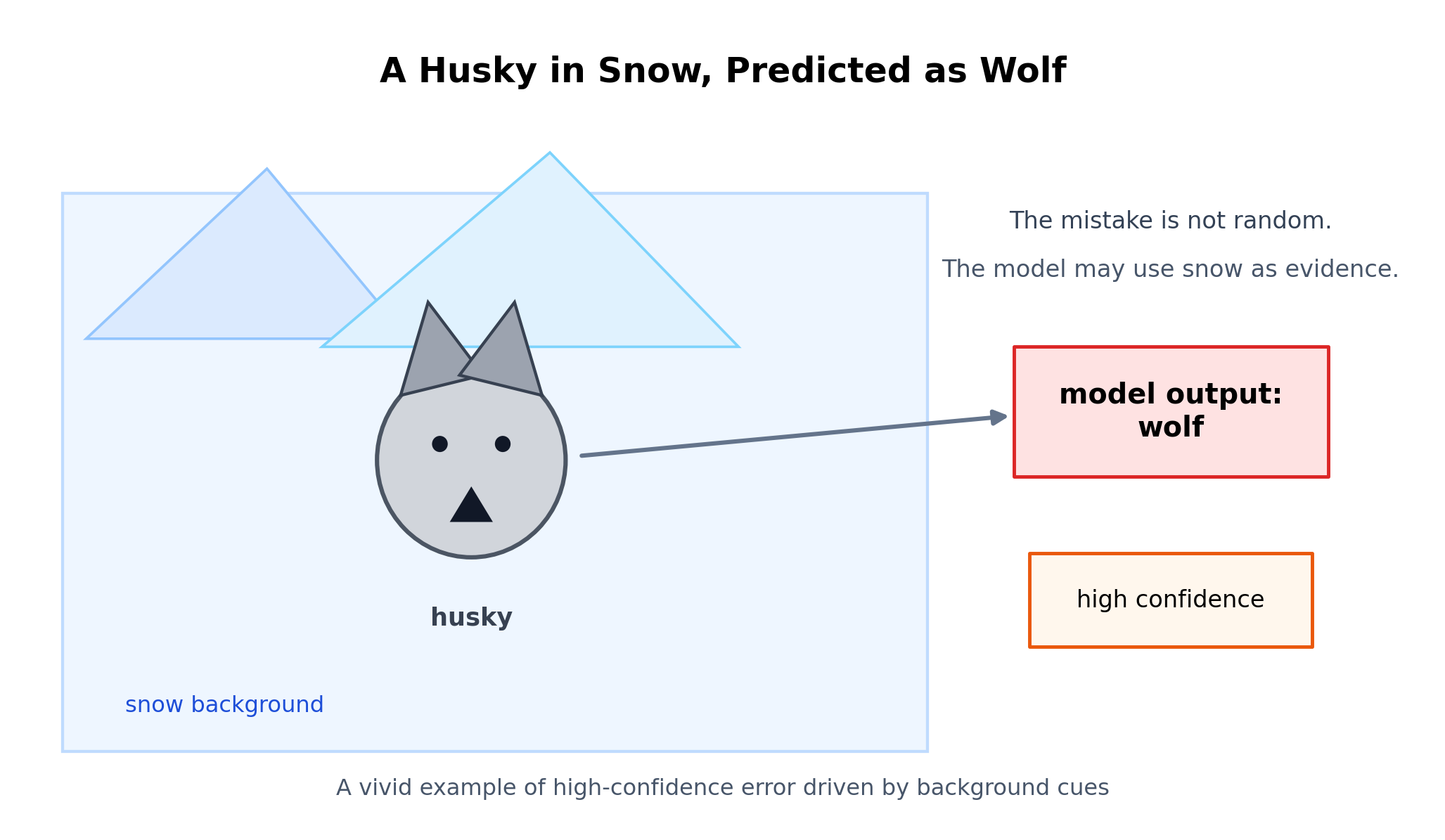
有个很经典的例子:雪地里一只哈士奇,模型却把它认成了狼。更麻烦的是,它还属于高置信误判。很多时候,问题不在模型没见过哈士奇,而在训练数据里"狼"和"雪地"总是一起出现。模型最后记住的,可能不是狼本身的特征,而是"雪地 + 灰白毛色"这类组合信号。
图 0:雪地中的哈士奇
这类误判往往来自背景被当成强证据,因此模型会在视觉上相似但语义不同的样本上给出高置信错误。

灵魂画手有没有(bushi,狗头保命
分类任务的核心不是贴标签,而是选择证据。关键问题包括:
- 模型依据什么打分。
- 决策规则如何把分数变成标签。
- 指标如何评价结果。
- 数据偏差如何扭曲上述三步。
先把分类在预测什么说清
分类的基本形式是:给定输入样本 xxx,在有限类别集合 C\mathcal{C}C 中输出预测标签 y^\hat{y}y^。输入可以是图像、文本或结构化记录;任务骨架不变,都是根据输入模式在候选解释之间做判别。
常见误解是:模型先"认出对象",再"贴上名字"。实际过程是先学习区分类别的判别模式,再把这些模式映射到标签。分类可以视为有限候选中的排序问题。排序稳定,系统才稳定;排序被伪特征污染,系统就会在新场景里失效。
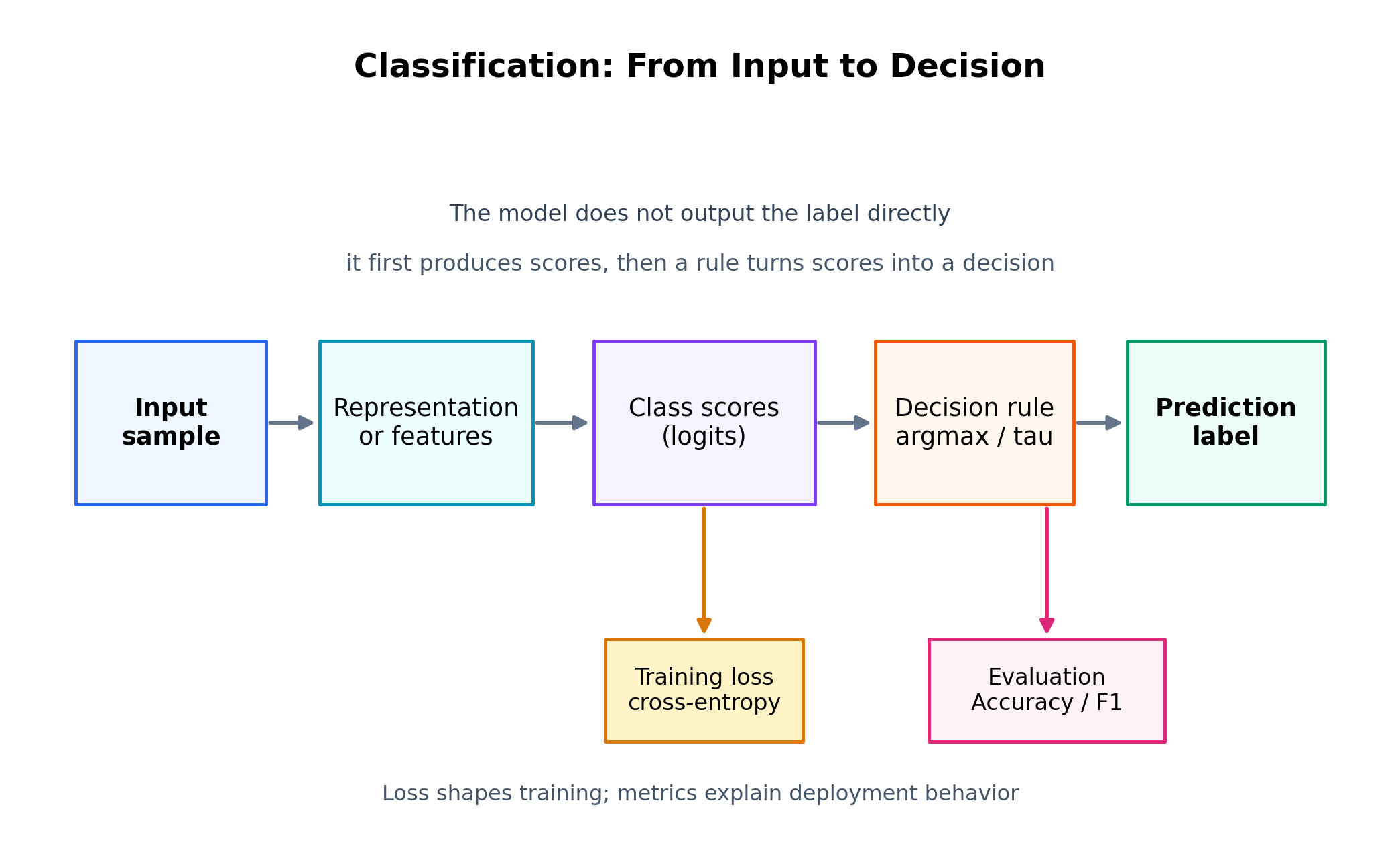
模型先输出分数,再把分数变成决策
大多数分类模型不会直接输出类名,而是先输出一组类别分数 z1,z2,...,zCz_1, z_2, \dots, z_Cz1,z2,...,zC,也就是 logits。这些分数不是概率,但决定后续概率和最终决策。
- 多分类 :通常先用
softmax转成概率,再用argmax选最高类。 - 二分类 / 多标签 :通常先用
sigmoid压到0到1,再用阈值 τ\tauτ 做判断。
因此,最终预测不是单一步骤,而是分数比较 + 决策规则的联合结果。
图 1:分类任务从输入到决策的最小链路。
输入不会直接变成标签,模型先形成表示,再产生类别分数,最后由
argmax或阈值生成预测;训练损失和评估指标分别作用于不同环节。
决策边界决定模型怎么分
分类模型在输入空间里画边界。样本落在哪一侧,预测就属于哪一类。训练过程不断调整这条边界;评估阶段的大量失败样本,则集中在边界附近。噪声、遮挡、角度变化足以把样本推到另一侧。
因此,分类分析不能只看最终标签,还要看边界是否稳定 、边界依据是否可靠。
把几类常见分类问题分开
"分类"不是单一设定。任务定义不清,后续的输出层、损失函数、阈值和指标都会错位。
二分类、多分类、多标签不是一回事
- 二分类:判断目标是否成立。典型场景是垃圾邮件过滤、欺诈识别、医学初筛。
- 多分类 :多个候选类别中只选一个。常见规则是
argmax。 - 多标签:多个标签可同时成立,每个标签都要单独判断。
把这三类任务混为一谈,通常带来两个后果:
- 输出层设置错误,训练目标偏移。
- 评估口径错误,离线结果和线上行为失配。
类别不平衡会改变问题重点
很多现实任务的难点不在类别数量,而在类别分布。医学筛查、欺诈检测、风控审核都存在显著长尾。此时"全判正常"也可能得到不低的 Accuracy,但系统没有价值。
类别不平衡会同时影响:
- 训练:少数类容易被主流模式淹没。
- 评估:平均指标容易掩盖失败。
- 部署:阈值需要服从错误代价,而不是服从默认设置。
因此,这类问题通常需要同时处理三件事:
- 训练时重加权或重采样。
- 评估时拆开看类别指标。
- 部署时按代价调阈值。
损失函数和评价指标不是一回事
训练目标回答"参数如何更新",评估目标回答"系统是否可用"。两者相关,但不能互换。
cross-entropy 在训练时负责什么
分类最常见的训练损失是 cross-entropy:
L=−logp(y∣x) \mathcal{L} = - \log p(y \mid x) L=−logp(y∣x)
真实类别概率越高,损失越小;真实类别概率越低,损失越大。训练反复执行这件事,作用就是抬高正确类分数,压低错误类分数。
cross-entropy 优化的是训练区分能力,不直接保证部署效果。部署效果还取决于指标、阈值和数据分布。
准确率为什么经常不够用
Accuracy 只回答"整体判对多少"。类别均衡、错误代价接近时,它足够有用;这两个条件一旦不成立,它就会失真。
医学初筛是典型反例:
- 把健康样本判成有风险,会增加复检、穿刺或额外影像检查。
- 把有风险样本判成健康,会直接漏掉需要继续检查的患者。
因此,评价不能只看总体对错,必须拆开看错误结构。
| 指标 | 关注的问题 | 适合用来判断什么 |
|---|---|---|
Accuracy |
整体判对比例 | 类别较均衡时的总体效果 |
Precision |
判为正类的样本里,有多少是真的正类 | 误报是否过多 |
Recall |
真实正类里,有多少被成功找出 | 漏检是否严重 |
F1 |
Precision 和 Recall 的综合平衡 |
两种风险都需要兼顾时 |
用癌症初筛把二分类指标算一遍
假设有 1000 名患者做初筛,其中 50 人真的患癌,950 人没有患癌。模型筛查后,给出下面的结果:
40名患者被判为高风险,而且确实患癌。这是TP。40名患者被判为高风险,但实际上没有患癌。这是FP。10名患者实际上患癌,但模型没有报出来。这是FN。910名患者没有患癌,模型也没有报错。这是TN。
这时四个常见指标可以直接算:
-
Accuracy
$$
\dfrac{TP + TN}{TP + FP + FN + TN}
\dfrac{40 + 910}{1000}
95%
$$
- 高准确率并不等于低漏检率。
-
Precision
$$
\dfrac{TP}{TP + FP}
\dfrac{40}{40 + 40}
50%
$$
- 模型每报出
2个高风险患者,只有1个真的患癌。
- 模型每报出
-
Recall
$$
\dfrac{TP}{TP + FN}
\dfrac{40}{40 + 10}
80%
$$
- 真实患癌的
50人里,模型找出了40人,漏掉了10人。
- 真实患癌的
-
F1
$$
2 \cdot \dfrac{Precision \cdot Recall}{Precision + Recall}
2 \cdot \dfrac{0.5 \cdot 0.8}{0.5 + 0.8}
\approx
0.615$$
- 该指标同时压缩误报与漏检。
准确率达到 95%,但模型仍漏掉了 20% 的癌症患者,而且高风险预测中有一半是误报。 二分类评估不能只盯 Accuracy。
进一步定位时,混淆矩阵更直接。它把 TP、FP、TN、FN 展开,显示系统究竟是报多了 还是漏多了。
图 2:混淆矩阵把"错了多少"拆成"错在什么地方"。
TP / FP / TN / FN对应不同错误结构;误报和漏报一旦分开,Precision、Recall以及错误代价的差异就会立刻显现。
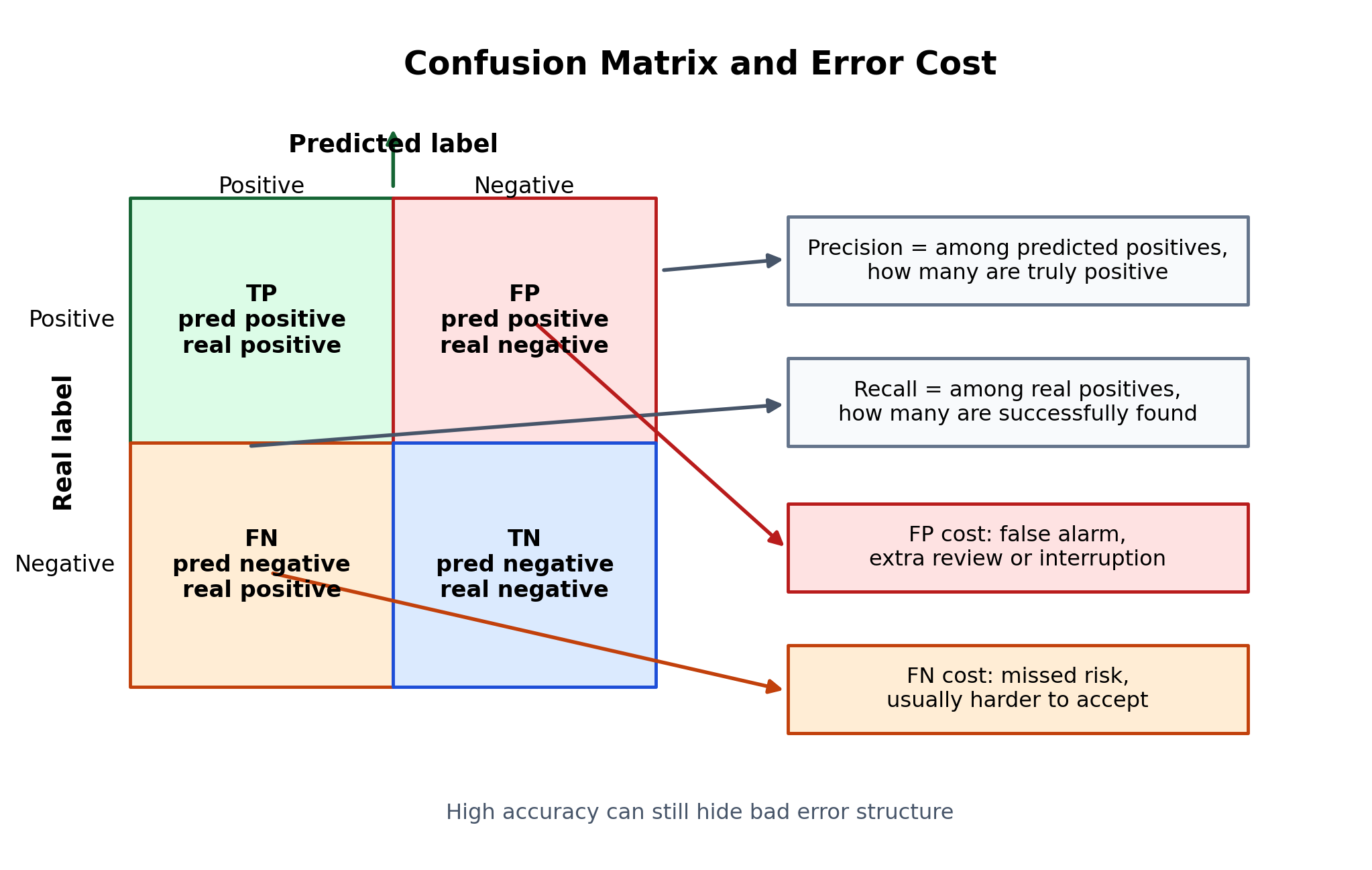
沿用上面的癌症初筛结果,混淆矩阵实际上在回答两个不同问题:
-
Precision 在看什么
- 所有被模型判成"高风险"的人里,有多少真的需要进一步检查。
40 / 80 = 50%。- 该值过低会带来大量误报负担。
-
Recall 在看什么
- 所有真实患癌的人里,有多少被模型成功找出来。
40 / 50 = 80%。- 该值过低会漏掉本该尽快处理的患者。
同样一套结果,Precision 关注的是"报出来的人准不准",Recall 关注的是"该找出来的人漏了多少"。这两个问题不是一回事,所以不能用一个指标替代另一个指标。
多分类指标不能只看一个总准确率
多分类任务里,Accuracy 同样容易掩盖结构性问题。假设有一个三分类胸片系统,要区分:
- 正常
- 肺炎
- 肿瘤疑似
测试集共有 100 张片子:
- 正常
50张,其中45张判对,3张被判成肺炎,2张被判成肿瘤疑似。 - 肺炎
30张,其中21张判对,6张被判成正常,3张被判成肿瘤疑似。 - 肿瘤疑似
20张,其中12张判对,3张被判成正常,5张被判成肺炎。
这时总体准确率是:
$$
\dfrac{45 + 21 + 12}{100}
78%
`78%` 看上去不算差,但把每一类拆开后,结论完全不同: * **正常类召回率** * 4550=90% \\dfrac{45}{50} = 90\\% 5045=90% * **肺炎类召回率** * 2130=70% \\dfrac{21}{30} = 70\\% 3021=70% * **肿瘤疑似类召回率** * 1220=60% \\dfrac{12}{20} = 60\\% 2012=60% 这说明模型对"正常"较稳,对"肿瘤疑似"明显偏弱。若只看总准确率,关键薄弱类会被平均值淹没。 因此,多分类里通常至少要补两层观察: * **每一类的召回率或精确率**:看模型是否系统性忽略某一类。 * **宏平均指标**:给每个类别相同权重,避免头部类别把整体结果抬高。 三类召回率的宏平均是: ##
\dfrac{90% + 70% + 60%}{3}
73.3%
该值比总体 `Accuracy = 78%` 更能反映类别间是否均衡。 ### 用一次前向传播把分数、概率、损失串起来 上面的指标属于评估阶段。单个样本在网络里的前向传播可以写成下面这样。假设某个患者样本经过神经网络后,最后一层输出一个二分类 `logit`: z=1.39 z = 1.39 z=1.39 把它送进 `sigmoid`: p=σ(z)=11+e−1.39≈0.80 p = \\sigma(z) = \\dfrac{1}{1 + e\^{-1.39}} \\approx 0.80 p=σ(z)=1+e−1.391≈0.80 `0.80` 表示:**模型认为该患者属于"阳性 / 高风险"这一类的概率约为 `80%`。** 同一个输出会同时影响三件事: * **预测阶段** * 如果阈值 τ=0.5\\tau = 0.5τ=0.5,那么 `0.80 > 0.5`,模型判为阳性。 * 如果阈值 τ=0.9\\tau = 0.9τ=0.9,那么 `0.80 < 0.9`,同一个样本又会被判为阴性。 * **损失阶段** * ## 如果患者真实患癌,y=1y = 1y=1,二分类交叉熵是:
\\mathcal{L}
* \\log 0.80
\\approx
0.223
$$
损失较小,说明模型这次判断和真实标签一致。## 如果患者真实健康,y=0y = 0y=0,损失变成:
$$
\\mathcal{L}
* \\log (1 - 0.80)
=
* \\log 0.20
\\approx
1.609
$$
损失明显更大,训练会推动模型压低该样本的阳性分数。-
参数更新方向
- 若真实标签是阳性,梯度会推动
logit继续上升。 - 若真实标签是阴性,梯度会推动
logit下降。
- 若真实标签是阳性,梯度会推动
这个单样本过程拆开了三件容易混淆的事:
- 概率是模型当前的置信度。
- 阈值决定最终标签。
- 损失决定参数如何更新。
阈值会改变系统表现
二分类和多标签任务里,很多系统没有天然唯一的决策点,阈值 τ\tauτ 直接决定结果结构。
- 阈值调高 :
Precision往往上升,Recall往往下降。 - 阈值调低 :
Recall往往上升,误报通常增加。
图 4:阈值变化会把
Precision和Recall推向不同方向。阈值越低,系统越愿意把样本判为正类,因此通常召回率更高,但误报也更多;阈值越高,系统越谨慎,精确率通常提升,但漏检也会增加。
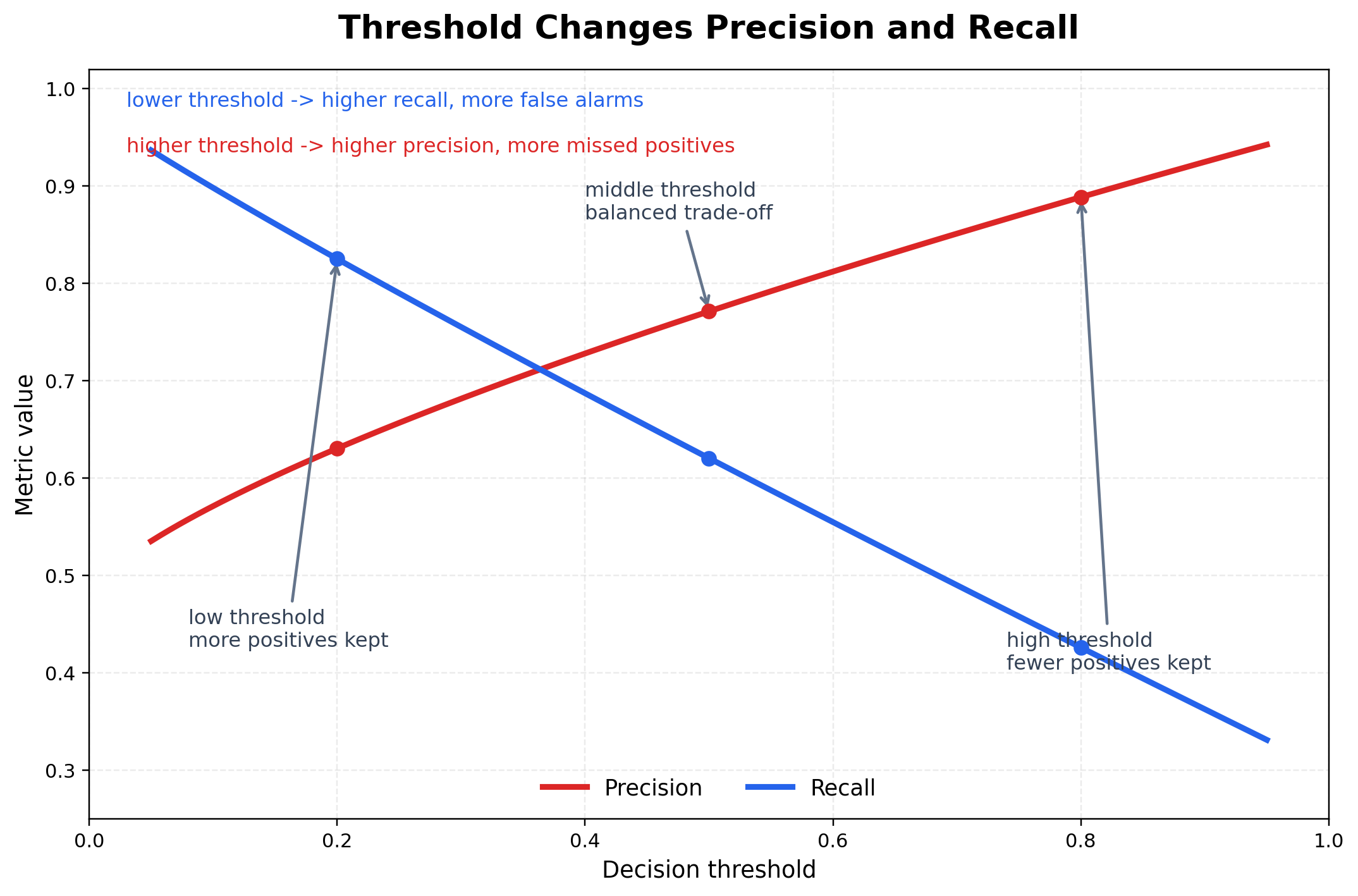
所以预测结果通常不是"模型算出的唯一答案",而是模型分数 + 人工规则 的联合产物。更稳妥的做法不是固定 0.5,而是先定义可接受错误范围,再反推阈值。
最后难在模型依据什么做判断
分类系统最危险的失败,不是随机错,而是依据错了还很自信。
伪特征会让模型学到错的依据
如果训练集中狼多出现在雪地里,狗多出现在草地或室内,模型就可能把"雪地"学成主要判别信号。这类信号在训练集里有效,在新场景里立即失效。
伪特征和标签共现,但不是稳定因果依据。它最麻烦的地方在于,训练集和验证集若共享同样偏差,离线分数仍可能很好看,直到部署环境变化才暴露。
图 3:高频共现背景会被压缩成分类捷径。
如果训练集长期把"狼"和"雪地"绑定、把"狗"和"草地"绑定,模型就可能把背景学成主特征;一旦遇到"雪地里的哈士奇",错误就会集中暴露。
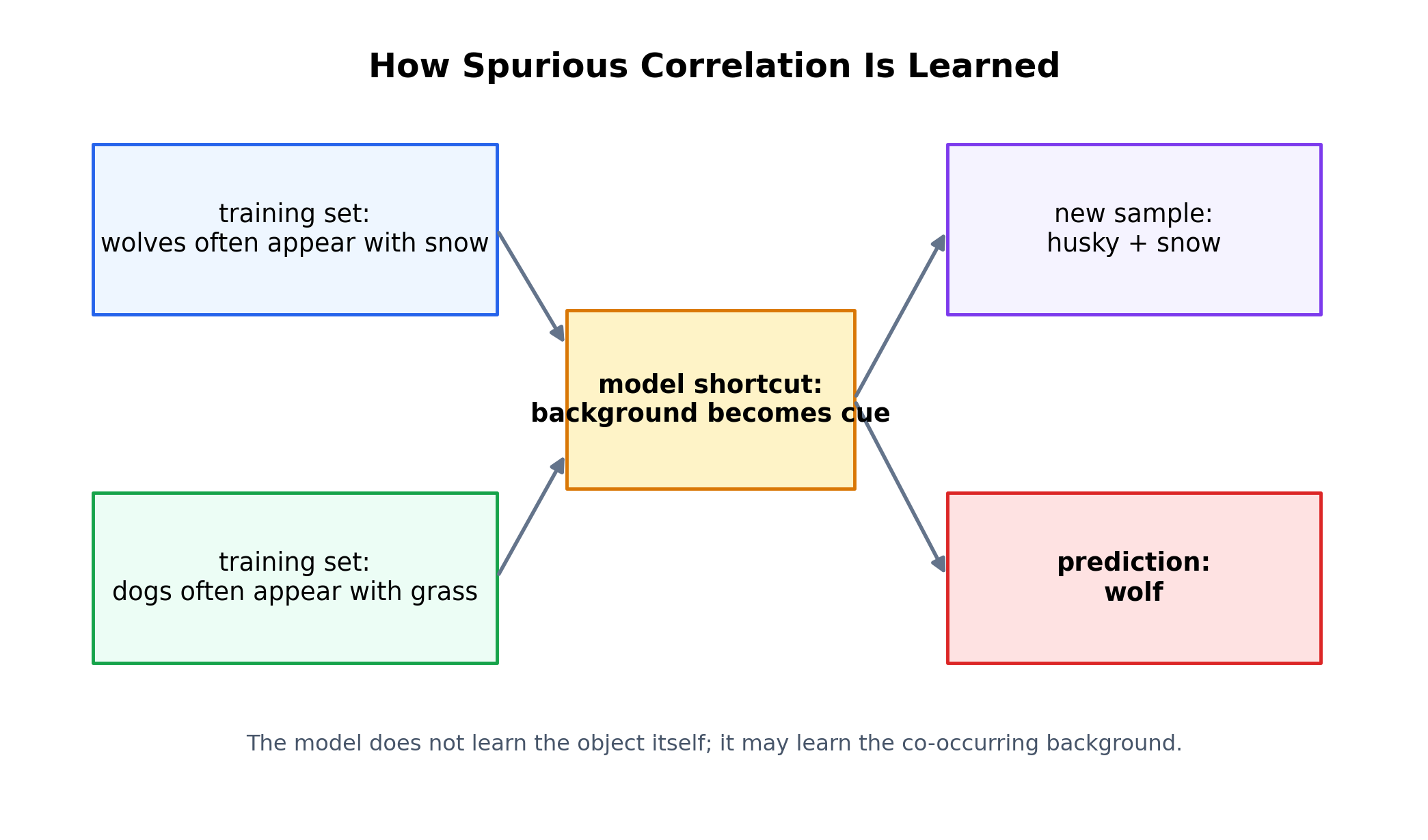
数据偏差会把整个问题带偏
很多分类失败,根源不在最后一层分类头,而在数据定义本身:
- 类别划分是否合理。
- 标签口径是否一致。
- 采样场景是否覆盖真实环境。
- 训练集和部署环境是否同分布。
同样的"猫狗分类",高清宠物摄影和夜间监控画面并不是同一个任务。标签口径冲突同样会扭曲边界。标注人员对同类样本给出不同标签时,模型学到的不是判别规律,而是标注噪声。
错误分析不能只看平均分
平均指标只能给总体判断,不能定位根因。更有效的检查通常包括:
- 哪些类别最容易混淆。
- 错误是否集中在特定背景、光照或设备条件下。
- 少数类是否被系统性忽略。
- 阈值变化后,误报和漏报如何迁移。
- 高置信错误样本是否共享同一类伪特征。
错误分析的目标不是写更长的复盘报告,而是产出可执行动作。最小闭环通常只有四步:
- 定位错误簇。
- 判断根因。
- 做最小改动。
- 在针对性切片上复测。
最后收束到判别依据
分类看上去简单,因为表面形式只是"输入一个样本,输出一个标签"。稳定的分类系统至少要同时处理六层问题:
- 定义类别和标签。
- 生成类别分数。
- 用规则把分数变成决策。
- 用合适指标衡量结果。
- 拆解错误结构。
- 回到数据分布检查判别依据。
前四层决定系统如何运行,后两层决定系统是否可靠。哈士奇误判成狼并不是一个孤立案例,而是整个问题的缩影:模型可能抓住了错误证据,指标可能掩盖了错误结构,阈值可能进一步放大了代价。
所以,分类任务要解决的不是"把名字贴上去",而是建立稳定、可迁移、可解释的判别依据。模型结构重要,但它不是唯一上限。问题定义、数据分布、决策规则三者失衡,再强的模型也会在真实环境里失真。