一、真实面经:栽在线程池这个坑里
上周朋友去字节面后端岗,上来就是一道场景题:线上接口超时频繁,报错堆在一起,你看了下日志发现大部分都卡在线程池队列满了拒绝请求,你会怎么优化?
朋友想了两分钟,回答说那把核心线程数调大一点,队列容量也改大一点,不就能装更多请求了 。面试官听完就笑了:你管这叫高并发优化?然后就没有然后了。
其实这真不能怪他,很多人对线程池的理解,还停留在创建的时候填四个参数,知道核心线程、最大线程、存活时间、队列就完事了。真到线上出问题,全靠瞎调参数,蒙对了就万事大吉,蒙错了反而更糟。
这里要注意,线程池调优不是越大越好 。队列加太大,请求堆积多了,反而会让平均响应时间更长,用户还是超时。线程开太多,CPU 切换不过来,上下文切换开销把性能都吃掉了。
有意思的是,很多公司的线程池配置,从项目上线那天起就没动过。默认参数用到底,出了问题才慌慌张张改一改,改完又出新问题。其实线程池调优是有章法的,不是靠感觉瞎蒙。
二、别上来就调参数,先搞清楚问题在哪
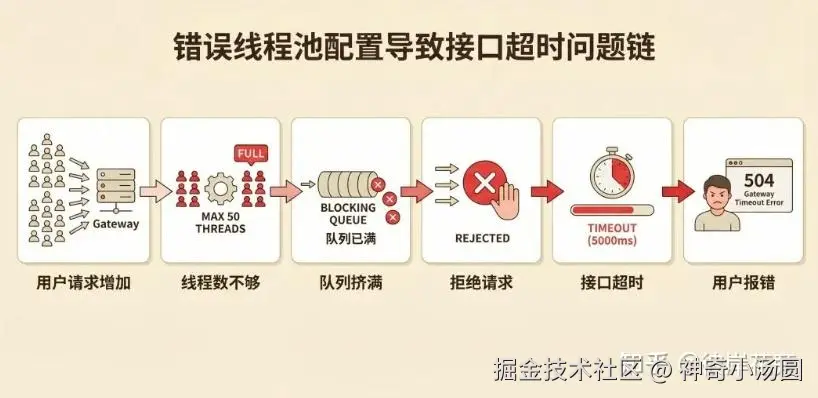
碰到接口超时全是线程池拒绝,第一步真不是改参数。你得先搞明白:到底是请求真的太多了,还是线程卡在那里动不了?
两种情况解法完全不一样。如果是某个慢查询把线程都block住了,你就算开一百个线程,很快还是会被占满,问题根本没解决。这个时候应该去优化慢接口,而不是扩容线程池。
这里说个简单的判断方法:看一下线程的平均等待时间 和实际执行时间。如果等待时间很长,执行时间很短,说明确实是线程数不够,请求排不上队。如果执行时间本身就很长,那问题出在任务本身,不是线程池。
举个例子:你的接口处理一次请求需要 100ms,8 核机器开了 16 个线程,理论上每秒能处理 160 个请求。如果每秒来了 300 个请求,那自然排不过来,这个时候可以考虑扩容。如果每个请求要等 2 秒数据库查询,开 100 个线程一下子就占满了,这时候优先优化 SQL 加索引,比加线程有用多了。
线程池解决的是排队问题,不是慢问题。先治病还是先止痛,得分清楚。
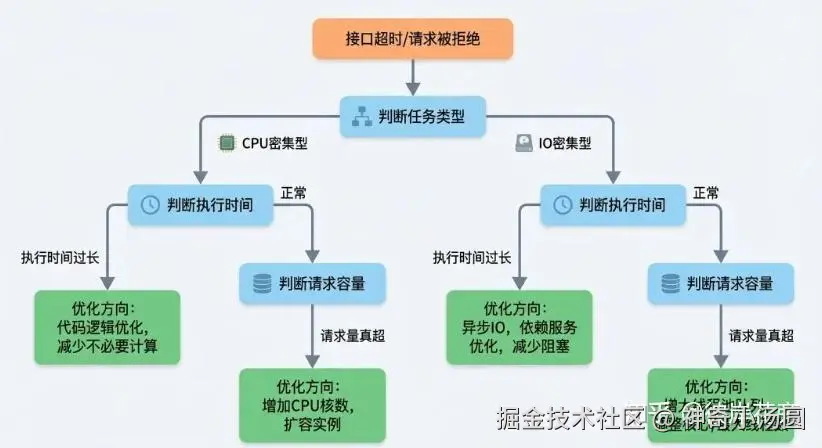
很多人误以为,核心线程数就设成CPU核数乘以2就行。其实这个公式只适用于CPU密集型任务。如果你的任务大部分都是在等IO------等数据库、等第三方接口,那线程数可以设得大很多,因为很多线程都是在等待,CPU其实是空的。
举个实际例子:我之前做过一个推送服务,大部分时间都在等第三方网关回调,线程数开到 CPU 核数的 10 倍,吞吐量反而更高,因为闲着也是闲着,多开线程能多处理请求。
三、真正实用的优化步骤,一步步来
搞清楚问题之后,再动手优化就不会错了。说几个实战中真正有用的优化手段,按顺序来:
第一,缩小任务本身的执行时间。这是性价比最高的优化。把慢SQL优化了,把不必要的串行调用改成并行,加上缓存,能解决 80% 的问题。任务跑得快了,自然不需要那么多线程排队。
第二,根据任务类型设置合理的线程数。公式给你放这了:
线程数 = CPU核数 × (1 + 平均等待时间 / 平均计算时间)
等待时间越长,需要的线程越多。IO密集型任务,等待时间远大于计算时间,线程数可以大一点。CPU密集型,计算时间占比高,线程数接近CPU核数就够了,开多了反而增加切换开销。
第三,拒绝策略真的很重要 。很多人默认用AbortPolicy,队列满了直接抛异常,用户直接看到报错。其实更合理的是用CallerRunsPolicy,让提交任务的线程自己去执行这个任务,这样能把请求速率降下来,不至于把所有用户都拒绝了。当然,你也可以自己实现拒绝策略,把请求放到Redis队列里慢慢处理,或者直接返回系统繁忙,请稍后重试给用户,比直接抛异常强得多。
第四,队列选型别瞎选 。你用无界LinkedBlockingQueue试试,请求一来堆积几万条,内存直接炸掉。所以生产环境一定要用有界队列。那用SynchronousQueue好不好?这个队列不存任务,来了直接提交给线程,线程不够就拒绝,适合请求量大但处理快的场景,能减少排队延迟。如果你希望请求尽量都能处理,接受一点延迟,那就用有界LinkedBlockingQueue。
这里踩过坑才知道:队列不能太长。队列太长,请求排队时间久了,用户还是超时,你堆积那么多请求干嘛?还不如早点拒绝,让用户重试或者降级。
还有一点容易忽略:不同类型的任务要分开线程池 。你不能把推送任务、导入任务、接口请求都塞到同一个线程池里。一旦某个类型的任务把线程都占满了,其他正常请求也别想处理了,全被连累。拆分之后,就算一个池子炸了,不影响其他业务。四、别光说不练,线上要这么监控
调完参数不是完事了,你得盯着看实际运行效果。线程池有几个关键指标必须监控:
- 当前活跃线程数 :是不是经常跑到最大线程数,说明确实不够用
- 队列中等待的任务数:是不是经常排队排满
- 任务完成速度和提交速度对比:如果提交一直比完成快,那迟早会崩
- 平均执行时间、平均等待时间:看你的调优有没有效果
其实很多问题,监控一看就明白。你调完参数,观察一天,看看拒绝次数还多不多,接口超时率降了没有,一目了然。
面试官其实不care你能背出多少参数,他就想知道你线上真碰到问题会怎么一步步分析解决。你把这套诊断流程说出来,比你背十个线程池参数有用多了。
回到最开始那个问题:接口超时频繁,线程池队列满了拒绝请求,你该怎么回答?
别上来就说加大线程加大队列,先问清楚:任务是CPU密集还是IO密集?现在每个任务平均执行时间多少?是不是有慢接口拖后腿?然后再一步步来,先优化任务,再调整参数,再拆分隔离,最后上监控。这么说,面试官基本就满意了。
很多时候,候选人凉不是因为不知道线程池是什么,是因为太着急给答案,没搞清楚问题就瞎优化,正好踩中面试官挖的坑。