★★★★★个人专栏《C语言》** 《数据结构-初阶》★★★★★**
欢迎各位大佬交流!!
一、双向链表(循环):
双向链表就是每个节点都有prev和next指针;
双向链表相较于单链表,不仅将尾插、尾删的时间复杂度降低为O(1)级别;
同时减少了代码量,逻辑更加清晰!使用起来更得心应手;
下面我们就来实现双向链表这个数据结构
0、初始化
同样创建三个文件,同时在 .h 文件中进行结构体的定义;
cpp
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int LTDataType;
typedef struct ListNode
{
LTDataType x;
struct ListNode* next;
struct ListNode* prev;
}LTNode;接着我们写初始化函数
分析逻辑:
申请哨兵位,将头指针指向哨兵位!
初始化函数要申请哨兵位,那么就需要申请节点;
由于后续还会用到申请节点,不妨封装为函数
cpp
//申请节点
LTNode* LTBuyNode(LTDataType x)
{
LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));
if (newnode == NULL)
{
perror("malloc failed!\n");
exit(1);
}
newnode->val = x;
//循环链表需要将自身的next和prev指向自身
newnode->next = newnode->prev = newnode;
return newnode;
}创建时将哨兵位节点的val置为无效数据即可
cpp
//初始化
void LTInit(LTNode** pphead)
{
//申请哨兵位
*pphead = LTBuyNode(-1);
}1、打印
为了后续更直观的看代码是否出错,我们提前完成打印函数
打印逻辑:
由于并未修改头节点,因此直接传一级参数即可;
打印要从有效数据开始,创建cur指针指向phead的next指针;
当cur == phead 时,循环结束
cpp
//打印
void LTPrint(LTNode* phead)
{
//从有效数据开始遍历
LTNode* cur = phead->next;
while (cur != phead)
{
printf("%d ", cur->val);
cur = cur->next;
}
printf("\n");
}2、尾插
逻辑分析:
首先要明确一点,无论怎样插入、删除数据,都不会改变头节点;
因此直接传入一级指针即可;
接着,既然是尾插,那么头节点的上一个位置是不是尾节点?当然是了;
由此,当我们申请节点之后,先修改节点的指向;
之后,由于是在尾节点之后插入,因此最后修改尾节点的后驱
cpp
//尾插
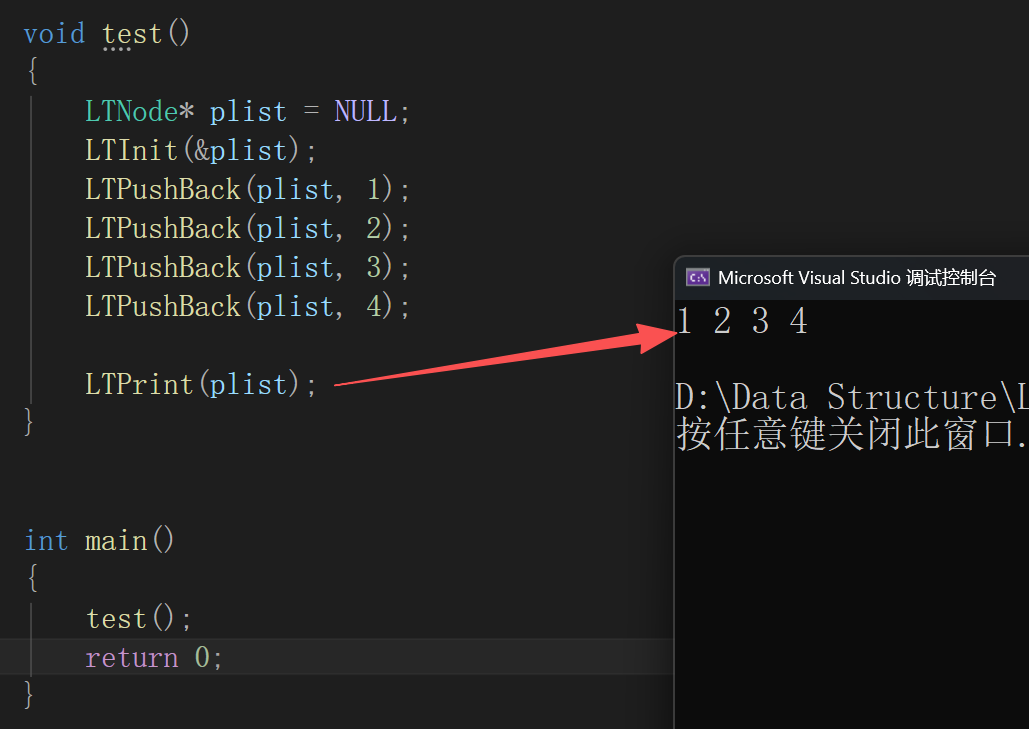
void LTPushBack(LTNode* phead, LTDataType x)
{
assert(phead);
//申请节点
LTNode* newnode = LTBuyNode(x);
//找到尾节点
LTNode* tail = phead->prev;
//先修改自身的节点
newnode->prev = tail;
newnode->next = phead;
//再修改指向自身的节点
//因为是在末尾节点之后插入,因此最后修改末尾节点的后驱
phead->prev = newnode;
tail->next = newnode;
}来测一下
3、头插
分析逻辑:
申请完节点之后,首先修改自身的指向;
由于是在头节点之后进行插入,因此最后修改头节点的后驱
cpp
//头插
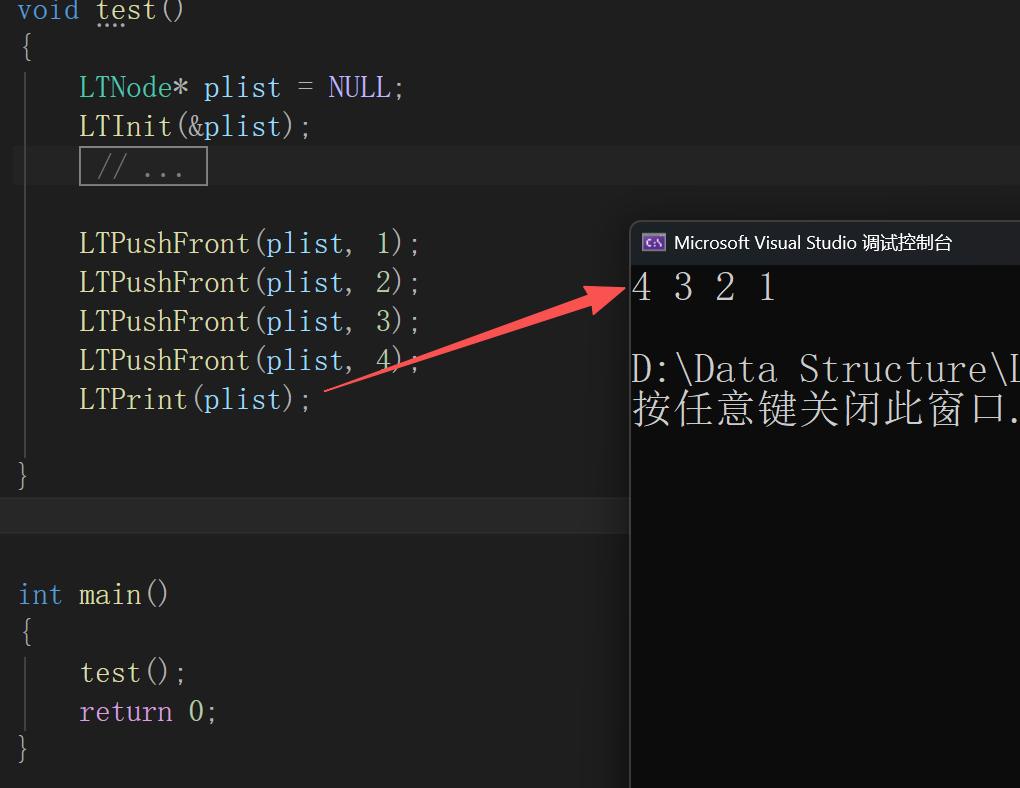
void LTPushFront(LTNode* phead, LTDataType x)
{
assert(phead);
//申请节点
LTNode* newndoe = LTBuyNode(x);
//先修改自身指向
newndoe->prev = phead;
newndoe->next = phead->next;
//再修改指向自身的节点
//最后修改头指针的后驱
phead->next->prev = newndoe;
phead->next = newndoe;
}来测一下
4、尾删
分析逻辑:
尾删前先暂存倒数第二个节点(通过最后一个节点);
接着free最后一个节点;
最后修改指针指向:让phead的prev指向倒数第二个节点,倒数第二个节点的next指向phead;
cpp
//尾删
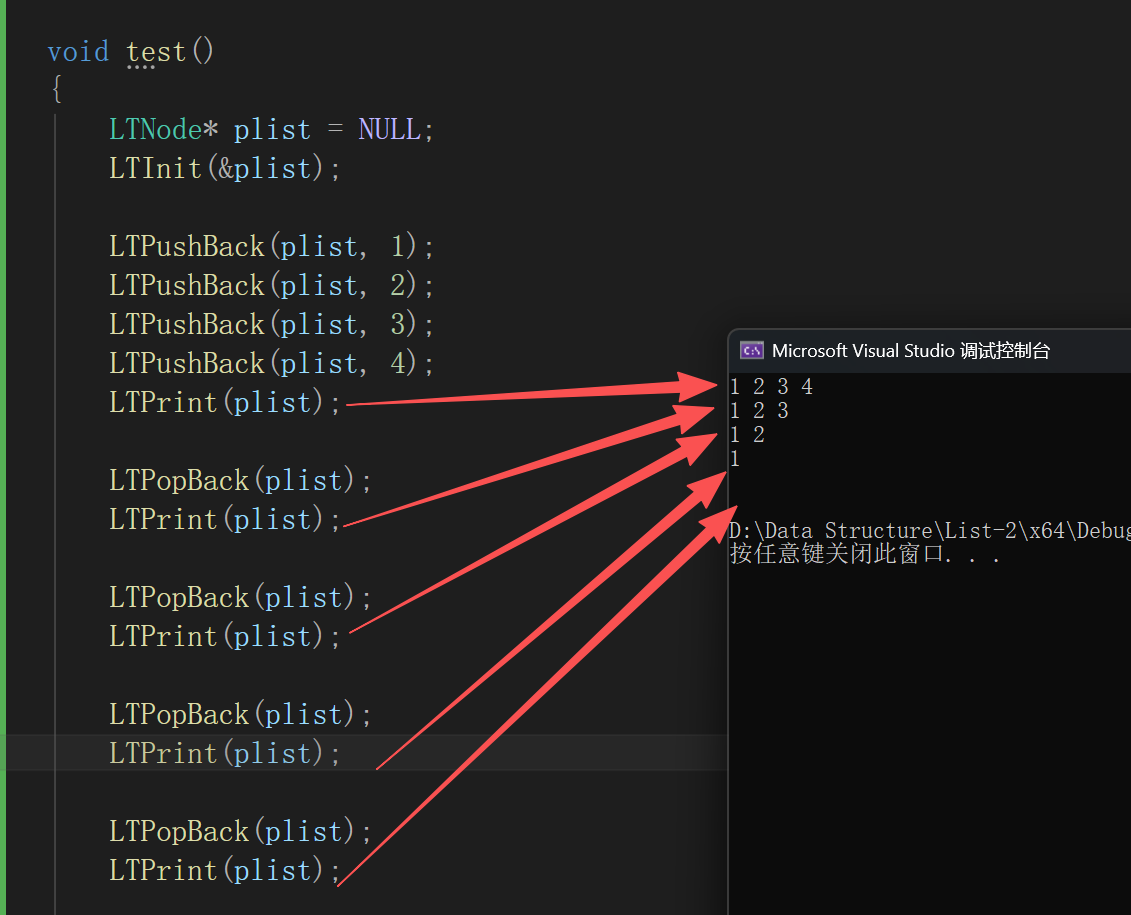
void LTPopBack(LTNode* phead)
{
assert(phead);
assert(phead->next);
//找到尾节点
LTNode* tail = phead->prev;
LTNode* prevtail = tail->prev;
free(tail);
tail = NULL;
phead->prev = prevtail;
prevtail->next = phead;
}来测一下
再删一次,看是否会触发断言
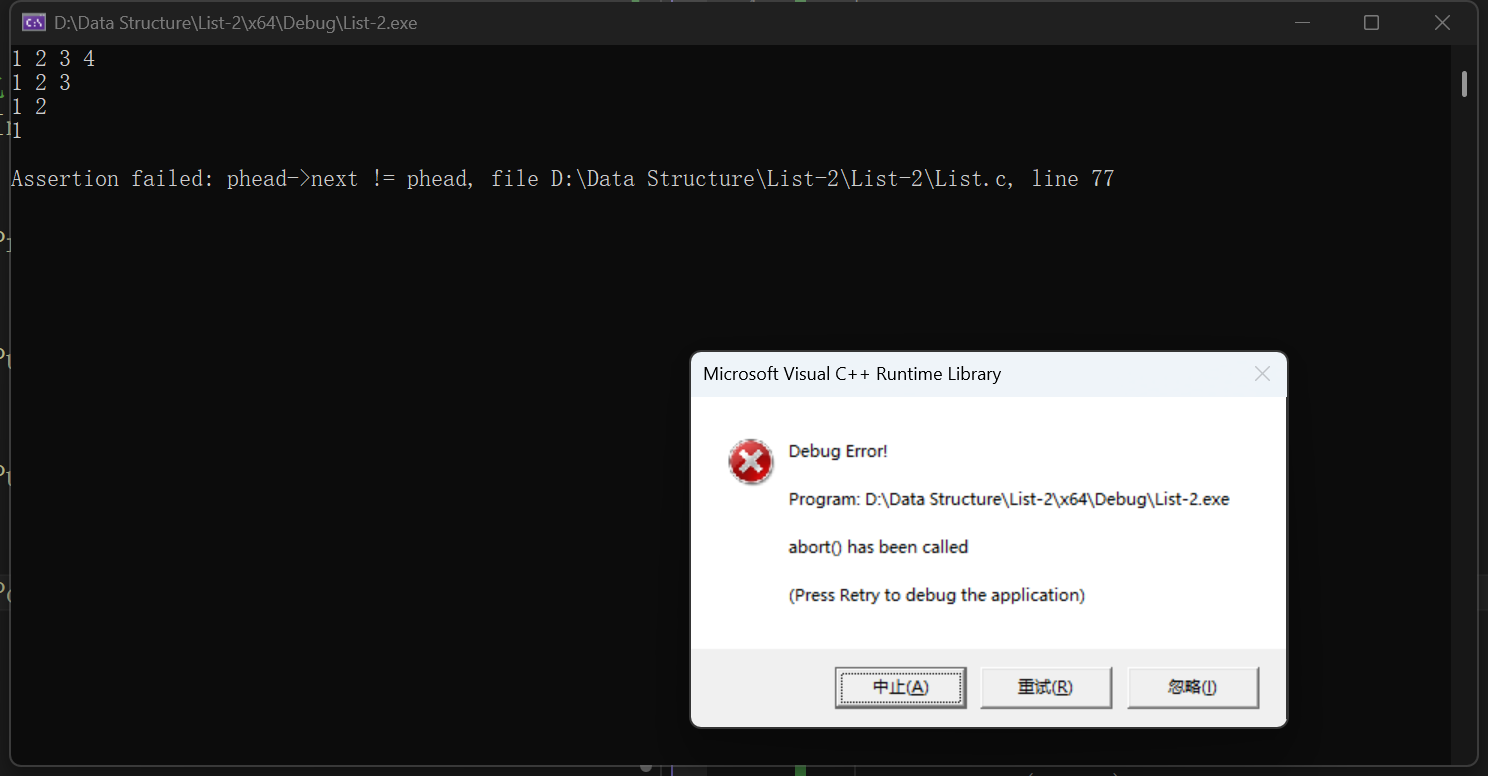
没有问题
5、头删
分析逻辑:
首先暂存头节点的下一个节点的下一个节点next;
然后free 头节点的下一个节点
接着修改next的指向
cpp
//头删
void LTPopFront(LTNode* phead)
{
assert(phead);
assert(phead->next != phead);
LTNode* del = phead->next;
LTNode* next = del->next;
free(del);
del = NULL;
phead->next = next;
next->prev = phead;
}来测一下
再删一次,看是否会触发断言
6、查找
分析逻辑:
遍历一遍链表,逐个比较val是否相等,找到就直接返回节点对应的地址;
循环结束后,返回NULL
cpp
//查找
LTNode* LTFind(LTNode* phead, LTDataType x)
{
assert(phead);
assert(phead->next);
LTNode* cur = phead->next;
while (cur != phead)
{
if (cur->val == x) return cur;
cur = cur->next;
}
return NULL;
}
7、在pos前插入
分析逻辑:
首先申请节点,接着修改指针指向;
注意先修改自身的指向,再修改指向自身的节点的指向;
最后修改pos的前驱!
cpp
//在pos之前插入
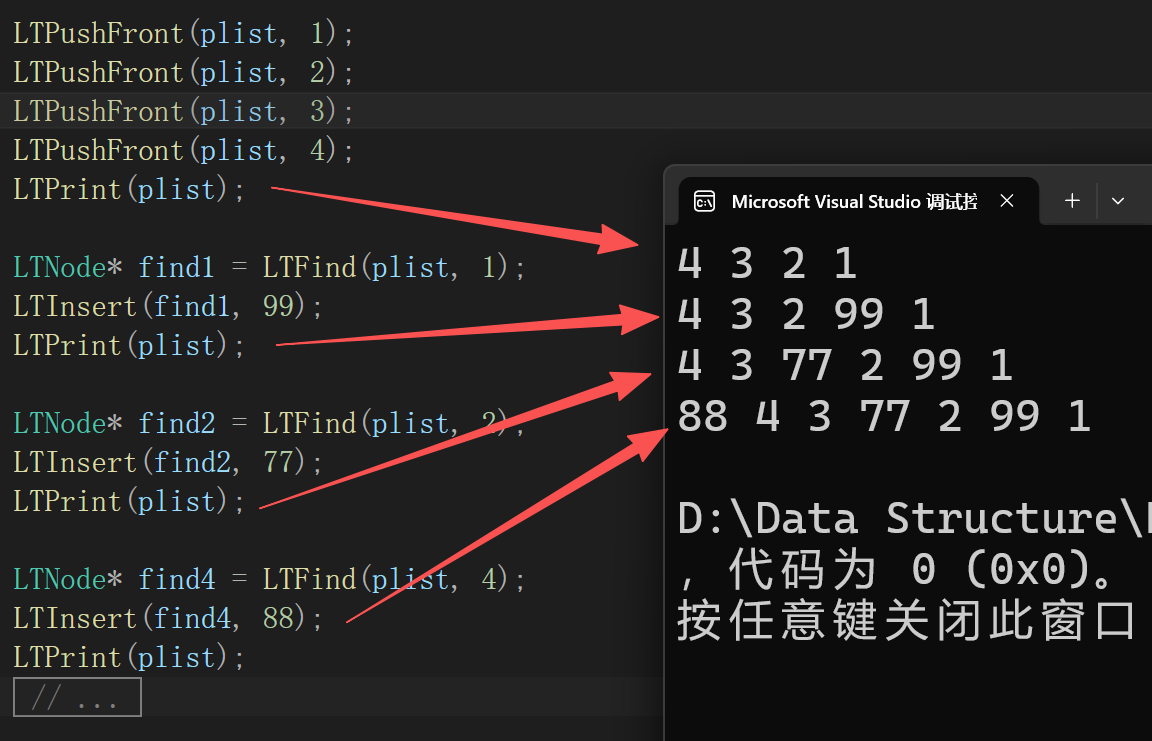
void LTInsert(LTNode* pos, LTDataType x)
{
assert(pos);
//先申请节点
LTNode* newnode = LTBuyNode(x);
//先修改自身节点的指向
newnode->next = pos;
newnode->prev = pos->prev;
//最后修改pos的前驱
pos->prev->next = newnode;
pos->prev = newnode;
}
8、删除pos节点
分析逻辑:
先暂存pos节点的前驱和后继;
接着free,修改指针指向即可
cpp
//删除pos节点
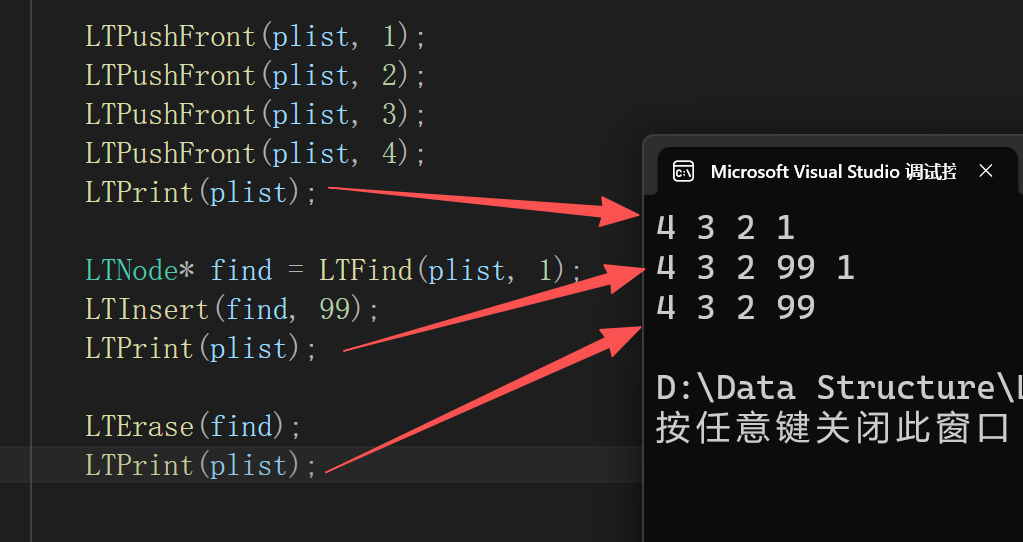
void LTErase(LTNode* pos)
{
assert(pos);
LTNode* prev = pos->prev;
LTNode* next = pos->next;
free(pos);
pos = NULL;
prev->next = next;
next->prev = prev;
}
9、销毁
分析逻辑:
其实就是遍历一遍链表,暂存下一个节点的信息,然后逐个free;
最终free哨兵位
cpp
//销毁
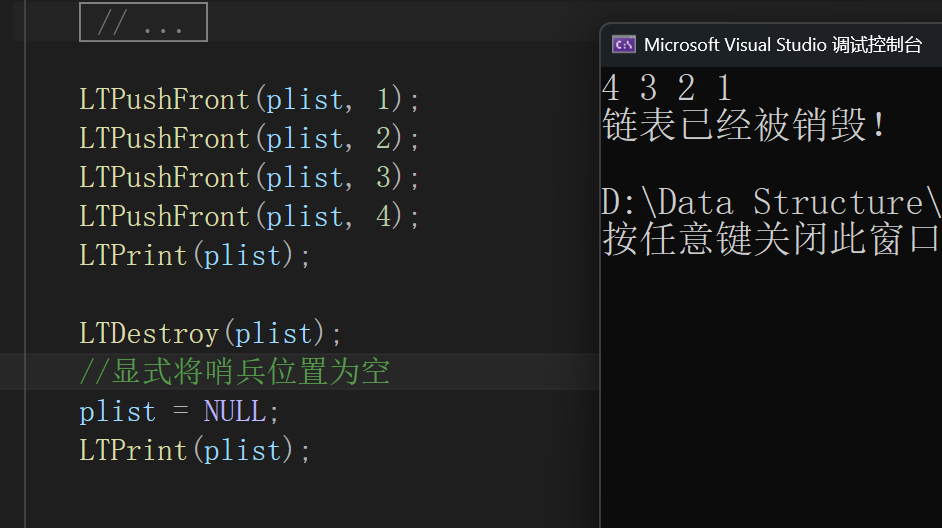
void LTDestroy(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
LTNode* next = cur->next;
free(cur);
cur = next;
}
free(phead);
}如果想打印销毁后的链表的话,我们直接在打印函数中对phead进行处理;
cpp
//打印
void LTPrint(LTNode* phead)
{
//从有效数据开始遍历
if (phead == NULL)
{
printf("链表已经被销毁!\n");
return;
}
LTNode* cur = phead->next;
while (cur != phead)
{
printf("%d ", cur->val);
cur = cur->next;
}
printf("\n");
}
没有问题!
双向链表的基本核心功能均已实现!
二、链表篇总结
我们先比较单链表与双链表,接着再比较顺序表与链表;
1、单链表与双链表
|-----------------|--------------------------|-------------------------------------|
| 比较维度 | 单链表 | 双链表 |
| 节点结构 | 数据域、指向下个节点的指针 | 数据域、指向上个节点的指针和下个节点的指针 |
| 内存占用 | 占用较少(一个指针) | 占用较多(两个指针) |
| 反向遍历 | 不支持 | 支持 |
| 查找前驱节点 | 不支持 | 支持 |
| 插入/删除(给定节点 指针时) | 需要知道前驱 否则先查找前驱(O(N)) | O(1)时间内完成 |
| 插入/删除(仅给 值或位置) | 遍历一遍 O(N) | 也是O(N) 修改指针更简单 |
| 应用场景 | 简单、内存紧凑的场景 如哈希桶链、简单的栈/队列 | 需要双向遍历、频繁操作前后节点的场景 如 LRU 缓存、浏览器历史记录 |
2、顺序表与链表
|-----------|---------------------|-----------------|
| 不同点 | 顺序表 | 链表 |
| 存储空间上 | 物理上一定连续 | 逻辑上连续; 物理上不一定连续 |
| 随机访问 | 支持O(1) | 不支持,O(N) |
| 任意位置插入/删除 | 可能需要移动元素; O(N) | 只需修改指针指向 |
| 插入 | 动态顺序表; 空间不够时扩容,按需处理 | 没有容量的概念 |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置插入/删除 |
| 缓存利用率 | 高 | 低 |
下面我们着重来讲一下缓存利用率的问题;
顺序表和链表在缓存利用率上的根本差异源于内存布局的不同;
顺序表的大多存储在一块连续的内存空间,当cpu访问某个元素时,不仅会加载该元素,更会通过缓存将邻近的多个元素一起读入缓存;
因此无论是顺序访问还是随机访问,大概率能命中已在缓存中的元素,从而减少访问主存的次数,提高效率;
而链表,节点大多是随机存储在堆内存上,cpu每次访问一个节点都需要跟随指针去访问一个大概率不在缓存中的地址;
因此cpu频繁访问势必会造成效率低下,导致缓存利用率低。
如有不足之处恳请指出!