Go 并发模式:在现代架构中融合 CSP 哲学与传统原语
一、从"Hello, goroutine"到"Hello, 世界"------现代 Go 并发的起点
让我们从一个最经典的入口开始。在几乎所有编程语言的教程里,第一个程序往往是向屏幕打印一句"Hello, World"。这是一种宣告,一个起点。在 Go 语言里,这个起点被赋予了并发的基因。当你写下第一个 go 关键字时,旅程便开始了。
go
package main
import (
"fmt"
"time"
)
func sayHello() {
fmt.Println("Hello, goroutine!")
}
func main() {
// 传统的、顺序的"Hello, World"
fmt.Println("Hello, World (sequentially)")
// 并发的起点:一个简单的 goroutine
go sayHello()
// 给一点时间,让 goroutine 有机会执行
time.Sleep(time.Millisecond * 10)
}这短短的几行代码,便是 Go 并发世界最朴素的"Hello, World"。一个 go 关键字,就将函数 sayHello() 从一个普通的同步调用,变成了一个在后台并发执行的轻量级线程------goroutine。它如此轻巧,以至于你几乎感觉不到它的启动成本。这种"感觉不到"的重量,恰恰是 Go 并发设计的精髓。
轻如鸿毛的"执行单元"
为什么 goroutine 如此特别?传统的操作系统线程(OS Thread)是"重量级"的,创建和切换涉及内核调用、内存开销大(通常 MB 级别栈)。而 goroutine 是 Go 运行时管理的用户级线程 ,它的初始栈只有约 2KB,并且可以在用户态高效地创建、调度和销毁。这意味着你可以轻松地创建成千上万个 goroutine,而不用担心耗尽内存或拖垮 CPU。它不再是稀缺资源,而是一种可以被大量、慷慨使用的并发流构建块。
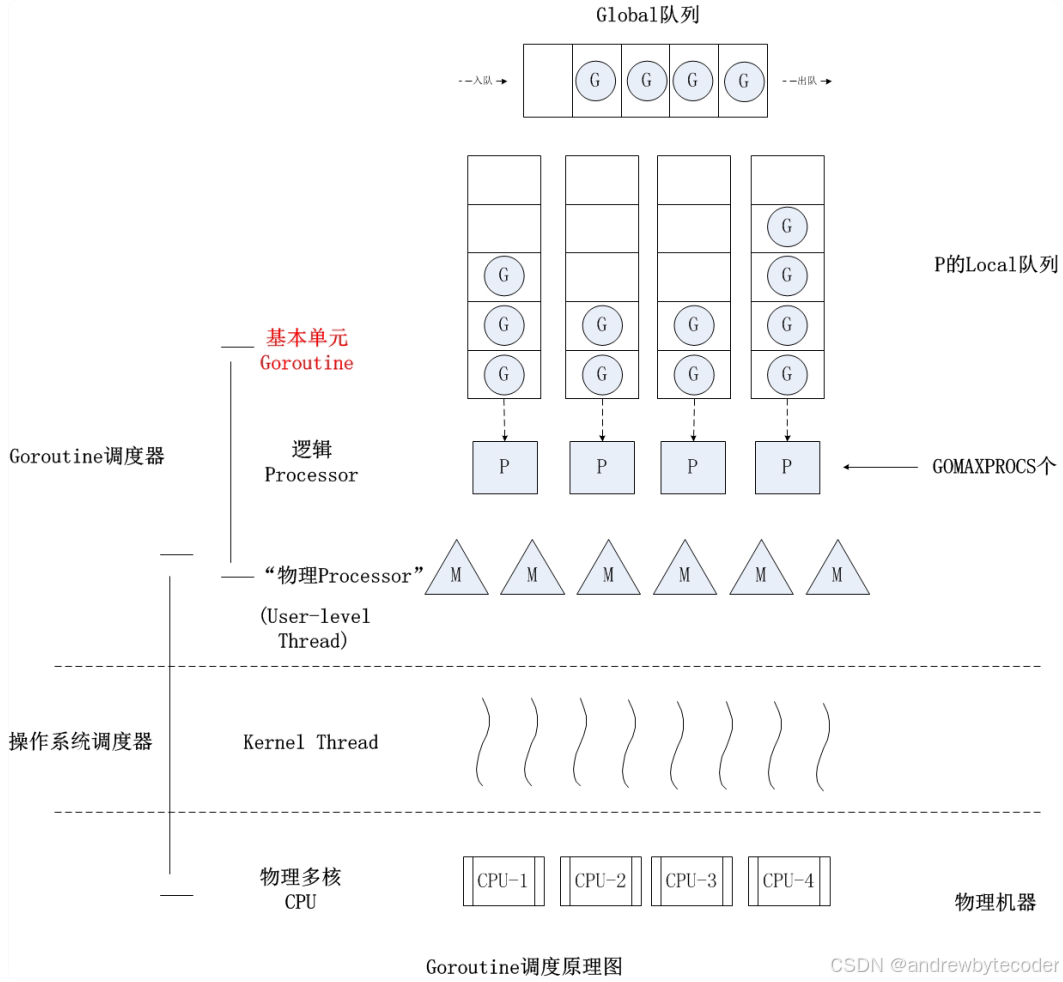
这与 CSP 理论中的"进程"概念完美契合。在 CSP 里,"进程"是独立的计算实体。Go 将其落地为 goroutine,一个你可以随手 go 一下就去执行的函数。函数退出,goroutine 即结束。这种生命周期与函数绑定的简洁性,极大地简化了并发编程的心智模型------你不再需要费力地管理一个复杂的线程对象,你只是在启动一个"去做某件事"的函数。
"通信"取代"共享":核心理念的无声渗透
但仅有轻量级的执行单元是不够的。如何让这些成千上万的 goroutine 安全、高效地协作?Go 给出的答案隐匿在其最著名的设计格言中:"不要通过共享内存来通信,而应通过通信来共享内存。"
这句话是 CSP(Communicating Sequential Processes)理论在工程上的凝练。它指出了一条与传统的、基于锁和共享内存的并发模型完全不同的道路。在传统模型里,线程们围着一块共享数据,小心翼翼地用互斥锁(Mutex)划出临界区,稍有不慎就会导致数据竞争、死锁等问题。这像是在一个嘈杂的房间里,多人争抢着修改同一块白板,需要复杂的规则来维持秩序。
而 Go 鼓励的模型,像是建立一条条**有序的传输带(channel)**。每个 goroutine 守在自己的工位上,处理手头的工作。它不直接去动别人的"白板",而是将需要处理的数据(或处理好的结果)放在传输带上,发送给下一个工位的 goroutine。数据在 channel 中移动的过程,就是所有权转移的过程。 接收方从 channel 中取走数据后,发送方就不再(也不应)持有它,从而在架构层面规避了数据竞争。
go
// 一个简单的"管道"雏形:数据通过 channel 在 goroutine 间传递
func simplePipeline() {
// 创建一个无缓冲的 int 型 channel
ch := make(chan int)
// 生产者 goroutine
go func() {
defer close(ch) // 完成后关闭channel,这是一种重要的信号
for i := 0; i < 5; i++ {
ch <- i // 将数据发送到 channel
}
}()
// 消费者(主 goroutine)
for num := range ch { // 自动从 channel 接收,直到其被关闭
fmt.Println("Received:", num)
}
}在这个例子里,数字 i 的所有权从匿名 goroutine(生产者)转移到了主 goroutine(消费者)。它们没有共享任何变量,唯一的交集就是那个 channel。Channel 成为了协调与同步的核心 。无缓冲的 channel (make(chan int)) 要求发送和接收同时就绪,否则就会阻塞,这本身就是一种强大的同步机制。而 range 循环在 channel 关闭后自动结束,提供了一种清晰的生命周期终结信号。
并发?并行?Go 的设计哲学分野
在深入之前,必须厘清一个关键概念:并发(Concurrency)不等于并行(Parallelism)。 这是现代 Go 并发设计的哲学基座。
- 并发 是一种程序结构设计方法 。它关心的是如何将一个问题分解为多个可以独立推进 的执行单元(goroutines)。即使是在单核 CPU 上,程序也可以通过快速的切换(时间片)来"同时"处理多个任务,给人并发的假象。它是关于代码组织的。
- 并行 则是同时执行 。它需要多核或多 CPU 硬件支持,让多个执行单元真正物理上同时运行。它是关于执行效率的。
Go 语言的天才之处在于,它首要关注的是并发结构的设计 。它通过 goroutine 和 channel,让开发者能够以一种清晰、组合的方式去构建并发的程序逻辑。而一旦你构建好了正确的并发结构,并发就会自然而然地使并行成为可能。Go 运行时的工作窃取调度器会自动将你的 goroutines 映射到多个操作系统线程上,从而充分利用多核 CPU 的算力,而开发者通常无需关心底层细节。
这就像是先设计好一条高效、分工明确的流水线(并发设计),当你有更多工人(CPU 核心)时,这条流水线可以立即让他们各司其职,提升整体产量(并行执行)。Go 将你从手忙脚乱地管理线程和锁的泥潭中拉出来,让你能专注于更高层次的任务分解与流程编排。
所以,当你说"Hello, goroutine"时,你启动的不仅是一个轻量级线程,更是一套以通信为核心、以结构设计优先的现代并发哲学。你从一个传统"Hello, World"的线性世界,迈入了一个由无数轻量级流经 channel 连接、可清晰推理、并能自然扩展至多核的"Hello, 世界"。这是一个全新的起点,它为构建从简单工具到复杂分布式系统的一切,提供了坚实而优雅的基础。
当然,CSP 和 channel 并非万能银弹。下一章,我们将看到当这条优雅的"传输带"遇到现实世界的复杂场景时,传统原语如何登场,与 channel 共舞,构建出真正健壮的并发程序。
二、CSP 不是银弹:当 channel 遇到 mutex
在满怀希望地发出第一个 go 关键字,并看着数据在 channel 构成的流水线中顺畅流动后,我们很容易将 "不要通过共享内存来通信,而应通过通信来共享内存" 这句格言奉为圭臬。它确实描绘了一幅清晰、易于推理的并发蓝图。但这枚"银弹"在面对现实中千变万化的场景时,偶尔也会留下一些无法击穿的孔洞。当你为一个性能关键的内核计数器反复创建和关闭 chan int,只为遵循"通信"教条时,可能会疑惑:我们是否矫枉过正了?
本章旨在为 channel 正名,也为 mutex 松绑。在 Go 的现代并发工具箱里,它们从来不是"非此即彼"的对立双方,而是分层协作的理想搭档 。让我们聊聊 CSP 模型的优雅边界 ,以及 mutex 在何时何地会带来更简洁、更高效 的解决方案。
何时 Channel 会显得"笨重"?划清 CSP 的适用边界
Channel 的核心优势在于所有权转移 和生命周期信号 。当你需要将数据从一个计算阶段安全地移交到下一个阶段,或是需要广播"结束"信号时,channel 是无懈可击的。Go 官方和社区也始终推荐以 CSP 模型作为构建并发程序整体架构的首选。
然而,在一些特定场景下,channel 的开销和复杂性会显得不那么划算:
- 性能敏感的简单状态保护 假设你有一个高频更新的全局计数器,比如一个每分钟被触发数十万次的 API 访问统计。如果每次更新都通过
chan int发送,再由一个专门的 goroutine 接收并累加,你会引入两次上下文切换 (发送者阻塞、接收者调度)和通道缓冲管理 的开销。文档明确指出,在高性能临界区 ,sync.Mutex等低级同步原语的性能通常优于 channel。对于这种"仅需原子更新一个数字,无需传递所有权"的任务,一把轻量级的锁反而更快、更直接。 - **守护复杂内部状态的"看门人"**考虑一个内存缓存对象,它内部持有一个
map[string]interface{}。多个 goroutine 会并发地读取、写入和遍历它。使用 channel 来模拟所有操作,意味着你需要为每种操作(Get, Set, Range)定义消息格式,并通过 channel 发送给一个独占的"管理 goroutine"来串行执行。这虽然实现了安全,但:- 引入了序列化瓶颈:所有操作,哪怕是只读的,也必须排队。
- 牺牲了局部性 :调用者必须"远程过程调用",无法就地快速读取。 而
sync.RWMutex允许多个读取者并行访问 ,仅在写入时短暂互斥,完美匹配了"读多写少"的缓存场景。正如资料所说,当你 "不想转移结构体对象所有权,但又要保证内部状态同步访问" 时,传统的锁更为合适。
- 一次性初始化或资源准备 像程序启动时需要加载一次配置文件,或建立数据库连接池这类场景。
sync.Once的Do方法提供了简洁、并发安全的保证。如果用 channel 实现,你需要手动维护一个状态标志和一个保护它的锁(又回到了锁!),或者设计一个复杂的"初始化请求-响应"协议,这显然是一种过度设计。
Mutex 的现代姿势:从"洪水猛兽"到"精密工具"
既然锁仍有其用武之地,那我们就该了解如何正确地使用它。现代 Go 语境下的 mutex,早已不是容易导致死锁的"洪水猛兽",而是一个设计精良的精密工具。
最佳实践一:嵌入结构体,明确保护域
最清晰的做法是将 sync.Mutex 或 sync.RWMutex 直接嵌入到需要被保护的结构体中。这清晰地表明了该结构体是并发安全的,且锁的职责被限定在结构体方法内部。
go
type SafeConfig struct {
sync.RWMutex // 嵌入读写锁
settings map[string]string
}
func (c *SafeConfig) Get(key string) string {
c.RLock() // 读操作用读锁,允许多个goroutine并发读取
defer c.RUnlock()
return c.settings[key]
}
func (c *SafeConfig) Set(key, value string) {
c.Lock() // 写操作用写锁,独占
defer c.Unlock()
c.settings[key] = value
}最佳实践二:defer 解锁与临界区最小化
获取锁后立刻使用 defer 安排解锁 ,这是避免因 panic 或提前返回而导致锁泄漏的铁律。同时,牢记临界区应尽可能小------只锁定必要的操作,尽快释放锁,以减少竞争。
务必警惕的反模式:复制已使用的锁
与 channel 不同,sync.Mutex 是一个包含内部状态的值类型。复制一个已经使用过的 Mutex(例如在函数传参或赋值结构体时)会导致副本和原锁失去关联,同步完全失效,引发极难调试的数据竞争或死锁。请务必通过指针来传递包含 Mutex 的结构体。
Channel 与 Mutex 的共舞:分层设计与默契配合
真正优雅的并发设计,往往不是纯粹的单一样式,而是两种模式在不同层次上的默契配合。
- 宏观架构用 CSP,微观优化用原语 这正是资料中强调的核心思想:从程序的整体结构来看,推荐以 CSP 风格构建并发程序;对于局部情况,如性能敏感区或需要保护的结构体数据时,使用更高效的低级同步原语 。想象一个实时日志处理系统:
- **宏观(数据流)**:各个服务产生的日志条目,通过
chan LogEntry流入一个处理管道(Pipeline),进行过滤、解析、富化。这个数据流的驱动和生命周期由 channel 和context.Context完美管理。 - 微观(状态与统计):管道中的某个"统计"阶段,内部维护着一个
map[string]int64来统计不同错误代码的数量。这个 map 的更新就用sync.RWMutex保护。而最终的统计结果,再通过另一个chan Report输出给聚合器。在这里,锁保护内部共享状态,channel 负责跨阶段通信。
- **宏观(数据流)**:各个服务产生的日志条目,通过
- 经典组合模式:WaitGroup + Channel 这是等待一组并发任务完成并收集结果的黄金搭档。
go
func fetchAll(urls []string) []Result {
var wg sync.WaitGroup
results := make(chan Result, len(urls)) // 结果通道
for _, url := range urls {
wg.Add(1)
go func(u string) {
defer wg.Done()
// 并发抓取
res, err := http.Get(u)
if err == nil {
results <- Result{URL: u, Data: res.Body}
}
}(url)
}
// 关键:启动一个 goroutine 等待所有任务,然后关闭通道
go func() {
wg.Wait()
close(results) // 所有生产者完成后,关闭通道通知消费者
}()
var collected []Result
for res := range results { // 主 goroutine 可以安全地循环读取,直到通道关闭
collected = append(collected, res)
}
return collected
}这里,WaitGroup 纯粹用于同步任务完成 这一行为,而 channel 则负责结果的流动和完成信号的传递。两者各司其职,组合起来既清晰又高效。
最终抉择:一份务实的选择指南
当你面对一个并发设计抉择时,可以问自己几个问题:
| 如果你的问题是关于... | 更倾向的工具 |
|---|---|
| 数据在逻辑组件间的流动 、事件通知 、构建清晰的生产者-消费者链 | Channel |
| 等待一组无关的并发操作全部完成(不关心结果或结果另存) | sync.WaitGroup |
| 保护一个小的、内部的共享变量或状态(尤其是高频更新) | sync.Mutex / atomic |
| 保护一个复杂的、读多写少的数据结构(如缓存映射) | sync.RWMutex |
| 保证一段代码仅执行一次(如初始化) | sync.Once |
| 需要超时、取消,并跨 API 边界传播这些信号 | context.Context |
记住,Go 提供这些工具,是为了让你根据问题域选择最合适的工具,而非被一种哲学所束缚。优秀的 Go 程序员,既懂得用 channel 编织出清晰的数据流乐章,也善于在关键的节拍处,用 mutex 敲下精准而有力的节奏点。它们共同谱写的,才是稳健、高效且易于维护的并发程序。
三、context 的隐形契约:取消、超时与值传递
在 CSP 模型的华丽舞台和传统原语的坚实基础之上,我们终于要直面一个贯穿现代分布式系统血脉的核心问题:如何优雅地、确定性地终结一个跨边界的并发任务? 当你的 HTTP 处理器启动了数个数据库查询和外部 API 调用,用户却关闭了浏览器标签页,那些孤悬在外的 goroutine 该如何知晓"演出已经结束"?这便是 context.Context 登场的时刻。它并非数据通道,而是一份关于控制流的隐形契约。
一份关于"终结"的统一契约
在 context 包诞生之前,每个项目、甚至每个团队都有一套自创的"终止信号"系统:一个名为 done 的 chan struct{},一个 closed 的布尔原子变量,或是更为复杂的自定义结构。这种割裂带来了维护和集成的噩梦。
context 的出现,正是为了确立这份统一的契约。它的核心承诺很简单:提供一套标准机制,来传递取消信号、截止时间,以及请求作用域的值 。这份契约的精髓,在 Go 社区的那句名言中得以体现:"**Never start a goroutine without knowing how it will stop.**"(永远不要在不知道如何停止的情况下启动一个 goroutine)。context 就是那个让你清晰知晓"如何停止"的标准答案。
它的底层机制朴素而有效:利用通道的关闭来广播信号 。每个可取消的 Context(内部类型为 cancelCtx)都持有一个 done chan struct{}。当取消发生时,该通道被关闭,所有监听它的 goroutine 都能收到这一广播事件,从而有机会清理资源并退出。
树形血统与信号传播:契约的基石
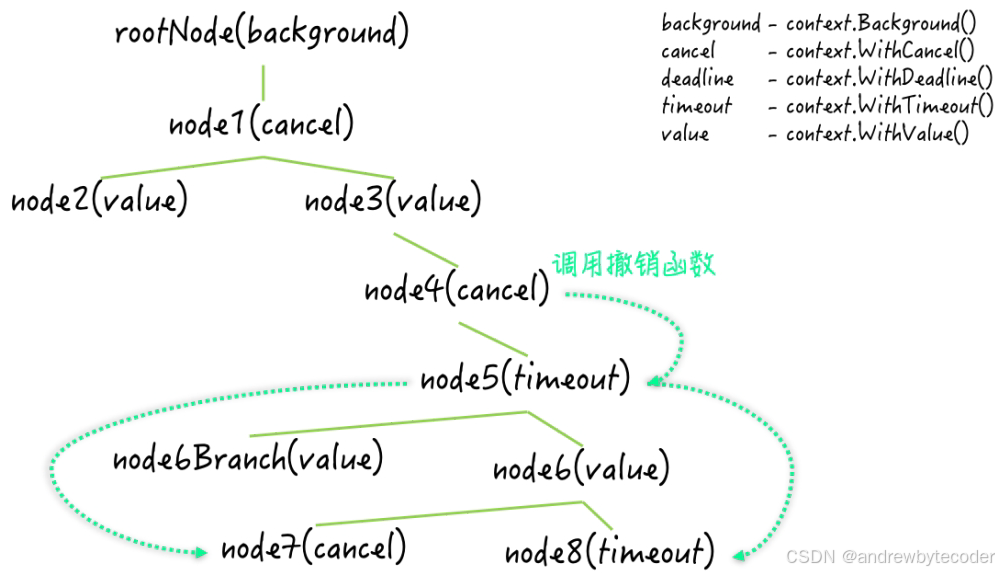
这份契约的第一个关键特性是其树形继承结构 。所有的 Context 值共同构成一棵全局的上下文树。
- 根与派生 :树的根通常是
context.Background()(用于主函数、测试或顶级请求)或占位符context.TODO()。通过WithCancel、WithTimeout、WithDeadline、WithValue这些函数,可以从一个父 Context 派生(derive) 出新的子 Context。 - 单向的级联取消 :这是一个至关重要的设计:父节点的取消信号会自动、向下级联传递给所有子孙节点。但反之不成立,子节点的取消不会影响父节点。这完美模拟了现实世界中的任务依赖关系------上游任务取消,下游所有子任务自然失去意义;但某个子任务失败,不应导致整个任务链崩溃。
go
// 一个简单的级联取消示例
func main() {
// 祖父节点
ctx, cancel := context.WithCancel(context.Background())
defer cancel() // 确保资源释放
// 父节点:带超时
timeoutCtx, _ := context.WithTimeout(ctx, 2*time.Second)
// 子节点:携带值
valueCtx := context.WithValue(timeoutCtx, "request_id", "req-123")
go worker(valueCtx)
// 模拟:1秒后主动取消祖父任务
time.Sleep(1 * time.Second)
cancel() // 此操作将导致 worker 中的 ctx.Done() 收到信号
}
func worker(ctx context.Context) {
reqID := ctx.Value("request_id").(string)
fmt.Printf("Worker started for %s\n", reqID)
select {
case <-time.After(5 * time.Second):
fmt.Println("Work completed")
case <-ctx.Done(): // 监听取消信号
fmt.Printf("Work cancelled: %v\n", ctx.Err()) // 将输出 "context canceled"
// 执行资源清理...
}
}这份"树形血统"契约,使得跨服务、跨层级的协同取消变得清晰且可靠。
作为第一参数的契约:不可变性与显式传递
这份契约的第二个关键实践,是 **Context 应作为函数的第一个参数显式传递**。这已成为 Go 社区铁律般的习惯。
go
// 正确:Context 作为首参
func ProcessOrder(ctx context.Context, orderID string) error {
// ...
}
// 错误:不要将其存储为结构体字段
type Service struct {
ctx context.Context // 反模式!
}为何如此?原因在于 Context 的**不可变性(Immutable)**。每次调用 WithXXX 都会产生一个全新的 Context 对象,而非修改原对象。将其作为参数传递,确保了调用链上每一层都可能拥有与其职责相匹配的、携带不同元数据或超时的上下文。将其存入结构体,则冻结了它的状态,破坏了这种灵活性,也模糊了生命周期的边界。
实践中的契约:超时、取消与审慎的值传递
1. 超时与截止时间:契约中的"信号灯塔"
在网络编程中,没有超时的请求等于埋下了资源泄漏的定时炸弹。WithTimeout 和 WithDeadline 是这份契约中最常用的工具。标准库(如 net/http、database/sql)已深度集成此机制,使得从最外层的 HTTP 服务器超时,到内部连接池的等待超时,形成一套可层层细化的时间预算体系。
2. 优雅的级联取消:契约的履行
当 ctx.Done() 通道被关闭时,监听它的代码应履行契约,立即开始清理工作并退出。这通常通过 select 语句与主业务逻辑通道配合实现:
go
func worker(ctx context.Context, input <-chan Task, result chan<- Result) {
for {
select {
case task, ok := <-input:
if !ok {
return // 输入通道关闭,正常退出
}
// 处理任务...
case <-ctx.Done():
// 契约履行:收到取消信号,立即终止循环
fmt.Println("Cancellation received, cleaning up...")
// 可能还需要尝试发送一个终止性结果或记录状态
return
}
}
}3. 值传递:契约中需要慎用的"附注"
通过 WithValue 可以在 Context 中附加请求域的数据,如链路追踪的 Trace ID、用户认证令牌。这解决了在深层次函数调用中透传元数据而不污染所有函数签名的难题。
然而,这是一份需要极度审慎 使用的契约附注。因为它使用 interface{} 类型,失去了编译时的类型安全。最佳实践是:
- 使用自定义的、非导出的类型作为键,避免包间的键冲突。
- 提供类型安全的访问器函数进行封装 ,而非直接调用
ctx.Value。
go
// 定义包内私有的键类型
type traceIDKey struct{}
// 安全的设值函数
func WithTraceID(ctx context.Context, id string) context.Context {
return context.WithValue(ctx, traceIDKey{}, id)
}
// 安全的取值函数
func GetTraceID(ctx context.Context) (string, bool) {
id, ok := ctx.Value(traceIDKey{}).(string)
return id, ok
}同时,务必记住:Context 值传递适用于请求作用域、进程内、并发安全的数据。不要滥用它来传递函数可选参数或替代正常的函数返回值。
契约的精神:协同而非主宰
最终,context.Context 在现代 Go 并发工具箱中,扮演的是"协调者"而非"主宰者"的角色。它与前两章探讨的工具协同工作:
- 与 channel 互补:Channel 负责数据流的所有权转移 ;Context 负责控制流信号(取消/超时)的广播。一个管"内容",一个管"开关"。
- 与 sync.WaitGroup 组合:
WaitGroup等待一组任务完成 ;Context可以通知一组任务提前结束。两者结合,能实现"等待所有任务完成,但可中途超时取消"的复杂语义。 - 与 sync.Mutex 分工:Mutex 保护的是内存中的共享状态 ;Context 管理的是执行过程的生命周期。前者关乎数据一致性,后者关乎流程控制。
这份关于取消、超时与值传递的隐形契约,其伟大之处在于,它通过一个极其简洁的接口,将分布式系统中固有的不确定性------尤其是失败与终止------封装成了一个可预测、可编程的模型。它让"优雅退出"从一个美好的愿望,变成了每一行 Go 并发代码都可以践行的日常实践。当你养成了"ctx context.Context 作为首参"的肌肉记忆时,你便已经签署了这份构建健壮系统的关键契约。
四、泛型之后:类型安全的并发管道
在确立了"宏观用 channel 构建流水线,微观用原语保护状态"的分层策略后,我们面对的下一个工程挑战变得清晰:如何让这些并发的"管道"和"组件"在复杂组合时,既能保持 CSP 模型的清晰度,又能获得编译器的强力保障?Go 1.18 引入的泛型(Generics)正是为此而来的工具箱升级,它没有颠覆并发模型,而是让编写高质量、类型安全的并发"积木"变得前所未有的容易。
泛型:为并发管道注入编译时类型安全
在泛型之前,构建通用的并发数据处理组件常常面临两难选择。要么为每种数据类型重复编写几乎相同的管道逻辑,导致代码膨胀;要么使用 interface{} 进行抽象,但这意味着失去类型安全,并引入运行时类型断言的开销与风险。正如前文所述,一个需要处理多种数据类型的 fan-in 或 worker pool,其接口往往会变得笨拙。
泛型通过类型参数 解决了这一核心矛盾。它允许我们在编写诸如通道处理函数、并发安全集合等组件时,将数据类型参数化。编译器会为实际使用的具体类型生成特化的代码,从而在编译期就确保类型匹配,完全消除了运行时类型不确定性的隐患。这对并发编程尤其重要,因为数据在多个 goroutine 间流动时,类型的错配是难以调试的深坑。
构建泛型并发组件:从安全容器到复用管道
泛型最直接的应用是创建类型安全的并发数据结构。例如,我们可以告别 sync.Map 的 interface{},设计一个泛型并发映射:
go
type ConcurrentMap[K comparable, V any] struct {
mu sync.RWMutex
data map[K]V
}
func (m *ConcurrentMap[K, V]) Get(key K) (V, bool) {
m.mu.RLock()
defer m.mu.RUnlock()
val, ok := m.data[key]
return val, ok
}
func (m *ConcurrentMap[K, V]) Set(key K, value V) {
m.mu.Lock()
defer m.mu.Unlock()
m.data[key] = value
}这个 ConcurrentMap[string, int] 在编译时就知道自己只处理 string 键和 int 值,任何错误的赋值或读取都会在编译阶段被捕获,并且访问性能与原生 map 无异,因为它无需任何运行时反射或断言。
更重要的是,泛型让并发模式本身 成为可复用的资产。考虑一个经典的管道阶段:过滤。过去,为 int、string 或自定义结构体写过滤逻辑,需要复制代码。现在,我们可以定义一个泛型过滤器:
go
func Filter[T any](in <-chan T, predicate func(T) bool) <-chan T {
out := make(chan T)
go func() {
defer close(out)
for v := range in {
if predicate(v) {
out <- v
}
}
}()
return out
}这个 Filter 函数现在可以用于任何类型 T 的通道流。我们可以轻松组合出类型安全的数据处理管道:
go
// 假设有一个产生整数的通道 sourceChan
evenChan := Filter(sourceChan, func(x int) bool { return x%2 == 0 })
// evenChan 的类型明确为 <-chan int,后续处理完全类型安全Fan-in、Fan-out、转换(Map) 等模式都可以用泛型优雅地实现。这意味着团队可以构建一个内部通用的"并发算法库",其中包含类型安全、经过测试的管道操作原语,极大地提升了复杂数据流系统的开发效率与可靠性。
性能与清晰度的平衡:泛型并非银弹
尽管泛型带来了强大的表现力,但 Go 的设计哲学提醒我们保持谨慎:非必要,不泛型。泛型是解决代码重复和类型安全问题的利器,但它不应被滥用而增加不必要的抽象复杂度。
在实践中,泛型通过编译时类型实例化 来工作。当你使用 Filter[int] 时,编译器会生成一份处理 int 类型的特化代码。这消除了基于接口的动态派发开销,对于性能敏感的并发操作组件(如高频访问的缓存、队列)是显著的利好。然而,这并不意味着所有 interface{} 都应该被泛型替换。对于真正需要运行时类型灵活性的场景(如插件系统、序列化框架),接口仍然是合适的工具。
此外,虽然泛型在一定程度上 支持了更函数式的风格(如定义通用的 Map、Reduce 管道),但这并非 Go 的主流惯用法。Go 更鼓励通过 channel 传递具体的、有状态的数据流。泛型的最佳用途是增强这种惯用模式的类型安全和复用性,而非强行引入另一种编程范式。
总结:更强悍的工具,不变的蓝图
Go 1.18 的泛型,对于并发编程而言,是一次精准的工具箱升级。它没有改变"通过通信共享内存"的核心并发蓝图,也没有重新定义 goroutine 和 channel 的角色。相反,它为我们提供了铸造更坚固、更合手的"并发积木"的能力。
现在,我们可以:
- 设计类型安全的通用并发数据结构 ,告别
interface{}的猜测与断言。 - 封装可复用的并发模式(管道阶段、扇出扇入),让业务逻辑从重复的通道编排代码中解放出来。
- 在编译期捕捉更多错误,让数据在并发流动中的类型轨迹清晰可循,提升系统的整体健壮性。
最终,泛型让 Go 的并发哲学在大型工程中得以更纯粹、更安全地实践。我们依然用 channel 勾画系统脉络,用 goroutine 驱动执行流,但现在,连接它们的管道和组件,拥有了由编译器担保的、坚固的类型接口。这正如为一位技艺精湛的工匠换上了一套刻度更精密的工具,作品的结构因此可以更复杂、更可靠,而创作的心智负担却得以减轻。
五、传统原语的现代姿势:Once、Atomic 与 WaitGroup 的再思考
在确立了"宏观用 CSP(channel)组织数据流,微观用传统原语保护状态"的分层哲学后,是时候对我们工具箱里的几件"老家伙"进行一次深度的现代化审视。sync.Once、sync/atomic 以及 sync.WaitGroup,它们绝非被 channel 光芒掩盖的遗老,而是在现代 Go 并发架构中扮演着无可替代的精确角色。理解它们的新姿势,意味着能在清晰与性能之间找到更优雅的平衡点。
1. sync.Once:不仅仅是一次性初始化
sync.Once 的核心承诺极为纯粹:确保一个函数在并发环境下只执行一次。这使其成为懒加载(Lazy Initialization)的绝佳工具,避免不必要的启动开销。
现代姿势:与 CSP 架构的集成
它绝非孤岛。想象一个微服务启动时,需要懒加载一个全局的、线程安全的配置缓存。一个现代的模式是,Once 负责安全的初始化,而 channel 负责就绪状态的广播。
go
var (
configCache atomic.Value // 使用 atomic.Value 存储配置
initOnce sync.Once
ready chan struct{} // 用于广播"初始化完成"
)
func InitConfigManager(ctx context.Context) {
ready = make(chan struct{})
// ... 其他初始化
}
func GetConfig() *Config {
// 确保初始化只发生一次
initOnce.Do(func() {
cfg := loadConfigFromRemote() // 昂贵的初始化操作
configCache.Store(cfg)
close(ready) // 广播初始化完成事件
})
v, _ := configCache.Load().(*Config)
return v
}
// 另一个组件可以等待初始化完成
func StartProcessor(ctx context.Context) {
select {
case <-ready:
// 安全地开始处理,配置已就绪
processor.Run()
case <-ctx.Done():
return
}
}这里,Once 保证了 loadConfigFromRemote 的幂等性,而 close(ready) 这个 channel 操作,则优雅地将"就绪"这一事件通知给系统中所有关心它的组件,实现了 CSP 风格的事件驱动。
必须绕开的陷阱
然而,纯洁的背后藏着锋利的刀刃:
- 死锁陷阱 :如果
Do方法中传入的函数f内部,直接或间接地又调用了同一个Once实例的Do方法,就会导致循环等待,引发死锁。 - 不可重试性 :一旦
Do执行过(即使f函数内部 panic 了),这个Once实例就永远"失效"了。它不是用来保证成功,而是保证只尝试一次 。对于需要重试的初始化,Once并不合适。 - 性能考量 :对于极度简单、性能敏感的初始化(比如查表),
Once内部的互斥锁和原子操作开销可能显得过重。此时,一个简单的原子标志位检查可能更快,但你需要自己实现"双重检查锁定"等模式来保证正确性,复杂度更高。
一句话总结 :将 sync.Once 视为一个**并发安全的"触发器"**。用它来触发那些昂贵且只需一次的动作,然后将结果通过 channel 或原子存储分享出去,让 CSP 的通信机制接管后续的协调工作。
2. atomic:共享内存时代的"外科手术刀"
当讨论从 channel 回归到共享内存时,sync/atomic 包提供了一把"外科手术刀"。它通过对单一整型变量或指针进行原子操作,实现了无锁(lock-free)同步。
性能的绝对优势
基准测试是冷酷的法官。数据表明,对于简单的增减操作,atomic.AddInt64 的速度可以达到 sync.Mutex 保护的数倍乃至数十倍。其优势在于:
- 硬件加速 :直接映射为 CPU 的原子指令(如 x86 的
LOCK INC),避免操作系统级线程调度的上下文切换。 - 无等待:多数原子操作本身是非阻塞的,没有锁的排队和唤醒开销。
- 缓存友好:通过 CPU 的缓存一致性协议(如 MESI)直接保证内存可见性,减少了锁可能导致的大量缓存行无效化。
现代姿势:作为高性能的"胶水"
在现代 Go 架构中,atomic 很少单独承担复杂的业务逻辑,而是作为高性能基础设施的"胶水":
- 统计数据:在网关、代理中,对请求数、耗时、错误次数进行毫秒级的高频累加。
- 状态标志:实现一个轻量级的、无锁的"开关"或"阶段状态机"。
- 实现高级原语 :
sync.WaitGroup、sync.Pool乃至sync.Once的内部,都依赖原子操作来维护计数器或状态。
一个典型模式是与 channel 结合:多个 worker goroutine 使用 atomic 无锁地更新本地或全局计数器,待一个聚合周期结束后,再由一个协调者 goroutine 通过 channel 收集并归零这些计数,进行批量上报。
go
type Metrics struct {
reqCount atomic.Int64
errCount atomic.Int64
}
func (m *Metrics) IncReq() {
m.reqCount.Add(1)
}
// 聚合器定期通过channel收集并重置
func (m *Metrics) Report() ReportSnapshot {
return ReportSnapshot{
Req: m.reqCount.Swap(0), // 原子地读取并归零
Err: m.errCount.Swap(0),
}
}适用条件与限制
这把手术刀非常锋利,但应用范围也极其明确:
- 适用 :对单一 整数、指针、布尔值进行
Add、CompareAndSwap (CAS)、Load、Store等简单操作。 - 不适用 :保护任何复合操作 或复杂数据结构(如 slice 的 append、map 的赋值)。你无法原子地"读取-修改-写入"一个结构体的多个字段。
关于 atomic.Value
atomic.Value 是一个特例,它可以原子地存储和加载任意类型的值(interface{})。它非常适合配置热更新:
go
var config atomic.Value
config.Store(loadNewConfig()) // 原子地更新整个配置对象
currentCfg := config.Load().(Config) // 原子地读取但切记:它存储的值本身应该是不可变的(immutable),或者使用者必须自己保证对值内部状态的并发访问安全。Store 一个 map 后,外部对这个 map 的修改仍然会破坏原子性。
3. WaitGroup:重新定义"等待"的艺术
sync.WaitGroup 可能是最被低估的原语。它的 API 简单到极致(Add, Done, Wait),但其在现代并发编排中的价值,在于它完美地诠释了 **"协调"与"通信"的分离**。
超越"等待完成"
是的,它的基础作用是等待一组 goroutine 结束。但现代用法更关注 **"它等待的是什么事件"**。
- 等待所有数据生产者结束,以便安全关闭结果 channel(Fan-in 模式的核心)。
- 等待所有后台清理任务完成,实现 Graceful Shutdown。
- 等待所有并发探测返回,以达成共识。
与 Channel 的经典二重奏
这是现代 Go 并发模式中最优雅的配合之一:
go
func merge(channels ...<-chan int) <-chan int {
var wg sync.WaitGroup
out := make(chan int)
// 为每个输入channel启动一个中继goroutine
output := func(c <-chan int) {
defer wg.Done()
for n := range c {
out <- n
}
}
wg.Add(len(channels))
for _, c := range channels {
go output(c)
}
// 关键:启动一个独立的goroutine,等待所有中继完成,然后关闭输出channel
go func() {
wg.Wait()
close(out)
}()
return out
}在这个经典的 Fan-in 模式中,WaitGroup 纯粹负责协调生命周期 (等待所有中继 goroutine 退出),而 channel (out) 纯粹负责数据传输 。wg.Wait() 完成后关闭 out,是通知下游消费者"流已结束"的唯一正确信号。这种职责分离让代码逻辑无比清晰。
易错点:Add 的时机
一个常见的陷阱是在 goroutine 内部调用 wg.Add(1)。这可能导致主 goroutine 的 wg.Wait() 在计数器增加之前就返回。黄金法则 :确保在启动任何 goroutine 之前 ,调用 wg.Add 设置好期望的计数。这通常意味着在循环外或循环开始时进行 Add。
现代演进:与 Context 集成
在需要超时或取消的等待场景中,WaitGroup 可以与 context.Context 结合:
go
func waitWithTimeout(ctx context.Context, wg *sync.WaitGroup) error {
done := make(chan struct{})
go func() {
wg.Wait()
close(done)
}()
select {
case <-done:
return nil
case <-ctx.Done():
return ctx.Err() // 超时或取消
}
}这里,我们用一个额外的 channel (done) 和 select 语句,将阻塞的 wg.Wait() 转化为一个可中断的等待。
再思考:传统原语在现代架构中的坐标
回顾并展望,Once、Atomic、WaitGroup 以及之前讨论的 Mutex,它们在现代 Go 并发版图中的坐标已然清晰:
Once是 "决策点" ,负责在并发洪流中,对某个关键动作做出一次且仅一次的执行决策。Atomic是 "刻度尺" ,在性能的毫米级赛道上,为最简单的共享状态提供无可匹敌的度量速度。WaitGroup是 "集合点" ,不关心过程细节,只负责在约定的地点清点并等待所有参与者到达,为下一阶段的通信(通常是关闭 channel)创造安全条件。Mutex是 "护卫" ,当共享的状态结构略微复杂,超出原子操作的范畴时,它提供强一致性的保护。
它们的共同点是:解决局部、具体的同步问题 。而 channel 和 context,则负责处理全局的、流动的数据与生命周期。
因此,一个现代的、健壮的 Go 并发程序,其代码可能呈现出这样的纹理:用 channel 编织出清晰的数据流主干道,用 context 管理着沿途的交通信号灯,而在那些关键的十字路口(初始化点)、收费站(计数器)和汇合广场(任务集合点),则由这些精心挑选的传统原语担任高效的交警和调度员。
这便是传统原语的现代姿势------不是被取代,而是在更高的设计层次上,找到了自己最舒适、最专业的定位。
六、微服务中的并发骨架:一个网关的演进故事
现在,让我们把镜头拉远,不再盯着孤立的函数或单一的数据结构,而是望向微服务架构的边界------API 网关。这里,高并发的流量、下游服务的不可靠性、以及毫秒级的延迟要求,会将前面讨论的所有模式放大、组合,最终形成一个健壮的"并发骨架"。
这个故事始于一次简单的重构,却在三年里演进了四个版本。
V1:朴素起点,每个请求一个协程
最初的网关非常简单,几乎是教科书式的 Go 网络服务:为每个 HTTP 请求启动一个独立的 goroutine 来处理。
go
func handleRequest(w http.ResponseWriter, r *http.Request) {
// 解析请求,验证身份,记录日志...
result, err := callDownstreamService(r)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
w.Write(result)
}
func main() {
http.HandleFunc("/api", handleRequest)
log.Fatal(http.ListenAndServe(":8080", nil))
}**📝 骨架分析** :这是 "goroutine-per-connection" 模式的直接应用。Go 的 net/http 包在底层使用 netpoll (I/O 多路复用器) 高效管理连接,当一个连接有数据可读时,运行时调度一个 goroutine 去处理。这种方式结构清晰,能轻松支撑数千个并发连接。但它有个致命问题:缺乏统一的控制面。任何一个下游服务的慢响应或 goroutine 泄漏,都会像滚雪球一样耗尽系统资源。
V2:引入 Context,建立生命周期契约
为了解决失控的问题,我们引入了 context.Context。这不是一个可有可无的参数,而是每个请求生命周期的隐形契约。
go
func handleRequestV2(w http.ResponseWriter, r *http.Request) {
// 从请求中派生一个带有超时(如 30 秒)的 Context。
ctx, cancel := context.WithTimeout(r.Context(), 30*time.Second)
defer cancel()
// 将 ctx 注入到所有下游调用中。
result, err := callServiceA(ctx, r)
if err != nil {
handleError(ctx, w, err) // 错误处理也能感知 ctx
return
}
// 继续后续处理...
}**✅ 收益**:
- 超时控制 :30 秒一到,
ctx.Done()通道关闭,所有监听它的下游调用(如配置了超时的 gRPC 或 HTTP 客户端)会收到取消信号,快速失败,释放资源。 - 级联取消 :如果
callServiceA内部又调用了callServiceB,它传递的是同一个ctx。当网关层的父 Context 超时,所有嵌套调用会被连锁取消。 - 资源清理 :
defer cancel()确保即使请求提前返回,相关的定时器资源也能被释放,防止内存泄漏。
**🦴 骨架形成** :此时,骨架有了第一根支柱:Context 作为贯穿请求处理链条的生命线。它让"优雅退出"从一个美好的愿望,变成了可编程、可预测的机制。
V3:扇出与聚合,面对下游并发
我们的网关开始承担更多职责:一个用户请求可能需要聚合来自用户服务、订单服务和推荐服务的数据。同步串行调用会让总延迟变成三者之和。是时候引入 Fan-out 模式了。
go
func aggregateData(ctx context.Context, userID string) (*Response, error) {
// 创建用于接收结果的 channel,类型为各服务的响应或错误。
userCh := make(chan *UserServiceResp, 1)
orderCh := make(chan *OrderServiceResp, 1)
recCh := make(chan *RecommendationResp, 1)
// 扇出:启动多个 goroutine 并发调用下游服务。
go fetchUser(ctx, userID, userCh)
go fetchOrders(ctx, userID, orderCh)
go fetchRecommendations(ctx, userID, recCh)
// 响应体
resp := &Response{}
// 扇入:从三个 channel 中收集结果。
// 使用 for 循环确保收集到足够数量的结果,或直到 Context 超时。
for i := 0; i < 3; i++ {
select {
case user := <-userCh:
resp.User = user
case orders := <-orderCh:
resp.Orders = orders
case recs := <-recCh:
resp.Recommendations = recs
case <-ctx.Done(): // 关键是这里!
return nil, ctx.Err() // 有任何超时或取消,立即中断等待
}
}
return resp, nil
}**✅ 收益**:
- 降低延迟 :总延迟从
T(user) + T(order) + T(rec)降低为max(T(user), T(order), T(rec))。 - 结果隔离:一个下游服务的失败(返回错误到其 channel)不会阻塞其他服务的正常响应收集。
- 及时中止 :
select与ctx.Done()的结合,确保一旦超时,整个聚合逻辑立即停止等待,快速返回错误给客户端,避免无用的等待。
**🦴 骨架强化** :第二根支柱出现:Channel 作为并发任务间通信与协调的管道。它完美践行了"通过通信来共享内存",将并发的复杂性封装在清晰的 channel 读写背后。
V4:共享状态与配置热更新
网关需要路由表、限流器、认证缓存等共享状态。当运维在后台更新路由配置时,我们希望在不停机的情况下,让所有处理 goroutine 立刻使用新配置。这里,传统同步原语登场了。
go
type Router struct {
mu sync.RWMutex // 保护路由表
routes atomic.Value // 存储 *RouteConfig,利用 atomic 实现无锁读
reloadCh chan struct{} // 用于广播重载事件的 channel
}
// 热更新协程
func (r *Router) hotReload(ctx context.Context) {
for {
select {
case <-r.reloadCh: // 收到管理端发出的重载信号
newConfig := loadConfigFromEtcd()
r.mu.Lock()
// 短暂加锁写入
r.routes.Store(newConfig)
r.mu.Unlock()
case <-ctx.Done():
return
}
}
}
// 处理请求的协程(数量可能成千上万)
func (r *Router) GetRoute(key string) *Route {
// 绝大多数情况:无锁、原子地读取最新配置
config := r.routes.Load().(*RouteConfig)
return config.Lookup(key)
// 只有在极少数配置更新的瞬间,写锁会阻塞新的读锁获取,
// 但写操作很快,影响微乎其微。
}**✅ 收益**:
- 高性能读 :
atomic.Value或sync.RWMutex的RLock()使得海量读请求近乎无锁。 - 安全更新 :
sync.Mutex或WLock()保证配置更新这个"写"操作的原子性,不会让请求看到中间状态的、不一致的路由表。 - 事件驱动 :
reloadCh这个 channel 将"何时更新"的控制逻辑与"如何更新"的执行逻辑解耦。
**🦴 骨架完善** :第三根支柱加入:传统同步原语 (sync/atomic) 用于保护微观的、高频访问的共享状态。它们在 Channel 构建的宏观流程内部,提供精准、高效的同步补丁。
V5:泛型与中间件管道
最后,随着 Go 1.18 泛型的到来,我们开始重构那些充斥着 interface{} 的通用中间件(如鉴权、日志、指标收集)。目标是类型安全,且不损失性能。
go
// 定义中间件函数类型
type Middleware[T any] func(ctx context.Context, req T) (context.Context, error)
// 泛型化的链式组合函数
func Chain[T any](mw ...Middleware[T]) Middleware[T] {
return func(ctx context.Context, req T) (context.Context, error) {
var err error
for _, m := range mw {
if ctx, err = m(ctx, req); err != nil {
return ctx, err
}
}
return ctx, nil
}
}
// 具体中间件,现在是类型安全的
func AuthMiddleware[T any]() Middleware[T] {
return func(ctx context.Context, req T) (context.Context, error) {
// 从 req 中安全地提取 token 字段(如果结构体有)
// 类型安全,无需断言
return ctx, nil
}
}
// 在请求处理器中使用
var userRequestChain = Chain[UserRequest](
LoggingMiddleware[UserRequest](),
AuthMiddleware[UserRequest](),
RateLimitMiddleware[UserRequest](),
)**✅ 收益**:
- 编译期安全 :中间件链现在在编译时就知道它处理的是
UserRequest还是OrderRequest,杜绝了运行时类型断言失败的错误。 - 零额外开销:泛型在编译后生成具体类型的函数副本,性能与手写代码一致。
- 骨架的润滑剂 :它让并发骨架中的"处理逻辑"组件变得更可靠、更易复用,但并未改变
goroutine + channel + context的核心通信与协调模型。
总结:一个健壮的并发骨架
回顾这个网关的演进:
- Context 是骨架的神经系统,传递着"开始"、"超时"、"取消"的指令,确保整个系统可被控制。
- Goroutine 是骨架的肌肉纤维,轻量而有力,承载着具体的计算与 I/O 任务。
- Channel 是骨架的血管与韧带,在组件间传递数据与信号,实现协调与流动。
- sync/atomic 是骨架的关节与软骨,在关键连接点提供稳固、高效的同步。
- 泛型 是骨架的标准化接口,让肌肉(逻辑)能够更安全、灵活地附着在骨骼之上。
这个骨架不是通过一次惊天动地的设计完成的,而是在解决"资源泄漏"、"延迟过高"、"状态不一致"等一个个具体问题的过程中,将 Go 并发工具箱中的工具,在正确的层级上组合、演进而来。它最终赋予服务的,是一种名为 "可预测性" 的韧性------无论流量高低,你都能清晰地知道请求如何流动、如何结束、资源如何回收。而这,正是复杂微服务系统中最宝贵的东西。
七、实时数据流的背压艺术:从日志到指标
上一章,我们谈到了网关架构中 Fan-in/Fan-in 聚合模式留下了一个隐患:当上游产生数据的速度远超下游处理能力时,即使有超时控制,数据的堆积也会悄无声息地发生。这种由速率不匹配 导致的隐式背压,在日志、指标这类高吞吐实时数据流系统中尤为致命------它不像错误会立刻失败,而是像缓慢的失血,最终导致内存溢出(OOM)和服务崩溃。
背压 ,本质上是一种反馈控制系统 。它的目标不是阻止数据流动,而是让快速的生产者(Producer)感知到慢速的消费者(Consumer)的压力,并主动调节自己的生产节奏,从而维持系统的稳定。在 Go 的并发世界里,实现背压的艺术,就是如何精巧地运用 channel、select 和同步原语,将"压力"信号可视化与可管控。
问题的根源:当 Channel 不再是银弹
假设一个简单的日志收集流水线:
go
func logPipeline(logCh <-chan string) {
// 处理阶段:格式化并发送到远程ES
for log := range logCh {
formatted := expensiveFormat(log)
sendToElasticsearch(formatted) // 可能很慢或阻塞
}
}生产者源源不断地向 logCh 写入日志。如果 sendToElasticsearch 网络抖动或下游存储变慢,这个 for-range 循环就会阻塞。在无缓冲或缓冲已满的 channel 上,阻塞会反向传导给上游的发送方。
此时,你面临三个经典但都不够好的选择:
- 阻塞式发送 (
ch <- data)- 问题 :上游发送
goroutine被挂起,整个生产流程停滞。如果阻塞的goroutine很多,可能耗尽调度资源。
- 问题 :上游发送
- 无限缓冲的 Channel (
make(chan T, bufferSize))- 问题 :
bufferSize设为很大(如 10000),这仅仅是将内存爆炸的时间点推后,并未解决问题,反而掩盖了问题,使系统在 OOM 前毫无预警。
- 问题 :
- 非阻塞发送 (
select + default)- 问题:数据被直接丢弃,对业务不可接受。
go
select {
case logCh <- log:
// 成功发送
default:
// 缓冲满,直接丢弃这条日志
}显然,我们需要更细腻的策略。
构建显式背压:从缓冲到信号
背压设计的核心是:让生产者"知道"下游的拥堵,并做出有策略的响应。
策略一:固定缓冲 + 可控丢弃/降级
这是第一步。使用一个合理大小的缓冲池,并定义明确的丢弃策略。
go
type BoundedLogger struct {
logCh chan string
dropCount atomic.Int64 // 使用 Go 1.19+ 的 atomic 类型
}
func NewBoundedLogger(bufferSize int) *BoundedLogger {
return &BoundedLogger{
logCh: make(chan string, bufferSize),
}
}
func (b *BoundedLogger) TryLog(log string) {
select {
case b.logCh <- log:
// 成功入队
default:
// 缓冲已满,执行降级策略
b.dropCount.Add(1)
// 策略A: 采样记录,保证关键信息不丢
if rand.Float64() < 0.01 { // 1%采样率
b.logCh <- fmt.Sprintf("[DROPPED_SAMPLE]: %s", log)
}
// 策略B: 写入本地磁盘临时文件(慢速后备通道)
// writeToLocalTmp(log)
}
}这种方法让系统从"静默失败"变为"可观测的降级"。通过 atomic.Int64 监控 dropCount,运维可以清晰地看到背压触发的频率,从而调整缓冲大小或扩容下游处理能力。
策略二:动态背压信号(Token Bucket / 滑动窗口)
当固定缓冲不够灵活时,我们需要一个能动态反映下游处理能力的信号。这可以通过一个独立的"信号 channel" 或 令牌桶 来实现。
令牌桶 是一个经典的限流算法,但它也可以用作背压信号。下游的消费者根据自身处理能力,定期向桶中补充"令牌"。生产者必须拿到令牌,才能发送数据。
go
type TokenBucket struct {
tokens chan struct{}
stopCh chan struct{}
}
func NewTokenBucket(capacity, refillRate int) *TokenBucket {
tb := &TokenBucket{
tokens: make(chan struct{}, capacity),
stopCh: make(chan struct{}),
}
// 启动令牌补充协程
go func() {
ticker := time.NewTicker(time.Second / time.Duration(refillRate))
defer ticker.Stop()
for {
select {
case <-ticker.C:
select {
case tb.tokens <- struct{}{}:
default: // 桶满,令牌丢弃
}
case <-tb.stopCh:
return
}
}
}()
return tb
}
// 生产者发送前必须获取令牌
func (tb *TokenBucket) SendWithBackpressure(data string, dataCh chan<- string) bool {
select {
case <-tb.tokens: // 获取令牌
select {
case dataCh <- data:
return true
default:
// 即使有令牌,但dataCh瞬时也满了?把令牌还回去(或丢弃)
// 这说明了背压信号的层级:有发送权 != 一定能发送
return false
}
default:
// 没有令牌,立刻返回背压状态
return false
}
}在这种模型下,下游的处理速率 refillRate 直接控制了上游的发送上限。上游的 SendWithBackpressure 方法会立即返回成功或失败,调用方可以根据失败情况决定是重试、丢弃还是暂存到二级队列。
策略三:select 与 context 的超时竞赛
对于不能丢失的数据,我们可以引入超时等待机制,让背压在一个时间窗口内有机会缓解。
go
func SendWithTimeout(data string, dataCh chan<- string, timeout time.Duration) error {
ctx, cancel := context.WithTimeout(context.Background(), timeout)
defer cancel()
select {
case dataCh <- data:
return nil
case <-ctx.Done():
return ctx.Err() // 在超时时间内依然无法写入,返回背压超时错误
}
}调用方收到 context.DeadlineExceeded 错误后,可以触发更高级别的降级,比如写入一个更慢但更可靠的持久化队列。这保证了在短暂拥塞时数据不丢,在长期拥塞时也有明确的失败边界。
综合实战:一个可背压的指标聚合器
让我们把这些策略组合起来,设计一个从服务实例收集指标的聚合器,它需要应对实例数量突增(生产者激增)或远端存储故障(消费者卡住)的场景。
go
type MetricsAggregator struct {
// 输入通道,带缓冲
metricCh chan Metric
// 背压信号通道,容量代表当前可处理额度
pressureTokenCh chan struct{}
// 停止信号
stopCh chan struct{}
wg sync.WaitGroup
}
func NewMetricsAggregator(bufferSize, concurrency int) *MetricsAggregator {
ma := &MetricsAggregator{
metricCh: make(chan Metric, bufferSize),
pressureTokenCh: make(chan struct{}, concurrency), // 令牌数等于并发处理数
stopCh: make(chan struct{}),
}
// 初始化令牌桶,代表并发处理能力
for i := 0; i < concurrency; i++ {
ma.pressureTokenCh <- struct{}{}
}
// 启动处理工作池
ma.wg.Add(concurrency)
for i := 0; i < concurrency; i++ {
go ma.processWorker()
}
return ma
}
func (ma *MetricsAggregator) Submit(m Metric) error {
// 带超时的背压写入
select {
case ma.metricCh <- m:
return nil
case <-time.After(50 * time.Millisecond): // 背压等待超时
atomic.AddInt64(&dropMetrics, 1)
// 写入本地环形缓冲或低优先级队列,等待系统恢复
return ErrBackpressureTimeout
}
}
func (ma *MetricsAggregator) processWorker() {
defer ma.wg.Done()
for {
select {
case <-ma.stopCh:
return
case metric := <-ma.metricCh:
// 1. 获取处理令牌(背压关键点)
<-ma.pressureTokenCh
// 2. 处理(可能是慢速I/O)
processAndUpload(metric)
// 3. 归还令牌,代表一个处理槽位释放
ma.pressureTokenCh <- struct{}{}
}
}
}这个设计实现了多级背压:
- **第一级(
Submit 超时)**:防止metricCh堆积过长,超过 50ms 就降级。 - **第二级(
pressureTokenCh )**:核心机制。processWorker只有在拿到令牌后才会进行实际处理。下游 processAndUpload 的耗时直接决定了令牌的释放频率,从而控制了 Submit 中能成功通过第一级 metricCh 的数据量。 - 工作池的
concurrency参数,明确限定了最大并行处理数,避免了慢速下游拖垮所有goroutine。
哲学与边界
背压艺术的价值在于,它将系统从"开环"的盲目喷射,变成了"闭环"的适应性系统。通过 channel、select、atomic 计数器构成的反馈网络,压力变得可见、可度量、可控制。
然而,Go 的 channel 终究是内存队列。在极端场景下,例如整机断电,内存中的数据依然会丢失。因此,真正的"背压"需要与持久化机制结合。当内存缓冲持续告急时,背压控制器应该能自动将数据流切换到磁盘队列,并发出告警------这便进入了"流控"与"稳定性工程"的更深领域。
这也引出了下一个问题:当我们用一个全局的 map 来缓存这些实时计算出来的指标时,如何避免这个共享状态成为新的性能瓶颈和死锁陷阱?这便是我们下一章要探讨的舞蹈:在 mutex 与 channel 之间,为缓存系统寻找最优的锁分片策略。
八、缓存系统的锁分片:在 mutex 与 channel 之间跳舞
缓存,是性能的加速器,也常常是并发的风暴眼。当 QPS 冲上十万、百万,那个保护着全局 map[string]*CacheItem 的 sync.RWMutex,就从沉默的守护者变成了喧嚣的瓶颈。每一个 Get() 和 Set() 请求,无论它们访问的是键 "user:1001" 还是 "product:9999",都在排队等待同一把锁。我们的并发系统,在宏观上用 channel 编织出流畅的数据流,却在微观的缓存层,被一把大锁拖回了串行时代。
是时候让锁也"分而治之"了。这就是**锁分片(Lock Sharding)**的核心:将一个大锁,拆成 N 个小锁,每个小锁只保护哈希映射中一个特定的片段(Shard)。
实现方案:从一把大锁到 N 把小锁
最直接的实现,是将一个 map 拆成 N 个 map,每个配一把独立的锁。
go
// ShardedMap 的基础结构
type Shard struct {
sync.RWMutex
data map[string]interface{}
}
type ShardedMap []*Shard
func NewShardedMap(shardCount int) ShardedMap {
shards := make([]*Shard, shardCount)
for i := 0; i < shardCount; i++ {
shards[i] = &Shard{data: make(map[string]interface{})}
}
return shards
}
// 关键:通过哈希函数决定键属于哪个分片
func (m ShardedMap) getShard(key string) *Shard {
// 一个简单的哈希示例:将字符串键转换为分片索引
hash := fnv.New32a()
hash.Write([]byte(key))
return m[int(hash.Sum32())%len(m)]
}
func (m ShardedMap) Get(key string) (interface{}, bool) {
shard := m.getShard(key)
shard.RLock()
defer shard.RUnlock()
return shard.data[key]
}
func (m ShardedMap) Set(key string, value interface{}) {
shard := m.getShard(key)
shard.Lock()
defer shard.Unlock()
shard.data[key] = value
}这个模式的神奇之处在于:访问 keyA 和 keyB 的两个 goroutine,如果它们的哈希值落在不同的分片,就能实现真正的并行读写,锁竞争被限制在分片内部。分片数 N 通常设置为 CPU 核心数的 2-4 倍,或者一个不会过大的 2 的幂(如 64、256)。
变体与增强:读多写少与无锁读
对于典型的"读远多于写"的配置缓存场景,我们可以结合之前提到的 atomic.Value 进行增强,实现无锁读。
go
type ConfigShard struct {
mu sync.Mutex
cache atomic.Value // 存储 *ConfigData
}
func (s *ConfigShard) HotReload(newData *ConfigData) {
s.mu.Lock()
defer s.mu.Unlock()
s.cache.Store(newData) // 原子替换,瞬间生效
}
func (s *ConfigShard) Get() *ConfigData {
return s.cache.Load().(*ConfigData) // 原子读取,完全无锁
}在这个方案里,写(热更新)仍然需要互斥锁来序列化,防止并发更新导致数据错乱。但所有的读操作都是原子和无锁的,性能达到极致。我们可以为不同类型的配置(如路由配置、特性开关)建立不同的分片,进一步分散写入时的锁压力。
为什么不是分片 Channel?
一个自然的疑问是:既然 Go 推崇 "share memory by communicating",我们能否为每个分片创建一个专属的 goroutine 和 channel,让所有访问都通过 channel 发送"指令"给这个 goroutine 来串行处理呢?
这听起来很 CSP,但在缓存这种超高频、超低延迟的访问场景下,它通常会带来反效果:
- 通信开销:即使是无缓冲 channel,一次通信也涉及 goroutine 调度和上下文切换,其开销远大于直接获取一个已空闲的互斥锁。
- 序列化瓶颈:一个分片 channel 后的 goroutine 依然是串行处理请求,其吞吐上限受限于单个 goroutine 的处理速度,而锁分片方案在无冲突时允许多个 goroutine 真正并行。
- 复杂性:你需要管理分片 goroutine 的生命周期、优雅退出、channel 关闭等问题,增加了系统状态复杂度。
因此,在缓存锁分片这一特定问题上,"通过细粒度锁来保护共享内存" 是比 "通过分片通信来共享内存" 更务实、性能更优的选择。这完美诠释了 Go 并发工具箱的哲学:channel 用于流程编排,mutex 用于性能临界区的状态保护。两者各司其职,在系统架构的不同层级上共舞。
设计哲学:在 "正确" 与 "高效" 间寻找平衡
锁分片的设计,是空间(更多锁和 map 结构)换时间(更低的锁竞争)的经典权衡。它引入了新的考量:
- 分片函数:需要足够均匀,防止某些分片过热。对于非字符串键,需设计合适的哈希。
- 跨分片事务:如果需要原子性地更新多个分片中的键,就需要按固定全局顺序(如按分片 ID 从小到大)加锁,严防死锁。
- 监控与动态调整:在高级系统中,分片数量甚至哈希算法本身,都可能根据运行时负载进行动态调整。
最终,当你看到缓存层的 p99 延迟从毫秒级跌回微秒级,你就知道,这场在 mutex 与 channel 之间精心编排的舞蹈,值回了所有深思熟虑的设计票价。