大家好,我是 小特,一个正在努力学习的菜鸟
最近在学 Redis,顺便把笔记整理成博客分享出来~
如果哪里有讲得不对的地方,欢迎大佬们温柔指正 🥹
那我们开始吧,一起搞定 Redis!💪
一、认识 Redis:为啥不直接定义变量,非得绕个圈用 Redis?
灵魂拷问:Redis 也是存内存,我 Python/Java 里直接定义一个变量不香吗?
答案就在 分布式系统 里~ 单机程序请直接走变量,别折腾自己 😅
1、变量 vs Redis:单机时代,变量才是王者
- 在单机程序中,数据直接放在变量里,访问速度极快,没有任何网络开销 ✅
- 如果只有你一个人(一个进程)玩,用 Redis 反而是脱裤子放屁 ------ 多此一举 💨
但问题是:一旦上了分布式,情况就完全不一样了。
2、 分布式系统的"天堑":进程隔离
- 分布式系统 = 多个进程,通常跑在不同主机上
- 进程天生具有隔离性 ------ 你不能随随便便去访问另一台机器上的内存变量 🚫
- 那怎么办?进程间通信(IPC) 来救场!而最主流的 IPC 方案就是 👉 网络
✨ Redis 的本质:
基于网络,把自己内存里的变量分享给别人用 ------ 相当于一个远程内存仓库 🗄️
3、Redis vs MySQL:快,就是任性
- MySQL 慢在磁盘 I/O,哪怕有缓存,本质还是面向磁盘设计
- Redis 全在内存 ,读写速度轻松微秒/毫秒级,比 MySQL 快几个数量级 🚀
所以很多高并发场景(秒杀、排行榜、缓存)都会请 Redis 出马。
4、那为啥不全部用 Redis,扔掉 MySQL?
因为 Redis 的"阿喀琉斯之踵" ------ 存储空间有限 📉
- 内存比磁盘贵得多,一台机器的内存也就几十 GB ~ 几百 GB
- MySQL 的磁盘可以轻松上 TB / PB 级别
如果 Redis 能无限存,还要啥自行车?可惜现实很骨感 😭
5、 二八原则:Redis + MySQL 黄金组合
80% 的请求集中在 20% 的热点数据上
- 热点数据(如登录 session、热门商品)👉 放 Redis,飞快访问
- 全量数据 👉 放 MySQL,稳如老狗
- 代价:系统复杂度飙升 💥 ------ 数据修改时要同时考虑 Redis 和 MySQL 的同步问题
6、冷知识:Redis 最早是想做消息队列的
- Redis 的初心:分布式下的生产者-消费者模型(消息中间件)
- 后来大家发现:咦?这货做数据库/缓存简直太香了!🍭
- 于是 Redis 在缓存/数据库的路上一路狂飙,消息队列反而成了附属功能
7、最后总结
离开分布式系统,Redis 最大的优势几乎归零
单机程序:直接用变量,简单高效
分布式系统:用 Redis 共享内存数据,真香!
二、单机架构:千万别把分布式想得多高大上!
在聊分布式之前,咱先老老实实看看 单机架构 长啥样 👇
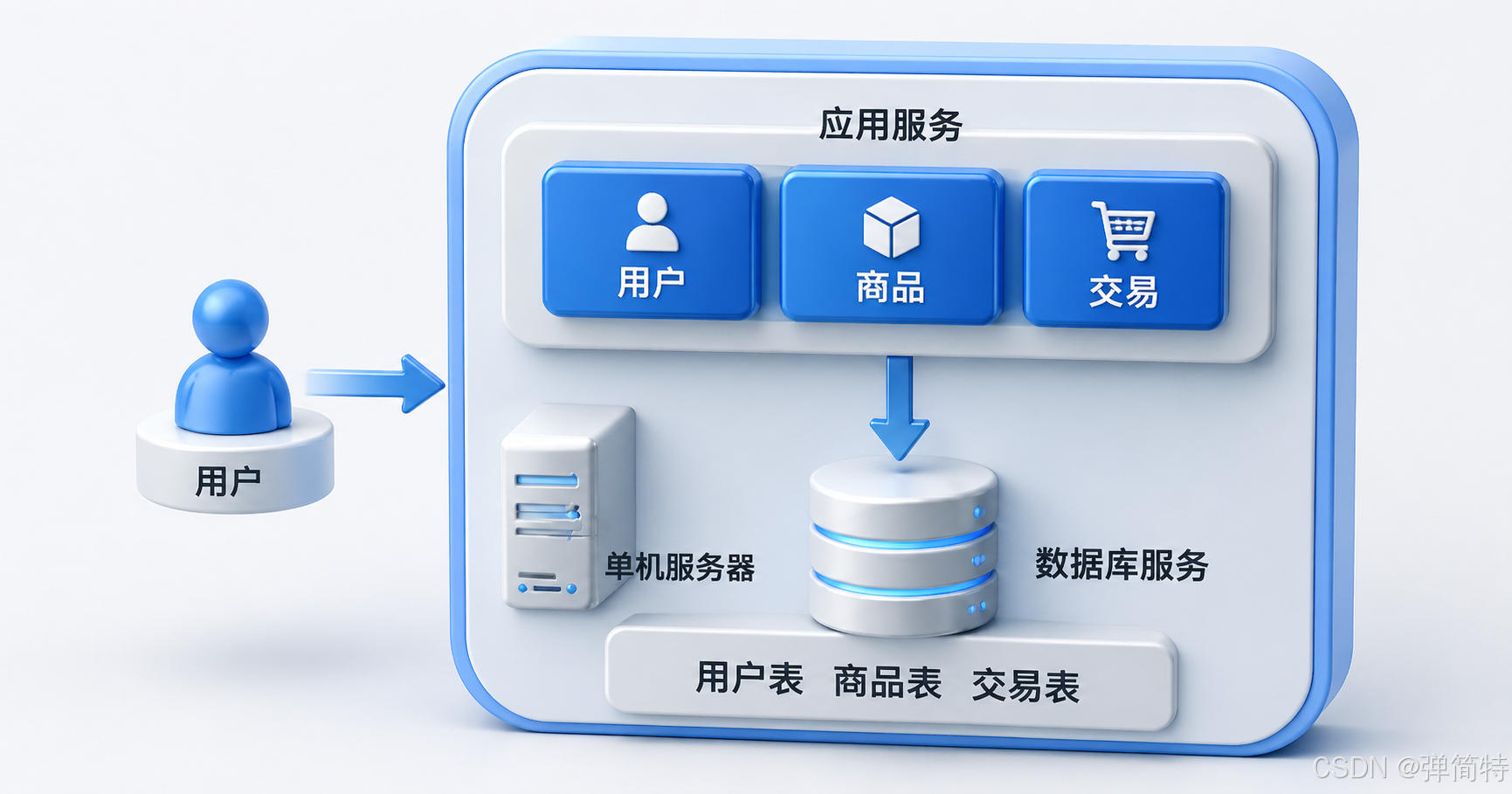
1、啥是单机架构?
就一台服务器,包揽所有活 ------ 应用服务 + 数据库服务,全挤在一块儿。
假设我们搞了一个电商网站:
- 应用服务 = 你写的服务器程序(业务逻辑、接口)
- 数据库服务 = 比如 MySQL,专门存数据
🤔 有人会问:能不能连数据库服务也省了,让应用服务器既管业务又管存储?
------ 不是不行,但你会把自己逼疯 😫 数据持久化、查询、事务... 自己造轮子太痛苦了。
别瞧不起单机架构!
现在 绝大多数公司的产品 依然是单机架构滴
为什么?因为硬件发展太快了 !
一台主机的性能已经很高,能扛住相当高的并发和相当大的数据量。
只有当业务继续膨胀、用户量和数据量 水涨船高 的时候,我们才不得不考虑分布式。
二、分布式系统:无奈之举,但也是必经之路
1、 为什么用户多了就必须上分布式?
因为 一台主机的硬件资源是有上限的 🔝
资源包括但不限于:
- CPU
- 内存
- 硬盘
- 网络带宽
每个请求都会消耗上述资源。同一时刻请求太多,某个资源就会先被榨干 💀
结果就是:请求处理变慢,甚至直接报错。
2、硬件不够用了怎么办?两条路
1) 开源 ------ 加硬件
简单粗暴:加 CPU、加内存、换 SSD、插网卡...
但 一台主机的扩展能力是有限的 (主板插槽就这么几个)。
加到了极限还不够?那就只能上 多台主机 了。
2) 节流 ------ 软件优化
通过性能测试找出瓶颈,然后优化代码、索引、缓存、算法......
这很考验程序员的水平,但也是最硬核的解法。
两种方法可以一起用,但记住:
引入分布式,是万不得已的决策 ⚠️
为啥?因为分布式会让系统复杂度爆炸 💥
Bug 概率 ↑,加班概率 ↑↑
3、 从单机到分布式的第一步:数据库分离 + 负载均衡
我们最初的单机架构:应用 + 数据库 挤在同一台主机。
如果请求量增加,一台主机顶不住,最典型的分布式改造就是:
1) 应用服务器 和 数据库服务器 分开放
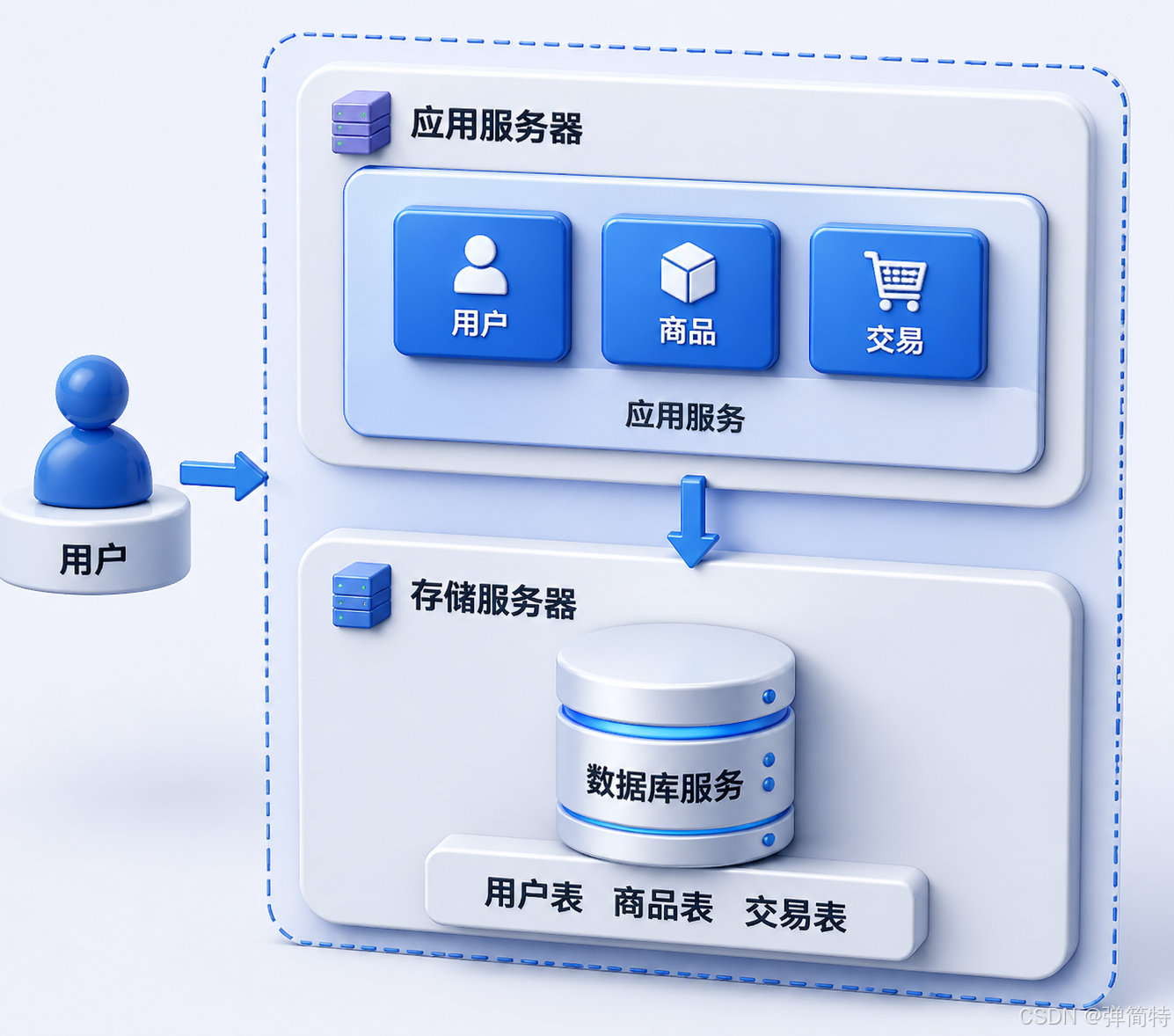
- 上面:只部署应用服务
- 下面:只部署数据库服务(比如 MySQL)
之前:一份资源两个人抢 → 现在:各用各的,不打架 🥊
而且可以根据不同服务的特性,配置不同的硬件:
- 应用服务器 → 吃 CPU 和内存 → 配高频 CPU、大内存
- 数据库服务器 → 需要大存储、快速 I/O → 配大容量 HDD / NVMe SSD
这样性价比更高 ✅
4、请求量继续涨?上应用服务器集群!
如果一台应用服务器还是顶不住(CPU/内存爆了),那就 再加几台应用服务器 👥
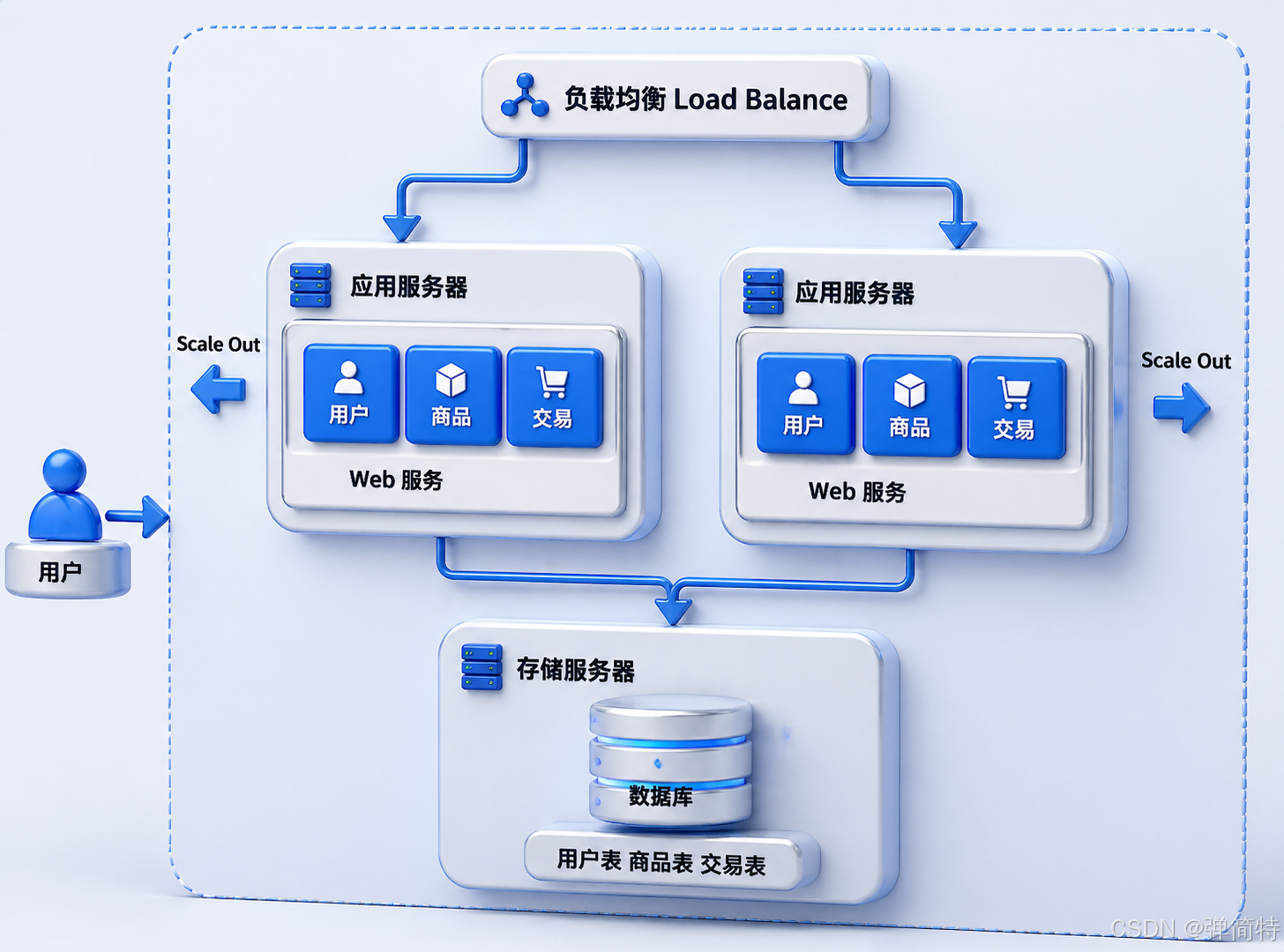
用户请求先到达 负载均衡器 (也叫网关),它把请求分发到多台应用服务器上。
例如:
- 2 台应用服务器,1 万用户请求 → 每台扛 5000
- 10 台应用服务器 → 每台扛 1000
这不就和 多线程 一个道理嘛 😏
5、负载均衡器:分配任务的"领导"
负载均衡器就像公司里的项目经理 🧑💼 ------ 来了任务,分给手下的码农。
最简单的分配算法:轮询(Round Robin)
- 第 1 个请求 → 服务器 A
- 第 2 个请求 → 服务器 B
- 第 3 个请求 → 服务器 C
- 循环往复 🔁
但轮询也有缺点:
如果同一个用户的多个请求被分到不同的服务器,可能会导致会话丢失 (比如登录状态没了)。
这时候可以用 IP Hash 等算法,让同一个 IP 的请求始终打到同一台服务器上 🧠
6、 理解负载均衡:领导永远比组员轻松?
刚才我们聊了:引入更多应用服务器 + 负载均衡器 → 请求压力被分摊了 ✅
但是灵魂拷问来了:负载均衡器自己不是要扛所有请求吗?它不会炸吗? 💣
别慌~ 负载均衡器的抗压能力远远高于应用服务器。为啥?
🧠 道理很简单:
- 负载均衡器 = 领导 👔 → 只负责"分配任务"(转发请求)
- 应用服务器 = 组员 🛠️ → 要真正"执行任务"(业务逻辑 + 数据库操作)
分配任务 花的时间 vs 执行任务 花的时间 ------ 谁更快?
当然是领导啦!领导动动嘴,组员跑断腿 🏃♂️
1) 万一连负载均衡器都扛不住了呢?
那就 再加负载均衡器 呗!
比如:引入多个机房,每个机房配自己的负载均衡器,把流量再分一层 🌍
总之,没有什么是加一层解决不了的,如果有,就再加一层(计算机界真理 😏)
7、 数据库读写分离:不能只让一个数据库背锅
应用服务器多了,负载均衡也稳了,但是 你看下图,只有一个数据库服务器
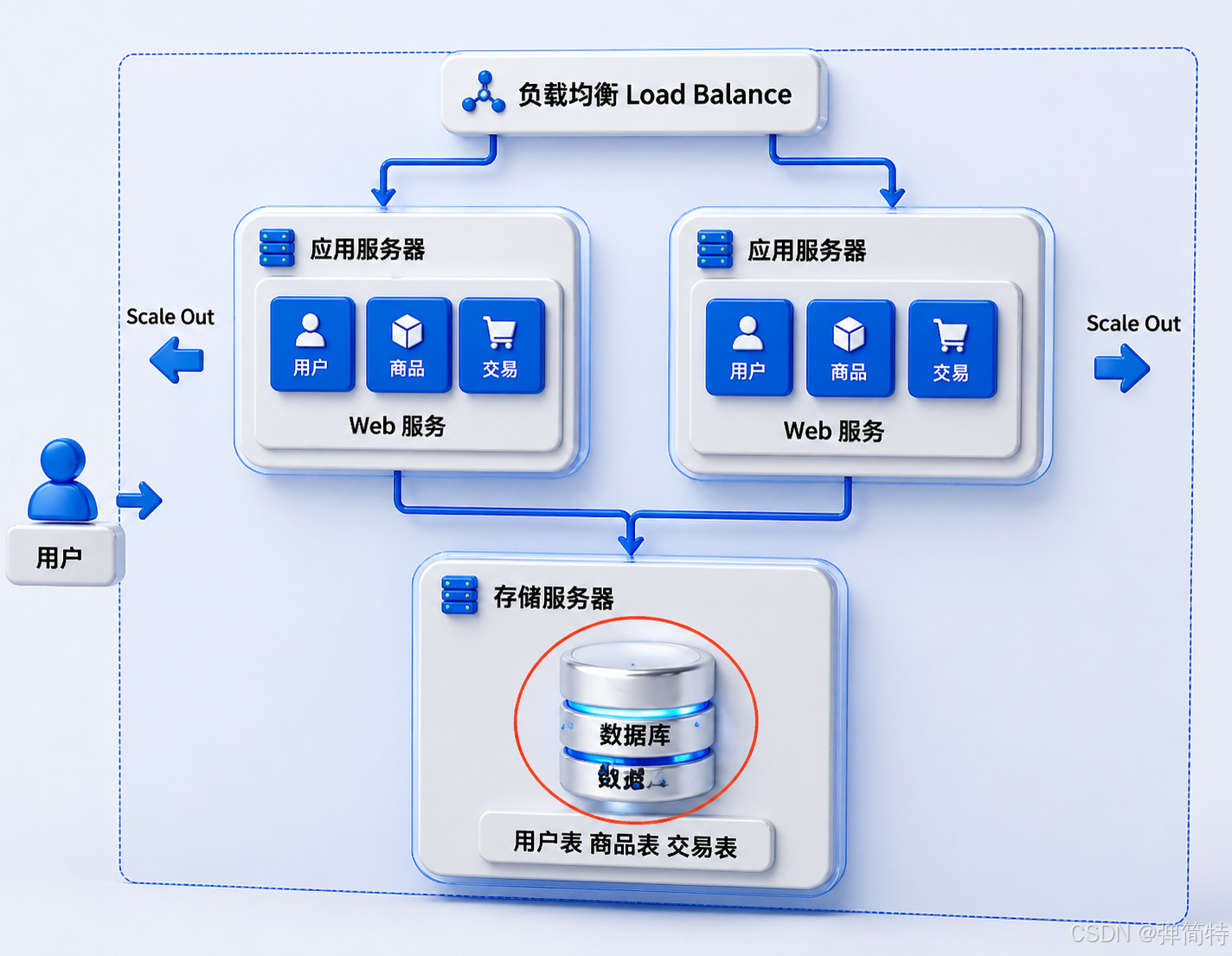
数据库服务器:就我一个??? 😨
应用服务器集群扛住了 1 万请求,结果这 1 万请求全怼到同一台数据库 上。
数据库这小身板,比应用服务器敏感多了,压力一大就直接躺平 🛌
咋办?还是那两招:开源 / 节流 。
节流太考研技术了,咱先开源 ------ 加机器!
1)读写分离(Master-Slave)
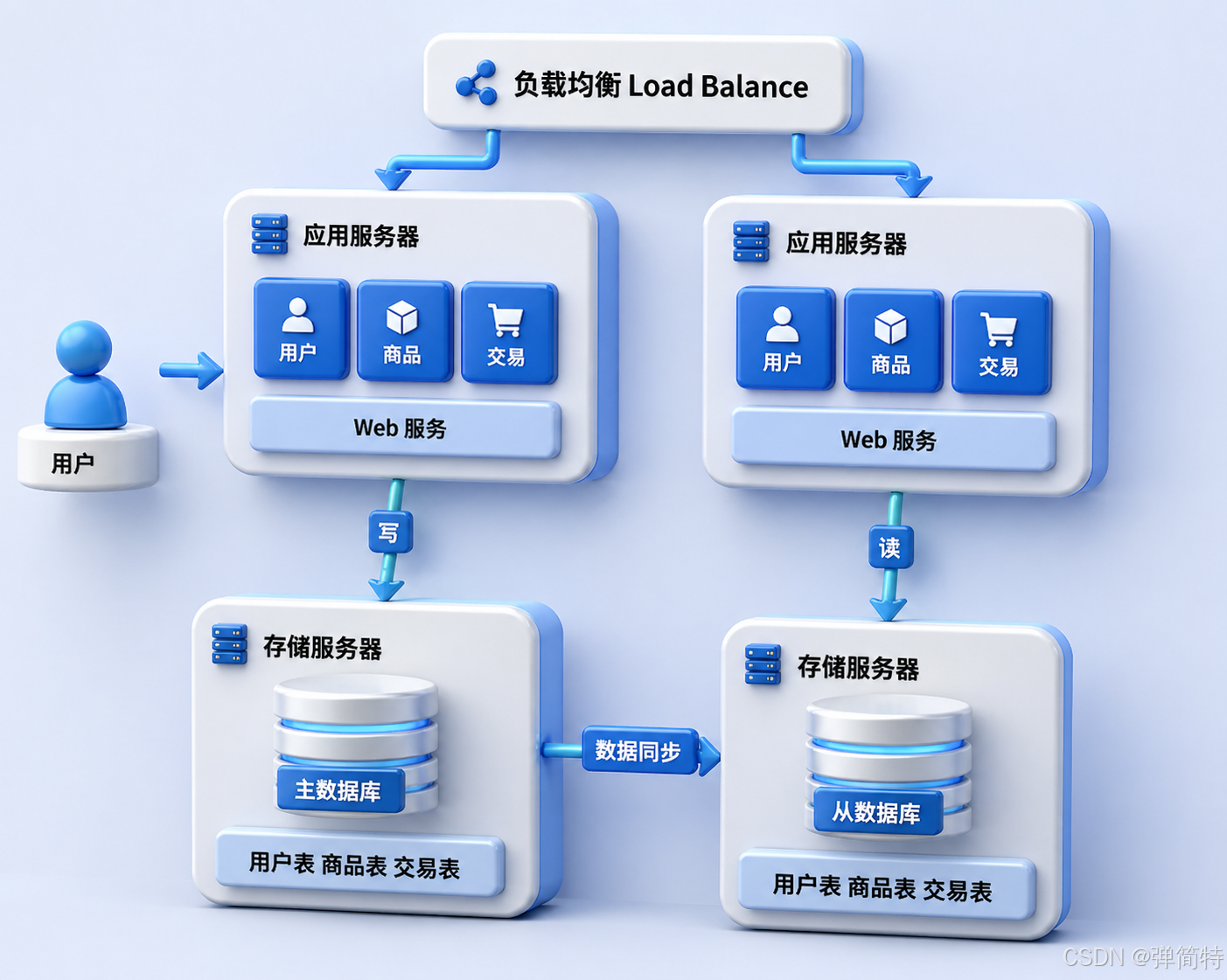
- 主库(Master):负责写操作(增、删、改)
- 从库(Slave):负责读操作(查)
应用服务器:
- 写数据 → 找 Master
- 读数据 → 找 Slave
Master 会实时/定期把数据同步给 Slave。
🎯 关键点:实际业务中,读的频率远高于写 。
所以一主多从,从库可以搞很多个,再用负载均衡分散读压力 ------ 美滋滋~
8、引入缓存:数据库太慢,我给它请个"外援"
读写分离解决了并发问题,但数据库终归要读硬盘,硬盘慢啊 🐢
为了进一步提高访问速度,我们把数据分成 冷数据 和 热数据:
- 热数据 :频繁访问的 → 放到 缓存(比如 Redis)
- 冷数据:不怎么访问的 → 继续留在数据库
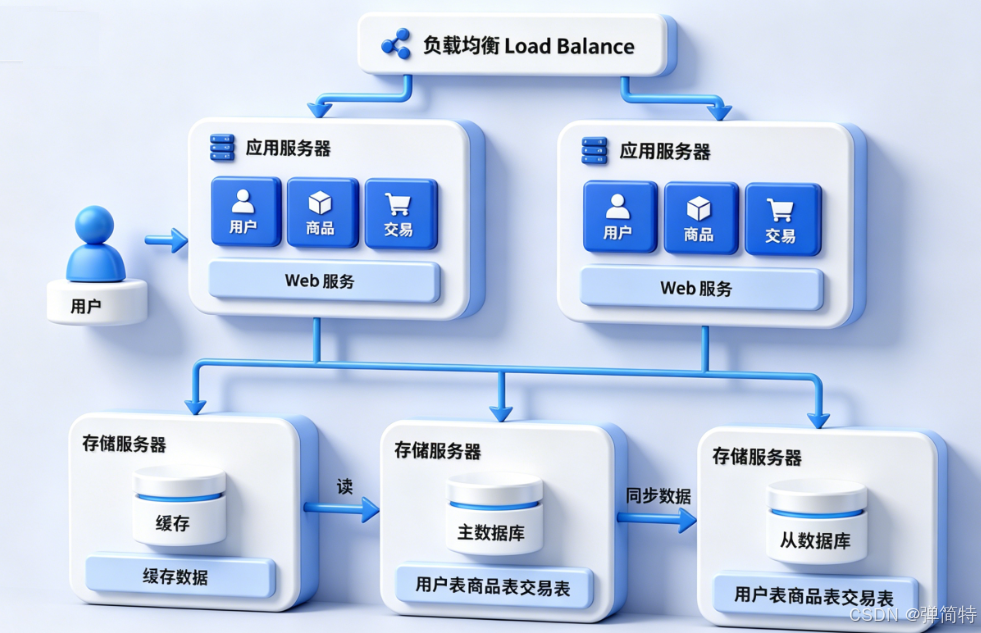
1)二八原则(帕累托定律)
20% 的热点数据,支撑了 80% 的访问量
极端情况下甚至 10% 的数据支撑 90% 的访问量
缓存的特点:快,但小 (内存贵啊)。
所以我们只把热点数据放到缓存里,数据库仍然保存全量数据。
Redis 就是干这个的 👑
应用服务器读数据时:
1️⃣ 先查缓存 ------ 有就直接返回 ✅
2️⃣ 缓存没有 ------ 再查数据库,顺便把结果写回缓存
数据库压力 ↓,整体速度 ↑,缓存帮数据库负重前行 💪
2) 缓存的一致性问题(经典坑)
如果用户修改了数据(比如把商品价格改了):
- 数据库更新了 ✅
- 缓存里还是旧数据 ❌
怎么办?这就涉及到 缓存和数据库的双写一致性问题 。
分布式系统的复杂度 就体现在这些地方。
解决办法后面会讲 ------ 先挖个坑 🕳️
想要飞一般的速度,就要承受对应的代价 💸
9、 数据库分库分表:数据太多,一台机器装不下
前面我们都在解决 高并发 问题。
但还有一个维度:海量数据 📦
一台数据库服务器,就算几十 TB,也可能不够用。
比如短视频平台 ------ 视频文件、用户记录...... 很快撑爆 💥
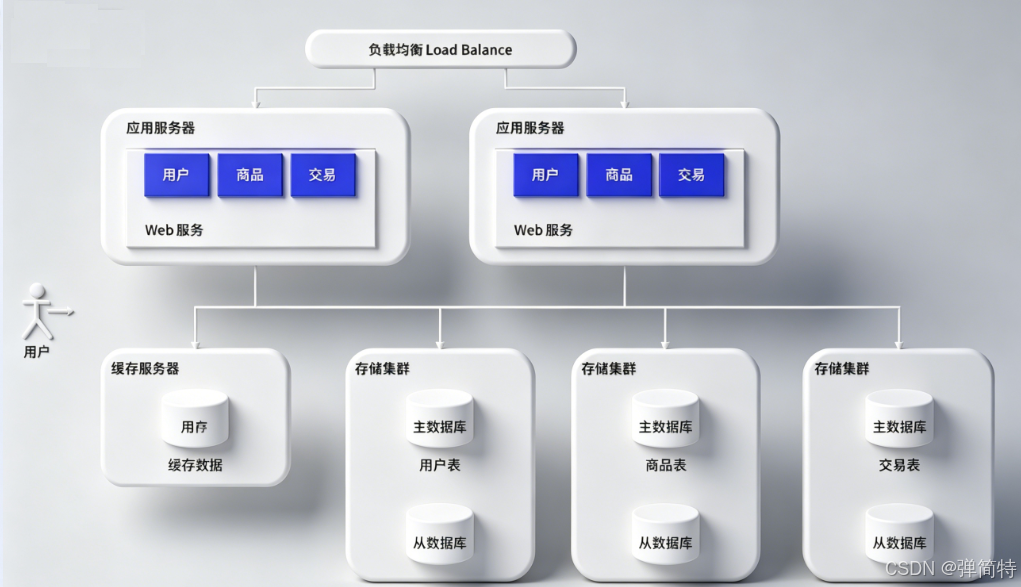
🔹 分库
原来一个数据库服务器上挂了 N 个库 → 拆成多个服务器,每个服务器放一个或几个库。
分库解决的是 数据量大 的问题,不是并发问题。
🔹 分表
如果某一张表特别巨大(比如订单表几百亿行),连一台机器都放不下 → 把这张表拆成多张表,放到不同服务器上。
具体怎么分,要根据业务场景来(比如按用户 ID 哈希、按时间范围等)。
这是 DBA 和架构师的必修课 📚
10、引入微服务:拆分应用服务器,解决"人的问题"
我们的分布式系统已经能扛高并发 + 海量数据了。
但应用服务器本身变成了一个巨无霸 ------ 代码几十万行,几十个人一起改,天天冲突 😫
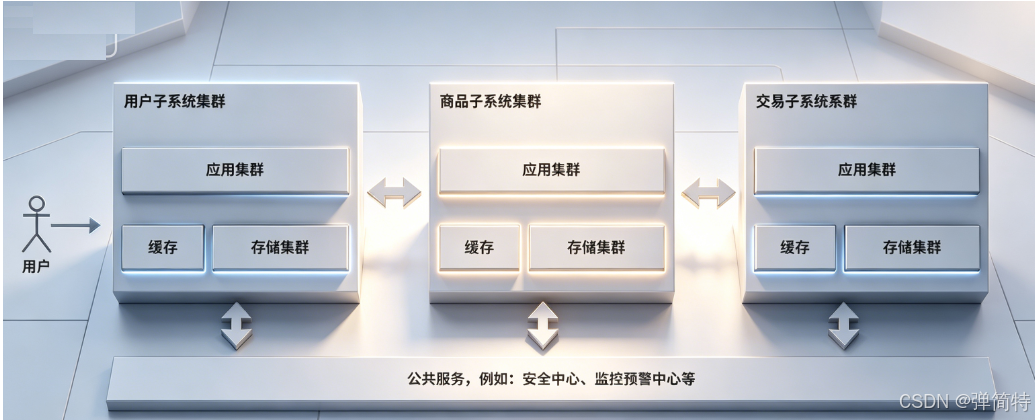
1) 微服务架构
把一个巨大的应用服务器,拆成多个功能单一、职责清晰的小服务器:
- 用户服务 👤
- 商品服务 📦
- 交易服务 💰
- 订单服务 📋
- ......
本质:用分布式系统解决团队协作问题 ------ 每个小团队维护自己的微服务,互不干扰 ✅
2)微服务的好处
- 解决人的问题:团队可以按服务拆分,各自独立开发、部署、扩容
- 功能复用:一个服务可以被多个上游调用
- 异构部署:不同服务可以用不同语言、不同数据库、不同硬件
3)微服务的代价
- 性能下降 :原本进程内调用,现在变成跨网络调用(网络比硬盘还慢!)
不过现在万兆网卡已经很猛了,能追上硬盘速度 🚀 - 复杂性爆炸:服务多了,出问题的概率指数级上升 → 需要监控、告警、链路追踪、熔断降级...
- 运维成本:得有一票 SRE 专门伺候这些服务 👨🔧
微服务不是银弹,中小公司慎用。大厂才玩得起这种"快乐" 😇
三、 补充:分布式系统常用名词解释
🧩 系统 / 应用
一组(或一个)服务器程序,共同完成某些功能。
🧩 模块 / 组件
一个应用内部的独立功能单元。
🌍 分布式
引入多个主机/服务器,协同完成工作。
👥 集群
逻辑上多个主机做同一件事。
有时候,分布式 和 集群 经常混用,不必太纠结~
👑 主从(Master-Slave)
一个主节点,多个从节点。从节点的数据从主节点同步过来。
读写分离就是典型的主从结构。
🧰 中间件
与业务无关 的通用服务:数据库、缓存、消息队列......
它们就像乐高积木,拿来就能用 🧱
四、分布式系统核心指标
1️⃣ 可用性(Availability)
系统正常运行时间 / 总时间
比如 99.9% 的可用性,一年宕机不超过 8.76 小时 ⏰
2️⃣ 响应时长(Response Time)
从发请求到收到响应的时间。
越小越快,但具体数值与业务场景强相关(查缓存 vs 跑机器学习模型,差远了)
3️⃣ 吞吐率 / 并发量(Throughput / Concurrency)
系统同时能处理多少请求。
这是衡量处理能力的核心指标,也是衡量性能的关键。
五、 总结一下我们的分布式演化之路🎬
| 阶段 | 做法 | 解决的问题 |
|---|---|---|
| 单机 | 一台服务器搞定一切 | 简单,够用 |
| 应用与数据库分离 | 分开部署,按需配硬件 | 资源不争抢,性价比高 |
| 应用服务器集群 + 负载均衡 | 多台应用服务器 + 负载均衡器 | 高并发(读/写) |
| 数据库读写分离 | 主写从读,一主多从 | 数据库压力分摊 |
| 引入缓存(Redis) | 热点数据放内存 | 加速读,减轻数据库压力 |
| 分库分表 | 数据拆到多个库/表/服务器 | 海量数据存储 |
| 微服务 | 应用拆成多个小服务 | 解决团队协作、功能复用 |
最后一句大实话 :
架构不是越复杂越好,而是够用就好 。
上分布式,往往是因为 单机真的扛不住了 ------ 不是因为你喜欢加班 🥲
如果觉得这篇有用,欢迎 点赞👍 + 收藏⭐ + 评论💬
小特正在努力学习Redis中~~