1400 条小红书收藏 · 37 个专辑 · 0 人工:我把 AI 分类塞进了 Obsidian
我老婆是一个典型的小红书重度用户。她的收藏夹里有超过 1400 条笔记:化妆教程、穿搭攻略、旅行路线、家居改造、美食菜谱......应有尽有。
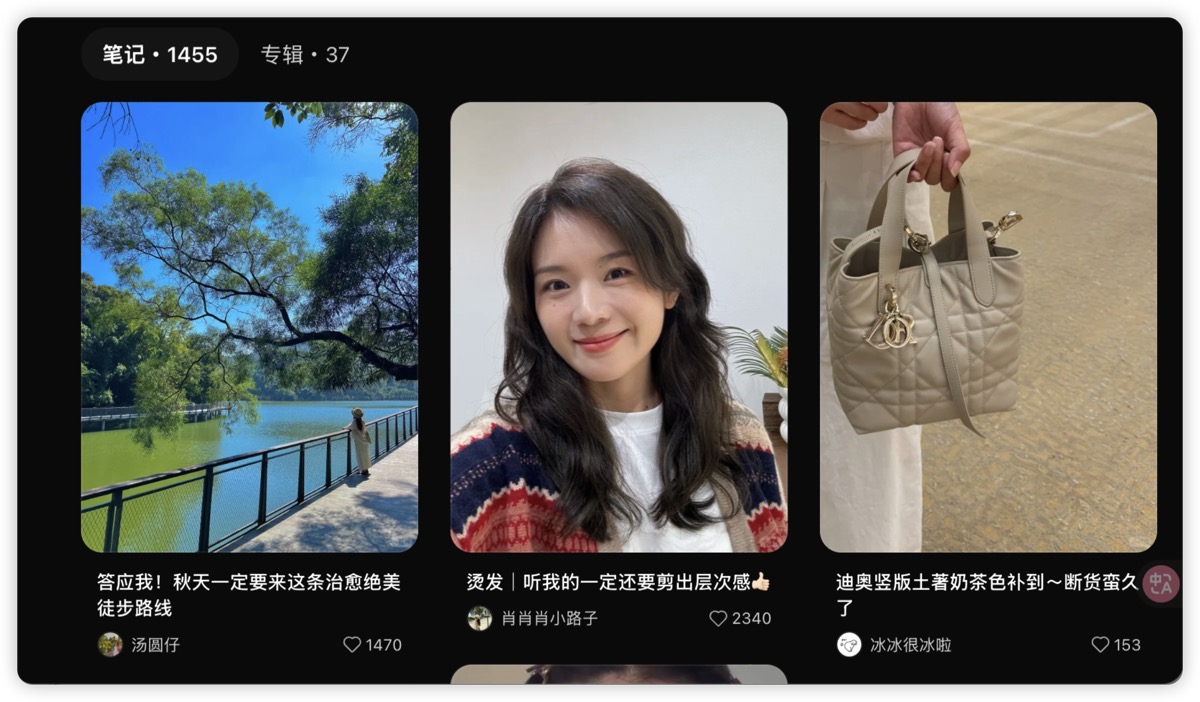
如果你也是小红书重度用户,现在打开 App 翻翻自己的收藏夹------大概率你也是这种状态:心血来潮收藏一通,然后再也没回去看过。
两年前她终于下决心要整理------手动建了 37 个专辑,塞进去 20 几条就放弃了。一千四百多条收藏横跨各种主题,没有分组、没有结构,逐条归类几乎是灾难级的工作量。第二天她就把这件事忘了。
我看着她放弃的那个瞬间,意识到问题根源:这是一个天然适合 AI 的重复任务,完全不适合人工做。
所以我写了一个 Obsidian 插件(也写了个Notion的插件)------让 AI 帮她把这 1400 条收藏全部自动分类,同步到她自己的 vault 里。
为什么是 Obsidian:三个用户独有的痒点
小红书收藏要"搬家",选项其实不少------Notion(这个我去年也写了)、印象笔记、飞书文档,各种云端知识库都能装。为什么偏偏是 Obsidian?
答案有三层,构成了很多人(尤其是深度笔记爱好者)选择 Obsidian 的独特理由:
痒点一:数据主权。 很多 Obsidian 用户不愿意把知识库锁在云端。云服务偶尔抽风、API 动一动、网络不稳一下,都是一次心悸。说白了:你的笔记不能因为别人的产品死亡而消失。
痒点二:和自己笔记融合。 Obsidian vault 里有读书笔记、会议记录、项目资料、工作日志。如果小红书收藏活在另一个应用里,它就永远是一座"孤岛"------搜索不到、反链不到、也没法和自己的思考交叉。Obsidian 用户要的不是再多一个收藏箱,而是让小红书收藏成为自己笔记网络的一部分。
痒点三:离线 + 跨端自由。 地铁两小时没网想翻收藏?需要本地。想用 iCloud 或 Syncthing 在手机电脑之间同步?需要本地。换一台电脑打开就能接着用?需要 markdown。云端笔记是租房,本地 markdown 才是自有产权。
这三件事加起来,就是写这个插件的动机:把小红书收藏真正放回用户自己手里。
1400 条 · 37 个专辑 · 0 人工:这是怎么做到的
标题里那三个数字,一个一个来讲。
1400 条 ------ 历史收藏一次性全量拉。
小红书的接口对频率很敏感,拉太快就会丢限流错误码。插件的策略是:默认每 10 分钟跑一批,每批 5 条,后台跑;历史数据阶段一旦拉完(has_more === false),自动切换到增量模式,只拿新增。你开着 Obsidian 不用管它,一两天就全拉完了。
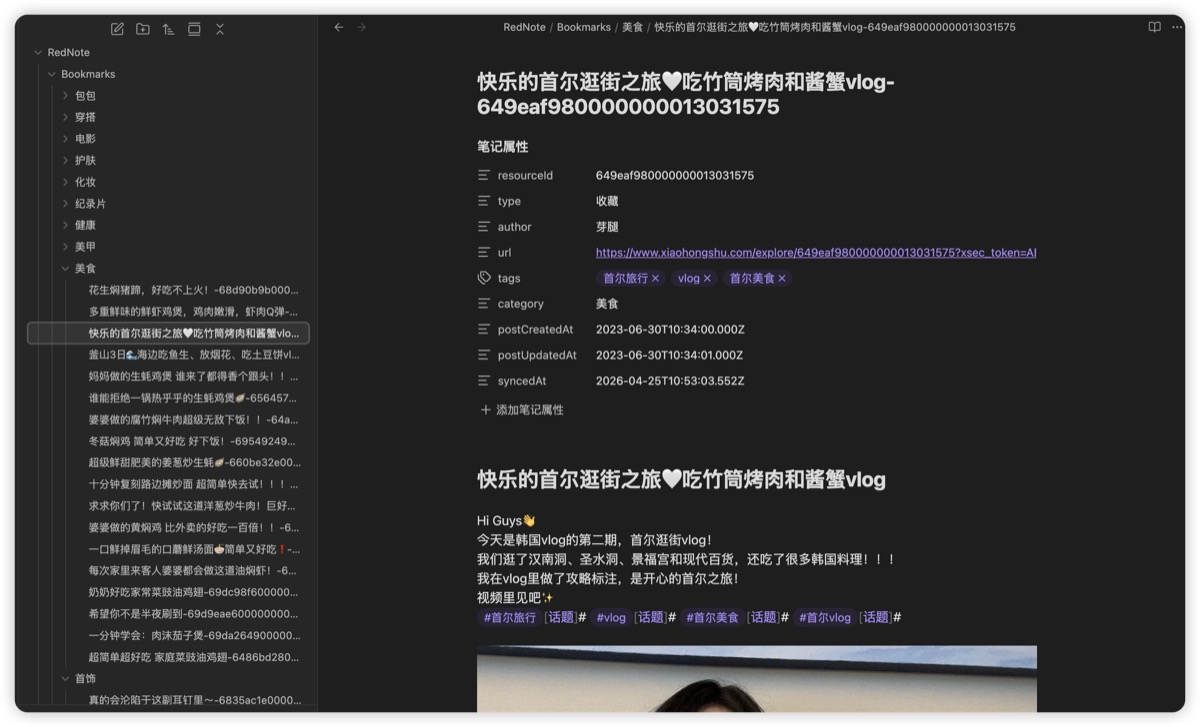
37 个专辑 ------ 每个专辑就是一个 Obsidian 子文件夹。
只要在插件设置里打开「按专辑同步」,同步出来的结构就是这样:
RedNote/
├── Bookmarks/
│ ├── 旅游路线/
│ ├── 化妆教程/
│ ├── 穿搭参考/
│ ├── ...(你的 37 个专辑,每个一个文件夹)
│ └── 未分类/
├── Posts/
├── Likes/
└── Media/
└── {帖子ID}/image-1.webp没分进专辑的收藏有兜底目录。每条笔记的正文是小红书原帖,图片全部下载到本地 Media/ 下,用 webp 原格式。
0 人工 ------ AI 分类自动归档。
这是最要命的那一块。手动整理 1400 条,按每条 30 秒算需要 11.7 小时;开启 AI 分类之后,你第一次配好 API Key,剩下的事情你再也不用管 ------新同步进来的每一条,插件都会把标题+正文+标签丢给 AI,拿回分类名,然后把文件放进对应的子目录。
同步前:1400+ 条散在一起,没有结构,没有分组。
同步后:Obsidian 里一个干干净净的文件树。
AI 分类是怎么工作的:一张图说清楚
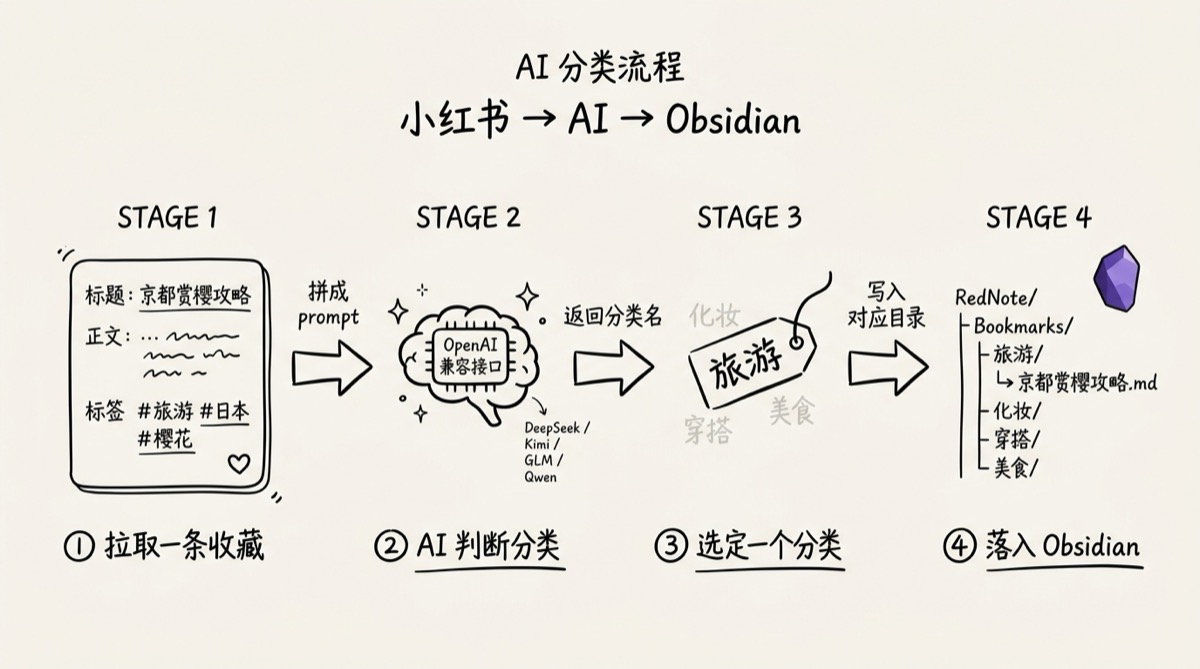
整个流程只有四步:
- 插件从小红书接口拉到一条收藏(含标题、正文、标签)
- 把这些内容和你设置的分类列表拼成一段 prompt,丢给 AI
- AI 返回一个分类名
- 插件把这条笔记写进 Obsidian 对应的子目录
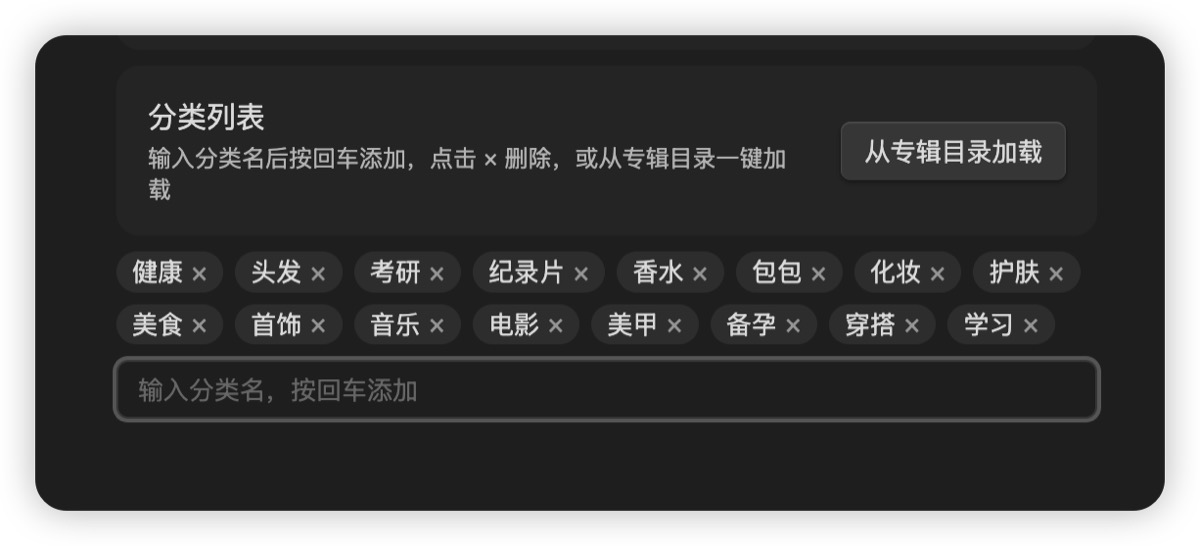
你只要做一件事:告诉插件你想要哪些分类。
可以手填 JSON 数组,比如 ["旅游", "化妆", "穿搭", "家居", "美食"];也可以点一下「从专辑目录加载」------插件直接把你小红书现有的专辑名拿来用,省得再想。
AI 模型方面几乎没有限制。任何 OpenAI 兼容接口都行:
- OpenAI
- DeepSeek(便宜好用)
- Kimi / 智谱 GLM / 通义千问
- OpenRouter / 硅基流动
- 或者你自己搭的网关
我自己测下来,DeepSeek 跑 1400 条分类成本不到 5 毛钱。
安装和配置:10 分钟跑起来
说了这么多,真要上手其实很快。
第一步:装插件。
下载 rednote2obsidian.zip(文章下方有下载地址),解压后把 rednote2obsidian 文件夹整个放到你 vault 的 .obsidian/plugins/ 目录下。
.obsidian 是隐藏文件夹,macOS 按 Cmd + Shift + . 显示,Windows 在资源管理器里勾"显示隐藏项"。
然后打开 Obsidian,设置 → 第三方插件 → 关闭安全模式 → 刷新 → 启用 RedNote Sync。
第二步:登录小红书。
插件设置里点「登录小红书」,弹出的窗口里登录你的小红书账号,登完点「登录完成,提取 Cookie」。
一个很重要的承诺:Cookie 不会离开你的电脑。 它只存在 .obsidian/plugins/rednote2obsidian/data.json 这个文件里,不会上传到任何服务器。简单说:这个插件没办法、也没动机偷你的账号------它没有云端、没有服务器、连一个 API 调用都没有。
第三步:配同步策略。
把「同步内容」选「收藏」,把「按专辑同步」打开。同步间隔建议保持默认 10 分钟一批 5 条------这是我反复试出来最稳的节奏,再激进就容易被小红书限流。
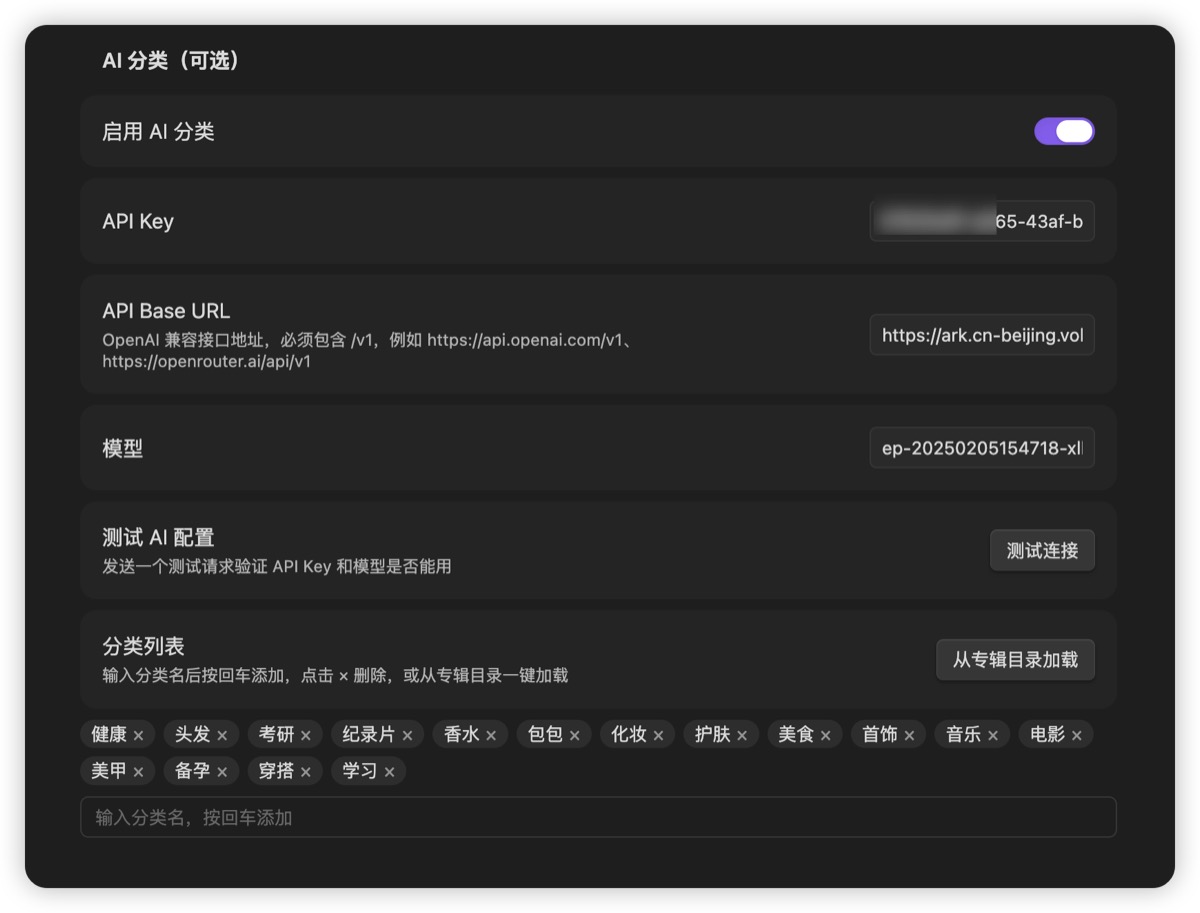
第四步:配 AI 分类。
填 API Key、Base URL(记得带 /v1)、模型名,点「测试连接」确认绿灯。
然后在「分类列表」里把分类写好,或者直接点「从专辑目录加载」一键拉。
所有配置完成后,要么在左侧栏点小红书图标手动触发一次同步,要么就挂着让它自己跑。右上角会不断弹小 toast:"收藏:同步了 5 条"。
同步完成后的 vault 长什么样
这一段才是我最想让 Obsidian 用户看的。
每一条小红书笔记在 Obsidian 里长这样:
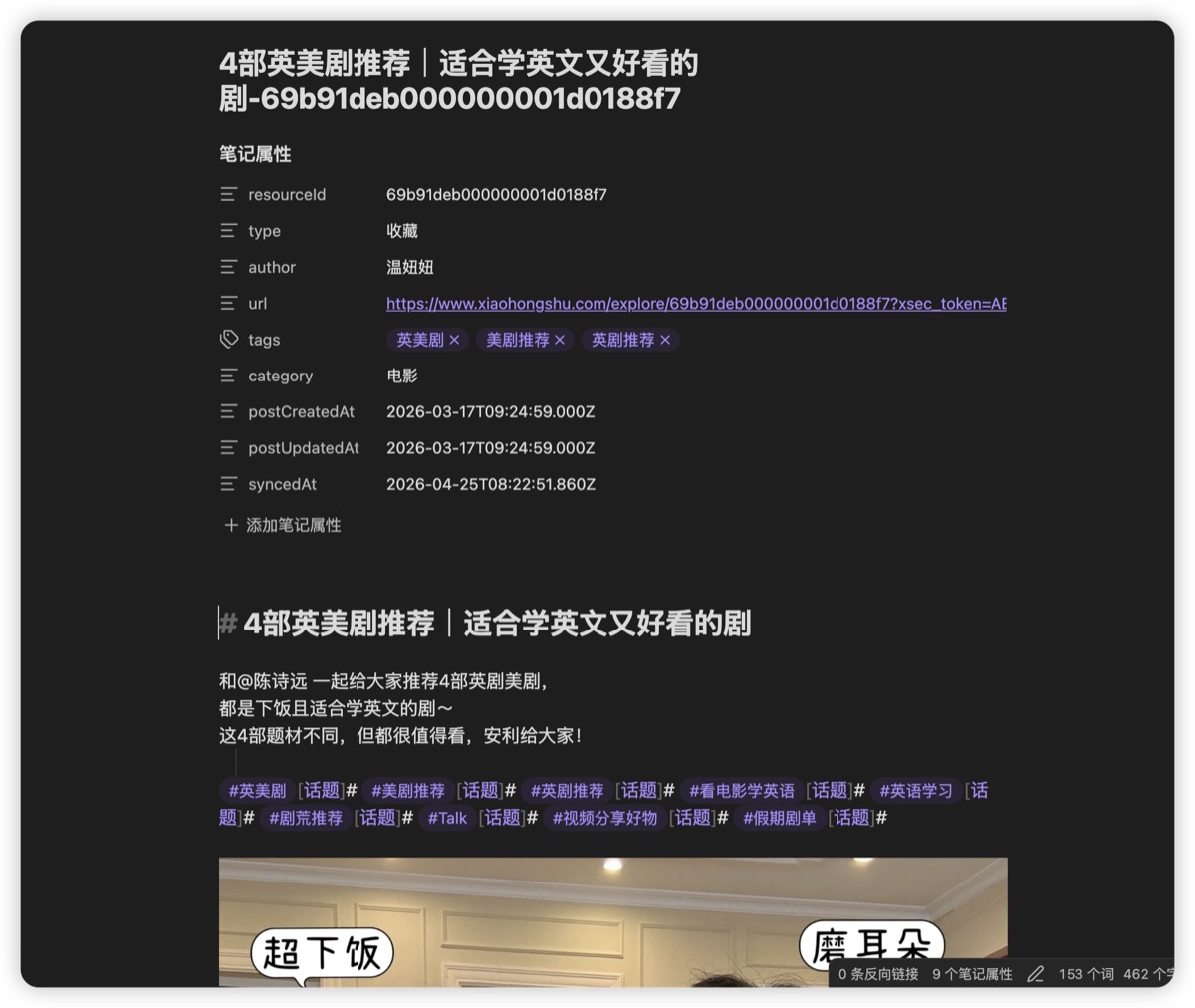
上面是 YAML frontmatter------resourceId、作者、原文链接、标签、分类、创建时间全在里面,可以被 Dataview 直接查询。
中间是帖子正文。
下面是本地图片(下载到 RedNote/Media/{帖子ID}/)。视频呢?视频保留了嵌入播放器和原链,但不下载到本地------视频太占空间,也不是 vault 的主角。
这时候真正的价值才显露出来。
我老婆的 vault 里本来就有一篇叫 \[护肤 SOP] 的笔记,是她自己整理的护肤流程。同步完小红书收藏之后,她在 \[护肤 SOP] 里加了一行:
相关参考:#敏感肌然后 Obsidian 的反链面板立刻显示------她收藏过的 12 条关于敏感肌的小红书笔记,全部跳出来。
这件事云端数据库做不到。云端数据库是孤岛,一条记录和另一篇文档之间没有原生的网状关系。但 Obsidian 是一张网------小红书收藏就是新织进去的一圈节点。
全局搜「敏感肌 」,她自己写的皮肤记录、小红书收藏的科普、收藏的产品评测,同一个搜索框里全部出来。
这就是我说"让小红书收藏成为自己笔记的一部分"的意思。收藏不再是孤立的一千多条卡片,而是会和你的思考双向链接、被你随时召回的、活的素材库。
这个插件适合什么样的人
它不是万能工具。如果你是下面这几类人之一,它几乎是为你量身定做的:
- 数据主权党 --- 不想让知识库活在别人的服务器上
- Obsidian 重度用户 --- vault 已经很厚了,想让小红书收藏也成为笔记网络的一部分
- 离线优先 --- 地铁、飞机、信号差的地方也要能翻
- 纯 markdown 拥护者 --- 哪天不用 Obsidian 了,还可以随手换到 VS Code、Typora、iA Writer
- 被"收藏吃灰"困扰的人 --- 知道自己存了好东西,但再也没回去看过
反过来,如果你只是偶尔刷刷小红书、收藏量不大、对本地笔记没需求------这个插件可能对你过于"重",留在小红书 App 里翻就好。
最后
- 下载地址:
https://static.2notion.com/rednote2notion/rednote2obsidian.zip - 遇到问题反馈:插件设置页底部有联系入口
把小红书收藏放回自己手里------这是我做这个插件的全部动机。