阻塞队列
- 什么是阻塞队列?
- BlockingQueue常用继承关系
-
- 声明关系
- [ArrayBlockingQueue ------ 有界数组结构](#ArrayBlockingQueue —— 有界数组结构)
- [LinkedBlockingQueue ------ 链表结构](#LinkedBlockingQueue —— 链表结构)
- [PriorityBlockingQueue ------ 优先级无界队列](#PriorityBlockingQueue —— 优先级无界队列)
- 📊全量并发队列对比表⭐
-
- [1. JDK 阻塞队列 - 适合生产者-消费者模式](#1. JDK 阻塞队列 - 适合生产者-消费者模式)
- [2. JDK 非阻塞队列 - 适合高并发轮询模式](#2. JDK 非阻塞队列 - 适合高并发轮询模式)
- [3. 框架级无锁队列 - 适合极致性能场景](#3. 框架级无锁队列 - 适合极致性能场景)
- [4. 补充:双端队列](#4. 补充:双端队列)
- BlockingQueue核心方法
- 手搓阻塞队列(泛型实现)
-
- MyBlockingQueue的成员变量与构造函数
- [MyBlockingQueue入队:put(T elem)](#MyBlockingQueue入队:put(T elem))
- MyBlockingQueue出队:take()
- 完整测试(生产者消费者模型)
- 生产者消费者模型
-
- 模型说明
- 代码实战
- 生产者消费者模型的优势
-
- [1. 解耦 (Decoupling)](#1. 解耦 (Decoupling))
- [2. 支持并发,提升效率 (Concurrency & Performance)](#2. 支持并发,提升效率 (Concurrency & Performance))
- [3. 削峰填谷 (Smoothing Traffic Spikes)](#3. 削峰填谷 (Smoothing Traffic Spikes))
- 生产者消费者模型的劣势
-
- [1. 增加系统复杂度](#1. 增加系统复杂度)
- [2. 潜在的性能开销](#2. 潜在的性能开销)
- [3. 存在延迟 (Latency)](#3. 存在延迟 (Latency))
- [4. 资源风险](#4. 资源风险)
在Java多线程编程中,生产者-消费者模式 是解耦数据处理最经典的解决方案。而java.util.concurrent包提供的阻塞队列(BlockingQueue),则是实现该模式的核心。
什么是阻塞队列?
阻塞队列是一种支持阻塞式插入和移除的线程安全队列。它具备两个典型特性:
- 当队列满时:生产者线程尝试插入元素会被阻塞,直到队列有可用空间。
- 当队列空时:消费者线程尝试移除元素会被阻塞,直到队列中有新元素。
这种特性使得它天然适合处理生产者和消费者速度不匹配的问题。
BlockingQueue常用继承关系
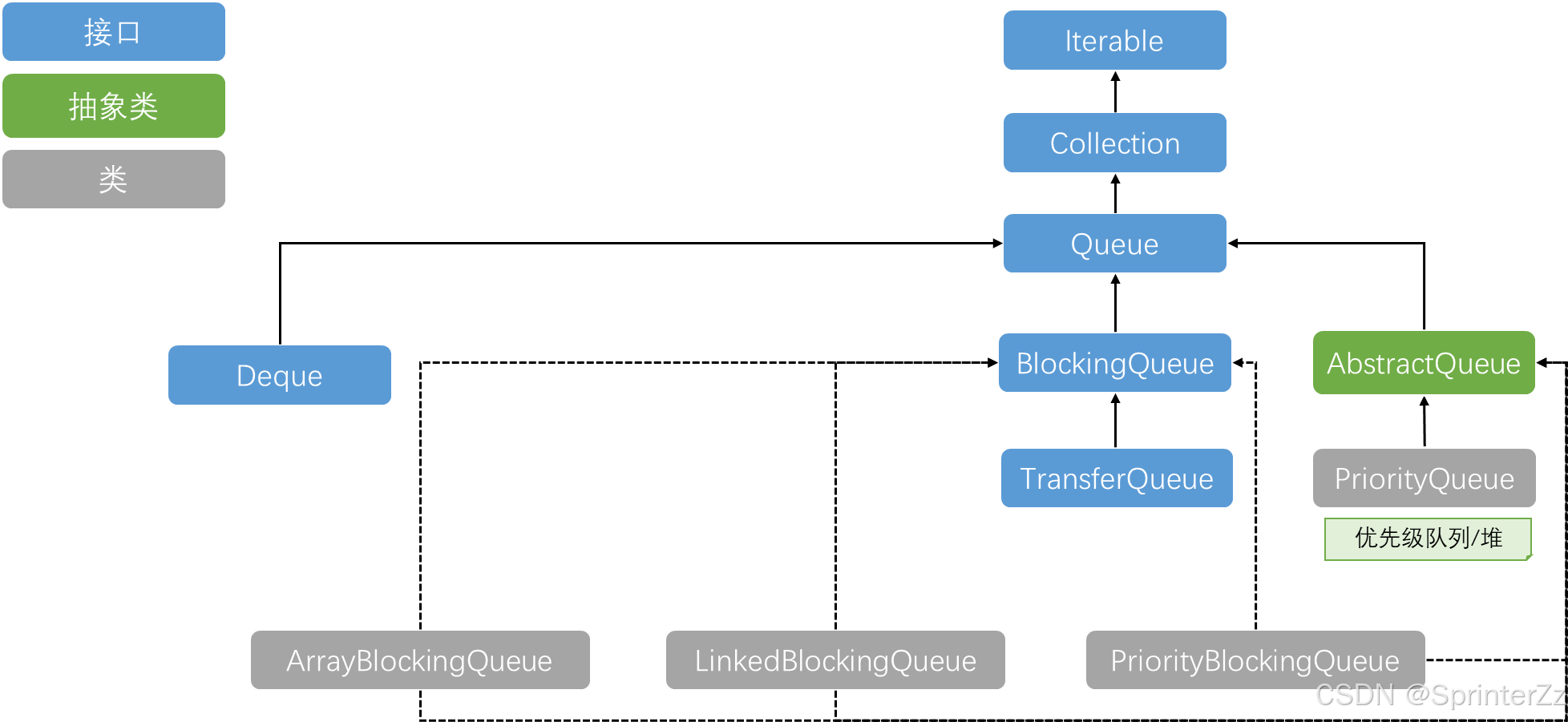
声明关系
java
// Queue --- 最顶层的队列接口
public interface Queue<E> extends Collection<E> { }
// AbstractQueue --- Queue 的骨架抽象实现
public abstract class AbstractQueue<E> extends AbstractCollection<E>
implements Queue<E> { }
// BlockingQueue --- 继承 Queue,增加阻塞操作
public interface BlockingQueue<E> extends Queue<E> { }
// 三个实现类:继承 AbstractQueue 骨架,实现 BlockingQueue 契约
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, Serializable { }
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, Serializable { }
public class PriorityBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, Serializable { }ArrayBlockingQueue ------ 有界数组结构
- 内部结构 :基于循环数组 + 一把
ReentrantLock+ 两个Condition(notEmpty、notFull)。 - 特点:有界且容量固定,支持公平/非公平锁(默认非公平)。
- 适用:生产消费速度较为均衡、对内存限制严格的场景。
java
BlockingQueue<String> queue = new ArrayBlockingQueue<>(100, true); // 公平模式LinkedBlockingQueue ------ 链表结构
- 内部结构:基于单向链表 + 两把锁(putLock / takeLock)分离。
- 特点 :理论上无界(默认
Integer.MAX_VALUE),吞吐量高于ArrayBlockingQueue。 - 注意:若不设置容量,可能因生产者过快导致内存溢出。
java
BlockingQueue<String> queue = new LinkedBlockingQueue<>(1000);PriorityBlockingQueue ------ 优先级无界队列
- 特点 :按元素优先级出队(自然排序或自定义
Comparator),无界但可能OOM。 - 适用:任务调度、医疗分诊等需按优先级处理的场景。
java
BlockingQueue<Task> queue = new PriorityBlockingQueue<>(11,
(t1, t2) -> t2.getPriority() - t1.getPriority());📊全量并发队列对比表⭐
| 队列名称 | 数据结构 | 吞吐量 | 有界性 | 锁机制 | 排序特性 | 典型适用场景 |
|---|---|---|---|---|---|---|
| ArrayBlockingQueue | 数组 | 中 | 严格有界 | 单锁(不分离) | FIFO | 资源受控、内存严格限制、防止OOM的生产消费模型 |
| LinkedBlockingQueue | 链表 | 高 | 可选有界(默认Integer.MAX) | 双锁(锁分离) | FIFO | 高吞吐、基于链表的容量可控生产消费(如线程池默认任务队列) |
| SynchronousQueue | 无内部容器 | 极高 | 严格为0(无容量) | CAS/自旋 | 无 | 任务直传、 Executors.newCachedThreadPool() 的核心实现 |
| DelayQueue | 堆 | 中 | 无界 | 单锁(锁分离) | 按延迟时间排序 | 延迟任务调度、定时重试机制、缓存过期淘汰 |
| PriorityBlockingQueue | 堆 | 中 | 无界 | 单锁(锁分离) | 按优先级排序 | 优先级任务调度、带权重的数据处理、动态Top-N |
| LinkedTransferQueue | 链表 | 极高 | 无界 | 无锁(CAS) | FIFO | 极高并发下的直接交接、替代SynchronousQueue提升吞吐 |
| LinkedBlockingDeque | 双向链表 | 高 | 可选有界 | 双锁(锁分离) | FIFO | 工作窃取算法、消费者既可以是生产者也可以是消费者的场景 |
| ConcurrentLinkedQueue | 链表 | 极高 | 无界 | 无锁(CAS) | FIFO | 高并发非阻塞场景、对吞吐量要求极高且不需要阻塞等待的场景 |
| Disruptor (RingBuffer) | 环形数组 | 极致 | 严格有界 | 无锁(序号栅栏) | 按序发布 | 金融交易系统、超低延迟事件驱动架构(非JDK内置) |
| Netty MpscQueue | 环形数组 | 极高 | 严格有界 | 无锁(CAS) | FIFO | Netty EventLoop任务分发、多生产者单消费者极致并发 |
1. JDK 阻塞队列 - 适合生产者-消费者模式
这类队列实现了 BlockingQueue 接口,当队列满时,put 操作会阻塞;当队列空时,take 操作会阻塞。
- ArrayBlockingQueue :利用环形数组实现。缺点 是插入和取出使用的是同一把
ReentrantLock,导致生产和消费无法真正并行,所以吞吐量只是"中等"。但它不产生额外对象,内存开销极小。 - LinkedBlockingQueue :利用单向链表实现。优点 是采用了"锁分离"技术(
putLock和takeLock两把锁),生产者和消费者可以完全并发执行,因此吞吐量"高"。注意 :如果不传初始容量,默认大小为Integer.MAX_VALUE,极易导致OOM。 - PriorityBlockingQueue :内部基于
PriorityHeap实现。允许插入null吗?不允许 。元素必须实现Comparable或在构造时传入Comparator。由于每次插入/取出都要堆化,吞吐量中等。 - DelayQueue :本质上是
PriorityBlockingQueue的封装,元素必须实现Delayed接口。只有元素的延迟时间到了,才能被take出来。常用于订单超时取消、心跳检测失败重连等。
2. JDK 非阻塞队列 - 适合高并发轮询模式
这类队列不实现阻塞方法,如果队列空了,取出操作直接返回 null,完全基于 CAS(Compare-And-Swap) 硬件级指令实现,没有锁的开销。
- ConcurrentLinkedQueue:Java非阻塞队列的标杆。基于链表,使用CAS自旋保证线程安全。在低到中等争用下性能无敌,但在极高争用下,CAS失败的自旋会导致CPU开销飙升。
- LinkedTransferQueue :这是一个"集大成者"。它结合了
SynchronousQueue和LinkedBlockingQueue的特点。如果有消费者在等待,直接把数据交给消费者(Transfer);如果没有,就放在队列里缓冲。完全无锁实现,极其复杂但也极其高效。
3. 框架级无锁队列 - 适合极致性能场景
当JDK自带的队列无法满足微秒级/纳秒级延迟要求时,通常需要引入第三方框架队列。
- Disruptor (LMAX) :号称世界上最快的队列。摒弃了链表,使用固定大小的环形数组(预分配内存,解决GC问题)。核心思想是"消除伪共享"(通过缓存行填充
@Contended)和"序列器栅栏"协调生产消费者。通常比LinkedBlockingQueue快 10 倍以上。 - Netty MpscQueue :
Mpsc全称 Multi-Producer Single-Consumer(多生产者单消费者)。Netty 为了解决 EventLoop 中的外部任务入队问题专门设计的。它也是环形数组,针对"多写一读"的场景做了极致的CAS优化,在Netty内部无处不在。
4. 补充:双端队列
- LinkedBlockingDeque :相比于普通 Queue 只能在队头出、队尾进,双端队列可以在两端 都进行插入和移除。这非常适合工作窃取模式。比如 ForkJoinPool 中,每个线程都有自己的双端队列,自己从头部拿任务执行,空闲的线程去"偷"其他线程队列尾部的任务,极大地提高了线程利用率。
⚙️ 选型总结
- 最稳妥的默认选择 :
LinkedBlockingQueue(记得指定容量,防OOM)。 - 内存极其敏感 :
ArrayBlockingQueue。 - 不要缓冲池,必须一手交钱一手交货 :
SynchronousQueue。 - 需要按时间/优先级处理 :
DelayQueue/PriorityBlockingQueue。 - 不需要阻塞等待,追求高并发读 :
ConcurrentLinkedQueue。 - 消费者也是生产者(工作窃取) :
LinkedBlockingDeque。 - 面临千万级TPS、延迟要求微秒级 :放弃JDK队列,直接上
Disruptor或Netty MpscQueue。
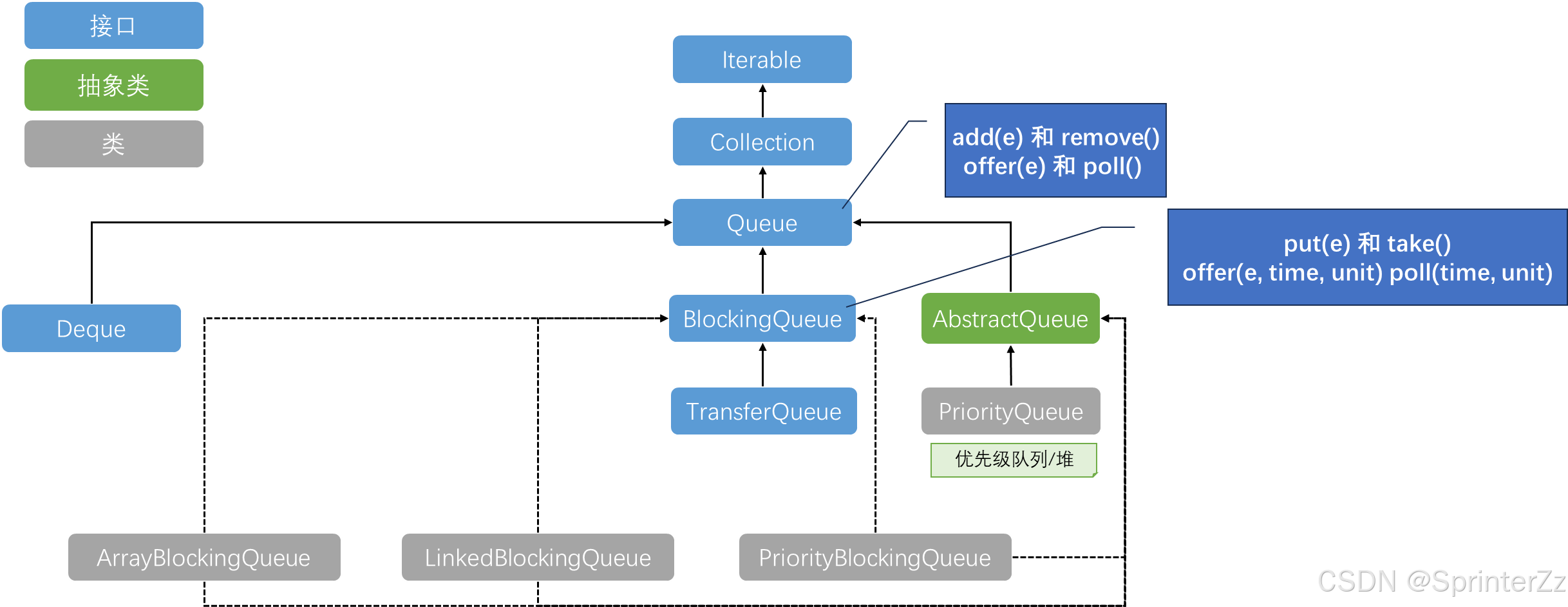
BlockingQueue核心方法
BlockingQueue提供了四种添加/移除元素的方法:异常、布尔值、阻塞、超时策略
| 抛出异常 | 返回特殊值 | 阻塞 | 超时退出 | |
|---|---|---|---|---|
| 插入 | add(e) |
offer(e) |
put(e) |
offer(e, time, unit) |
| 移除 | remove() |
poll() |
take() |
poll(time, unit) |
| 查看队列头部元素 | element() |
peek() |
无 | 无 |
- 抛出异常 :操作失败直接抛
IllegalStateException或NoSuchElementException。 - 返回特殊值 :插入返回
true/false,移除返回元素或null。 - 阻塞:操作未满足条件时线程阻塞。
- 超时退出 :阻塞一段时间后仍不满足则返回
false或null。
调用put()或take()时,务必妥善处理InterruptedException,不能只打印日志就吞掉异常,否则可能导致线程无法正确关闭。
java
try {
queue.take();
} catch (InterruptedException e) {
Thread.currentThread().interrupt(); // 重置中断标志
return;
}
java
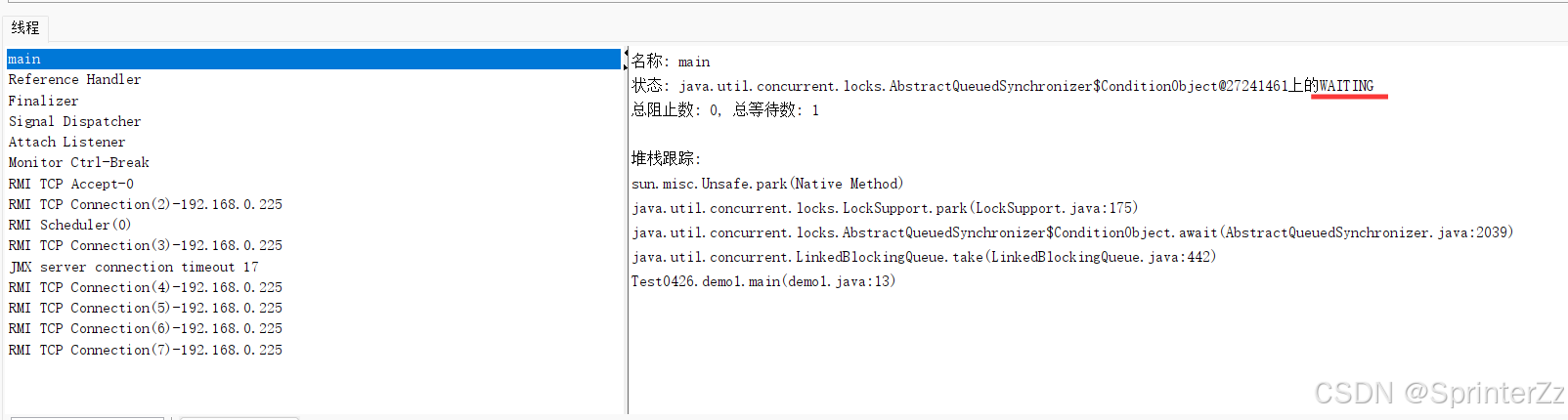
//take()示例
public static void main(String[] args) throws InterruptedException {
//创建了一个线程安全的LinkedBlockingQueue,用于存储字符串元素。
BlockingQueue<String> queue = new LinkedBlockingQueue<>();
// 使用take()方法从队列中获取并移除头元素。
// 如果队列为空,这个方法会阻塞(等待),直到有元素可用或线程被中断。
String elem = queue.take();
System.out.println(elem);
}没有任何输出结果,用jconsole可以看到main线程处于WAITING状态
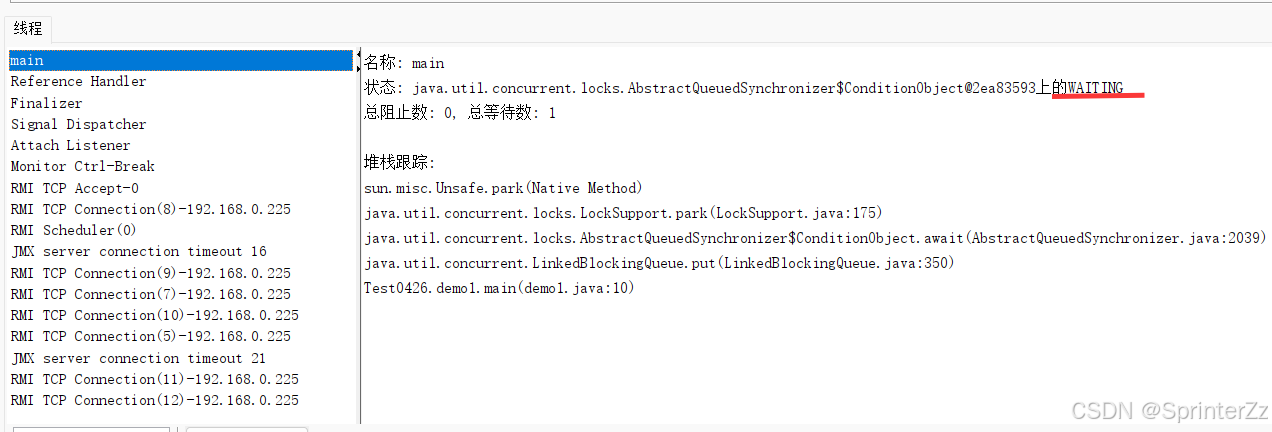
java
//put(e)示例
public static void main(String[] args)throws InterruptedException {
BlockingQueue<String> queue = new LinkedBlockingQueue<>(100);//最大容量100
for (int i=0;i<=100;i++){//加入101个元素
queue.put(String.valueOf(i));
}
System.out.println("插入元素结束");
}没有任何输出结果,用jconsole可以看到main线程处于WAITING状态
手搓阻塞队列(泛型实现)
MyBlockingQueue的成员变量与构造函数
java
public class MyBlockingQueue<T> {
// 使用泛型数组,初始化时需要强转
private T[] data = null;
// 队首索引
private int head = 0;
// 队尾索引
private int tail = 0;
// 当前元素个数
private int size = 0;
@SuppressWarnings("unchecked")
public MyBlockingQueue(int capacity) {
// 在 Java 中不能直接 new T[capacity],通常 new Object 数组再强转
data = (T[]) new Object[capacity];
}
}MyBlockingQueue入队:put(T elem)
java
public void put(T elem) throws InterruptedException {
synchronized (this) {
// 使用 while 循环检查,防止虚假唤醒 (Spurious Wakeup)
while (size >= data.length) {
// 队列满了,进入等待状态,释放锁
this.wait();
}
//入队
data[tail] = elem;
tail = (tail + 1) % data.length;
size++;
// 唤醒可能正在等待 take 的线程
this.notifyAll();
}
}| 机制 | 说明 |
|---|---|
synchronized |
保证对缓冲区的操作线程安全, size、head、tail 的修改不会乱套(原子性) |
wait() |
条件不满足时(满/空)让出锁并阻塞 |
notifyAll() |
唤醒所有等待线程,重新检查条件 |
while 循环 |
防止虚假唤醒,每次醒来都要重新判断条件 |
MyBlockingQueue出队:take()
java
public T take() throws InterruptedException {
synchronized (this) {
// 队列为空,进入等待状态
while (size == 0) {
this.wait();
}
//出队
T ret = data[head];
// 帮助 GC:取出元素后将原位置置为空(可选,但对于泛型对象是个好习惯)
data[head] = null;
head = (head + 1) % data.length;
size--;
// 唤醒可能正在等待 put 的线程
this.notifyAll();
return ret;
}
}| 机制 | 说明 |
|---|---|
synchronized |
保证对缓冲区的操作线程安全, size、head、tail 的修改不会乱套(原子性) |
wait() |
条件不满足时(满/空)让出锁并阻塞 |
notifyAll() |
唤醒所有等待线程,重新检查条件 |
while 循环 |
防止虚假唤醒,每次醒来都要重新判断条件 |
完整测试(生产者消费者模型)
java
/**
* 泛型阻塞队列实现
* @param <T> 队列中元素的类型
*/
public class MyBlockingQueue<T> {
// 使用泛型数组,初始化时需要强转
private T[] data = null;
// 队首索引
private int head = 0;
// 队尾索引
private int tail = 0;
// 当前元素个数
private int size = 0;
@SuppressWarnings("unchecked")
public MyBlockingQueue(int capacity) {
// 在 Java 中不能直接 new T[capacity],通常 new Object 数组再强转
data = (T[]) new Object[capacity];
}
/**
* 入队列
*/
public void put(T elem) throws InterruptedException {
synchronized (this) {
// 使用 while 循环检查,防止虚假唤醒 (Spurious Wakeup)
while (size >= data.length) {
// 队列满了,进入等待状态,释放锁
this.wait();
}
data[tail] = elem;
tail++;
// 环形结构处理:如果到达数组末尾,回到开头
if (tail >= data.length) {
tail = 0;
}
size++;
// 唤醒可能正在等待 take 的线程
this.notifyAll();
}
}
/**
* 出队列
*/
public T take() throws InterruptedException {
synchronized (this) {
// 队列为空,进入等待状态
while (size == 0) {
this.wait();
}
T ret = data[head];
// 帮助 GC:取出元素后将原位置置为空(可选,但对于泛型对象是个好习惯)
data[head] = null;
head++;
if (head >= data.length) {
head = 0;
}
size--;
// 唤醒可能正在等待 put 的线程
this.notifyAll();
return ret;
}
}
public static void main(String[] args) {
// 创建一个容量为 3 的阻塞队列
MyBlockingQueue<Integer> queue = new MyBlockingQueue<>(3);
// 消费者线程:每隔 1 秒取出一个元素
Thread customer = new Thread(() -> {
try {
while (true) {
int value = queue.take();
System.out.println("消费了元素: " + value);
Thread.sleep(1000); // 故意放慢消费速度,测试队列满的情况
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "消费者");
// 生产者线程:快速生产元素
Thread producer = new Thread(() -> {
try {
int count = 1;
while (true) {
System.out.println("准备生产元素: " + count);
queue.put(count);
System.out.println("生产成功: " + count);
count++;
// 生产速度很快,不休眠
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "生产者");
customer.start();
producer.start();
}
}生产者消费者模型
模型说明
- 生产者:不断生产数据,放入共享缓冲区
- 消费者:不断消费数据,从共享缓冲区取出
- 缓冲区:有大小限制,满则生产者等待,空则消费者等待
代码实战
java
/**
* 生产者-消费者模式演示
* 使用 BlockingQueue (阻塞队列) 实现多线程间的数据传递与解耦
*/
public class Demo {
// 定义一个"毒丸"元素,用于通知消费者安全退出
// 注意:LinkedBlockingQueue 不允许放入 null 值,所以用一个特殊对象作为结束标志
private static final Integer POISON_PILL = -1;
public static void main(String[] args) throws InterruptedException {
// 1. 创建一个容量为 5 的有界阻塞队列
BlockingQueue<Integer> queue = new LinkedBlockingQueue<>(5);
// 2. 定义生产者任务
// 扩充为多生产者,每个生产者内部维护自己的计数器,避免多线程共享变量导致的并发问题
Runnable producerTask = () -> {
String threadName = Thread.currentThread().getName();
int n = 0;
try {
// 每个生产者只生产 10 个元素
while (n < 10) {
// put() 方法:如果队列已满,当前线程会阻塞(挂起),直到队列有空位才放入
queue.put(n);
System.out.println("【" + threadName + "】 生产元素 >>> " + n);
n++;
// 稍微休眠,模拟生产耗时,让效果更明显
Thread.sleep((long) (Math.random() * 200));
}
System.out.println("【" + threadName + "】 生产完毕,退出。");
} catch (InterruptedException e) {
// 如果线程在阻塞时被中断,恢复中断标志并退出
Thread.currentThread().interrupt();
}
};
// 3. 定义消费者任务
Runnable consumerTask = () -> {
String threadName = Thread.currentThread().getName();
try {
while (true) {
// take() 方法:如果队列已空,当前线程会阻塞(挂起),直到队列有新元素才取出
Integer element = queue.take();
// 判断是否取到了"毒丸",如果是,则将毒丸放回队列(供其他消费者退出),然后自己退出
if (element.equals(POISON_PILL)) {
System.out.println("【" + threadName + "】 收到毒丸,准备安全退出...");
queue.put(POISON_PILL); // 把毒丸放回去,让其他消费者也能看到
break;
}
System.out.println(" <<<【" + threadName + "】 消费元素 " + element + " | 当前队列长度: " + queue.size());
// 模拟处理业务的耗时(消费速度慢于生产速度)
Thread.sleep(500);
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
};
// 4. 创建并启动 3 个生产者线程
Thread p1 = new Thread(producerTask, "生产者-1");
Thread p2 = new Thread(producerTask, "生产者-2");
Thread p3 = new Thread(producerTask, "生产者-3");
// 5. 创建并启动 2 个消费者线程
Thread c1 = new Thread(consumerTask, "消费者-A");
Thread c2 = new Thread(consumerTask, "消费者-B");
System.out.println("====== 开始生产消费流程 ======");
c1.start();
c2.start();
p1.start();
p2.start();
p3.start();
// 6. 优雅停机逻辑 (在主线程中执行)
// 等待所有生产者线程执行完毕
p1.join();
p2.join();
p3.join();
System.out.println("====== 所有生产者均已停止,准备投入毒丸 ======");
// 因为有 2 个消费者,所以需要向队列中放入 2 个"毒丸"
queue.put(POISON_PILL);
queue.put(POISON_PILL);
// 等待所有消费者线程执行完毕
c1.join();
c2.join();
System.out.println("====== 所有消费者均已停止,程序结束 ======");
}
}
text
====== 开始生产消费流程 ======
【生产者-2】 生产元素 >>> 0
【生产者-3】 生产元素 >>> 0
【生产者-1】 生产元素 >>> 0
<<<【消费者-B】 消费元素 0 | 当前队列长度: 1
<<<【消费者-A】 消费元素 0 | 当前队列长度: 1
【生产者-1】 生产元素 >>> 1
【生产者-1】 生产元素 >>> 2
【生产者-3】 生产元素 >>> 1
【生产者-2】 生产元素 >>> 1
<<<【消费者-B】 消费元素 1 | 当前队列长度: 3
<<<【消费者-A】 消费元素 0 | 当前队列长度: 3
【生产者-2】 生产元素 >>> 2
【生产者-1】 生产元素 >>> 3
【生产者-3】 生产元素 >>> 2
【生产者-2】 生产元素 >>> 3
<<<【消费者-B】 消费元素 2 | 当前队列长度: 4
<<<【消费者-A】 消费元素 1 | 当前队列长度: 4
【生产者-1】 生产元素 >>> 4
<<<【消费者-A】 消费元素 1 | 当前队列长度: 4
<<<【消费者-B】 消费元素 3 | 当前队列长度: 5
【生产者-2】 生产元素 >>> 4
<<<【消费者-A】 消费元素 2 | 当前队列长度: 3
【生产者-3】 生产元素 >>> 3
<<<【消费者-B】 消费元素 2 | 当前队列长度: 3
【生产者-2】 生产元素 >>> 5
<<<【消费者-B】 消费元素 3 | 当前队列长度: 4
【生产者-1】 生产元素 >>> 5
<<<【消费者-A】 消费元素 4 | 当前队列长度: 4
【生产者-2】 生产元素 >>> 6
<<<【消费者-A】 消费元素 4 | 当前队列长度: 4
【生产者-3】 生产元素 >>> 4
<<<【消费者-B】 消费元素 3 | 当前队列长度: 4
【生产者-2】 生产元素 >>> 7
<<<【消费者-B】 消费元素 5 | 当前队列长度: 4
【生产者-1】 生产元素 >>> 6
【生产者-3】 生产元素 >>> 5
<<<【消费者-A】 消费元素 5 | 当前队列长度: 5
<<<【消费者-B】 消费元素 6 | 当前队列长度: 4
【生产者-2】 生产元素 >>> 8
<<<【消费者-A】 消费元素 4 | 当前队列长度: 4
【生产者-1】 生产元素 >>> 7
<<<【消费者-A】 消费元素 7 | 当前队列长度: 4
【生产者-3】 生产元素 >>> 6
<<<【消费者-B】 消费元素 6 | 当前队列长度: 4
【生产者-1】 生产元素 >>> 8
<<<【消费者-A】 消费元素 5 | 当前队列长度: 4
【生产者-2】 生产元素 >>> 9
<<<【消费者-B】 消费元素 8 | 当前队列长度: 4
【生产者-3】 生产元素 >>> 7
【生产者-2】 生产完毕,退出。
<<<【消费者-B】 消费元素 7 | 当前队列长度: 4
【生产者-1】 生产元素 >>> 9
<<<【消费者-A】 消费元素 6 | 当前队列长度: 4
【生产者-3】 生产元素 >>> 8
【生产者-1】 生产完毕,退出。
<<<【消费者-B】 消费元素 8 | 当前队列长度: 4
【生产者-3】 生产元素 >>> 9
<<<【消费者-A】 消费元素 9 | 当前队列长度: 4
【生产者-3】 生产完毕,退出。
====== 所有生产者均已停止,准备投入毒丸 ======
<<<【消费者-A】 消费元素 7 | 当前队列长度: 4
<<<【消费者-B】 消费元素 9 | 当前队列长度: 4
<<<【消费者-A】 消费元素 8 | 当前队列长度: 3
<<<【消费者-B】 消费元素 9 | 当前队列长度: 2
【消费者-A】 收到毒丸,准备安全退出...
【消费者-B】 收到毒丸,准备安全退出...
====== 所有消费者均已停止,程序结束 ======生产者消费者模型的优势
1. 解耦 (Decoupling)
- 逻辑分离:生产者不需要知道消费者的存在,反之亦然。生产者只管往队列里塞数据,消费者只管从队列里拿数据。
- 代码维护:如果你想修改消费者的处理逻辑(比如从存入数据库改为发送到消息队列),完全不需要改动生产者的代码。
2. 支持并发,提升效率 (Concurrency & Performance)
- 异步处理:生产者生产完数据后可以立刻去生产下一个,不需要等待消费者处理完。
- 平衡差异:如果生产数据很快(比如读取传感器数据),而处理数据很慢(比如复杂的图像识别),该模型可以让多个消费者同时工作,利用多核 CPU 提高整体吞吐量。
3. 削峰填谷 (Smoothing Traffic Spikes)
- 缓冲作用:当遇到突发流量(比如秒杀活动)时,大量请求(生产者)涌入。如果没有缓冲区,系统可能会直接崩溃。
- 流量整形:阻塞队列像一个水库,把瞬间的高压挡住,让消费者按照自己稳定的节奏(水位)去慢慢处理,保证系统的稳定性。
生产者消费者模型的劣势
1. 增加系统复杂度
- 并发控制 :正如你写的
MyBlockingQueue所示,你需要处理锁(synchronized)、线程通信(wait/notify)以及虚假唤醒等底层细节。 - 容错处理:如果队列满了生产者该怎么办?如果队列空了消费者等多久?这些都需要额外的逻辑去处理。
2. 潜在的性能开销
- 锁竞争 (Lock Contention) :如果大量线程频繁操作同一个队列,
synchronized带来的锁竞争会成为性能瓶颈。 - 上下文切换 :线程的阻塞(
wait)和唤醒(notify)涉及到操作系统的内核态切换,频繁的切换会消耗不少 CPU 资源。
3. 存在延迟 (Latency)
- 数据不是直接从生产者传给消费者的,而是经过了内存中的队列中转。对于一些对时间极其敏感(微秒级延迟)的系统(如高频交易),这种中转带来的延迟可能是不可接受的。
4. 资源风险
- 内存溢出 (OOM):如果生产速度长期大于消费速度,且队列没有设置上限(无界队列),最终会导致内存耗尽。
- 数据丢失:如果消费者处理失败或系统崩溃,留在队列里的数据可能会丢失,需要额外的持久化机制来保障。