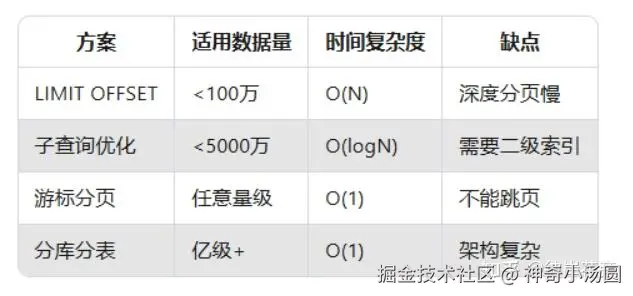
今天给大家分享一道阿里云社招面试中的经典问题------如何处理千万级数据的分页查询。这不仅是高频面试题,更是实际业务中必须解决的性能难题。下面我会从基础实现到阿里级优化方案,逐步拆解这个问题的技术要点。
1. 基础方案:LIMIT OFFSET的致命缺陷
面试官 :"假设订单表有1000万数据,如何实现分页查询? "
初级开发者的回答通常是:
sql
SELECT * FROM orders ORDER BY create_time DESC LIMIT 10 OFFSET 1000000;问题分析:
- 全表扫描MySQL需要先读取1000010条记录,然后丢弃前100万条
- 性能灾难 当OFFSET=900万时,查询可能需要10秒+
- 内存爆炸大偏移量会导致大量临时文件生成(Using filesort)
2. 中级优化:子查询+索引覆盖
进阶方案:
sql
SELECT * FROM orders WHERE id <= (SELECT id FROM orders ORDER BY create_time DESC LIMIT 1000000, 1)ORDER BY create_time DESC LIMIT 10;优化原理:
- 子查询先通过覆盖索引快速定位到起始ID
- 主查询通过主键ID范围过滤
- 相比OFFSET方案,性能提升10倍+
适用场景:
- 数据量在100万-5000万级别
- 必须有合适的索引(create_time需建立二级索引)
3. 阿里级方案:游标分页(Cursor Pagination)
面试官期待的答案:

技术要点:
- 无OFFSET通过上一页的最后一条记录作为游标锚点
- 索引友好 完美利用
(create_time)索引的有序性 - 性能稳定无论查询第1页还是第100万页,响应时间都<100ms
业务适配:
- 需要前端配合传递
last_record_value - 不支持随机跳页(但符合现代APP无限滚动交互)
4. 终极方案:分库分表+二级索引
当数据量达到亿级时,阿里云实际采用的架构:
- 水平分片按订单ID哈希分16个库
- 全局索引表 单独维护
(user_id, create_time)的映射关系
- 查询流程
- 先查索引表获取目标记录的主键ID
- 再通过ID路由到具体分片查询完整数据