目录
[1.1.步骤1:申请API KEY](#1.1.步骤1:申请API KEY)
[2.4 步骤4:调用大模型](#2.4 步骤4:调用大模型)
[3.1 Runnable 接口:所有组件的统一操作方式](#3.1 Runnable 接口:所有组件的统一操作方式)
[3.2 LCEL:用简单的符号把多个 Runnable 串联起来](#3.2 LCEL:用简单的符号把多个 Runnable 串联起来)
一.快速上手
我们这里以DeepSeek大模型为例
1.1.步骤1:申请API KEY
首先我们需要去DeepSeek这里申请一下API key:DeepSeek 开放平台
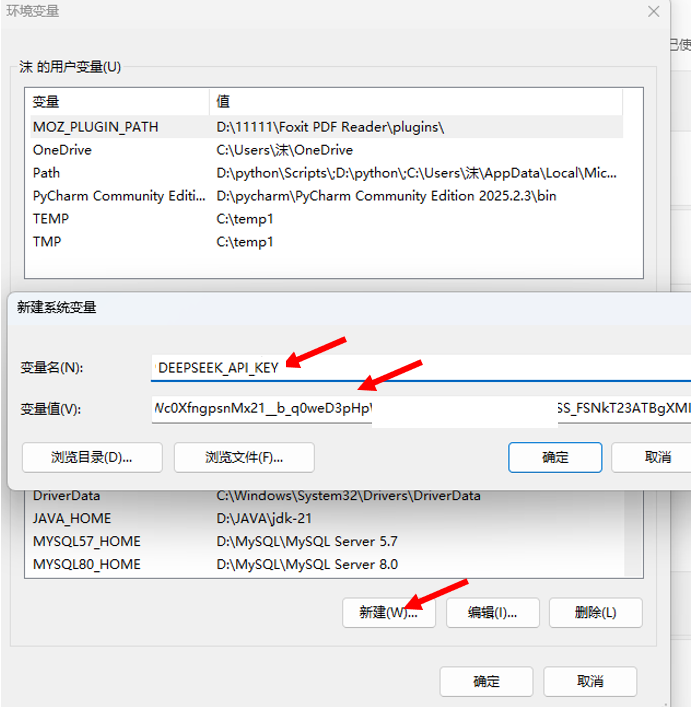
然后我们需要将我们获取到的这个API key配置到我们的系统环境变量里面,这样子代码里面就不要去写我们的API key了
1.2.步骤2:定义大模型
安装DeepSeek包
pip install -U langchain-deepseek接下来我们定义我们的大模型
python
from langchain_deepseek import ChatDeepSeek
model = ChatDeepSeek(model="deepseek-chat")有人可能就会问了,为什么这里不需要写这个API KEY呢?
事实上这个ChatDeepSeek 函数默认会去读取一个叫 DEEPSEEK_API_KEY的环境变量,这个环境变量里面存储的就是我们的API KEY。也就是我们上面设置的
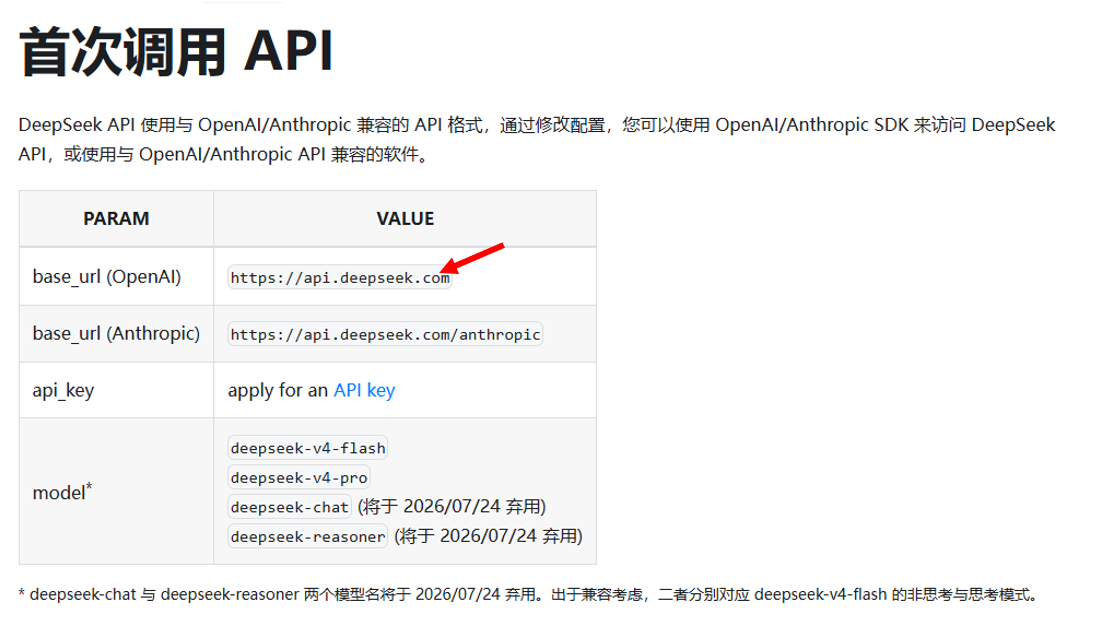
具体的model我们可以去官网看看:首次调用 API | DeepSeek API Docs
1.3.步骤3:定义消息列表
在使用 LangChain 与大语言模型交互时,通常需要将对话内容表示为一系列消息。每条消息都有明确的角色,用来区分这段话是谁说的。LangChain 提供了多种消息类型,其中最基础、最常用的是以下两种:
核心代码
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="Translate the following from English into Chinese"),
HumanMessage(content="hi!"),
]参数说明
- SystemMessage(系统角色消息)
- 表示来自系统或开发者的指令性消息。系统消息通常作为输入消息序列中的第一条传入,用来设定 AI 的行为模式、回答风格、任务目标或安全边界。在上面的例子中,系统消息告诉模型:"接下来的对话中,请把英文翻译成中文"。系统消息的内容不会被用户看到,它只用于指导模型的行为。
- HumanMessage(用户角色消息)
- 表示来自用户的消息,是用户传递给模型的实际问题或请求。在上面的例子中,用户发送的内容是 "hi!",模型在接收到系统消息的指令后,会按照"翻译"的要求,将用户的 "hi!" 翻译成中文(例如输出"你好!")。
补充说明
在一个对话序列中,通常可以包含多条 HumanMessage 和 AssistantMessage(模型回答的消息),从而实现多轮对话。而 SystemMessage 一般只在开始时设置一次,用来固定模型的行为基调。例如:
- 系统消息:"你是一个专业的医疗助手,回答必须基于权威资料,不确定时请建议就医。"
- 用户消息:"我头痛两天了,可以吃什么药?"
- 模型消息(即 AIMessage):"根据您的描述,建议先测量体温......"
这种角色划分机制,使得开发者能够清晰地区分"指令"和"提问",从而更精确地控制模型的输出结果。
2.4 步骤4:调用大模型
在 LangChain 中,model 对象是"可运行接口"的一个实例。这意味着我们通过一个统一的标准接口来与模型交互。要简单地调用模型,可以将之前构建好的消息列表直接传递给 model 的 invoke 方法。
核心操作说明
-
调用
model.invoke(messages)方法,其中messages是我们之前定义好的包含系统消息和用户消息的列表。 -
该方法会向大语言模型发送请求,并返回模型的回答结果。
-
将返回的结果赋值给一个变量(例如
result),然后通过打印该变量来查看模型的输出。
核心代码
result = model.invoke(messages)
print(result)1.5.步骤5:输出解析
那么到这里,我们可以先写一个初步的小demo
python
from langchain_deepseek import ChatDeepSeek
from langchain_core.messages import HumanMessage, SystemMessage
model = ChatDeepSeek(model="deepseek-chat")
messages = [
SystemMessage(content="Translate the following from English into Chinese"),
HumanMessage(content="hi!"),
]
result = model.invoke(messages)
print(result)我们这里的运行结果如下
python
D:\pycharm\PythonProject\.venv\Scripts\python.exe D:\pycharm\PythonProject\main.py
content='你好!' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 2, 'prompt_tokens': 13, 'total_tokens': 15, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 13}, 'model_provider': 'openai', 'model_name': 'deepseek-v4-flash', 'system_fingerprint': 'fp_058df29938_prod0820_fp8_kvcache_20260402', 'id': 'ff086a72-418c-402d-b385-1e24f41410cc', 'finish_reason': 'stop', 'logprobs': None} id='lc_run--019dc40f-e7e6-7bc1-b3f3-f82b5cd5d855-0' tool_calls=[] invalid_tool_calls=[] usage_metadata={'input_tokens': 13, 'output_tokens': 2, 'total_tokens': 15, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}
进程已结束,退出代码为 0在上一步中,我们调用模型后得到了一个 AIMessage 类型的对象,其中包含了模型的回答内容(content 字段)以及**许多附加的元数据(**如令牌使用情况、模型名称等)。但在实际应用程序中,我们往往只需要模型生成的纯文本内容,而不需要那些调试用的元数据。
为此,LangChain 提供了一个名为 StrOutputParser 的输出解析器组件。
它的作用非常简单:将模型返回的 AIMessage 对象解析成最可能的字符串形式,也就是只提取出 content 字段的文本内容。
使用流程说明
- 导入组件:从 langchain_core.output_parsers 中导入 StrOutputParser 类。
- 创建解析器实例:实例化一个 StrOutputParser 对象,可以给它起一个名字,比如 parser。
- 执行解析:调用解析器的 invoke 方法,并将上一步得到的模型调用结果(即 AIMessage 对象)作为参数传入。
- 获取纯文本:invoke 方法会返回一个字符串,这就是模型回答的纯文本内容。
也就是下面这样子
python
# 定义str字符串输出解析器
from langchain_core.output_parsers import StrOutputParser
parser = StrOutputParser()
print(parser.invoke(result))1.6.步骤6:链式执行
通过前面几个步骤,我们可以看到:无论是调用大模型,还是对模型输出进行解析,每一步都需要手动调用一次 invoke 方法,才能得到想要的结果。例如,先调用模型的 invoke 获得 AIMessage,再调用解析器的 invoke 获得纯文本字符串。
LangChain 提供了一种更高效的执行方式------链式执行 。它的核心思想是:开发者只需要定义好各个组件(比如模型、输出解析器等),然后将它们链起来(用某种方式连接),最后一次性执行这个链,就能直接得到最终结果,而无需分步手动调用。
注意:这里的描述是为了便于理解,并非 LangChain 中"链"的严格定义。等您看完示例后,我们会引出更准确的定义。
python
# 定义执行链
chain = model | parser
# 执⾏链
result = chain.invoke(messages)
print(result)可以看到这个chain就是一个链。
1.7.完整流程
快速上手完整流程总结
整个快速上手的流程可以概括为以下步骤:
-
导入所需的类:模型类(从
langchain_openai导入ChatOpenAI)、消息类(系统消息和用户消息)、输出解析器(StrOutputParser)。 -
定义模型实例(选择具体模型,如 GPT-5-mini)。
-
定义消息列表(系统消息设定任务,例如"将英文翻译成中文";用户消息输入具体内容,例如"hi!")。
-
定义输出解析器实例(
StrOutputParser)。 -
使用管道操作符将模型和解析器组合成一个链。
-
调用链的
invoke方法,传入消息列表,获得最终结果字符串。 -
打印结果。
通过这种方式,您可以用极少的代码实现一个完整的"提示词 → 模型调用 → 输出解析"流程,这也是 LangChain 中最基础、最常用的编程模式。
python
# 导入 DeepSeek 的聊天模型类(专门用于调用 DeepSeek API)
from langchain_deepseek import ChatDeepSeek
# 导入消息类型:SystemMessage 用于设定系统指令,HumanMessage 用于用户输入
from langchain_core.messages import HumanMessage, SystemMessage
# 导入字符串输出解析器,将模型的 AIMessage 对象转换为纯文本字符串
from langchain_core.output_parsers import StrOutputParser
# 创建 DeepSeek 聊天模型实例
# model="deepseek-chat" 指定使用 DeepSeek 的通用对话模型
model = ChatDeepSeek(model="deepseek-chat")
# 定义消息列表,按顺序发送给模型
messages = [
# 系统消息:设定任务角色,让模型把英文翻译成中文
SystemMessage(content="Translate the following from English into Chinese"),
# 用户消息:实际的输入内容,这里是一个简单的 "hi!"
HumanMessage(content="hi!"),
]
# 创建字符串输出解析器,后续会将模型的复杂输出对象简化为纯字符串
parser = StrOutputParser()
# 定义执行链(LangChain 表达式语法 LCEL)
# 使用管道符 | 将模型和解析器串联起来:模型先处理消息,然后解析器提取 .content
chain = model | parser
# 执行链:将消息列表传入,模型翻译 + 解析器提取文本,最终得到纯字符串结果
result = chain.invoke(messages)
# 打印翻译后的结果(预期输出应该是 "你好!" 或类似的问候)
print(result)运行结果

这个就比较简单了吧!!
二.引出LangChain相关概念
3.1 Runnable 接口:所有组件的统一操作方式
在 LangChain 中,每个功能模块(比如语言模型、输出解析器、检索器等)都被设计成一种叫做 Runnable 的东西。你可以把 Runnable 理解为"可以被执行的任务单元"。
Runnable 定义了一套统一的操作方法。无论你面对的是哪种模块,都可以用同样的方式进行以下四种操作:
-
单独执行(invoke)
给这个任务单元一个输入,它就会产生一个输出。就像你向模型发送一条消息,它返回一个回答。
-
批量执行(batch)
一次性给这个任务单元多个输入,它会把每个输入分别处理,然后一次性返回所有对应的输出。这比用循环一个个执行要快。
-
流式执行(stream)
当你希望输出不是一次性全部得到,而是一边生成一边拿到部分结果时,可以使用流式执行。比如模型生成长文本时,你可以逐字或逐句地接收,而不必等到全部生成完毕。
-
检查内部信息(inspect)
你可以查看这个任务单元的输入格式、输出格式、配置参数等元信息,方便调试和理解。
-
......
其实还有很多,我们可以去官网看看:Runnable | langchain_core | LangChain Reference
除此之外,多个 Runnable 还可以 组合 在一起。这是通过下一节要讲的 LCEL 来实现的。
回顾快速上手中的例子:
python
# 导入所需的 LangChain 组件
from langchain_openai import ChatOpenAI # 复用 OpenAI 兼容的接口类
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
# 1. 定义大模型实例 ------ 改为 DeepSeek 配置
model = ChatOpenAI(
model="deepseek-chat", # DeepSeek 对话模型名称
api_key="你的DeepSeek API Key", # 替换为你在 platform.deepseek.com 获取的密钥
base_url="https://api.deepseek.com" # DeepSeek 的 API 端点
)
# 2. 定义消息列表:包含系统指令和用户输入
messages = [
SystemMessage(content="Translate the following from English into Chinese"),
HumanMessage(content="hi!"),
]
# 3. 定义输出解析器
parser = StrOutputParser()
# 4. 构建链
chain = model | parser
# 5. 执行链
result = chain.invoke(messages)
# 6. 打印结果
print(result)- model(语言模型)是一个 Runnable。你可以调用它的 invoke 方法,传入消息列表,得到一个回答(AIMessage 对象)。
- parser(输出解析器)也是一个 Runnable。你可以调用它的 invoke 方法,传入 AIMessage 对象,得到一个纯文本字符串。
因为两者都是 Runnable,所以它们的使用方式完全一致:都是调用 .invoke() 来执行。
3.2 LCEL:用简单的符号把多个 Runnable 串联起来
LCEL是LangChainExpression Language:采⽤声明性⽅法,从现有Runnable对象构建新的 Runnable对象。
LCEL 的全称是 LangChain 表达式语言,它是一种用来 将多个 Runnable 连接成一条处理流水线 的写法。
通过 LCEL,你可以用竖线符号 | 把两个 Runnable 连起来,形成一个新的 Runnable,这个新的 Runnable 叫做 RunnableSequence(可运行序列),也就是我们常说的"链"。
具体做法:
- 假设你有一个 model(语言模型)和一个 parser(输出解析器)。
- 你可以写:chain = model | parser。
- 这个 chain 本身也是一个 Runnable,它可以像 model 和 parser 一样被调用(例如 chain.invoke(messages))。
执行过程:
- 当你调用 chain.invoke(messages) 时:
- 首先,messages 被传递给 model,model 执行并返回一个 AIMessage 对象。
- 然后,这个 AIMessage 对象自动被传递给 parser,parser 执行并返回一个纯文本字符串。
- 最终,chain.invoke() 返回这个纯文本字符串。
也就是说,| 的作用就是把前一个 Runnable 的输出,原封不动地作为后一个 Runnable 的输入,并自动按顺序执行。
为什么叫 LCEL?
因为它是一种表达式语言,专门用来描述 Runnable 之间的连接关系,而且这种描述是"声明式"的------你只需要声明要连接哪些组件,而不需要写代码去手动传递数据。
python
chain = model | parser其他等价写法:
除了使用 | 符号,你还可以使用以下两种方式达到完全相同的效果:
显式创建 RunnableSequence 对象:
python
from langchain_core.runnables import RunnableSequence
chain = RunnableSequence(first=model, last=parser)使用 .pipe 方法:
python
chain = model.pipe(parser).pipe 这个名称来源于 Unix/Linux 系统中的管道概念,但在你目前的学习阶段,只需要知道它和 | 的作用一样即可。
核心要点:
- 任何两个 Runnable 都可以用 | 连接成链。
- 链本身也是 Runnable,所以可以继续与其他 Runnable 连接。
- 这样,你可以用非常简单的代码,构建出由多个步骤组成的复杂处理流程。
三.通过API定义聊天模型
3.1.方式一:调用ChatOpenAI这种专门的接口
ChatOpenAI 是 LangChain 中专门用来调用 OpenAI 公司提供的聊天模型(例如 gpt-5 或 gpt-5-mini)的一个工具。它已经提前封装好了与 OpenAI 服务通信的细节,您只需要设置好参数就能直接使用。
下面列出创建 ChatOpenAI 对象时最常用的参数,以及每个参数具体控制什么。所有说明都不包含代码,也不使用比喻。
常用参数说明
model
- 指定要使用哪一个 OpenAI 模型。例如 gpt-5 或 gpt-5-mini。不同的模型在能力、速度、价格上都有区别。不设置时,系统会使用某个默认模型(通常是一个较通用的版本)。
temperature
- 控制模型输出内容的随机程度。
- 当该值较大(例如 0.8 或更高)时,模型更可能选择那些概率不算最高的词语,从而让生成的回答更加多样化,甚至会出现一些意料之外的词语组合。
- 当该值较小(例如 0.2 或更低)时,模型几乎总是选择概率最高的词语,因此回答会非常稳定、重复性强,更贴近训练数据中最常见的表达方式。
- 取值范围一般是 0 到 2(具体依模型而定)。如果不设置,大多数 OpenAI 模型会使用 1.0 作为默认值。
max_tokens
- 限制模型生成的回答最多能包含多少个"令牌"(token)。一个令牌可以大致理解为一个英文单词的一部分,或者一个中文字符。设置此参数可以避免模型回答过长得超出您的需要。如果不设置,模型会一直生成到自然停止或达到模型自身的上限。
timeout
- 每次请求 OpenAI 服务时,最长等待多长时间(单位通常是秒)。如果网络延迟高或服务端响应慢,超过了这个时间,这次请求就会被放弃并报错。这可以防止您的程序一直卡住。如果不设置,系统会使用一个默认的超时时间(例如 60 秒)。
max_retries
- 当请求因为网络波动、服务暂时繁忙等可恢复的原因失败时,最多再尝试多少次。例如设置为 3,则第一次失败后会重试 3 次,总共 4 次请求(1 次原始请求 + 3 次重试)。如果所有尝试都失败,最终会返回错误。不设置时,一般会有默认的重试次数(例如 2 次)。
openai_api_key(或 api_key)
- 您的 OpenAI API 密钥。这是访问 OpenAI 服务的凭证,必须正确提供。您可以直接在参数中填写密钥字符串;**如果不填写,系统会自动从环境变量 OPENAI_API_KEY 中读取。**建议使用环境变量的方式,避免把密钥写在代码里。
base_url
- 请求 OpenAI API 时使用的网络地址。正常情况下您不需要修改它,因为 LangChain 已经内置了 OpenAI 官方的地址。但如果您使用的是代理服务,或者某个与 OpenAI API 格式兼容的本地服务,可以通过这个参数把请求指向另一个地址。
organization
- 您在 OpenAI 中的组织 ID。如果您一个账号下关联了多个组织,可以通过这个参数指定使用哪个组织来计费或管理 API 调用。如果不填写,系统会从环境变量 OPENAI_ORG_ID 中读取。如果既不填写也没有环境变量,则使用您账号的默认组织。
......还有其他参数
补充说明:
- 以上参数中,只有 model 是强烈建议您主动设置的(否则可能用错模型),其他参数都有合理的默认值,可以按需调整。
- temperature 建议先使用 0.5 到 0.7 之间的值,获得既稳定又略带变化的回答;如果要求非常准确的固定答案,可以尝试 0 或 0.1。
- max_tokens 建议根据您期望的回答长度设置,例如对于简单问答设置 500 通常足够,对于长文本生成可以设置到 2000 以上。注意,设置过大并不会导致更快消耗,只是允许模型生成更长内容。
当然,除了 ChatOpenAI 这个专门用于 OpenAI 模型的接口外,LangChain 还为其他主流模型提供了类似的专用接口。例如,DeepSeek 模型对应 ChatDeepSeek,Kimi 模型(来自 Moonshot AI)对应 ChatMoonshot。这些接口都继承自统一的 BaseChatModel,因此它们的方法(如 invoke、stream 等)与 ChatOpenAI 完全一致。
3.2.方式二:init_chat_model
在 LangChain 里,如果你想用 OpenAI 的模型,通常会直接写 ChatOpenAI(...);想用 DeepSeek 的模型,就写 ChatDeepSeek(...)。
但是这样写比较死板:换一个模型就得改代码、改导入、改初始化方式。
init_chat_model 是一个 工厂函数 ------ 你只要告诉它"我要用哪个模型,哪个供应商提供的",它自动帮你创建对应的模型对象。
好处:代码统一,换模型成本低,甚至可以在运行时动态切换模型(后面会讲)。
基本用法
第一步:安装对应的包 + 设置 API Key
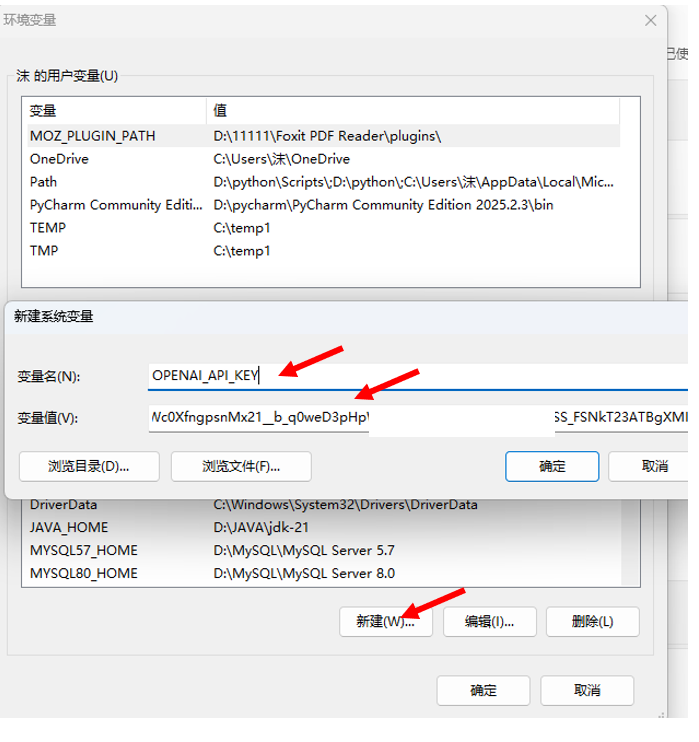
每种模型供应商需要单独安装 Python 包,并配置 API Key到指定环境变量里面:
- OpenAI:pip install langchain-openai,环境变量 OPENAI_API_KEY
- DeepSeek:pip install langchain-deepseek,环境变量 DEEPSEEK_API_KEY
- Anthropic:pip install langchain-anthropic,环境变量 ANTHROPIC_API_KEY
- Google VertexAI:pip install langchain-google-vertexai,环境变量 GOOGLE_API_KEY
- Ollama:pip install langchain-ollama(通常不需要额外 API Key)
你也可以在代码里直接传 api_key 参数,但环境变量更安全。
我们以OpenAI为例
第二步:创建模型实例
python
from langchain.chat_models import init_chat_model
# 创建一个 OpenAI 的 gpt-5-mini 模型
openai_model = init_chat_model("gpt-5-mini", model_provider="openai")
# 创建一个 DeepSeek 的 deepseek-chat 模型
deepseek_model = init_chat_model("deepseek-chat", model_provider="deepseek")
# 调用它们(因为所有模型都遵循相同的 ChatModel 接口)
print(openai_model.invoke("你叫什么名字?").content)
print(deepseek_model.invoke("你叫什么名字?").content)init_chat_model会自动去读取指定的系统变量。
运行的结果就是
python
我叫 ChatGPT,有什么可以帮您?
我是 DeepSeek Chat,你可以叫我 DeepSeek。怎么样?使用起来很简单吧!!
init_chat_model常用参数
init_chat_model 这个函数接受很多参数,其中最常用的几个我来挨个说明一下。
第一个参数是 model,它是一个字符串,表示你想用的模型的名字。
比如 OpenAI 的 "gpt-5-mini",DeepSeek 的 "deepseek-chat",或者 Anthropic 的 "claude-3-opus"。正常情况下这个参数是必须填的。
第二个参数是 model_provider ,也是一个字符串,用来指明模型是哪家供应商提供 的,比如 "openai"、"deepseek"、"anthropic" 等等。这个参数是可选的,因为 init_chat_model 会试着从模型名字推测供应商 ------比如说,模型名里如果以 gpt 开头,它就会猜是 OpenAI。但推测不一定百分百准确,所以为了代码清晰可靠,我建议你每次都明确写出来。
第三个参数是 temperature ,它是一个浮点数,用来控制回答的"创造性"。大多数模型的取值范围在 0 到 1 之间(有些模型可能支持更大)。如果你把 temperature 设为 0,模型就会变得最保守、最确定、最靠谱,每次回答都尽量一致。如果你把温度调高,比如 0.8,那回答就会更多样化、更天马行空,有时候会给你一些意想不到的内容。简单记:温度越低越"老实",温度越高越"放飞"。
第四个参数是 max_tokens ,这是一个整数,用来限制模型最多生成多少个 token。 你可能好奇 token 是什么:你可以粗略地理解为,1 个英文单词大约占 1 到 2 个 token,1 个汉字也大约占 1 到 2 个 token。设置了这个上限后,模型生成的内容如果快超过了,就会被截断。这个参数可以帮你控制回答的长度和成本。
关于 API 密钥,有两个名字:api_key 或者 openai_api_key(后者主要是为了兼容以前的命名)。你可以在代码里直接传入这个参数来提供你的 API 密钥。但更推荐的做法是**把它设置成环境变量,**比如 OpenAI 的就叫 OPENAI_API_KEY,DeepSeek 的叫 DEEPSEEK_API_KEY,这样代码里就不用明文写密钥了,也更安全。
第五个参数是 **base_url ,**这个参数一般用不到。它是一个字符串,用来自定义 API 的访问地址。正常情况我们都用官方默认的地址,但如果你需要使用代理服务,或者自己搭建了一个兼容 OpenAI 格式的本地服务,那就可以通过这个参数来改变请求的目标网址。
第六个参数是 timeout 是一个数字(可以是整数或浮点数),单位是秒。它限定了每次请求模型 API 最多等待多长时间,超时了就会抛出异常。设置这个可以防止因为网络问题或模型响应太慢而导致程序卡死在那里。
第七个参数是 max_retries 是一个整数,表示请求失败后最多重试几次。比如网络突然抖动了一下,或者服务端暂时繁忙,重试可能会成功。默认值通常是 2 或 3,如果你觉得不需要重试,可以设为 0。
最后两个是高级参数 configurable_fields 和 config_prefix,它们和你之前看到的"可配置模型"有关。
configurable_fields 用来**指定哪些参数可以在运行时动态修改。**你可以把它设为一个元组,比如 ("model", "temperature"),那就表示模型名字和温度这两个参数允许在调用时通过 config 来覆盖。你也可以直接写字符串 "any",表示所有参数都允许运行时修改。如果写 None 或者不写,那就表示不允许运行时修改(这是默认行为)。
config_prefix 是一个字符串,它给运行时参数的名字增加一个前缀。为什么需要这个呢?想象一下,你可能会在同一个程序里创建多个可配置模型,或者在一个配置字典里同时存放多套参数(比如一套给"第一个模型"用,一套给"第二个模型"用)。如果不加前缀,参数名就会冲突。加了前缀之后,比如前缀是 "first",那么你在运行时传给 config"configurable" 的字典里,就需要用 first_model、first_temperature 这样的名字,而不再是直接写 model 和 temperature。这样不同前缀的配置就可以共存,互不干扰。
......
假设你希望不仅模型能变,连温度、最大生成量也能动态变,并且你可能同时管理多套配置(比如一套叫"first",一套叫"second"),可以这样写:
python
from langchain.chat_models import init_chat_model
# 创建可配置模型,默认使用 DeepSeek Chat
configurable_model = init_chat_model(
model="deepseek-chat", # 默认模型:DeepSeek 的对话模型
temperature=0, # 默认温度
configurable_fields=("model", "temperature", "max_tokens"), # 允许运行时修改
config_prefix="first" # 运行时参数名前缀为 "first_"
)
# 调用时,动态覆盖模型、温度和最大 token 数(换成 DeepSeek Coder)
result = configurable_model.invoke(
"你叫什么名字?",
config={
"configurable": {
"first_model": "deepseek-coder", # 运行时换成 DeepSeek 的代码模型
"first_temperature": 0.5,
"first_max_tokens": 100,
}
}
)
print(result.content)invoke() 方法通常接受两个主要部分:
- 输入(input):你要传给模型的内容。例如一条用户消息 "你好,请介绍一下你自己"。
- 配置(config,可选):一个字典,用来控制这次调用的行为,比如设置运行时的模型参数、追踪 ID、元数据等。
调用后,invoke() 会返回模型生成的输出(通常是包含回答内容的对象)。
invoke() 的第二个参数 config 是一个 RunnableConfig 字典。这个字典最常用的字段是 configurable。
configurable 是什么?
- 它是一个字典,里面放的键值对可以在运行时动态覆盖模型创建时设定的参数,比如换一个模型、改温度、改最大 token 数等。
- 你可能会问:为什么需要运行时覆盖?
- 因为之前我们用 init_chat_model 的 configurable_fields 和 config_prefix 创建了一个 可配置模型 ------ 那个模型本身不绑死具体的参数,而是允许你在调用 invoke() 时通过 config 来"现场决定"用哪个模型、用什么温度。
我们再看一个例子
简单示例 2:可配置模型(动态切换不同 DeepSeek 模型)
python
from langchain.chat_models import init_chat_model
# 创建一个可配置模型,默认使用 deepseek-chat,但允许运行时修改
flexible_model = init_chat_model(
model="deepseek-chat", # 默认模型
temperature=0,
configurable_fields=("model", "temperature") # 允许动态改模型和温度
)
# 第一次调用:使用默认配置(deepseek-chat)
res1 = flexible_model.invoke("你叫什么名字?")
print("默认模型:", res1.content)
# 第二次调用:动态切换到 deepseek-coder(代码助手)
res2 = flexible_model.invoke(
"你叫什么名字?",
config={"configurable": {"model": "deepseek-coder"}}
)
print("切换到 coder 模型:", res2.content)
# 第三次调用:动态改模型 + 温度
res3 = flexible_model.invoke(
"你叫什么名字?",
config={"configurable": {"model": "deepseek-chat", "temperature": 0.9}}
)
print("改温度后:", res3.content)运行结果
python
默认模型: 你好!我叫DeepSeek,是由深度求索公司创造的AI助手。很高兴认识你!有什么我可以帮你的吗?无论是回答问题、提供建议,还是陪你聊聊天,我都乐意效劳!😊
切换到 coder 模型: 你好!我叫DeepSeek,是由深度求索公司创造的AI助手。很高兴认识你!有什么我可以帮你的吗?无论是回答问题、提供建议,还是陪你聊聊天,我都乐意效劳!😊
改温度后: 你好!我叫DeepSeek,是由深度求索公司创造的AI助手。很高兴认识你!有什么我可以帮你的吗?😊再看一个例子:简单示例 3:使用前缀管理多套配置
python
from langchain.chat_models import init_chat_model
# 创建带前缀的可配置模型
model_with_prefix = init_chat_model(
model="deepseek-chat",
temperature=0,
configurable_fields=("model", "temperature"),
config_prefix="my_prefix" # 运行时参数名前缀为 my_prefix_
)
# 调用时使用带前缀的参数名
response = model_with_prefix.invoke(
"你好",
config={
"configurable": {
"my_prefix_model": "deepseek-coder", # 注意前缀
"my_prefix_temperature": 0.2
}
}
)
print(response.content)运行结果
python
你好!很高兴见到你。有什么我可以帮你的吗?无论是聊天、解答问题,还是需要一些建议,我都在这里!😊什么时候用 init_chat_model 而不是直接写 ChatOpenAI?
直接写 ChatOpenAI:你的项目只用一家模型,代码里写死,不需要动态切换。这种方式更简单直接。
用 init_chat_model:
- 你需要同时支持多家模型,希望代码统一。
- 你想根据用户输入或配置文件在运行时选择模型。
- 你写一个通用函数,希望函数能处理任何模型供应商。
- 你想要"可配置模型"的能力,让模型名、温度等参数从外部(比如 API 请求)传入。
3.3.方式三:ChatOllama()
除了使用云端 API(OpenAI、DeepSeek、Kimi 等),LangChain 也支持本地部署的大型语言模型。一个非常流行的本地部署工具就是 Ollama。你可以在自己的电脑或服务器上通过 Ollama 运行各种开源模型(比如 DeepSeek、Llama、Mistral 等),完全不需要联网,也不消耗 API 费用。
LangChain 提供了 ChatOllama 这个类,专门用来连接本地 Ollama 服务,让你像调用云端模型一样,调用本地模型。
第一步:安装对应包
在使用 ChatOllama 之前,需要先安装 LangChain 的 Ollama 集成包。运行以下命令:
python
pip install -U langchain_ollama注意:你还需要提前安装并启动 Ollama,并且已经下载好了想要的模型(例如通过 ollama pull deepseek-r1:70b)。这不是 LangChain 的工作,而是 Ollama 的准备工作。
第二步:ChatOllama 是什么?
ChatOllama 是 LangChain 为 Ollama 部署的聊天模型 提供的一个具体实现类。它和之前讲过的 ChatOpenAI、ChatDeepSeek 一样,都实现了 Runnable 接口。
这意味着你同样可以调用它的 .invoke() 方法,传入用户问题,获取模型回答。
最大的区别在于:
- ChatOpenAI 通过网络请求 OpenAI 的云端服务器。
- ChatOllama 通过网络请求你自己电脑或局域网内的 Ollama 服务。所以不需要 API Key,也不产生费用。
第三步:常用参数详解(自然语言)
ChatOllama 在创建实例时,可以接受很多参数。下面解释最常用的几个,全部用文字描述,没有表格。
- model 参数:一个字符串,表示你要**使用 Ollama 中的哪个模型。**模型必须先通过 ollama pull 下载好。例如 "deepseek-r1:70b"、"llama3.2"、"mistral" 等。这是必填的。
- base_url 参数:一个字符串,**表示 Ollama 服务的访问地址。默认情况下,Ollama 启动后会在本机 http://localhost:11434 提供服务。**如果你在本机运行,通常可以不写这个参数(使用默认值)。但如果你要连接另一台机器上的 Ollama 服务(比如局域网内有一台 GPU 服务器),就需要设置成对应的地址,例如 "http://192.168.100.220:11434"。这个参数是可选的。
- temperature 参数:一个浮点数,控制回答的创造性。取值通常从 0 到 1。设为 0 时模型最保守、最确定;设为 0.8 时回答更多样、更天马行空。这个参数和云端模型是完全一样的含义。
- timeout 参数:一个数字(秒),设置请求 Ollama 服务的超时时间。如果模型生成太慢或者网络有问题,超过这个时间就会报错,防止程序卡死。
- num_ctx 参数:一个整数,表示上下文窗口的大小,单位是 token。默认值是 2048。简单说,这个值决定了模型能"记住"多长的对话历史或多大的输入文本。如果你需要处理很长的内容,可以把这个值调大(比如 4096、8192),但同时会消耗更多显存。
- num_gpu 参数:一个整数,表示使用多少块 GPU 来运行模型。
- 在 macOS 上,如果设为 1 表示启用金属(Metal)加速(利用苹果芯片的 GPU);设为 0 表示禁用 GPU,只用 CPU。
- 在 Linux/Windows 上,你可以指定 GPU 数量。这个参数主要用于性能调优,一般初学者可以不关心。
其他更高级的参数还有很多,但以上这些足够让你开始使用 ChatOllama。
下面是一个完整的例子,展示如何创建一个 ChatOllama 实例,并用 .invoke() 向本地模型提问。
python
from langchain_ollama import ChatOllama
# 创建 Ollama 聊天模型实例
ollama_model = ChatOllama(
model="deepseek-r1:70b", # 必须:Ollama 中的模型名
base_url="http://192.168.100.220:11434", # 可选:远程 Ollama 服务地址
temperature=0.7, # 可选:创造性
num_ctx=4096 # 可选:增大上下文窗口
)
# 调用 .invoke() 提问
response = ollama_model.invoke("请问你叫什么名字?")
# 打印模型的回答
print(response.content)如果 Ollama 服务运行在本地(默认地址),你可以省略 base_url 参数,简化为:
python
ollama_model = ChatOllama(model="deepseek-r1:70b")ChatOllama 同样支持在 invoke() 时传入 config 参数,用来动态修改某些行为(比如添加元数据、指定运行名称等)。不过,ChatOllama 本身不支持像 init_chat_model 那样的可配置字段动态修改模型参数(model、temperature 等),因为 ChatOllama 是一个具体的类,而不是可配置模拟器。
如果你需要运行时切换本地模型,可以创建多个 ChatOllama 实例,或者使用 init_chat_model 配合 model_provider="ollama",就像之前云端模型那样:
python
from langchain.chat_models import init_chat_model
# 使用 init_chat_model 创建可配置的 Ollama 模型
flexible_ollama = init_chat_model(
model="deepseek-r1:70b",
model_provider="ollama",
temperature=0,
configurable_fields=("model", "temperature")
)
# 运行时切换模型
response = flexible_ollama.invoke(
"你好",
config={"configurable": {"model": "llama3.2"}}
)