热点Key与大Value:Redis集群中的"定时炸弹"
作者 :Weisian
发布时间:2026年4月

直击痛点:
"双11零点,缓存系统突然崩溃,运营说是Redis扛不住,架构师一看:一个Key承载了90%的流量,单分片CPU飙到100%;另一个场景,用户信息缓存Value高达5MB,每次读取导致网络毛刺,GC频繁------这就是Redis集群里的两颗'定时炸弹'。"
在Redis集群架构中,热点Key 和大Value是两类最隐蔽、最具破坏性的问题:
- 热点Key :某个Key被超高并发访问,导致单个分片CPU爆满、连接数耗尽,单机扛不住直接宕机,引发连锁雪崩;(访问倾斜);
- 大Value :单个Value过大(超过10KB),网络带宽被占满、Redis主线程阻塞,所有请求排队超时,主从复制延迟;(存储倾斜);
- 面试高频问:"如何发现热点Key?""多级缓存怎么设计?""大Value如何拆分?""布隆过滤器能解决缓存穿透吗?"------答不上来=架构设计能力被质疑。

本文将从问题定位 切入,结合底层原理 、代码实战 、生产级方案 ,彻底讲透热点Key与大Value的发现与治理:
✅ 剖析热点Key的三大危害:分片倾斜、连接耗尽、缓存雪崩;
✅ 四种热点Key发现方案:Redis监控、客户端统计、Proxy层分析、预测预热;
✅ 多级缓存实战:Caffeine(本地缓存)+ Redis(分布式缓存),性能提升10倍;
✅ 热点Key解决方案:Key分裂、逻辑过期、布隆过滤器防穿透;
✅ 大Value四大危害:网络阻塞、慢查询、复制延迟、内存碎片;
✅ 大Value拆分实战:JSON拆分/Hash拆分/压缩存储;
✅ 生产级避坑指南:bigkeys命令慎用、UNLINK替代DEL、序列化选型;
✅ 高频面试题标准答案(直接背);
✅ 监控告警与自动化治理方案。
📌 核心一句话 :
热点Key是流量扎堆 ,像所有人同时挤一扇门,必须分门分流+本地缓存;大Value是货物超重,像货车拉巨无霸货物堵死高速,必须拆分打包+轻量化存储;两者都是Redis集群的定时炸弹,提前排查+合理优化才是保命关键。
📌 面试金句先记牢:
- 热点Key:大量请求集中访问同一个Key,命中Redis单个分片,导致流量倾斜,单机过载;
- 热点Key判定标准:单个Key的QPS超过分片总QPS的50% ,或单个Key的CPU占用超过分片CPU的60%;
- 大Value:单个Key对应的Value超过10KB即为大Value,会阻塞Redis主线程、耗尽网络带宽;
- 大Value判定标准:单个Value > 10KB (预警),> 100KB (高危),> 1MB(禁止,必须拆分);
- 热点Key最优解决方案:多级缓存(Caffeine本地缓存+Redis分布式缓存),90%的流量拦截在JVM本地;
- 热点Key分流:将Key拆分为
hot_key_01~hot_key_10,随机读取分散流量;- 大Value最优雅的拆分方式是Hash结构 :大JSON拆成多个Field,用
HSET/HGET按需读取;- 布隆过滤器 解决缓存穿透,逻辑过期 解决缓存击穿,Key分裂解决热点Key;
- 发现工具:Redis Info命令、客户端埋点、Redis Cluster Proxy、云厂商监控。
- 生产环境禁止使用
KEYS命令,禁止定期执行bigkeys扫描大Value。

一、热点Key:访问倾斜的"隐形杀手"
1.1 核心痛点:一个Key打挂一个分片
想象一个场景:双11零点,某爆款商品的库存信息缓存在Redis中,Key为product:stock:12345。瞬时百万用户涌入,全部请求落到同一个Redis分片上:
分片A(负责Key product:stock:12345):
- CPU使用率:95% → 100%
- 网络带宽:打满
- 连接数:占满整个连接池
- 结果:分片A假死,拖累整个集群
其他分片B、C、D:
- CPU使用率:5%
- 大部分请求正常
- 但由于分片A故障,集群整体不可用
这就是热点Key的威力:一个Key引发的"访问倾斜",导致单个分片崩溃,进而拖垮整个集群。
生活类比:小区只有一个出入口,早晚高峰期所有人挤同一个门,哪怕小区有十个门(分片),也只用一个。结果就是:出入口瘫痪,整个小区的人出不去。
1.2 热点Key的三大危害
| 危害类型 | 具体表现 | 严重程度 |
|---|---|---|
| 分片倾斜 | 单个分片CPU 100%,其他分片CPU <10%,集群吞吐量骤降90% | ⭐⭐⭐⭐⭐ |
| 连接耗尽 | 单个分片连接数被占满,新请求无法建立连接 | ⭐⭐⭐⭐ |
| 缓存雪崩诱因 | 热点Key过期瞬间,大量请求穿透到DB,DB被打挂 | ⭐⭐⭐⭐⭐ |

1.3 热点Key的典型场景
| 场景 | 热点Key示例 | 并发量级 |
|---|---|---|
| 电商秒杀 | product:stock:12345 |
百万级QPS |
| 微博热搜 | weibo:hot:list |
十万级QPS |
| 配置中心 | config:system:global |
万级QPS |
| 用户Token | user:token:uid_123 |
因用户行为突发 |

二、发现热点Key:三种常见方案
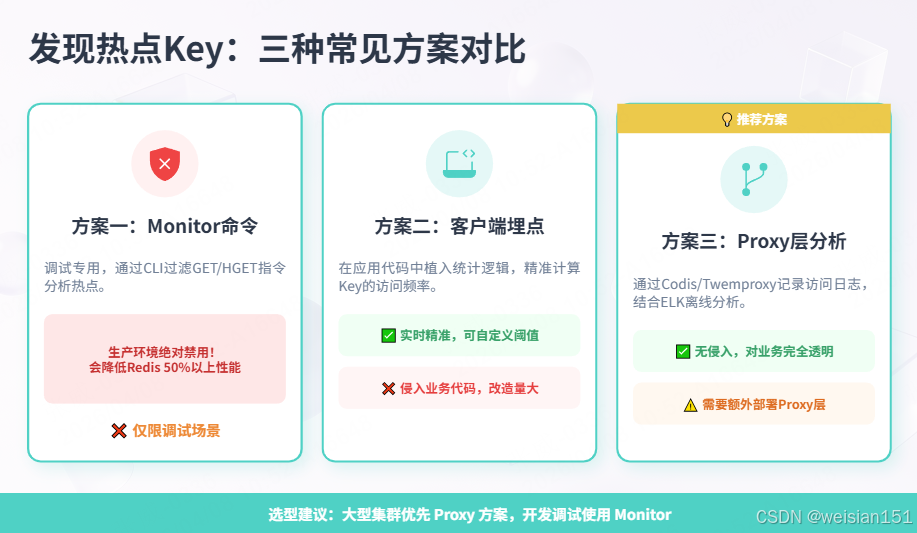
2.1 方案一:Redis Monitor命令(调试用,生产禁用)
bash
# 实时监控所有命令(会严重影响性能,禁止生产使用!)
redis-cli monitor | grep -E "GET|HGET" | awk '{print $4}' | sort | uniq -c | sort -rn | head -10警告 :MONITOR命令会降低Redis 50%以上的性能,生产环境绝对禁用!
2.2 方案二:客户端埋点统计
在应用层对Redis访问进行埋点,统计每个Key的访问频率:
java
/**
* Redis客户端埋点工具
*/
@Component
public class RedisAccessMonitor {
// 使用Caffeine缓存Key的访问计数(自动过期)
private final Cache<String, AtomicLong> accessCounter = Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(Duration.ofMinutes(1))
.build();
// 记录Key访问
public void recordAccess(String key) {
accessCounter.get(key, k -> new AtomicLong(0)).incrementAndGet();
}
// 获取热点Key列表(访问次数>阈值)
public List<String> getHotKeys(long threshold) {
return accessCounter.asMap().entrySet().stream()
.filter(entry -> entry.getValue().get() > threshold)
.map(Map.Entry::getKey)
.collect(Collectors.toList());
}
}
// 在RedisTemplate的拦截器中使用
@Component
public class RedisTemplateInterceptor {
@Autowired
private RedisAccessMonitor monitor;
public Object executeWithMonitor(String key, Supplier<Object> operation) {
monitor.recordAccess(key); // 埋点
return operation.get();
}
}优缺点:
- ✅ 实时、精准,可按业务自定义阈值
- ❌ 侵入业务代码,改造量大
- ❌ 高并发下统计本身有性能开销
2.3 方案三:Proxy层分析(推荐:Codis/Twemproxy/Redis Cluster Proxy)
如果使用了Redis Proxy(如Codis、Twemproxy),可以在Proxy层记录访问日志,通过ELK等日志系统分析热点Key:
log
# Proxy访问日志示例
2026-04-01 10:00:00 [GET] product:123 1ms
2026-04-01 10:00:00 [GET] product:123 1ms
2026-04-01 10:00:00 [GET] user:456 2ms
...通过Logstash聚合,Grafana展示热点Key排行榜。
yaml
# Codis Proxy配置(自动统计热点Key)
proxy:
hotkey:
enabled: true
threshold: 1000 # QPS阈值
log_path: /var/log/codis/hotkey.log优缺点:
- ✅ 无代码侵入,对业务透明
- ✅ 可实时统计所有经过Proxy的请求
- ❌ 需要额外部署Proxy层,增加架构复杂度
- ❌ Proxy本身可能成为瓶颈
三、治理热点Key:三大生产级方案
3.1 方案一:多级缓存(Caffeine + Redis)------ 最推荐
核心思想:JVM本地缓存(Caffeine)扛80%热点流量,Redis分布式缓存扛20%冷数据。

3.1.1 为什么选择Caffeine?
| 缓存库 | 特点 | 适用场景 |
|---|---|---|
| Caffeine | 基于Window TinyLFU算法,近似LRU但更高效,支持异步加载、自动刷新 | 首选,高性能本地缓存 |
| Guava Cache | 老牌缓存库,功能全面但性能略低于Caffeine | 兼容性要求高的老项目 |
| ConcurrentHashMap | 手动实现,无过期、无淘汰策略 | 简单场景,不推荐 |
3.1.2 多级缓存代码实战
java
/**
* 多级缓存管理器(Caffeine本地缓存 + Redis分布式缓存)
*/
@Component
public class MultiLevelCacheManager {
// 一级缓存:Caffeine本地缓存(性能极高,纳秒级)
private final Cache<String, Object> localCache;
// 二级缓存:Redis分布式缓存(毫秒级)
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// 布隆过滤器:防止缓存穿透
private final BloomFilter<String> bloomFilter;
public MultiLevelCacheManager() {
// 初始化Caffeine缓存:最大1万条,过期时间60秒
this.localCache = Caffeine.newBuilder()
.maximumSize(10000)
.expireAfterWrite(60, TimeUnit.SECONDS)
.recordStats() // 开启统计
.build();
// 初始化布隆过滤器(预计10万条数据,误判率1%)
this.bloomFilter = BloomFilter.create(
Funnels.stringFunnel(Charset.defaultCharset()),
100000,
0.01
);
}
/**
* 多级缓存查询
*/
public Object get(String key) {
// 1. 布隆过滤器过滤不存在Key(防穿透)
if (!bloomFilter.mightContain(key)) {
return null;
}
// 2. 查询一级缓存(Caffeine)
Object value = localCache.getIfPresent(key);
if (value != null) {
System.out.println("✅ 命中本地缓存,key=" + key);
return value;
}
// 3. 查询二级缓存(Redis)
value = redisTemplate.opsForValue().get(key);
if (value != null) {
System.out.println("✅ 命中Redis缓存,key=" + key);
// 回写到本地缓存
localCache.put(key, value);
return value;
}
// 4. 查询数据库(加互斥锁,防止击穿)
synchronized (key.intern()) {
// 双重检查
value = redisTemplate.opsForValue().get(key);
if (value != null) {
return value;
}
System.out.println("⚠️ 缓存未命中,查询数据库,key=" + key);
value = queryFromDatabase(key);
if (value != null) {
// 写入Redis(异步,避免阻塞)
redisTemplate.opsForValue().set(key, value, 300, TimeUnit.SECONDS);
// 写入本地缓存
localCache.put(key, value);
// 添加到布隆过滤器
bloomFilter.put(key);
}
return value;
}
}
private Object queryFromDatabase(String key) {
// 模拟数据库查询
try {
Thread.sleep(100); // 模拟DB耗时
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return "data_from_db_" + key;
}
// 获取本地缓存命中率(监控用)
public double getLocalHitRate() {
CacheStats stats = localCache.stats();
return stats.hitRate();
}
}
/**
* 测试代码
*/
@RestController
public class CacheController {
@Autowired
private MultiLevelCacheManager cacheManager;
@GetMapping("/product/{id}")
public Object getProduct(@PathVariable String id) {
String key = "product:" + id;
long start = System.nanoTime();
Object value = cacheManager.get(key);
long cost = (System.nanoTime() - start) / 1000; // 微秒
System.out.println("查询耗时:" + cost + "μs");
return value;
}
}性能对比:
| 缓存层级 | 查询耗时 | 命中率场景 | 适用场景 |
|---|---|---|---|
| 本地缓存(Caffeine) | 纳秒级(~50ns) | 80%热点流量 | 超高并发 |
| Redis缓存 | 毫秒级(~1ms) | 20%冷数据 | 分布式共享 |
| 数据库 | 十毫秒级(~50ms) | <1%穿透流量 | 兜底 |
核心优势:热点Key全部被本地缓存拦截,Redis压力降低80%以上。
3.2 方案二:Key拆分(hot_key_{1...N})------ 秒杀场景专用
核心思想 :
当热点Key的QPS极高(如百万级),即使多级缓存也扛不住时,需要使用Key拆分策略。将单个热点Key拆分成N个副本,随机读取,分散压力。
具体操作 :
(1)热点读场景:将一个热点Key拆分成N个子Key(如1:10),读取时随机选择一个子Key,写入时更新所有子Key。
(2)热点写场景:将一个热点数据如库存10000拆分成10个1000的子Key,下单随机读取1个进行扣减,单分片库存为0时在尝试其他分片扣减。

java
/**
* 热点Key分裂器(秒杀库存场景)
*/
@Component
public class HotKeySplitter {
private static final int SPLIT_COUNT = 10; // 拆分成10个副本
private final Random random = new Random();
@Autowired
private RedisTemplate<String, Integer> redisTemplate;
/**
* 初始化库存:将库存均匀分配到10个Key
*/
public void initStock(String originalKey, int totalStock) {
int perStock = totalStock / SPLIT_COUNT;
for (int i = 0; i < SPLIT_COUNT; i++) {
String splitKey = originalKey + "_" + i;
redisTemplate.opsForValue().set(splitKey, perStock);
}
// 余数放到第一个Key
int remainder = totalStock % SPLIT_COUNT;
redisTemplate.opsForValue().increment(originalKey + "_0", remainder);
}
/**
* 扣减库存:随机选择一个副本Key扣减
*/
public boolean decrStock(String originalKey) {
// 随机选择一个分片
int index = random.nextInt(SPLIT_COUNT);
String splitKey = originalKey + "_" + index;
Long stock = redisTemplate.opsForValue().decrement(splitKey);
if (stock != null && stock >= 0) {
System.out.println("扣减成功,分片=" + index + ",剩余库存=" + stock);
return true;
} else {
// 当前分片库存不足,尝试其他分片
for (int i = 0; i < SPLIT_COUNT; i++) {
if (i == index) continue;
splitKey = originalKey + "_" + i;
stock = redisTemplate.opsForValue().decrement(splitKey);
if (stock != null && stock >= 0) {
System.out.println("扣减成功(降级分片),分片=" + i + ",剩余库存=" + stock);
return true;
}
}
System.out.println("扣减失败,库存不足");
return false;
}
}
}执行效果:
# 10个分片Key各自承载10%流量
product:stock:12345_0 → 10%请求
product:stock:12345_1 → 10%请求
...
product:stock:12345_9 → 10%请求
单个分片压力从100%降低到10%,热点Key消失!3.3 方案三:永不过期 + 异步重建(解决缓存击穿)
核心思想 :
传统的缓存过期策略(TTL)在高并发下容易导致缓存击穿 (大量请求同时发现缓存过期,打到DB)。
永不过期策略 :缓存不设置物理过期时间,而是存储一个逻辑过期时间,由后台线程异步重建。

java
/**
* 永不过期缓存服务
*/
@Service
public class NeverExpireCacheService {
// 重建锁:防止多个线程同时重建
private final Map<String, ReentrantLock> rebuildLocks = new ConcurrentHashMap<>();
@Autowired
private RedisTemplate<String, Object> redisTemplate;
/**
* 获取缓存(核心方法)
*/
public Object get(String key) {
// 1. 从Redis获取包装对象
Map<String, Object> wrapper = (Map<String, Object>) redisTemplate.opsForValue().get(key);
if (wrapper == null) {
// 缓存完全不存在,同步重建
return rebuildCache(key);
}
// 2. 检查逻辑过期时间
Long expireTime = (Long) wrapper.get("expireTime");
if (System.currentTimeMillis() < expireTime) {
// 未过期,直接返回
return wrapper.get("data");
}
// 3. 已过期,尝试异步重建
CompletableFuture.runAsync(() -> {
try {
rebuildCache(key);
} catch (Exception e) {
log.error("Async rebuild cache failed for key: {}", key, e);
}
});
// 4. 返回旧数据(容忍短暂不一致)
return wrapper.get("data");
}
/**
* 重建缓存(加锁保证单线程重建)
*/
private Object rebuildCache(String key) {
ReentrantLock lock = rebuildLocks.computeIfAbsent(key, k -> new ReentrantLock());
try {
if (lock.tryLock(1, TimeUnit.SECONDS)) {
try {
// 双重检查:可能其他线程已经重建
Map<String, Object> current = (Map<String, Object>) redisTemplate.opsForValue().get(key);
if (current != null && System.currentTimeMillis() < (Long) current.get("expireTime")) {
return current.get("data");
}
// 从DB加载新数据
Object newData = loadFromDb(key);
if (newData != null) {
// 设置新的逻辑过期时间(5分钟后)
Map<String, Object> newWrapper = new HashMap<>();
newWrapper.put("data", newData);
newWrapper.put("expireTime", System.currentTimeMillis() + 5 * 60 * 1000);
redisTemplate.opsForValue().set(key, newWrapper);
}
return newData;
} finally {
lock.unlock();
}
} else {
// 获取锁失败,返回null或旧数据
return null;
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return null;
}
}
// 从DB加载数据
private Object loadFromDb(String key) {
// 实现DB加载逻辑
return null;
}
}核心优势:
- 避免击穿:即使缓存逻辑过期,也不会让大量请求打到DB;
- 平滑过渡:返回旧数据的同时,后台异步重建新数据;
- 高可用:获取重建锁失败时,直接返回旧数据或null,保证响应。
四、大Value:存储倾斜的"内存黑洞"
4.1 核心痛点:一个Value阻塞整个网络
典型案例:某电商系统将用户的完整订单历史(1000条记录)序列化成一个JSON,存入Redis,Value大小达到5MB。
json
{
"userId": 12345,
"orderList": [
{"orderId": 1, "items": [{"skuId": 1, "name": "商品1"}, ...]},
... // 共1000条订单
]
}后果:
- 每次读取这个Key,网络传输5MB,耗时50ms+;
- 序列化开销大:Java对象序列化/反序列化10MB数据需要几十毫秒;
- Redis处理单个大Value时,单线程模型导致其他请求排队;
- 主从复制延迟:5MB数据同步到从节点,网络带宽打满;
- 内存碎片:大Value频繁写入/删除导致内存碎片率飙升。
生活类比:快递站取包裹,别人的包裹是手机壳(小Value),你的包裹是一台冰箱(大Value)。快递员(Redis单线程)搬冰箱的时候,后面所有人排队等着------这就是大Value的阻塞效应。

4.2 大Value判定标准
| 级别 | Value大小 | 处理建议 |
|---|---|---|
| 正常 | < 10KB | 无需处理 |
| 预警 | 10KB ~ 100KB | 评估是否可拆分 |
| 高危 | 100KB ~ 1MB | 立即拆分 |
| 禁止 | > 1MB | 禁止写入,必须重构 |
4.3 大Value四大危害
| 危害类型 | 具体表现 | 严重程度 |
|---|---|---|
| 网络阻塞 | 单次读取5MB,千兆网卡只能支撑200 QPS | ⭐⭐⭐⭐⭐ |
| 慢查询 | Redis处理大Value耗时 > 100ms,阻塞其他请求 | ⭐⭐⭐⭐ |
| 主从延迟 | 大Value同步到从节点,导致主从延迟 > 1秒 | ⭐⭐⭐⭐ |
| 内存碎片 | 频繁写入/删除大Value,内存碎片率 > 1.5 | ⭐⭐⭐ |
4.4 发现大Value:三种方案
方案一:--bigkeys + MEMORY USAGE命令(低峰期执行)

bash
# 扫描大Key(会消耗CPU,低峰期执行)
redis-cli --bigkeys
# 输出示例:
# -------- summary -------
# Sampled 100000 keys in the keyspace!
# Total key length in bytes is 5000000 (avg len 50)
#
# Biggest string found 'user:order:12345' has 5242880 bytes
# Biggest list found 'product:list' has 100000 items
# Biggest hash found 'session:cache' has 50000 fields
# 查看单个Key的内存占用(字节)
redis-cli MEMORY USAGE user:order:12345
# 输出:5242880 (5MB)
# 批量检查(配合SCAN,避免阻塞)
redis-cli --scan --pattern "user:order:*" | xargs -L 1 redis-cli MEMORY USAGE方案二:RDB分析工具(推荐:redis-rdb-tools)
bash
# 安装工具
pip install redis-rdb-tools
# 分析RDB文件,找出大Key
rdb -c memory dump.rdb --bytes 102400 > large_keys.csv
# 输出CSV文件,按大小排序
cat large_keys.csv | sort -t, -k4 -rn | head -10方案三:客户端埋点(生产推荐)
在Redis工具类中埋点,统计Key访问次数+耗时+大小,定时上报监控平台。
方案四:无侵入Proxy层监控(集群首选)
使用Twemproxy/Redis Cluster Proxy,统一代理所有请求,自动统计:
- 热点Key:访问频次Top100;
- 大Value:大小超过阈值的Key;
- 流量倾斜:节点访问量分布。
方案五:云厂商监控(最简单)
阿里云/腾讯云Redis控制台直接提供:
- 热点Key自动告警;
- 大Value自动检测;
- 节点流量倾斜监控。
五、治理大Value:三大生产级方案
5.1 方案一:Hash结构拆分(最推荐)
核心思想:将大JSON拆分成Hash结构,按需读取字段,避免全量传输。

java
/**
* 大Value拆分:Hash结构存储用户订单
* 原方案:String存储整个JSON(5MB)
* 优化后:Hash存储,每个订单独立Field
*/
@Service
public class HashSplitService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
/**
* 存储用户订单(拆分为Hash)
*/
public void saveUserOrders(Long userId, List<Order> orders) {
String hashKey = "user:orders:" + userId;
Map<String, String> orderMap = new HashMap<>();
for (Order order : orders) {
// 每个订单作为独立的Field
String field = "order:" + order.getOrderId();
String value = JSON.toJSONString(order);
orderMap.put(field, value);
}
// 批量写入Hash(HSET)
redisTemplate.opsForHash().putAll(hashKey, orderMap);
System.out.println("存储完成,订单数=" + orders.size());
}
/**
* 查询单个订单(按需读取)
*/
public Order getSingleOrder(Long userId, Long orderId) {
String hashKey = "user:orders:" + userId;
String field = "order:" + orderId;
// HGET:只读取一个Field,传输量小
String json = (String) redisTemplate.opsForHash().get(hashKey, field);
if (json != null) {
System.out.println("读取单个订单,传输大小=" + json.length() + "字节");
return JSON.parseObject(json, Order.class);
}
return null;
}
/**
* 查询最近N条订单(分页读取)
*/
public List<Order> getRecentOrders(Long userId, int limit) {
String hashKey = "user:orders:" + userId;
// 获取所有Field(谨慎使用,仅当Field数量少时)
Map<Object, Object> entries = redisTemplate.opsForHash().entries(hashKey);
return entries.values().stream()
.map(v -> JSON.parseObject((String) v, Order.class))
.sorted((a, b) -> b.getCreateTime().compareTo(a.getCreateTime()))
.limit(limit)
.collect(Collectors.toList());
}
}性能对比:
| 存储方式 | Value大小 | 网络传输(单次) | QPS上限 |
|---|---|---|---|
| String大JSON | 5MB | 5MB | 200 |
| Hash拆分 | 每个Field 5KB | 5KB | 20000 |
5.2 方案二:压缩存储(GZIP/Snappy)
核心思想:对Value进行压缩,减少网络传输和内存占用。

java
/**
* 压缩存储工具类
*/
@Component
public class CompressedCacheManager {
@Autowired
private RedisTemplate<String, byte[]> redisTemplate;
/**
* GZIP压缩存储(压缩率50%-80%)
*/
public void setWithGzip(String key, Object value) throws IOException {
String json = JSON.toJSONString(value);
byte[] compressed = gzipCompress(json.getBytes(StandardCharsets.UTF_8));
System.out.println("压缩前:" + json.length() + "字节,压缩后:" + compressed.length + "字节");
redisTemplate.opsForValue().set(key, compressed);
}
/**
* 解压读取
*/
public <T> T getWithGzip(String key, Class<T> clazz) throws IOException {
byte[] compressed = redisTemplate.opsForValue().get(key);
if (compressed == null) return null;
byte[] decompressed = gzipDecompress(compressed);
String json = new String(decompressed, StandardCharsets.UTF_8);
return JSON.parseObject(json, clazz);
}
private byte[] gzipCompress(byte[] data) throws IOException {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
try (GZIPOutputStream gzip = new GZIPOutputStream(bos)) {
gzip.write(data);
}
return bos.toByteArray();
}
private byte[] gzipDecompress(byte[] data) throws IOException {
ByteArrayInputStream bis = new ByteArrayInputStream(data);
ByteArrayOutputStream bos = new ByteArrayOutputStream();
try (GZIPInputStream gzip = new GZIPInputStream(bis)) {
byte[] buffer = new byte[1024];
int len;
while ((len = gzip.read(buffer)) != -1) {
bos.write(buffer, 0, len);
}
}
return bos.toByteArray();
}
}压缩效果对比:
| 数据类型 | 原始大小 | GZIP压缩后 | 压缩率 |
|---|---|---|---|
| JSON文本 | 5MB | 1.2MB | 76% |
| 重复数据多的JSON | 10MB | 1MB | 90% |
| 二进制数据 | 1MB | 0.95MB | 5% |
5.3 方案三:异步处理 + 冷热分离
核心思想:将大Value中的冷数据(不常访问)迁移到对象存储(OSS)或MongoDB,Redis只存热数据。

java
/**
* 冷热分离:热数据存Redis,冷数据存OSS
*/
@Service
public class HotColdSeparationService {
@Autowired
private RedisTemplate<String, String> redisTemplate;
@Autowired
private OssClient ossClient; // 阿里云OSS
/**
* 存储用户完整数据(自动冷热分离)
*/
public void saveUserData(Long userId, UserFullData fullData) {
// 热数据:用户基本信息(小Value,存Redis)
UserBasicInfo basicInfo = fullData.getBasicInfo();
String hotKey = "user:basic:" + userId;
redisTemplate.opsForValue().set(hotKey, JSON.toJSONString(basicInfo), 1, TimeUnit.HOURS);
// 冷数据:订单历史、操作日志(大Value,存OSS)
String coldDataKey = "user:cold:" + userId;
String coldDataJson = JSON.toJSONString(fullData.getOrderHistory());
ossClient.putObject("my-bucket", coldDataKey, coldDataJson);
// Redis只存OSS路径
String metaKey = "user:meta:" + userId;
redisTemplate.opsForHash().put(metaKey, "oss_path", coldDataKey);
}
/**
* 查询用户数据(按需加载冷数据)
*/
public UserFullData getUserData(Long userId) {
UserFullData result = new UserFullData();
// 1. 查询热数据(Redis)
String basicJson = redisTemplate.opsForValue().get("user:basic:" + userId);
result.setBasicInfo(JSON.parseObject(basicJson, UserBasicInfo.class));
// 2. 按需加载冷数据(仅当需要时)
if (needColdData()) {
String ossPath = (String) redisTemplate.opsForHash().get("user:meta:" + userId, "oss_path");
String coldJson = ossClient.getObjectAsString("my-bucket", ossPath);
result.setOrderHistory(JSON.parseObject(coldJson, OrderHistory.class));
}
return result;
}
}六、避坑指南:生产环境绝对不能做的事
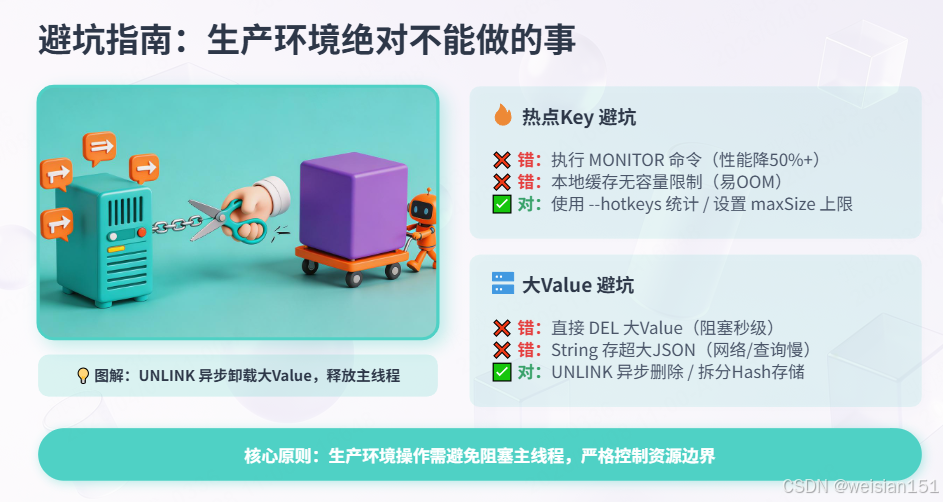
6.1 热点Key避坑
| 错误做法 | 后果 | 正确做法 |
|---|---|---|
生产环境执行MONITOR |
Redis性能下降50%+ | 使用--hotkeys(低峰期)或Proxy统计 |
| 本地缓存无容量限制 | OOM内存溢出 | 设置maximumSize和expireAfterWrite |
| 热点Key无超时控制 | 数据不一致 | 逻辑过期 + 异步刷新 |
| 缓存击穿不用互斥锁 | DB被打挂 | 使用synchronized或分布式锁 |
6.2 大Value避坑
| 错误做法 | 后果 | 正确做法 |
|---|---|---|
定期执行--bigkeys |
生产环境CPU飙升 | 低峰期执行或使用RDB离线分析 |
直接DEL大Value |
Redis阻塞秒级 | 使用UNLINK异步删除 |
| String存储大JSON | 网络阻塞、慢查询 | 拆分为Hash或压缩存储 |
| Value超过1MB不拆分 | 主从延迟、内存碎片 | 必须拆分,迁移到对象存储 |
bash
# 正确:异步删除大Key(Redis 4.0+)
redis-cli UNLINK user:order:12345
# 错误:同步删除会阻塞(禁止)
redis-cli DEL user:order:123456.3 序列化选型建议
| 序列化方式 | 性能 | 大小 | 可读性 | 推荐场景 |
|---|---|---|---|---|
| JSON | 中 | 大 | ✅ | 与前端交互 |
| Protobuf | 高 | 小 | ❌ | 内部RPC |
| Kryo | 高 | 小 | ❌ | 高性能缓存 |
| Java原生 | 低 | 大 | ❌ | 禁止使用 |
java
// 推荐:Protobuf序列化(性能高、体积小)
// 推荐:Kryo序列化(Java生态兼容好)
// 不推荐:Java原生序列化(体积大、性能差)七、选型指南:什么时候用哪种方案?

7.1 热点Key选型原则
- QPS < 1万:仅用Redis即可,无需特殊处理;
- 1万 <= QPS < 10万 :多级缓存(Caffeine + Redis),性价比最高;
- QPS >= 10万 :多级缓存 + Key拆分,双保险;
- 缓存击穿风险高 :永不过期 + 异步重建,保证高可用。
7.2 大Value选型原则
- Value < 100KB:无需处理,Redis原生支持;
- 100KB <= Value < 1MB :启用压缩(LZ4),简单有效;
- Value >= 1MB :内容分片 + 压缩,必须拆分;
- 对象字段多 :字段拆分(Hash),按需获取。
7.3 核心选型原则
- 先监控,后优化:通过埋点或Proxy日志确认问题存在,再选择方案;
- 简单优先:多级缓存能解决90%的热点问题,不要过度设计;
- 成本考量:Key拆分会增加存储成本(N倍),大Value分片会增加代码复杂度;
- 团队能力:选择团队熟悉的技术栈,避免引入难以维护的方案。
八、监控告警与自动化治理
8.1 监控指标
yaml
# Prometheus监控指标
redis_hotkey_qps: 热点Key的QPS
redis_bigkey_size: 大Value的字节数
redis_cache_hit_rate: 本地缓存命中率(多级缓存)
redis_slowlog_count: 慢查询数量(大Value导致)8.2 告警阈值
yaml
# 告警规则
- name: hotkey_detected
expr: redis_hotkey_qps > 5000
severity: warning
message: "检测到热点Key,QPS={{ $value }}"
- name: bigkey_detected
expr: redis_bigkey_size > 102400 # 100KB
severity: critical
message: "检测到大Value,大小={{ $value }}字节"8.3 自动化治理
java
/**
* 热点Key自动本地缓存(自适应)
*/
@Component
public class AutoHotKeyManager {
private final Map<String, AtomicLong> qpsCounter = new ConcurrentHashMap<>();
private final Cache<String, Object> localCache = Caffeine.newBuilder()
.maximumSize(10000)
.expireAfterWrite(60, TimeUnit.SECONDS)
.build();
@Scheduled(fixedDelay = 5000)
public void autoDetectAndCache() {
qpsCounter.forEach((key, counter) -> {
long qps = counter.getAndSet(0) / 5;
if (qps > 1000 && localCache.getIfPresent(key) == null) {
// 自动将热点Key加载到本地缓存
Object value = redisTemplate.opsForValue().get(key);
if (value != null) {
localCache.put(key, value);
System.out.println("自动缓存热点Key:" + key + ",QPS=" + qps);
}
}
});
}
}九、面试高频真题(标准答案直接背)
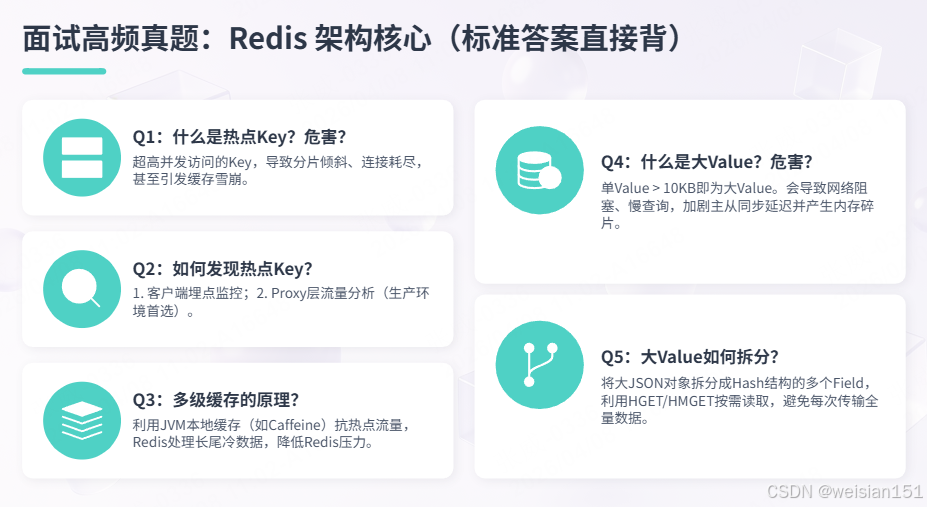
Q1:什么是热点Key?有什么危害?
答案:
- 定义:被超高并发访问的Key,单个Key的QPS超过分片总QPS的50%;
- 危害 :
- 分片倾斜:单个Redis分片CPU爆满,其他分片空闲;
- 连接耗尽:热点Key所在分片连接数被占满;
- 缓存雪崩:热点Key过期瞬间,大量请求穿透到DB;
- 典型场景:电商秒杀、微博热搜、配置中心。
Q2:如何发现热点Key?
答案:
- Redis监控 :通过
INFO命令查看整体统计,但无法定位单个Key(MONITOR命令性能差,生产禁用); - 客户端埋点:在应用层统计每个Key的访问频率,使用Caffeine缓存计数,定期上报热点Key;
- Proxy层分析:在Redis Proxy(如Codis)记录访问日志,通过ELK分析热点Key排行榜。
Q3:多级缓存的原理是什么?如何实现?
答案:
- 核心思想:JVM本地缓存(Caffeine/Guava)+ Redis分布式缓存,本地缓存扛80%热点流量,Redis扛20%冷数据;
- 实现步骤 :
- 查询本地缓存,命中则返回;
- 未命中则查询Redis,命中则回写本地缓存;
- 都未命中则查DB,写入Redis和本地缓存;
- 性能提升:本地缓存纳秒级,Redis毫秒级,DB十毫秒级。
Q4:什么是大Value?有什么危害?
答案:
- 定义:单个Value > 10KB(预警),> 1MB(禁止);
- 危害 :
- 网络阻塞:大Value传输耗时,带宽打满;
- 慢查询:Redis单线程处理大Value,阻塞其他请求;
- 主从延迟:大Value同步到从节点,复制延迟;
- 内存碎片:频繁写入/删除大Value,内存碎片率飙升。
Q5:热点Key的Key分裂方案具体怎么做?有什么注意事项?
答案:
- 实现步骤 :
- 将热点Key拆分成N个副本(如10个),命名规则
key_0到key_9; - 写入时:数据同时写入所有副本或均匀分配;
- 读取时:随机选择一个副本读取;
- 将热点Key拆分成N个副本(如10个),命名规则
- 注意事项 :
- 拆分数量不宜过多(10-20个),否则管理复杂;
- 秒杀扣库存场景需处理多个副本库存不足的降级逻辑;
- 更新数据时需同步更新所有副本(可用消息队列)。
Q6:逻辑过期和物理过期有什么区别?如何实现?
答案:
- 物理过期:Redis自带的TTL,Key过期立即删除,容易引发缓存击穿;
- 逻辑过期:Key永不过期,Value中存储逻辑过期时间,后台异步刷新;
- 实现要点 :
- 查询时判断逻辑过期时间,未过期直接返回;
- 已过期则获取互斥锁,异步从DB加载新数据;
- 返回旧数据(保证高可用,不阻塞);
- 优势:彻底解决缓存击穿问题。
Q7:大Value如何用Hash结构拆分?举个例子?
答案:
- 原方案:String存储用户完整订单历史,Value大小5MB;
- 优化方案:Hash存储,每个订单作为独立的Field,大小5KB;
- 查询优化 :
- 查询单个订单:
HGET user:orders:123 order:456,传输5KB; - 查询最近10条:
HGETALL+ 排序,传输50KB;
- 查询单个订单:
- 效果:网络传输量降低1000倍,QPS从200提升到20000。
Q8:布隆过滤器如何解决缓存穿透?有什么缺点?
答案:
- 原理:将所有合法Key预加载到布隆过滤器,请求到达时先判断Key是否存在;
- 解决穿透:非法Key直接被布隆过滤器拦截,不会查询Redis和DB;
- 缺点 :
- 有误判率(存在但不一定存在,不存在一定不存在);
- 无法删除元素(除非使用Counting Bloom Filter);
- 需要预先知道所有合法Key。
Q9:生产环境如何安全地删除大Value?
答案:
-
使用UNLINK命令 (Redis 4.0+):异步删除,不阻塞主线程;
bashredis-cli UNLINK big_key -
分批删除 (List/Hash/Set/ZSet):
bash# List:每次删除100条 redis-cli LTRIM big_list 0 -101 # Hash:每次删除100个Field redis-cli HDEL big_hash field1 field2 ... field100 -
低峰期执行:避免影响业务。
Q10:压缩存储大Value有什么优缺点?
答案:
- 优点 :
- 减少网络传输(压缩率50%-80%);
- 减少Redis内存占用;
- 提升QPS上限;
- 缺点 :
- 增加CPU开销(压缩/解压);
- 代码复杂度增加;
- 无法直接读取(需解压);
- 适用场景:文本数据(JSON/XML)、重复数据多的场景。
Q11:设计一个秒杀系统的热点Key治理方案,要求扛住百万QPS。
答案:
-
方案选型:多级缓存(Caffeine)+ Key分裂 + 逻辑过期;
-
架构设计 :
用户请求 → Nginx限流 → Caffeine本地缓存(80%命中)→ Redis(20%命中)→ DB(<1%穿透) -
核心实现 :
- 秒杀商品信息:Caffeine本地缓存,过期时间60秒;
- 库存扣减:Key分裂成10个副本,随机扣减;
- 缓存击穿防护:逻辑过期 + 异步重建;
-
兜底策略 :
- 本地缓存穿透后,Redis仍扛不住,熔断降级返回默认数据;
- DB兜底时加分布式锁,防止DB被打挂。
-
监控告警 :
- 客户端埋点统计热搜Key访问频率;
- 超过阈值自动触发Key拆分。
Q12:用户订单历史达到10万条,Value超过10MB,如何优化?
答案:
- 拆分方案:Hash结构存储,每个订单独立Field;
- 冷热分离 :
- 最近30天订单(热数据):存Redis Hash,Field数量 < 100;
- 历史订单(冷数据):迁移到OSS或MongoDB,Redis只存索引;
- 分页查询 :
HSCAN命令分批读取,避免一次HGETALL; - 压缩存储:对冷数据启用GZIP压缩,压缩率70%;
- 最终效果:Redis内存占用从10MB降低到1MB,查询耗时从100ms降到5ms。
总结
1. 核心知识点速记口诀
热点Key要警惕,流量集中是大敌,
多级缓存第一线,Caffeine本地扛压力。
Key拆分化整零,随机读取分散击,
永不过期后台建,避免击穿保可用。
大Value莫存储,网络GC都受苦,
字段拆分按需取,内容分片小步走。
启用压缩LZ4,体积减半速度快,
监控先行再优化,切忌盲目上方案。2. 核心要点回顾
- 热点Key :核心是流量集中 ,解决方案是分散流量(多级缓存、Key拆分);
- 大Value :核心是数据体积 ,解决方案是减小体积(拆分存储、压缩优化);
- 多级缓存:Caffeine(本地) + Redis(分布式)是应对热点Key的黄金组合;
- Key拆分:适用于极端热点,但要注意写放大和数据不一致;
- 大Value拆分:1MB是分界线,超过必须拆分,禁止存储超大对象。
- 避坑要点 :禁用
MONITOR、使用UNLINK异步删除、低峰期扫描。
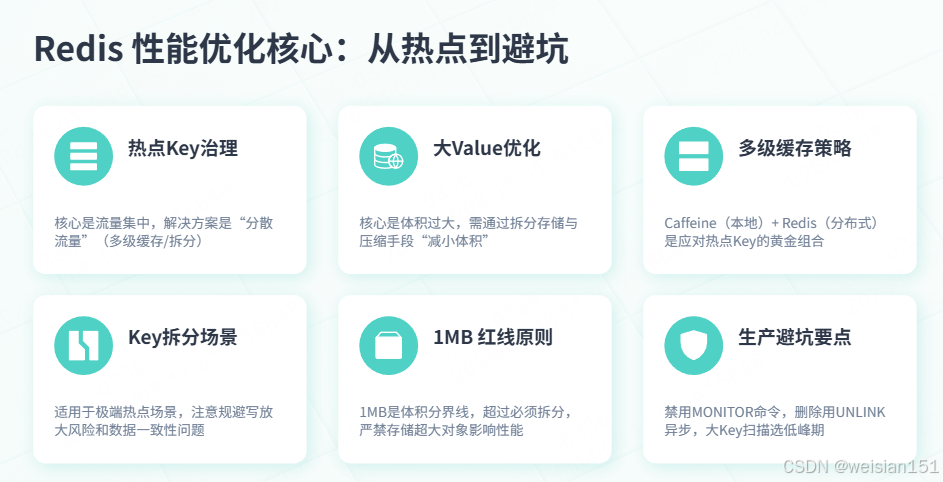
3. 实战建议
- 热点Key:先上多级缓存,监控后再决定是否Key拆分;
- 大Value:100KB以上启用压缩,1MB以上必须分片;
- 缓存策略:高并发场景优先永不过期 + 异步重建;
- 监控体系:客户端埋点 + Proxy日志,实时发现热点Key和大Value。
写在最后
热点Key和大Value是Redis集群中最常见的性能陷阱,但也是最容易被忽视的"定时炸弹"。很多团队在系统崩溃后才意识到问题的严重性,却不知道这些隐患本可以在设计阶段就规避。
最好的优化,是不需要优化。在业务初期就建立完善的缓存规范:
- 禁止存储>1MB的Value;
- 热点Key必须经过多级缓存;
- 所有缓存操作必须有监控埋点。
记住:高性能系统不是靠天才设计出来的,而是靠无数个细节的累积。希望本文能帮你避开这些"坑",构建出真正高可用的缓存系统。
如果觉得有帮助,欢迎点赞、收藏、转发!