文章目录
摘要
本周看了一篇论文《Accurate Scene Text Recognition with Efficient Model Scaling and Cloze Self-Distillation》,关于decoder-encoder模型应用于文字识别,利用填空自蒸馏来提升不同数据区间模型的鲁棒性和性能。
Abstract
This week I read a paper titled 'Accurate Scene Text Recognition with Efficient Model Scaling and Cloze Self-Distillation,' about the application of decoder-encoder models in text recognition, using cloze self-distillation to improve the robustness and performance of models across different data ranges.
1.Accurate Scene Text Recognition with Efficient Model Scaling and Cloze Self-Distillation

论文发现,在编解码模型中,编码器的大小对性能的影响比解码器要大,增大编码器的规模可以带来更好的结果。
训练数据中的噪声标签。他们分析表明,在某些情况下,视觉编码器的扩展可能导致收益递减或准确性下降,尤其是在STR模型训练于有限的真实数据时。在此背景下,我们观察到STR数据集的文本注释常常存在不一致、错误和噪声,这会对STR性能产生负面影响。
为解决这个问题,提出了一种新的填空自蒸馏(CSD)技术。在CSD中,首先训练一个作为教师的模型,用于生成训练数据的预测。然后通过Cloze fill方法对这些预测进行细化:每个字符都被重新预测,使用所有其他字符作为文本上下文,从而获得更准确、信息丰富且具上下文感知性的软预测。随后,我们将教师的硬预测作为实地真实和知识提炼项,将教师的有限上下文预测(通过置换语言建模获得)与教师全上下文填空预测之间的差异最小化,将教师提炼成同一训练集中的学生模型。该技术使学生能够在有限上下文限制下,更新其参数,适应教师更丰富、更具上下文感知的输出。实验证明CSD在减少标签噪声和不一致方面具有显著效果,从而显著提升表现。
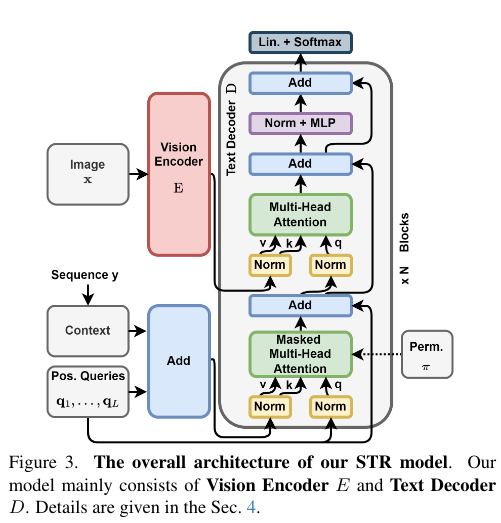
图2 模型结构
置换语言解码器(PLD)。为实现PLM,译码器D采用了特定的变换器架构,将查询流与键值流分离,以考虑其三个输入(方程8),并允许任意顺序解码序列。如图3所示,每个译码块由两个多头交叉注意力层和一个MLP组成,具有预归一化和跳跃连接。序列位置1, . . . , L嵌入到位置查询向量q1, . . . , qL中,这些向量是查询流的输入:为了预测位置θt中的字符,可以使用位置查询qεt。此外,位置查询也用作位置编码,并添加到上下文中,即嵌入的先前预测字符序列yω<t。值得注意的是,在第一层交叉注意力中,该符号作为键值流的输入引入,而视觉符号z则在第二层交叉注意力中引入。与之前的方法不同3, 31,当使用多个模块时,我们不更新上下文或视觉标记,正如我们在补充材料(第7节)中分析的那样。在训练过程中,所有位置查询和完整的真实上下文都作为输入被利用以实现并行性,而第一个交叉注意力则被掩蔽,通过推广标准语言建模中使用的因果掩码,强制输入置换ω的顺序。
CSD模块
CSD的动机来自两个关键观察:
• 经过完整训练后,STR模型的预测在大多数情况下比实际训练标签更准确。
• PLM允许用cloze-filling方法(第3节末)细化预测,并在所有其他字符 y ^ ≠ t \hat{y}_{\neq t} y^=t为上下文的情况下计算序列中每个位置t的上下文感知概率。
给定具有潜在标签噪声的数据集 S n o i s e S_{noise} Snoise,CSD包含三个主要步骤:
(i)教师STR模型 p θ T p_{\theta_T} pθT在噪声数据 S n o i s e S_{noise} Snoise上完全训练;
(ii)使用 p θ T p_{\theta_T} pθT计算伪标签和上下文感知日志,并对数据集 S n o i s e S_{noise} Snoise进行封闭填充细化;
(iii)从教师中提炼出一个新的学生模型 p θ S p_{\theta_S} pθS(与初始模型的架构和大小相同)。因此,教师伪标签被用来代替实地真实注释,以最小化式6的负对数似然(NLL)目标,并引入额外的知识蒸馏(KD)损失项,以最小化教师上下文感知软预测(通过Cloze-filling获得)与学生部分上下文预测(通过PLM获得)之间的差异,如图4所示。形式上,KD项可以由以下方式表述:
K D π , t ( x , y ) = D K L ( p θ T η ( ⋅ ∣ y π ≠ t x ) ∣ ∣ p θ s η ( ⋅ ∣ y π < t , x ) ) KD_{\pi,t}(x,y)=D_{KL}(p_{\theta_T}^\eta(\cdot|y_{\pi_{\neq t}}x)||p_{\theta_s}^\eta(\cdot|y_{\pi < t},x)) KDπ,t(x,y)=DKL(pθTη(⋅∣yπ=tx)∣∣pθsη(⋅∣yπ<t,x))
其中上标 η \eta η表示模型的对数在计算软最大值输出前会随温度 π \pi π缩放。我们指出,教师软预测是在完整上下文 y π ≠ t y_{\pi \neq t} yπ=t下计算的,而学生输出则基于标准的 PLM 上下文 y π < t y_{\pi < t} yπ<t计算。
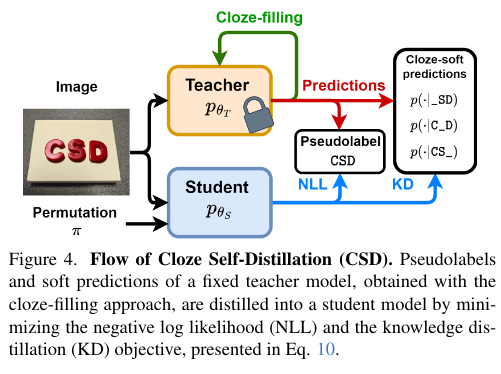
图3 CSD模块
总结
这个文章通过教师-学生模型对数据进行处理,模型层面可以得到质量更好的真实数据,并且增大编码器的参数,让模型的效果也更好了。