AAAI 2026 | DuSSS:基于双语义相似性监督的半监督医学图像分割
文章目录
- [1 论文信息](#1 论文信息)
- [2 论文主要贡献](#2 论文主要贡献)
- [3 论文创新点](#3 论文创新点)
- [4 方法](#4 方法)
-
- [4.1 整体框架](#4.1 整体框架)
- [4.2 语义相似性监督策略 (SSS)](#4.2 语义相似性监督策略 (SSS))
- [4.3 双对比学习预训练 (DCL)](#4.3 双对比学习预训练 (DCL))
-
- [4.3.1 跨模态对比学习 (CMC)](#4.3.1 跨模态对比学习 (CMC))
- [4.3.2 模态内对比学习 (IMC)](#4.3.2 模态内对比学习 (IMC))
- [4.4 文本引导的半监督分割网络](#4.4 文本引导的半监督分割网络)
-
- [4.4.1 文本引导伪标签生成](#4.4.1 文本引导伪标签生成)
- [4.4.2 师生网络伪标签生成](#4.4.2 师生网络伪标签生成)
- [4.4.3 联合损失函数](#4.4.3 联合损失函数)
- [5 实验分析](#5 实验分析)
-
- [5.1 对比实验](#5.1 对比实验)
- [5.2 消融实验](#5.2 消融实验)
- 5.3可视化
- [6 个人声明](#6 个人声明)
1 论文信息
论文题目:DuSSS: Dual Semantic Similarity-Supervised Vision-Language Model for Semi-Supervised Medical Image Segmentation
论文作者:Qingtao Pan, Wenhao Qiao, Jingjiao Lou, Bing Ji, Shuo Li
发表单位:山东大学、凯斯西储大学
发表会议期刊:AAAI 2026
代码链接:https://github.com/QingtaoPan/DuSSS/
2 论文主要贡献
针对半监督医学图像分割中传统方法伪标签质量低、以及现有视觉语言模型 (VLM) 跨模态对齐存在不确定性的核心问题,首次将 VLM 引入半监督医学图像分割领域,提出了双语义相似性监督的视觉语言模型 DuSSS。通过设计语义相似性监督策略 ,基于分布不确定性动态调节语义相似度,有效解决了跨模态一对多对应问题;同时构建了双对比学习 (DCL) 机制,同时进行跨模态和模态内对比学习,增强了跨模态语义一致性和模态内表示能力。基于预训练的 DuSSS,本文进一步设计了文本引导的半监督分割网络,利用文本提示生成高质量的文本引导掩码,与传统伪标签融合后监督模型训练。在 QaTa-COV19、BM-Seg 和 MoNuSeg 三个公共医学图像分割数据集上的实验表明,DuSSS 全面超越了当前的最优方法,在 50% 标注数据设置下分别取得了 82.52%、74.61% 和 78.03% 的 Dice 系数,验证了方法的有效性和泛化能力。
3 论文创新点
- 提出 VLM 驱动的半监督医学图像分割框架,利用文本提示的语义信息引导伪标签生成,从根本上解决了传统单模态半监督方法伪标签质量低、易误导训练的问题。
- 提出语义相似性监督策略 (SSS),将语义嵌入建模为多元高斯分布,通过 2-Wasserstein 距离量化不确定性水平,动态调节语义相似度计算,有效缓解了跨模态一对多对应带来的对齐不确定性
- 设计双对比学习 (DCL) 机制,同时执行跨模态图像 - 文本对比和模态内图像 - 图像、文本 - 文本对比,既增强了跨模态语义关联,又捕捉了模态内的固有表示关系,提升了 VLM 的表示能力。
4 方法
4.1 整体框架
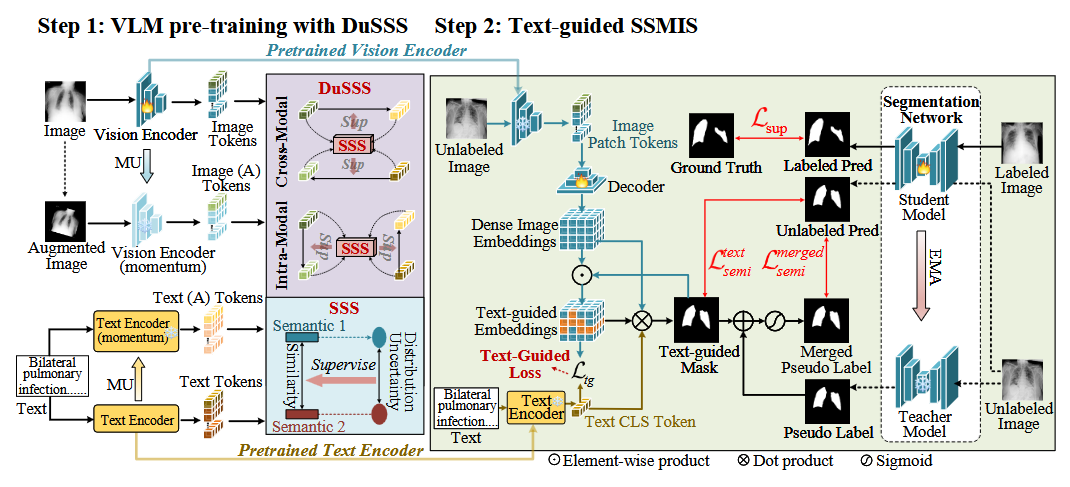
DuSSS 的整体框架如图所示,分为两个核心阶段:**VLM 预训练阶段和文本引导的半监督分割阶段。**在第一阶段,输入成对的医学图像和文本描述,通过双对比学习 (DCL) 进行预训练,同时将语义相似性监督 (SSS) 注入到每个对比学习过程中,学习具有不确定性感知能力的跨模态表示。在第二阶段,利用预训练好的 VLM 生成文本引导掩码,同时采用师生网络架构生成传统伪标签,将两者融合得到高质量的合并伪标签,用于监督学生分割模型的训练。整个框架实现了文本语义信息与视觉信息的深度融合,显著提升了半监督医学图像分割的性能。
4.2 语义相似性监督策略 (SSS)
语义相似性监督策略 是解决跨模态对齐不确定性的核心,其核心思想是基于分布不确定性动态调节语义相似度的计算。将图像和文本的 token 语义嵌入建模为多元高斯分布 N ( μ , σ 2 ) N(\mu, \sigma^2) N(μ,σ2),其中均值向量 μ \mu μ表示分布中心,方差向量 σ 2 \sigma^2 σ2表示分布范围。使用 2-Wasserstein 距离计算两个分布之间的差异,作为不确定性水平:
D 2 W = ∥ μ 1 − μ 2 ∥ 2 2 + ∥ σ 1 − σ 2 ∥ 2 2 D_{2W} = \left\| \mu_1 - \mu_2 \right\|_2^2 + \left\| \sigma_1 - \sigma_2 \right\|_2^2 D2W=∥μ1−μ2∥22+∥σ1−σ2∥22
基于 2-Wasserstein 距离,定义成对数据 ( x 1 , x 2 ) (x_1, x_2) (x1,x2) 之间的不确定性水平:
D u ( x 1 , x 2 ) = a ⋅ D 2 W ( x 1 C L S , x 2 C L S ) + b D_u(x_1, x_2) = a \cdot D_{2W}(x_{1CLS}, x_{2CLS}) + b Du(x1,x2)=a⋅D2W(x1CLS,x2CLS)+b
其中 a 和 b 为可学习的缩放和偏移参数。
为了平衡不确定性和语义相似度,定义相对不确定性为不确定性水平与语义相似度的比值:
D ^ u ( x 1 , x 2 ) = D u ( x 1 , x 2 ) D s ( x 1 , x 2 ) \hat{D}_u(x_1, x_2) = \frac{D_u(x_1, x_2)}{D_s(x_1, x_2)} D^u(x1,x2)=Ds(x1,x2)Du(x1,x2)
D s ( x 1 , x 2 ) = ∥ s 1 − s 2 ∥ 2 D_s(x_1, x_2) = \left\| s_1 - s_2 \right\|2 Ds(x1,x2)=∥s1−s2∥2为语义嵌入之间的欧氏距离。最终的语义相似性监督项定义为:
D S S S ( x 1 , x 2 ) = e − λ D ^ u ( x 1 , x 2 ) D{SSS}(x_1, x_2) = e^{-\lambda \hat{D}_u(x_1, x_2)} DSSS(x1,x2)=e−λD^u(x1,x2)
λ \lambda λ 为约束强度参数。该策略使得对于不确定性高的样本对,会适当降低其相似度约束强度,避免错误的对齐监督。
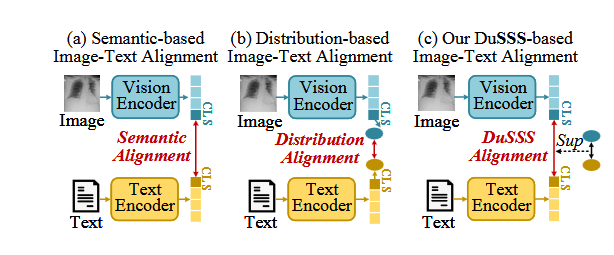
4.3 双对比学习预训练 (DCL)
双对比学习机制同时进行跨模态对比学习 (CMC) 和模态内对比学习 (IMC),全面提升 VLM 的表示能力。在每个对比学习过程中,都注入上述的语义相似性监督策略,对原始的余弦相似度进行修正:
s i m ^ ( I , T ) = 1 − ( 1 − s i m ( I , T ) ) ⋅ D S S S ( I , T ) \hat{sim}(I, T) = 1 - (1 - sim(I, T)) \cdot D_{SSS}(I, T) sim^(I,T)=1−(1−sim(I,T))⋅DSSS(I,T)
4.3.1 跨模态对比学习 (CMC)
跨模态对比学习旨在学习图像和文本之间的语义对应关系,将匹配的图像 - 文本对拉近,不匹配的对推远。基于修正后的余弦相似度,图像到文本的 InfoNCE 损失定义为:
L n c e I 2 T = − E ( I , T ) l o g e x p ( s i m \^ ( I 1 , T + ) / τ ) ∑ n = 1 N e x p ( s i m \^ ( I 1 , T \^ n ) / τ ) \mathcal{L}{nce}^{I2T} = -\mathbb{E}{(I, T)}\left log \\frac{exp\\left( \\hat{sim}(I_1, T_+) / \\tau \\right)}{\\sum_{n=1}\^{N} exp\\left( \\hat{sim}(I_1, \\hat{T}_n) / \\tau \\right)} \\right LnceI2T=−E(I,T) log∑n=1Nexp(sim^(I1,T^n)/τ)exp(sim^(I1,T+)/τ)
同理,文本到图像的 InfoNCE 损失为:
L n c e T 2 I = − E ( T , I ) l o g e x p ( s i m \^ ( T 1 , I + ) / τ ) ∑ n = 1 N e x p ( s i m \^ ( T 1 , I \^ n ) / τ ) \mathcal{L}{nce}^{T2I} = -\mathbb{E}{(T, I)}\left log \\frac{exp\\left( \\hat{sim}(T_1, I_+) / \\tau \\right)}{\\sum_{n=1}\^{N} exp\\left( \\hat{sim}(T_1, \\hat{I}_n) / \\tau \\right)} \\right LnceT2I=−E(T,I) log∑n=1Nexp(sim^(T1,I^n)/τ)exp(sim^(T1,I+)/τ)
最终的跨模态损失为两者的平均值:
L c m c = 1 2 L n c e I 2 T + L n c e T 2 I \mathcal{L}_{cmc} = \frac{1}{2} \left \\mathcal{L}_{nce}\^{I2T} + \\mathcal{L}_{nce}\^{T2I} \\right Lcmc=21LnceI2T+LnceT2I
4.3.2 模态内对比学习 (IMC)
模态内对比学习旨在捕捉同一模态内不同样本之间的语义关联,进一步增强表示的判别性。对于图像模态,对同一图像的不同增强视图进行对比;对于文本模态,对同一文本的不同表述进行对比。模态内对比损失定义为:
L i m c = 1 2 L n c e I 2 I + L n c e T 2 T \mathcal{L}_{imc} = \frac{1}{2} \left \\mathcal{L}_{nce}\^{I2I} + \\mathcal{L}_{nce}\^{T2T} \\right Limc=21LnceI2I+LnceT2T
其中 L n c e I 2 I \mathcal{L}{nce}^{I2I} LnceI2I 和 L n c e T 2 T \mathcal{L}{nce}^{T2T} LnceT2T 的计算方式与跨模态损失类似,同样使用修正后的余弦相似度。
4.4 文本引导的半监督分割网络
基于预训练的 DuSSS,本文设计了文本引导的半监督分割网络,通过融合文本引导掩码和传统伪标签,提升监督信号的质量。
4.4.1 文本引导伪标签生成
利用预训练 VLM 的图像编码器提取图像的 patch 级特征 v f p a t c h v_f^{patch} vfpatch,通过接地解码器 f g ( ⋅ ) f_g(\cdot) fg(⋅) 上采样为像素级特征 v f v_f vf;同时利用文本编码器提取目标类别的文本特征 t f t_f tf。文本引导掩码通过像素级特征与文本特征的点积计算得到:
v f = f g ( v f p a t c h ) , y u t e x t = σ ( t f ⊤ v f ) v_f = f_g(v_f^{patch}), \quad y_u^{text} = \sigma(t_f^\top v_f) vf=fg(vfpatch),yutext=σ(tf⊤vf)
其中 σ \sigma σ为 Sigmoid 函数。为了抑制无关文本区域的干扰,设计了文本引导损失 (\mathcal{L}{tg}),进一步优化跨模态对齐:
L t g ( v f t , t f ) = − 1 2 E ( f , t ) l o g e x p ( s i m ( v f t , t f ) / τ ) ∑ k = 1 K e x p ( s i m ( v f t , t \^ f k ) / τ ) − 1 2 E ( t , f ) l o g e x p ( s i m ( t f , v f t ) / τ ) ∑ k = 1 K e x p ( s i m ( t f , v \^ f k t ) / τ ) \begin{aligned} \mathcal{L}{tg}(v_f^t, t_f) = & -\frac{1}{2} \mathbb{E}{(f, t)}\left log \\frac{exp\\left( sim(v_f\^t, t_f) / \\tau \\right)}{\\sum_{k=1}\^{K} exp\\left( sim(v_f\^t, \\hat{t}_{f_k}) / \\tau \\right)} \\right \\ & -\frac{1}{2} \mathbb{E}{(t, f)}\left log \\frac{exp\\left( sim(t_f, v_f\^t) / \\tau \\right)}{\\sum_{k=1}\^{K} exp\\left( sim(t_f, \\hat{v}_{f_k}\^t) / \\tau \\right)} \\right \end{aligned} Ltg(vft,tf)=−21E(f,t) log∑k=1Kexp(sim(vft,t^fk)/τ)exp(sim(vft,tf)/τ) −21E(t,f) log∑k=1Kexp(sim(tf,v^fkt)/τ)exp(sim(tf,vft)/τ)
4.4.2 师生网络伪标签生成
采用经典的 Mean-Teacher 架构,学生模型 (f_{\theta_s}) 和教师模型 (f_{\theta_t}) 具有相同的架构。教师模型的参数通过学生模型参数的指数移动平均 (EMA) 更新:
θ t = α θ t + ( 1 − α ) θ s \theta_t = \alpha \theta_t + (1 - \alpha) \theta_s θt=αθt+(1−α)θs
α \alpha α为 EMA 衰减系数。教师模型对未标注图像生成传统伪标签 y u t e x t y_u^{text} yutext。
4.4.3 联合损失函数
将文本引导掩码 y u t e x t y_u^{text} yutext和教师模型伪标签 y u t y_u^t yut融合得到合并伪标签,用于监督学生模型的训练。总损失由监督损失和半监督损失组成:
L t o t a l = L s u p + L s e m i \mathcal{L}{total} = \mathcal{L}{sup} + \mathcal{L}_{semi} Ltotal=Lsup+Lsemi
监督损失计算标注图像的预测与真实标签之间的交叉熵损失,半监督损失由合并伪标签损失和文本引导损失两部分组成:
L s e m i m e r g e d = − 1 N u 1 H W ∑ i = 1 N u ∑ j = 1 H W ℓ c e ( y u i , j s , σ ( y u i , j t + y u i , j t e x t ) ) \mathcal{L}{semi}^{merged} = -\frac{1}{N_u} \frac{1}{HW} \sum{i=1}^{N_u} \sum_{j=1}^{HW} \ell_{ce}\left( y_{u_{i,j}}^s, \sigma(y_{u_{i,j}}^t + y_{u_{i,j}}^{text}) \right) Lsemimerged=−Nu1HW1i=1∑Nuj=1∑HWℓce(yui,js,σ(yui,jt+yui,jtext))
L s e m i t e x t = − 1 N u 1 H W ∑ i = 1 N u ∑ j = 1 H W ℓ c e ( y u i , j s , y u i , j t e x t ) \mathcal{L}{semi}^{text} = -\frac{1}{N_u} \frac{1}{HW} \sum{i=1}^{N_u} \sum_{j=1}^{HW} \ell_{ce}\left( y_{u_{i,j}}^s, y_{u_{i,j}}^{text} \right) Lsemitext=−Nu1HW1i=1∑Nuj=1∑HWℓce(yui,js,yui,jtext)
L s e m i = 1 2 ( L s e m i m e r g e d + L s e m i t e x t ) \mathcal{L}{semi} = \frac{1}{2} \left( \mathcal{L}{semi}^{merged} + \mathcal{L}_{semi}^{text} \right) Lsemi=21(Lsemimerged+Lsemitext)
5 实验分析
5.1 对比实验
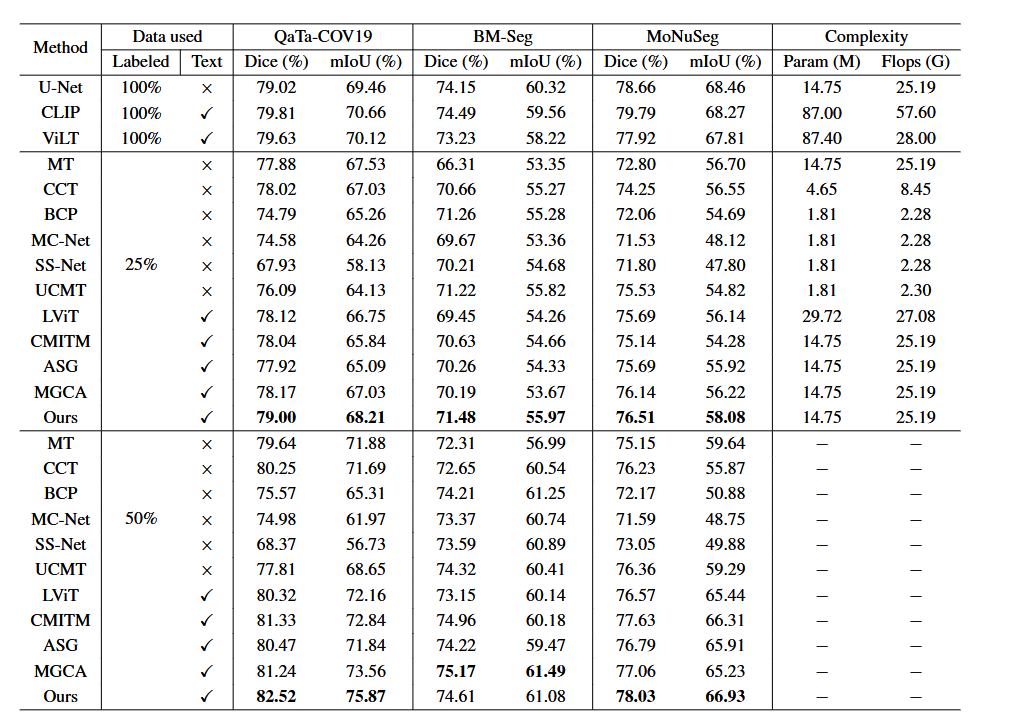
实验在 25% 和 50% 两种标注比例下,与 13 种主流方法进行对比。低标注比例下 DuSSS 优势显著,在所有数据集上均超越传统单模态半监督方法和其他 VLM 方法,且参数量 (14.75M) 和计算量 (25.19G) 与 U-Net 相当,远低于 CLIP、ViLT 等大型 VLM。高标注比例下 DuSSS 依然保持领先,在 50% 标注数据下进一步拉开差距,在 QaTa-COV19、BM-Seg 和 MoNuSeg 数据集上分别比之前的最优方法 MGCA 提升 1.28%、0.44% 和 0.97% 的 Dice。文本引导的效果尤为突出,DuSSS 在 25% 标注下的性能甚至超过了 U-Net、CLIP 等方法在 100% 标注下的性能,充分证明了利用文本语义信息提升半监督医学图像分割的有效性。
5.2 消融实验
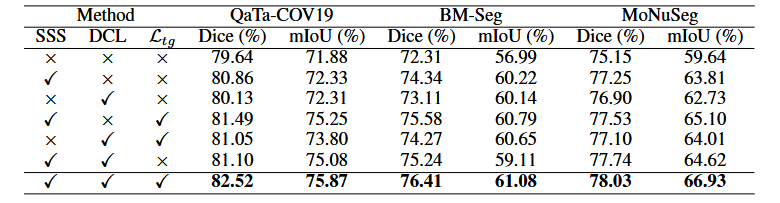
实验在 50% 标注数据设置下验证三个核心模块的有效性。语义相似性监督 (SSS) 贡献最大,单独引入可使 QaTa-COV19 数据集 Dice 提升 1.22%,验证了其解决跨模态对齐不确定性的核心作用。双对比学习 (DCL) 和文本引导损失分别带来 0.49% 和 0.63% 的 Dice 提升,前者增强了模态内和跨模态的语义关联,后者优化了文本引导掩码的质量。三个模块结合时产生显著协同效应,最终在三个数据集上分别达到 82.52%、76.41% 和 78.03% 的 Dice,相比基线提升 2.88%-4.10%,证明了整体架构设计的合理性。
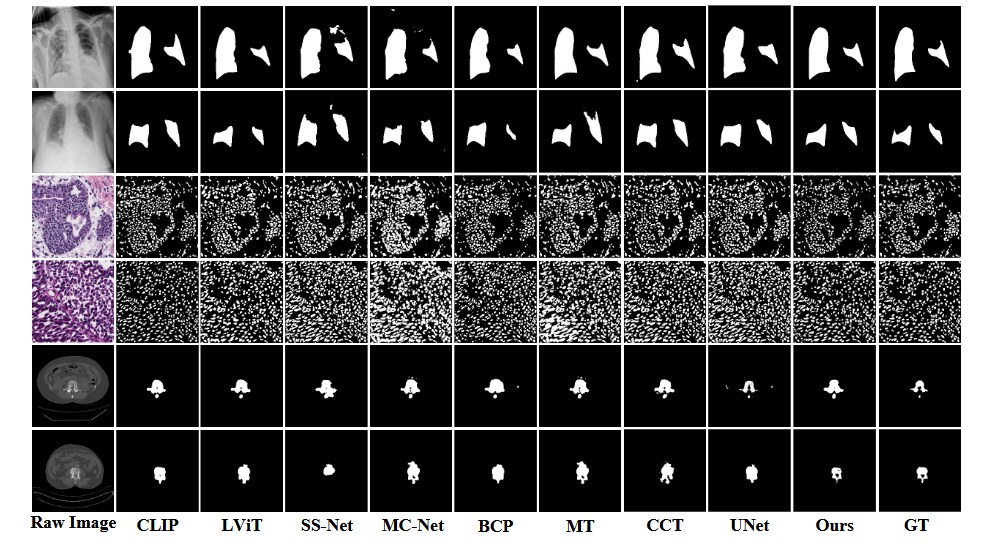
5.3可视化
6 个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解所限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表本文立场。如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。