文章目录
- 演练源码
- OpenSpec介绍(AI回答)
-
- OpenSpec是什么?
- OpenSpec和OpenCode是什么关系
- OpenSpec开发流程
- OpenSpec项目结构
-
- [**🧠 一、整体结构在干嘛**](#🧠 一、整体结构在干嘛)
- [**📄 二、每个文件详细作用(重点)**](#📄 二、每个文件详细作用(重点))
- [OpenSpec AI对话斜杠命令](#OpenSpec AI对话斜杠命令)
- OpenSpec/OpenCode安装
- openspec实战
演练源码
源码:https://github.com/joycode-bootcamp/executor-bootstrap
需求:https://github.com/joycode-bootcamp/sweeping-robot-requirements
演练过程代码仓:https://github.com/ShenXinda/executor-bootstrap
OpenSpec介绍(AI回答)
OpenSpec是什么?
OpenSpec既是一个开源的工作流框架与一套规则体系,也是一个命令行工具(CLI)。但你可能会接触到三种不同的 OpenSpec,这里可以帮你梳理得更清楚一些。
🧬 第一重:它是一个开源框架与规则集合
OpenSpec 首先是一个轻量级的、开源的规范驱动开发(Spec-Driven Development, SDD)框架。它的核心是"规范即代码",简单来说就是通过一套固定的目录结构和Markdown文件规则来工作:
它是一个方法论和规则集:框架定义了你与 AI 如何沟通协作的"标准流程",旨在解决 AI 编程中普遍存在的"需求偏移"或"代码幻觉"问题。
关键规则是 Markdown 文件:当你运行 openspec init 初始化项目后,它会创建一个 openspec/ 文件夹,其下包含 specs/ (当前系统规范)、changes/ (变更提案)、AGENTS.md (AI 工作指令) 等一系列 Markdown 文档,这些文档本身就是规则,用结构化语言清晰地记录了你的项目"应该是什么样"。
它是开源的:代码托管在 GitHub 上,任何人都可以查看和贡献。
它是与工具无关的规则系统:这种基于规则的特性使得它能被集成到 20 多种 AI 编程工具中,如 Claude Code、Cursor 等。
📦 第二重:它是帮助你实现这些规则的程序
OpenSpec 也是一个"打包"好的命令行工具(CLI)。它是一个用 Node.js 编写的、可以全局安装的程序(就像 git 一样),用来辅助你实施上面提到的这套规则流程。
这个工具主要帮你:
初始化和迁移:openspec init 为你项目生成上述的目录结构和规则文件。
状态查询:openspec list, openspec show 等命令可以查看当前项目规范。
质量保障:openspec validate 会自动检查你的规范文档是否符合规则,是确保质量的关键。
工作流管理:openspec archive 用于管理变更的归档。
🔀 第三重:它是 AI 上下文管理的一体化"枢纽"
此外,还存在一个由社区维护的变体 @menukfernando/openspec。
它专注于解决使用多个 AI 工具时的规则同步问题。它提供 openspec analyze 和 openspec sync 命令,分析你的项目并生成不同 AI 工具各自需要的规则格式,确保所有 AI 在同一个规则体系下工作。
OpenSpec和OpenCode是什么关系
🎯 角色定位:各司其职
📝 OpenSpec:规范驱动架构师
作为规范和框架,聚焦解决 AI 编程中的核心痛点------需求偏离和上下文丢失。核心理念是"先写规范,再写代码",通过强制在编码前创建提案(Proposal)→ 实施(Apply)→ 归档(Archive) 三阶段流程来固化共识。
🛠️ OpenCode:独立的 AI 编码引擎
作为具体的 AI 辅助工具,可以看作是模型中立的编码执行引擎。它能通过"斜杠命令"理解并严格遵循 OpenSpec 定义的规范与清单(tasks.md),并将代码实现、文档更新、测试编写等任务拆解执行,确保每次产出都与规范一致,构建可靠、可审计的开发流程。
🔗 核心关系:互补协作
OpenSpec 提供工作流框架,可与多种 AI 工具配合使用,而 OpenCode 凭借以下优势,成为其官方推荐的搭档之一:
原生支持:OpenSpec 中直接包含对 OpenCode 的原生斜杠命令支持。
配套生态:搭配 Oh-My-OpenCode 等插件可进一步编排为多智能体系统,并行处理复杂任务。
高度开放:模型中立性允许你接入不同的 AI 模型(如 OpenAI、Anthropic、本地模型等),本地化执行避免费用问题。
🧱 一个完整的AI开发"铁三角"
在更复杂的配置中,OpenCode 还会与另外两个开源工具一起配合,被社区称为 "AI 协作开发铁三角":
OpenSpec (规范层):扮演项目管理员角色,锁定需求共识,确保团队目标一致。
Superpowers (能力层)(可选):扮演任务指挥官角色,拆解和分配并行任务,强制 TDD 等软件工程实践。
Oh-My-OpenCode, OMO (基础设施层)(可选):扮演工具执行者/多智能体编排器角色,提供底层工具支持,实现多个 AI Agent 的并发协作。
OpenSpec开发流程
OpenSpec 的核心是"先定规范,再写代码"。它通过一个标准化的三阶段循环,将模糊的需求转化为结构化的行动,确保人与 AI 在编码前对齐目标,从而让 AI 的代码生成变得可靠、可预测且可追溯。
其核心开发流程是一个闭环:提案 → 实施 → 归档。
OpenSpec项目结构
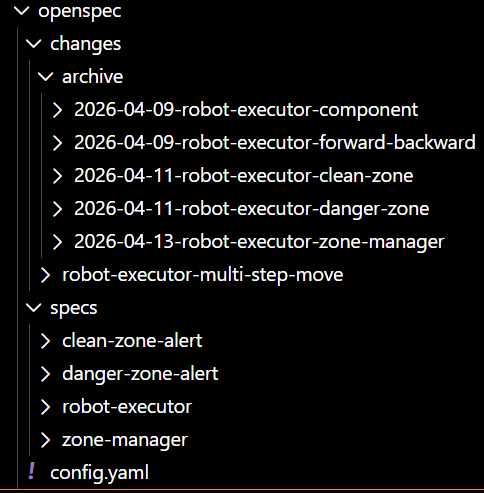
这个目录本质是三层结构:
openspec/
├── changes/ ← 变更历史(版本演进)
├── specs/ ← 当前"标准能力定义"(主干)
└── xxx-feature/ ← 实验/新功能(分支开发)
👉 可以理解为:
specs = 当前系统定义
changes = 过去怎么演进过
feature目录 = 正在开发的新能力
🧠 一、整体结构在干嘛
specs/robot-executor/
├── spec.md ← 核心规范(最重要)
design.md ← 技术设计
proposal.md ← 为什么要做
tasks.md ← 怎么落地
.openspec.yaml ← 配置/入口
👉 可以理解为:
一个功能从"想法 → 设计 → 规范 → 实现"的完整链路
📄 二、每个文件详细作用(重点)
1️⃣ spec.md(核心中的核心)
👉 这是 OpenSpec最关键的文件
里面定义的是:
• 系统要做什么(功能)
• 输入输出是什么
• 行为规则是什么
✳️ 典型内容:
• API定义(接口)
• 数据结构
• 行为描述
• 约束条件
✅ 作用:
• 给人看:理解系统
• 给机器用:生成代码 / 文档 / 测试
👉 一句话:
这是"可执行的说明书"
2️⃣ design.md(技术实现方案)
👉 这是"怎么实现 spec"
内容通常包括:
• 系统架构
• 模块划分
• 技术选型
• 数据流
✅ 作用:
• 给工程师用
• 指导 OpenCode 生成更合理的代码结构
👉 区别于 spec:
• spec = 做什么
• design = 怎么做
3️⃣ proposal.md(需求来源)
👉 这是"为什么要做这个东西"
内容一般是:
• 背景问题
• 使用场景
• 用户需求
• 目标
✅ 作用:
• 给产品/团队对齐认知
• 防止"做了个没用的功能"
👉 很多团队会忽略这个,但其实它决定方向
4️⃣ tasks.md(执行计划)
👉 这是"具体怎么落地"
内容:
• 开发任务拆分
• 优先级
• 步骤
• 里程碑
✅ 作用:
• 项目管理
• 可以被 AI 拆解执行(Agent 很常用)
5️⃣ .openspec.yaml(配置入口)
👉 这是整个系统的"控制文件"
一般定义:
• spec 文件路径
• 输出类型(文档 / 代码)
• 生成规则
• 工具配置
✅ 作用:
• 告诉 OpenCode:
👉 "去哪读 spec,生成什么"
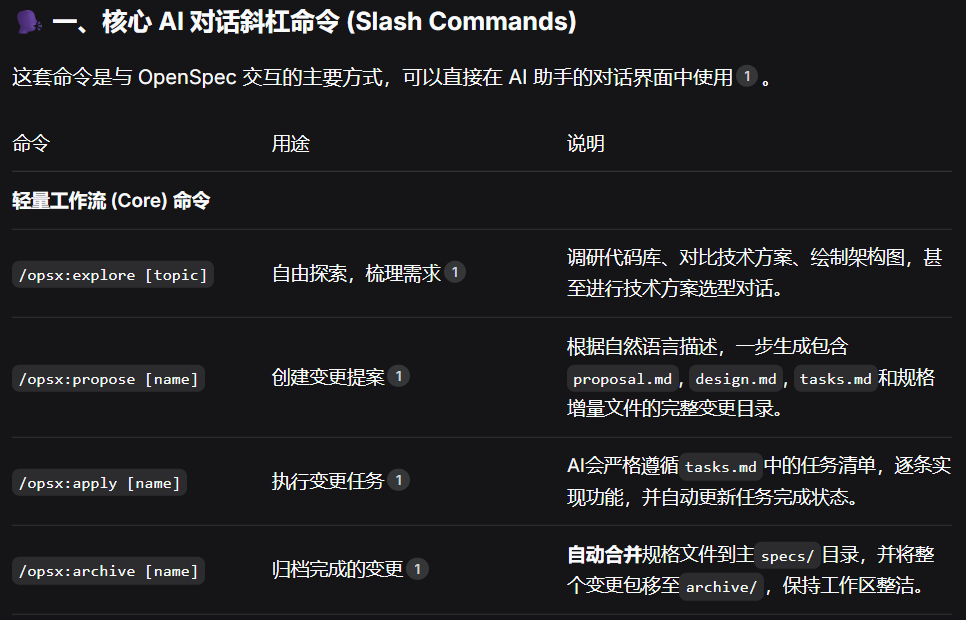
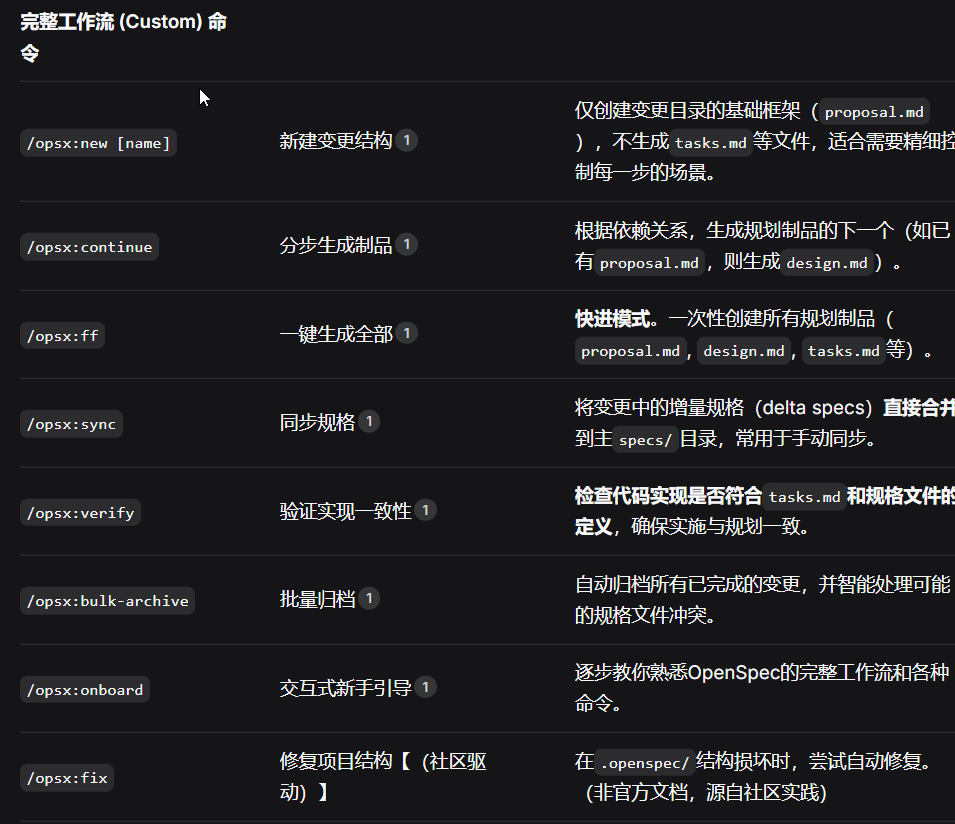
OpenSpec AI对话斜杠命令
OpenSpec/OpenCode安装
bash
# npm安装
sudo apt install npm
# opencode安装
npm install -g opencode-ai
# openspec安装
npm install -g @fission-ai/openspec@latest
# 创建项目目录,在项目目录下初始化openspec(空格键选择OpenCode作为AI编程助手)
mkdir executor-bootstrap && cd executor-bootstrap
openspec init # 初始化成功后,会在项目目录下创建 .openspec/ 和 .opencode/ 等目录
# 运行OpenCode(OpenCode配置AI模型以及使用使用技巧不在本文章详细介绍)
opencode
openspec实战
扫地机器人
提出需求
执行/opsx-propose 实现《扫地机器人-需求1.txt》需求描述中的功能,对需求有疑问可以停下来进行交流

在openspec/changes目录下会创建对应需求的
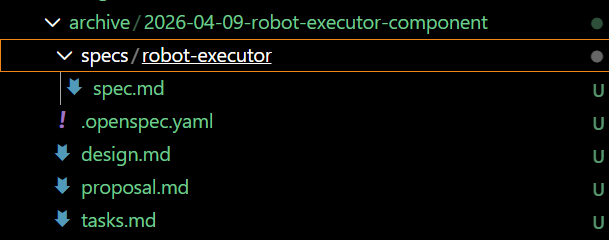
需求实现
注意:在需求实现前需要审视设计是否可以满足需求,如果不满足可以手动修改设计文档
执行/opsx-apply robot-executor-componen
任务会按照task.md的规划一步一步执行
需求归档
执行/opsx-archive robot-executor-forward-backward
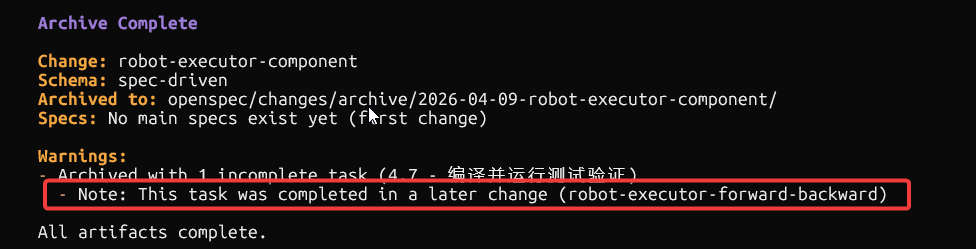
文档检查
完成robot-executor-multi-step-move需求后进行一次校验
执行openspec validate robot-executor-multi-step-move
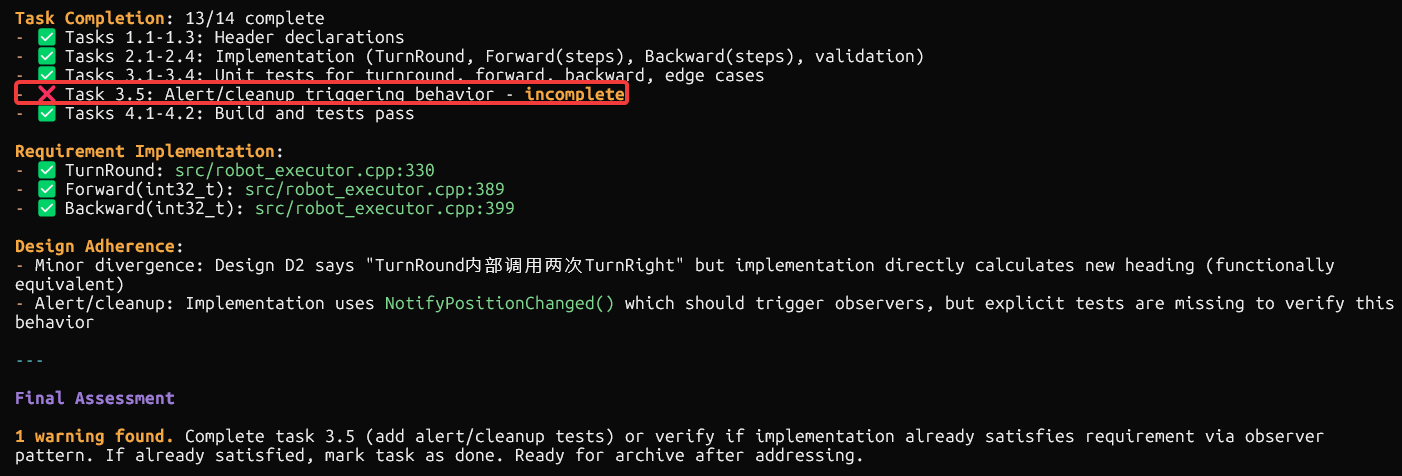
需求变更
- 用日常语言向 AI 描述你新的想法和调整点。
- 直接告诉 AI:"对于 add-user-profile 这个变更,我原来的想法有变化,......(此处描述新需求)。请据此更新相关的提案和规范文档。"
- AI 会理解你的意图,并自动编辑 proposal.md、tasks.md 和 spec.md 等文件。
探索模式
执行:/opsx-explore,然后进行对话交流
完成robot-executor-danger-zone需求后重构对话交流
第一次对话:
需求robot-executor-danger-zone完成后,代码存在以下问题:
判断危险点坐标并调用alert告警的代码在TurnRight、TurnLeft、Forward、Backward四个动作重复调用,存在多处分散修改问题
现在我们来探讨如何通过常见的设计模式优化代码的实现
约束条件:
1)RobotExecutor作为对外约定好的类,其接口不能改变,只能优化其内部实现逻辑
2)允许创建更多的类
第二次对话:
1、请将修改后得设计实现在opensec中的robot-executor-danger-zone更新需求文档,UML图使用paltuml语言;
2、请将DangerZoneObserver类的实现放在.cpp中,CleanZoneObserver类暂时还不需要,先删除
完成robot-executor-zone-manager需求后重构对话交流

第一次对话:
现在遇到了新的问题,如何改进现有代码:
1)使用了观察模式,告警坐标和打扫坐标点无法共享?
第二次对话:
我重新修改了下代码,请根据新修改的代码,请检查我重新修改的代码是否能满足需求的要求;如果可以满足,则重新刷新设计文档,并编写zone_manager_test.cpp中的测试用例,编译、运行通过;如果不满足,则我交流
openspec分层设计
根据现有的change,更新openspec/specs/