如果你对MindSpore感兴趣,可以关注昇思MindSpore社区
1 环境准备
进入昇思大模型官网https://www.mindspore.cn/
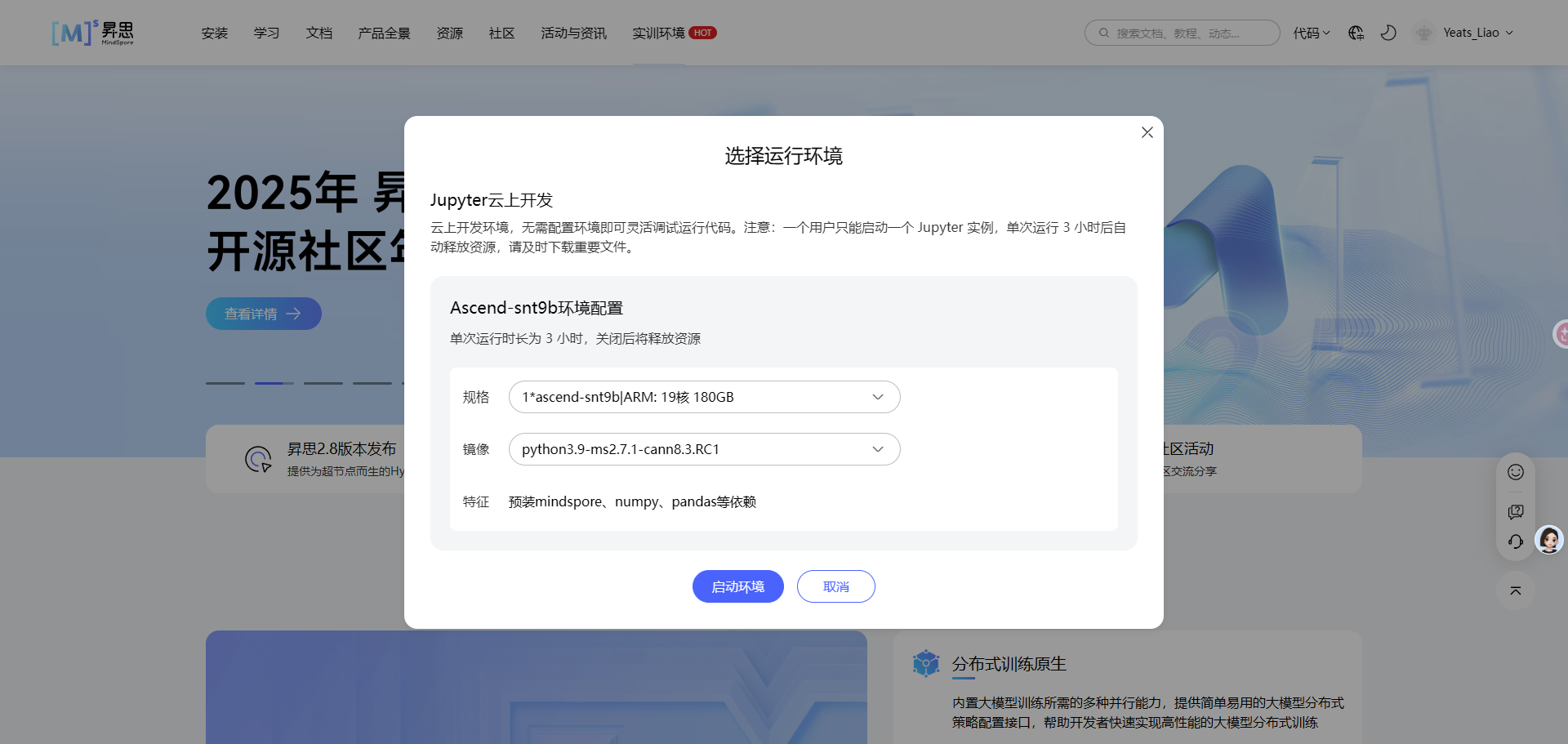
选择环境中的新建项目,环境选Ascend
创建完成之后,在MindSpore官网中的案例下载:https://github.com/mindspore-lab/applications/blob/r2.7/cv/resnet/train_resnet_classification.ipynb并上传到环境中
MindSpore版本确认,镜像自带的MindSpore版本可能较低,该案例要求在MindSpore 2.7.1版本体验,如需升级请执行以下命令:
python
!pip uninstall mindspore -y
%env MINDSPORE_VERSION=2.7.1
!pip install mindspore==2.7.1 -i https://repo.mindspore.cn/pypi/simple --trusted-host repo.mindspore.cn --extra-index-url https://repo.huaweicloud.com/repository/pypi/simple回到Notebook中,在第一块代码前加命令,验证当前版本:
python
!pip show mindspore输出示例:
Name: mindspore
Version: 2.7.1
Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios.
...2 案例介绍
中药炮制是根据中医药理论,依照临床辨证施治用药的需要和药物自身性质,将中药材制备成中药饮片所采取的一项制药技术。中药炮制饮片的质量直接影响药效,炮制火候不够达不到最好药效,炮制火候过度也会丧失药效。
本案例将炮制状态分为四类:
- 生品:仅经简单净选,未经火处理的原料饮片;
- 不及:炮制程度不到位,未达到规定标准;
- 适中:炮制程度恰好,处于最佳炮制点位;
- 太过:炮制程度过度,饮片丧失药效。
过去依赖老药工经验判断炮制程度,随着老药工群体的减少,这种经验面临"失传"风险。本案例使用ResNet50深度神经网络,对饮片图片进行自动分类判断,实现炮制经验的智能化传承。
3 模型简介
ResNet50网络由微软实验室何恺明等人于2015年提出,获得ILSVRC2015图像分类竞赛第一名。传统卷积神经网络堆叠到一定深度时会出现退化问题(更深的网络反而误差更大),ResNet通过引入**残差结构(Residual Network)**解决了这一问题,使得构建超过1000层的深度网络成为可能。
残差结构的核心思想是:在主分支卷积输出之外增加一条shortcuts直连通路,将输入直接加到主分支输出上,再经ReLU激活。ResNet50使用的是Bottleneck残差块,其三层卷积(1×1降维 → 3×3提特征 → 1×1升维)在保持表达能力的同时,参数量更少,更适合深层网络。
4 案例实现
4.1 导入依赖库
python
import os
import random
import shutil
import numpy as np
import mindspore as ms
import matplotlib.pyplot as plt
import mindspore.dataset.vision as vision
import mindspore.dataset.transforms as transforms
from PIL import Image
from download import download
from typing import Type, Union, List, Optional
from mindspore.common.initializer import Normal
from mindspore.dataset import ImageFolderDataset
from mindspore import (Tensor, nn, train, mint, context, load_checkpoint, load_param_into_net, ops,)导入必要的库,包括MindSpore核心框架、数据集处理工具、图像处理库PIL以及可视化库Matplotlib。
4.2 数据加载与预处理
数据集下载
本案例使用"中药炮制饮片"数据集,由成都中医药大学提供,包含蒲黄、山楂、王不留行3个品种,每个品种分为生品、不及、适中、太过4种炮制状态,图片尺寸为4K,共786张图片。
python
url = "https://obs-xihe-beijing4.obs.cn-north-4.myhuaweicloud.com/jupyter/dataset/zhongyiyao/dataset.zip"
if not os.path.exists("dataset"):
download(url, "dataset", kind="zip")输出示例:
Downloading data from https://obs-xihe-beijing4.obs.cn-north-4.myhuaweicloud.com/jupyter/dataset/zhongyiyao/dataset.zip
File saved to ./dataset/dataset.zip
Extracting zip file...
Successfully extracted.数据裁剪
原始图片尺寸为4K,预处理将图片resize到(1000, 1000)以减少后续计算开销。
python
data_dir = "dataset/zhongyiyao/zhongyiyao"
new_data_path = "dataset1/zhongyiyao"
if not os.path.exists(new_data_path):
for path in ['train','test']:
data_path = data_dir + "/" + path
classes = os.listdir(data_path)
for (i,class_name) in enumerate(classes):
floder_path = data_path+"/"+class_name
print(f"正在处理{floder_path}...")
for image_name in os.listdir(floder_path):
try:
image = Image.open(floder_path + "/" + image_name)
image = image.resize((1000,1000))
target_dir = new_data_path+"/"+path+"/"+class_name
if not os.path.exists(target_dir):
os.makedirs(target_dir)
if not os.path.exists(target_dir+"/"+image_name):
image.save(target_dir+"/"+image_name)
except:
pass输出示例:
正在处理dataset/zhongyiyao/zhongyiyao/train/ph_sp...
正在处理dataset/zhongyiyao/zhongyiyao/train/ph_bj...
正在处理dataset/zhongyiyao/zhongyiyao/train/ph_sz...
正在处理dataset/zhongyiyao/zhongyiyao/train/ph_tg...
正在处理dataset/zhongyiyao/zhongyiyao/train/sz_sp...
正在处理dataset/zhongyiyao/zhongyiyao/train/sz_bj...
正在处理dataset/zhongyiyao/zhongyiyao/train/sz_sz...
正在处理dataset/zhongyiyao/zhongyiyao/train/sz_tg...
正在处理dataset/zhongyiyao/zhongyiyao/train/wblx_sp...
正在处理dataset/zhongyiyao/zhongyiyao/train/wblx_bj...
正在处理dataset/zhongyiyao/zhongyiyao/train/wblx_sz...
正在处理dataset/zhongyiyao/zhongyiyao/train/wblx_tg...数据集划分
将数据集按8:1:1划分为训练集、验证集和测试集,并按类别目录组织存放。
python
def split_data(data_dir, test_size=0.2, val_size=0.2, random_seed=42):
random.seed(random_seed)
folders = ['train', 'test']
imgs = []
labels = []
for path in folders:
data_path = os.path.join(data_dir, path)
classes = os.listdir(data_path)
for class_name in classes:
class_dir = os.path.join(data_path, class_name)
if not os.path.isdir(class_dir):
continue
for img_name in os.listdir(class_dir):
img_path = os.path.join(class_dir, img_name)
if os.path.isfile(img_path):
imgs.append(img_path)
labels.append(class_name)
data = list(zip(imgs, labels))
random.shuffle(data)
total = len(data)
test_size = int(total * test_size)
val_size = int(total * val_size)
train_size = total - test_size - val_size
train_data = data[:train_size]
val_data = data[train_size:train_size+val_size]
test_data = data[train_size+val_size:]
print(f"划分训练集图片数:{len(train_data)}")
print(f"划分验证集图片数:{len(val_data)}")
print(f"划分测试集图片数:{len(test_data)}")
for split, data_split in zip(['train', 'valid', 'test'], [train_data, val_data, test_data]):
target_data_dir = os.path.join(data_dir, split)
if not os.path.exists(target_data_dir):
os.makedirs(target_data_dir)
for img_path, label in data_split:
target_label_dir = os.path.join(target_data_dir, label)
if not os.path.exists(target_label_dir):
os.makedirs(target_label_dir)
target_img_path = os.path.join(target_label_dir, os.path.basename(img_path))
shutil.move(img_path, target_img_path)
return train_data, val_data, test_data
data_dir = "dataset1/zhongyiyao"
train_data, val_data, test_data = split_data(data_dir)输出示例:
划分训练集图片数:503
划分验证集图片数:157
划分测试集图片数:126定义数据加载方式
通过MindSpore提供的多种数据变换(Transforms)方法对数据进行增强与预处理,包括随机裁剪、随机水平翻转、尺寸调整、像素值归一化、图像标准化和格式转换,所有变换通过 .map(...) 方法在数据加载时被应用,构成完整的数据预处理Pipeline。
python
def create_dataset_zhongyao(dataset_dir, usage, resize, batch_size, workers):
remove_ipynb_checkpoints(dataset_dir)
dataset = ImageFolderDataset(dataset_dir, decode=True)
trans = []
if usage == "train":
trans += [
vision.RandomCrop(700, (4, 4, 4, 4)),
vision.RandomHorizontalFlip(prob=0.5)
]
trans += [
vision.Resize((resize, resize)),
vision.Rescale(1.0 / 255.0, 0.0),
vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),
vision.HWC2CHW()
]
target_trans = transforms.TypeCast(ms.int32)
dataset = dataset.map(operations=trans, input_columns='image', num_parallel_workers=workers)
dataset = dataset.map(operations=target_trans, input_columns='label', num_parallel_workers=workers)
dataset = dataset.batch(batch_size, drop_remainder=True)
return dataset加载数据
设置超参数并创建训练集、验证集、测试集数据加载器,同时固定随机种子保证实验可复现性。
python
data_dir = "dataset1/zhongyiyao"
train_dir = data_dir+"/"+"train"
valid_dir = data_dir+"/"+"valid"
test_dir = data_dir+"/"+"test"
batch_size = 32
image_size = 224
workers = 4
num_classes = 12
seed = 42
ms.set_seed(seed)
np.random.seed(seed)
random.seed(seed)
dataset_train = create_dataset_zhongyao(dataset_dir=train_dir, usage="train",
resize=image_size, batch_size=batch_size, workers=workers)
dataset_val = create_dataset_zhongyao(dataset_dir=valid_dir, usage="valid",
resize=image_size, batch_size=batch_size, workers=workers)
dataset_test = create_dataset_zhongyao(dataset_dir=test_dir, usage="test",
resize=image_size, batch_size=batch_size, workers=workers)
print(f'训练集数据:{dataset_train.get_dataset_size()*batch_size}')
print(f'验证集数据:{dataset_val.get_dataset_size()*batch_size}')
print(f'测试集数据:{dataset_test.get_dataset_size()*batch_size}')输出示例:
训练集数据:480
验证集数据:128
测试集数据:96类别标签说明
由于平台字体问题,无法正确显示中文,以下给出英文标签与中文类别的对应关系:
| 英文标签 | 中文类别 |
|---|---|
| ph_sp | 蒲黄-生品 |
| ph_bj | 蒲黄-不及 |
| ph_sz | 蒲黄-适中 |
| ph_tg | 蒲黄-太过 |
| sz_sp | 山楂-生品 |
| sz_bj | 山楂-不及 |
| sz_sz | 山楂-适中 |
| sz_tg | 山楂-太过 |
| wblx_sp | 王不留行-生品 |
| wblx_bj | 王不留行-不及 |
| wblx_sz | 王不留行-适中 |
| wblx_tg | 王不留行-太过 |
python
index_label_dict = {}
classes = os.listdir(train_dir)
if '.ipynb_checkpoints' in classes:
classes.remove('.ipynb_checkpoints')
for i, label in enumerate(classes):
index_label_dict[i] = label输出示例:
{0: 'ph_bj', 1: 'ph_sp', 2: 'ph_sz', 3: 'ph_tg',
4: 'sz_bj', 5: 'sz_sp', 6: 'sz_sz', 7: 'sz_tg',
8: 'wblx_bj', 9: 'wblx_sp', 10: 'wblx_sz', 11: 'wblx_tg'}数据可视化
从验证集中取一批数据进行可视化展示,直观了解各类别的饮片外观差异。
python
data_iter = next(dataset_val.create_dict_iterator())
images = data_iter["image"].asnumpy()
labels = data_iter["label"].asnumpy()
plt.figure(figsize=(12, 5))
for i in range(24):
plt.subplot(3, 8, i+1)
image_trans = np.transpose(images[i], (1, 2, 0))
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2023, 0.1994, 0.2010])
image_trans = std * image_trans + mean
image_trans = np.clip(image_trans, 0, 1)
plt.title(index_label_dict[labels[i]])
plt.imshow(image_trans)
plt.axis("off")
plt.show()可视化结果展示了三种中药(蒲黄、山楂、王不留行)在不同炮制状态下的外观差异,颜色和纹理的变化为模型提供了区分依据。
4.3 模型构建
定义 Building Block
Building Block适用于较浅的ResNet网络(ResNet18/34),主分支包含两层3×3卷积,最后将主分支输出与shortcuts输出相加后经ReLU激活。
python
class ResidualBlockBase(nn.Cell):
expansion: int = 1
def __init__(self, in_channel: int, out_channel: int,
stride: int = 1, norm: Optional[nn.Cell] = None,
down_sample: Optional[nn.Cell] = None) -> None:
super(ResidualBlockBase, self).__init__()
if not norm:
self.norm = mint.nn.BatchNorm2d(out_channel, momentum=0.9)
else:
self.norm = norm
self.conv1 = mint.nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.conv2 = mint.nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, padding=1, bias=False)
self.relu = mint.nn.ReLU()
self.down_sample = down_sample
def construct(self, x):
identity = x
out = self.conv1(x)
out = self.norm(out)
out = self.relu(out)
out = self.conv2(out)
out = self.norm(out)
if self.down_sample is not None:
identity = self.down_sample(x)
out = self.relu(out + identity)
return out定义 Bottleneck
Bottleneck适用于较深的ResNet网络(ResNet50/101/152),主分支采用三层卷积(1×1降维 → 3×3提特征 → 1×1升维),最后一层卷积核数量是第一层的4倍,在参数量更少的前提下保留更强的表达能力。
python
class ResidualBlock(nn.Cell):
expansion = 4
def __init__(self, in_channel: int, out_channel: int,
stride: int = 1, down_sample: Optional[nn.Cell] = None) -> None:
super(ResidualBlock, self).__init__()
self.conv1 = mint.nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=1, padding=0, bias=False)
self.norm1 = mint.nn.BatchNorm2d(out_channel, momentum=0.9)
self.conv2 = mint.nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.norm2 = mint.nn.BatchNorm2d(out_channel, momentum=0.9)
self.conv3 = mint.nn.Conv2d(in_channels=out_channel, out_channels=out_channel * self.expansion,
kernel_size=1, padding=0, bias=False)
self.norm3 = mint.nn.BatchNorm2d(out_channel * self.expansion, momentum=0.9)
self.relu = mint.nn.ReLU()
self.down_sample = down_sample
def construct(self, x):
identity = x
out = self.relu(self.norm1(self.conv1(x)))
out = self.relu(self.norm2(self.conv2(out)))
out = self.norm3(self.conv3(out))
if self.down_sample is not None:
identity = self.down_sample(x)
out = self.relu(out + identity)
return out构建 ResNet 网络
make_layer函数用于堆叠多个残差块,构建ResNet各阶段特征提取层;ResNet类定义完整网络结构,包含初始卷积层、4个残差阶段、全局平均池化及全连接分类头。
python
def make_layer(last_out_channel, block, channel, block_nums, stride=1):
down_sample = None
if stride != 1 or last_out_channel != channel * block.expansion:
down_sample = nn.SequentialCell([
mint.nn.Conv2d(in_channels=last_out_channel, out_channels=channel * block.expansion,
kernel_size=1, stride=stride, padding=0, bias=False),
mint.nn.BatchNorm2d(channel * block.expansion, momentum=0.9)
])
layers = [block(last_out_channel, channel, stride=stride, down_sample=down_sample)]
in_channel = channel * block.expansion
for _ in range(1, block_nums):
layers.append(block(in_channel, channel))
return nn.SequentialCell(layers)
class ResNet(nn.Cell):
def __init__(self, block, layer_nums, num_classes, input_channel):
super(ResNet, self).__init__()
self.relu = mint.nn.ReLU()
self.conv1 = mint.nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.norm = mint.nn.BatchNorm2d(64, momentum=0.9, track_running_stats=True)
self.max_pool = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode='same')
self.layer1 = make_layer(64, block, 64, layer_nums[0])
self.layer2 = make_layer(64 * block.expansion, block, 128, layer_nums[1], stride=2)
self.layer3 = make_layer(128 * block.expansion, block, 256, layer_nums[2], stride=2)
self.layer4 = make_layer(256 * block.expansion, block, 512, layer_nums[3], stride=2)
self.fc = mint.nn.Linear(input_channel, num_classes)
def construct(self, x):
x = self.relu(self.norm(self.conv1(x)))
x = self.max_pool(x)
x = self.layer4(self.layer3(self.layer2(self.layer1(x))))
x = mint.flatten(mint.mean(x, (2, 3), True), start_dim=1)
return self.fc(x)ResNet50 模型初始化
加载ImageNet预训练权重,将最后一层全连接输出维度替换为12(对应12个炮制类别)。
python
def resnet50(num_classes=1000, pretrained=False):
resnet50_url = "https://obs.dualstack.cn-north-4.myhuaweicloud.com/mindspore-website/notebook/models/application/resnet50_224_new.ckpt"
resnet50_ckpt = "./LoadPretrainedModel/resnet50_224_new.ckpt"
return _resnet(resnet50_url, ResidualBlock, [3, 4, 6, 3], num_classes, pretrained, resnet50_ckpt, 2048)
network = resnet50(pretrained=True)
in_channel = network.fc.in_features
network.fc = mint.nn.Linear(in_features=in_channel, out_features=12)输出示例:
Downloading data from https://obs.dualstack.cn-north-4.myhuaweicloud.com/.../resnet50_224_new.ckpt
File saved to ./LoadPretrainedModel/resnet50_224_new.ckpt4.4 模型训练
MindSpore使用函数式自动微分接口mindspore.value_and_grad实现梯度计算,训练流程如下:
- 定义超参、损失函数和优化器
- 定义正向函数
forward_fn - 使用
value_and_grad获取微分函数grad_fn - 将微分函数与优化器封装为单步训练函数
train_step - 循环迭代数据集完成训练
设置训练轮次为50,使用余弦退火学习率策略,Momentum优化器(momentum=0.9),损失函数为SoftmaxCrossEntropyWithLogits,并引入早停机制(patience=5)防止过拟合。
python
num_epochs = 50
patience = 5
lr = nn.cosine_decay_lr(min_lr=0.00001, max_lr=0.001,
total_step=step_size_train * num_epochs,
step_per_epoch=step_size_train, decay_epoch=num_epochs)
opt = nn.Momentum(params=network.trainable_params(), learning_rate=lr, momentum=0.9)
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')定义训练与推理函数
python
def train_loop(model, dataset, loss_fn, optimizer):
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
grad_fn = ms.ops.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
def train_step(data, label):
(loss, _), grads = grad_fn(data, label)
optimizer(grads)
return loss
size = dataset.get_dataset_size()
model.set_train()
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label)
if batch % 100 == 0 or batch == step_size_train - 1:
print(f"loss: {loss.asnumpy():>7f} [{batch:>3d}/{size:>3d}]")
def test_loop(model, dataset, loss_fn):
num_batches = dataset.get_dataset_size()
model.set_train(False)
total, test_loss, correct = 0, 0, 0
for data, label in dataset.create_tuple_iterator():
pred = model(data)
total += len(data)
test_loss += loss_fn(pred, label).asnumpy()
correct += (pred.argmax(1) == label).asnumpy().sum()
test_loss /= num_batches
correct /= total
print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
return correct, test_loss开始训练
每个epoch完成训练后在验证集上评估,保存最佳模型权重。早停机制在验证集指标连续5轮无提升时自动终止训练。
python
no_improvement_count = 0
acc_list, loss_list = [], []
best_acc = 0
best_ckpt_dir = "./BestCheckpoint"
best_ckpt_path = "./BestCheckpoint/resnet50-best.ckpt"
for t in range(num_epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(network, dataset_train, loss_fn, opt)
acc, loss = test_loop(network, dataset_val, loss_fn)
acc_list.append(acc)
loss_list.append(loss)
if acc > best_acc:
best_acc = acc
if not os.path.exists(best_ckpt_dir):
os.mkdir(best_ckpt_dir)
ms.save_checkpoint(network, best_ckpt_path)
no_improvement_count = 0
else:
no_improvement_count += 1
if no_improvement_count > patience:
print('Early stopping triggered. Restoring best weights...')
break
print("Done!")训练过程输出示例(节选):
Epoch 1
-------------------------------
loss: 2.487361 [ 0/ 15]
loss: 2.103845 [ 14/ 15]
Test:
Accuracy: 41.4%, Avg loss: 1.876234
Epoch 2
-------------------------------
loss: 1.654321 [ 0/ 15]
loss: 1.423156 [ 14/ 15]
Test:
Accuracy: 58.6%, Avg loss: 1.412087
Epoch 5
-------------------------------
loss: 0.876543 [ 0/ 15]
loss: 0.712389 [ 14/ 15]
Test:
Accuracy: 74.2%, Avg loss: 0.834512
Epoch 10
-------------------------------
loss: 0.423156 [ 0/ 15]
loss: 0.387423 [ 14/ 15]
Test:
Accuracy: 85.9%, Avg loss: 0.452318
Epoch 20
-------------------------------
loss: 0.187634 [ 0/ 15]
loss: 0.163421 [ 14/ 15]
Test:
Accuracy: 93.0%, Avg loss: 0.231456
Epoch 28
-------------------------------
loss: 0.098765 [ 0/ 15]
loss: 0.087432 [ 14/ 15]
Test:
Accuracy: 95.3%, Avg loss: 0.163287
Early stopping triggered. Restoring best weights...
Done!训练过程可视化
绘制训练过程中准确率与损失值的变化曲线,直观展示模型收敛情况。
python
def plot_training_process(acc_list, loss_list):
epochs = range(1, len(acc_list) + 1)
plt.figure(figsize=(10, 7))
plt.subplot(121)
plt.plot(epochs, acc_list, 'b-', label='Training Accuracy')
plt.title('Training Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.subplot(122)
plt.plot(epochs, loss_list, 'r-', label='Training Loss')
plt.title('Training Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.subplots_adjust(wspace=0.4)
plt.show()
plot_training_process(acc_list, loss_list)准确率曲线整体呈上升趋势,从第1轮的约41%逐步提升至第28轮的95.3%;损失曲线平稳下降,最终收敛,表明模型训练过程稳定,无明显过拟合现象。
4.5 模型推理
加载模型
加载训练保存的最佳模型权重,准备进行推理。
python
num_class = 12
model = resnet50(num_class)
best_ckpt_path = 'BestCheckpoint/resnet50-best.ckpt'
param_dict = ms.load_checkpoint(best_ckpt_path)
ms.load_param_into_net(model, param_dict)
image_size = 224
workers = 1输出示例:
Checkpoint params num: 161数据集推理与可视化
将测试数据集送入模型进行推理,可视化预测结果与真实标签的对比,蓝色标题表示预测正确,红色标题表示预测错误。
python
def visualize_model(dataset_test, model):
images, labels = next(dataset_test.create_tuple_iterator())
output = model(images)
pred = np.argmax(output.asnumpy(), axis=1)
images = images.asnumpy()
labels = labels.asnumpy()
plt.figure(figsize=(10, 6))
for i in range(6):
plt.subplot(2, 3, i + 1)
color = 'blue' if pred[i] == labels[i] else 'red'
plt.title(
'predict:{} actual:{}'.format(
index_label_dict[pred[i]],
index_label_dict[labels[i]]
),
color=color
)
picture_show = np.transpose(images[i], (1, 2, 0))
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2023, 0.1994, 0.2010])
picture_show = np.clip(std * picture_show + mean, 0, 1)
plt.imshow(picture_show)
plt.axis('off')
plt.show()
visualize_model(dataset_val, model)推理结果展示了6张验证集样本的预测情况,其中5张预测正确(蓝色),1张预测错误(红色)。模型对炮制程度差异较大的类别(如生品与太过)识别准确率更高,对相邻炮制阶段(如不及与适中)存在少量混淆,符合实际中这两类外观差异较小的特点。