今天在抖音刷到一个视频:用WPS的`REGEXP`公式,直接从一堆乱序、混杂的文本记录中精准提取车牌号------看得我当场愣住,这个公式确实厉害。特此整理记录,供后续复用。
仅供参考。部分待优化。
> 注:本文所用为WPS 12.8.2.19315版本,该版本**仅支持`REGEXP`函数**(不支持`REGEXEXTRACT`或`REGEXREPLACE`等常见变体),故所有公式均基于`REGEXP`实现。官方文档详见文末参考资料。
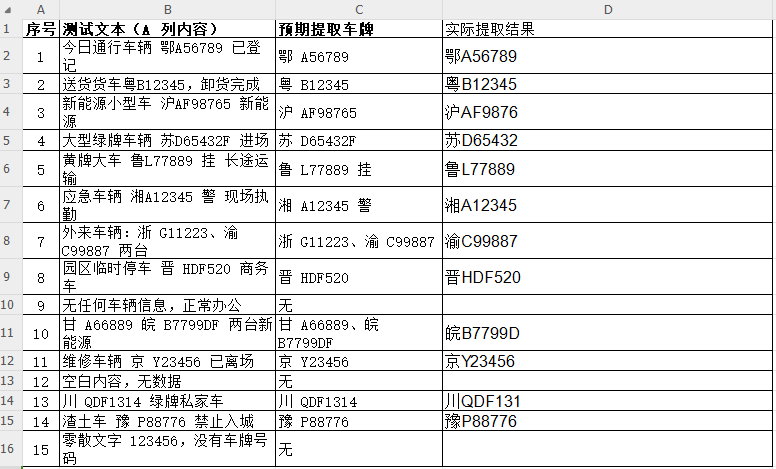
✅ 实战公式(可直接套用):
=IFERROR(LOOKUP(1,0/REGEXP(MID(SUBSTITUTE(B2,"",""),ROW(INDIRECT("1:"&LEN(SUBSTITUTE(B2,"",""))-6)),7),"^京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼A-ZA-Z0-9DF挂警{5,7}$",1),MID(SUBSTITUTE(B2,"",""),ROW(INDIRECT("1:"&LEN(SUBSTITUTE(B2,"",""))-6)),7)),"")
公式解析:
- SUBSTITUTE(B2,"","")`
→ 清除原始文本中所有空格(含全角、半角),确保字符连续无干扰;
- MID(..., ROW(INDIRECT("1:"&LEN(...)-6)), 7)`
→ 以滑动窗口方式,逐个截取长度为7的子字符串(因最短车牌为7字节:如"京A12345"共7字符);
- REGEXP(文本, 正则模式, 1)`
→ 在每个7字符片段中执行正则匹配,返回`TRUE/FALSE`逻辑值;
- LOOKUP(1,0/逻辑数组, 对应片段)`
→ 利用`0/TRUE=0`、`0/FALSE=#DIV/0!`的特性,定位首个匹配项并返回;
- IFERROR(...,"")`
→ 无匹配时返回空字符串,避免报错干扰。
正则模式详解:京津沪渝...宁琼A-ZA-Z0-9DF挂警{5,7}$`
-
^:字符串起始锚点;
-
京津沪渝...宁琼`:**第1位**------严格限定为全国31省市自治区汉字简称,杜绝错字、生造字;
-
A-Z:**第2位**------地市代码,仅允许大写英文字母(A--Z);
-
A-Z0-9DF挂警`:**第3--7位**------兼容全类型车牌:
✓ 普通蓝牌(5位):`京A12345`
✓ 新能源绿牌(6位):`京AD12345`(D/F为新能源专用字母)
✓ 黄牌/挂车/警用车(7位):`京A1234挂`、`京A1234警`
-
{5,7}:总长度控制为5--7字符(含省份+地市+号段),精准覆盖全部现行制式;
-
`$`:字符串结束锚点,确保匹配完整、不截断、不跨词。
WPS官方REGEXP使用说明
REGEXP
基于正则表达式,进行复杂文本的匹配、提取、替换,结果返回文本
(支持Perl兼容的正则表达式(PCRE)语法标准,默认区分大小写)
语法
REGEXP(text,regular_expression,match_pattern,replace_content)
Text 原始字符串。
regular_expression 匹配文本的正则表达式(必输项)
匹配文本的正则表达式
(正则表达式:匹配文本的正则表达式。支持Perl兼容的正则表达式(PCRE)语法标准,默认区分大小写)
Mtch_Pattern 匹配模式(默认0,非必输项)
0:提取,返回提取后的结果(数组)
1:判断,返回TRUE,FALSE(单值)
2:替换,返回替换后的结果(单值)
3:完整提取,无论参数一二是否为数组,都返回全部匹配结果(数组)
Replace_Content:替换内容(默认空文本)
第3个参数Type类型为2,替换模式时,此参数可用,可指定替换内容,省略参数替换内容为空文本(删除效果)
示例
=REGEXP("金山办公1988wps","\\d+",0)
或=REGEXP("金山办公1988wps","\\d+")
结果:1988
=REGEXP("金山办公1988wps","\\d+",1)
结果:True
=REGEXP("金山办公1988wps","\\d+",2)
结果:金山办公wps