了解人工智能、机器学习、深度学习
学习机器学习之前,首先明白什么是人工智能、机器学习和深度学习,它们三者之间是什么关系
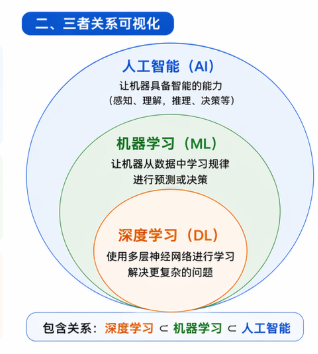
三者定义
**人工智能(AI , Artificial Intelligence):**人工智能是让计算机模拟人类智能的科学与工程,使机器能完成通常需要人类智能才能完成的任务。他是一个广泛的领域,目标是让机器具备"感知、理解、推理、学习、决策"等能力。
**机器学习(ML, Machine Learning):**机器学习是人工智能的一个子领域。它让计算机通过数据学习规律或模式,从而在没有明确编程的情况下进行预测或决策。
**深度学习(DL, Deep Learning):**深度学习是机器学习的一个子领域。它使用多层神经网络从大量数据中自动学习更高层次的特征表示,以解决更复杂的问题。
三者关系
一、机器学习(Machine Learning , ML)
机器学习是实现AI的一种主流方法。
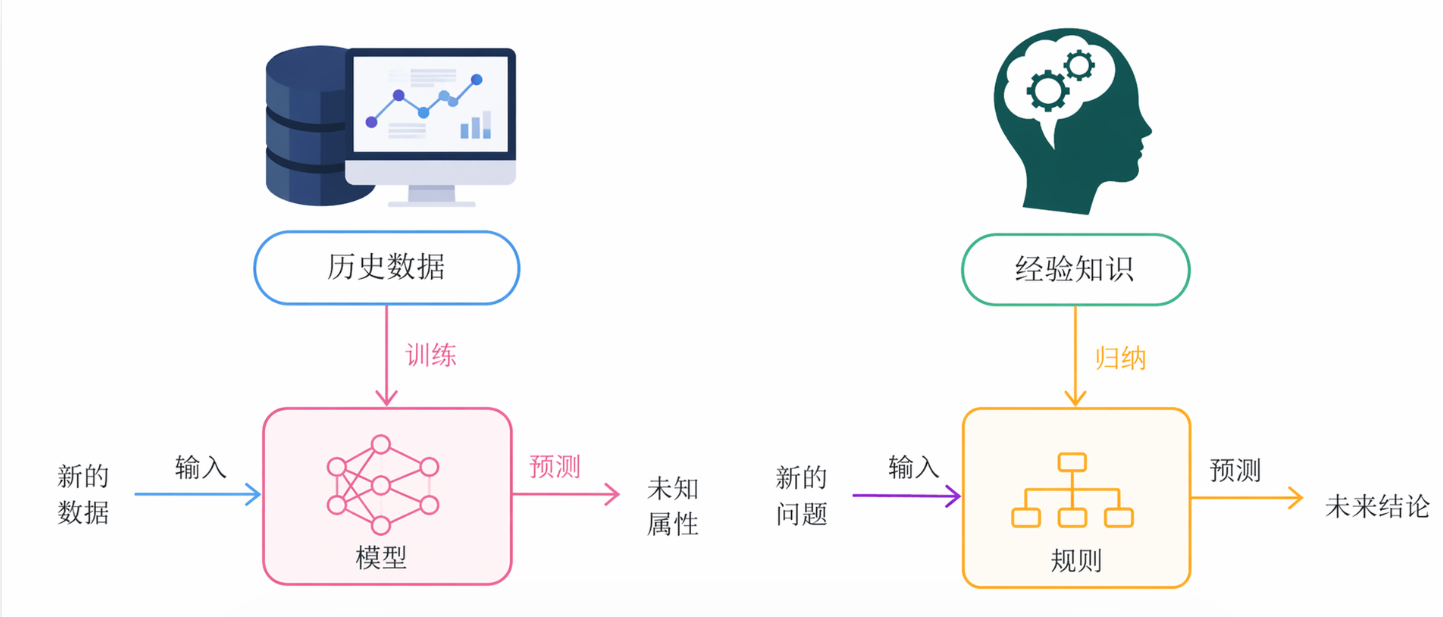
**定义:**不依赖于硬编码的固定队则,而是让计算机利用数据自行"学习"出规律和模式。
核心机制: 通过在数据集上训练模型和算法来逼近数据的内部规律 ,使得在新的数据集上能够进行分类、回归或决策等任务。
通俗的来讲:就像是教小孩识别是不是一只猫,你不学要告诉他猫的特征(两只耳朵、四条腿......)而是给他看很多猫得图片,让他自己从照片中发现特征或总结规律,然后给他一张新的猫的照片,让他识别是不是一只猫。这个过程就是机器学习。
机器学习主要包括三大类:有监督学习、无监督学习、强化学习。
二、机器学习三大类型
1. 有监督学习
定义: 利用一组已知类别的样本(即带有标签的数据) 来调整算法参数,使其能够学习输入数据到输出标签 之间的映射关系 。其目标是训练出一个模型,能够对新的、未见过的 数据做出准确的预测。根据输出类型的不同,主要分为分类(预测离散类别,如垃圾邮件识别)和回归(预测连续数值,如房价预测)。
通俗解释:
"就像学生做带有标准答案的练习题。"
想象你在教一个小孩子认动物。你拿着一张卡片告诉他:"这是猫",又拿一张说:"这是狗"。在这个过程中,"猫"和"狗"的标签就是标准答案 。
机器就像这个学生,它通过反复看这些带有答案的图片,总结规律(比如猫有尖耳朵,狗有大嘴巴)。当它学会了之后,你再给它一张它从未见过的动物照片,它就能自信地告诉你:"这是猫!"
- 核心: 有老师(标签)盯着,做错了立马就能知道,直到做对为止。
2. 无监督学习
定义: 无监督学习是指在未加标签的数据 中,试图找到隐藏的结构或模式。算法不需要外部的监督信号(即不需要标准答案),而是通过探索数据的内在统计规律,将数据进行聚类 (将相似的数据归为一组)或降维(在保留核心信息的前提下简化数据),以此来理解数据的分布特征。
通俗解释:
"就像给一个人一堆乱七八糟的积木,让他自己整理。"
这次没有老师教了,也没有标签告诉你哪个是"红色的"、哪个是"方形的"。机器必须自己观察这堆积木,然后它可能会发现:"哎,这一堆看起来都是圆圆的,那一堆都是方方的",或者"这一块和那一块颜色好像"。
于是,它就把相似的积木放在了一起。虽然它不知道这些积木具体叫什么名字,但它成功地把它们分类整理好了。
- 核心: 没老师教,全靠机器自己找规律,把相似的东西凑一对。
3. 强化学习
定义: 强化学习是一种通过与环境交互 来学习最优策略的方法。一个智能体 在特定的状态 下采取动作 ,环境会根据动作给予反馈(奖励 或惩罚)。智能体的目标不是最大化单次奖励,而是最大化长期的累积奖励。它通过不断的"试错"来调整策略,最终学会在复杂环境中如何做出最佳决策。
通俗解释:
"就像训练小狗,或者你自己学骑自行车。"
这里没有标准答案,也没有人告诉你每一步该怎么做。
当你学骑自行车时,你歪了摔倒了(惩罚 ),你就知道"下次不能这么歪";你骑稳了往前走了(奖励 ),你就记住了这个平衡的感觉。
机器也是这样,它在环境里瞎折腾(试错),做对了给块"糖"吃(加分),做错了打一下手(扣分)。为了吃到更多的糖,它会自己摸索出一套最厉害的玩法。像AlphaGo下围棋,就是靠这种自己跟自己下棋、赢了加分的方式练出来的。
- 核心: 没课本,全靠"吃一堑长一智",为了拿高分不断尝试。
4. 半监督学习
半监督机器学习解决了没有足够的已标记数据来完全训练模型的问题。比如说,您拥有庞大的训练数据集,但不想花费时间和金钱来标记整个数据集。
定义: 通过结合使用监督和无监督方法,您可以打造一个经过良好训练的模型。训练过程一开始类似于监督学习,使用已标记数据获得初始结果,并为算法建立指导原则。当已标记数据用尽后,这个训练到一半的模型就会转而使用未标记的数据集。模型利用已有的训练成果来分析未标记数据,目标是扩充标记数据集。如果模型很有把握能够为某个样本找到合适的标签,该样本就会被添加到已标记数据集中。学习过程再度启动时,已标记样本也变得更多了。通过迭代,更多的样本将被打上所谓的伪标签,模型也可以得到进一步优化。
三、机器学习的基本流程
1. 问题定义与数据收集
这是项目的起点,决定了后续所有工作的方向。
- 明确问题:首先要确定你要解决什么问题。是预测房价(回归问题)、判断邮件是否为垃圾邮件(分类问题),还是对用户进行分群(聚类问题)?明确任务类型是选择合适算法的前提。
- 获取数据:数据是机器学习的"燃料"。你需要根据问题从各种渠道收集数据,来源可以是数据库、API、网络爬虫、传感器或公开数据集(如Kaggle)。数据的质量和数量直接决定了模型性能的上限。
2. 数据预处理与探索
原始数据通常是"脏"的,不能直接喂给模型。这一步的目标是"清洗"数据。
- 数据清洗:处理缺失值(填充或删除)、去除重复项、识别并处理异常值。
- 探索性数据分析:通过可视化和统计方法了解数据的分布、相关性和潜在模式,这有助于后续的特征工程决策。
3. 特征工程
这是最关键、最耗时,也最能体现数据科学家功力的环节。正如我们之前讨论的,"数据和特征决定了上限"。
- 特征提取与转换:将文本、图像等非结构化数据转换为数值向量;对类别特征进行编码(如独热编码);对数值特征进行缩放(标准化/归一化)。
- 特征选择与构造:筛选出对预测目标最有价值的特征,剔除冗余或噪声;利用领域知识组合现有特征,创造出更有表达力的新特征。
4. 模型选择与训练
有了高质量的特征数据,就可以开始"教"模型了。
- 选择模型:根据问题类型(回归、分类、聚类)和数据规模选择合适的算法。例如,线性回归用于预测数值,决策树或神经网络用于复杂分类。
- 划分数据集 :通常将数据划分为训练集 (用于学习)和测试集(用于评估),常见的比例是80/20。
- 模型训练:让算法在训练集上反复迭代,调整内部参数,以最小化预测误差,直到模型收敛。
5. 模型评估与调优
模型训练好后,不能直接上线,必须先进行"考试"。
- 模型评估:使用测试集来验证模型的性能。分类问题常用准确率、精确率、召回率、F1分数等指标;回归问题常用均方误差(MSE)或R²分数。
- 超参数调优:如果模型效果不理想,需要调整超参数(如学习率、树的深度等)。可以使用网格搜索、随机搜索或贝叶斯优化等方法寻找最优参数组合。
- 解决过拟合/欠拟合:如果模型在训练集表现好但测试集差(过拟合),可能需要正则化或增加数据;如果两者都差(欠拟合),则可能需要更复杂的模型或更好的特征。
6. 模型部署
当模型通过评估后,就可以将其转化为实际的生产力。
- 模型保存:将训练好的模型序列化(如使用pickle或joblib),以便后续加载使用。
- 上线服务:将模型部署到服务器、云端或边缘设备,封装成API接口,供应用程序调用。这可以是实时预测(如实时推荐)或批量预测(如每周销量预测)。
7. 监控与维护
部署不是终点,而是新的起点。
- 性能监控:持续跟踪模型在生产环境中的表现。
- 模型重训:随着时间推移,真实数据的分布可能会发生变化(数据漂移),导致模型性能下降。这时需要定期用新数据重新训练模型,以保持其预测能力。
基本流程总结
| 步骤 | 核心任务 | 关键产出 |
|---|---|---|
| 1. 问题与数据 | 明确目标,收集原料 | 原始数据集 |
| 2. 预处理 | 清洗脏数据,探索分布 | 干净的数据集 |
| 3. 特征工程 | 挖掘价值,转换格式 | 高质量特征矩阵 |
| 4. 模型训练 | 选择算法,拟合数据 | 初步训练好的模型 |
| 5. 评估调优 | 验证效果,优化参数 | 性能达标的最终模型 |
| 6. 部署 | 封装接口,上线运行 | 可用的预测服务 |
| 7. 监控 | 跟踪表现,定期迭代 | 持续稳定的预测能力 |