HSFusion:基于状态空间模型的红外与可见光图像层次多尺度特征融合网络
HSFusion: hierarchical multi-scale feature fusion network based on state space model for infrared and visible image fusion
作者: Huaying Cheng, Bin Yang, Zhi Li, Qin Wan, Yanhui Xi, Shao Sheng Fan, Haotian Wu, Yaonan Wang
发表期刊: Expert Systems With Applications
论文地址: https://doi.org/10.1016/j.eswa.2025.130884
摘要 现有的主流红外与可见光图像融合方法主要集中于增强局部特征或全局特征,缺乏不同尺度之间的层次交互。最近,基于状态空间模型的Mamba架构在自然语言任务中展示了强大的能力,能够高效地提取全局特征。基于此,本文提出了一种基于状态空间的多尺度特征融合网络框架,称为HSFusion。首先,我们提出了一种多尺度特征提取网络,它通过残差多头SSM编码器(Residue Multi-Head SSM Encoder)结合了状态空间模型(SSM)和卷积网络在全局和局部特征提取方面的优势。这有效地保留了特征的全局和局部信息,同时显著降低了噪声干扰。其次,设计了一种跨层级全局-局部注意力模型(Cross-Level Global-Local Attention Model),以在不同特征尺度上对全尺度全局-局部特征的层次关系进行建模。它模拟了跨尺度的全局和局部层次之间的关系,促进了图像的高层语义关联。最后,采用自适应特征融合模块动态实现跨模态信息交互。通过门控机制,它自适应地对不同模态的全局特征关系进行建模。在三个不同数据集上的实验结果表明,所提出的多尺度状态空间框架在图像融合任务中表现出色,与现有方法相比在性能和效率上均具有显著优势,同时在高级视觉任务中也展示了强大的泛化能力。
1. 引言
由于不同传感器成像机制的固有差异以及硬件能力的限制,红外与可见光图像本质上具有各自的优势和局限性 (Hao Zhang et al., 2021)。红外图像能够在各种光照条件下持续捕捉目标的红外信息,但缺乏边缘纹理和颜色信息。相反,可见光图像提供卓越的视觉感知,但受光照变化的影响显著。考虑到成像机制和操作条件的互补性,图像融合能够无缝整合来自不同传感器的图像,从而生成既细节丰富又强调热辐射信息的合成图像。尽管现有技术可以取得令人满意的融合结果,但它们在保留局部细节和全局信息方面存在局限性。因此,改进图像融合技术以生成具有更丰富局部细节和更全面全局信息的图像,可以促进后续的实际应用(高级视觉任务),如目标检测 (Shreyas and Sheth, 2021)、目标跟踪 (X. Zhang et al., 2019) 和行人重识别 (K. Kim et al., 2023)。该方法在军事 (Liu et al., 2025)、自动驾驶 (Q. Yuan et al., 2023) 和视频跟踪 (Xia et al., 2013) 等领域具有广泛的应用。
在过去的几十年里,红外与可见光图像融合 (IVIF) 算法大致分为传统方法和基于深度学习的方法。传统算法通过数学建模解决红外与可见光图像融合问题,将任务分为三个关键阶段:特征提取、特征融合和特征重构。目前,主流的传统算法主要包括基于多尺度变换的方法 (A. Ben Hamza et al., 2005)-(Li, 2013)、基于表示的方法 (Rencan et al., 2021)、基于子空间的方法 (Weiwei Kong et al., 2014)、混合方法 (Zhao and Nie, 2021) 以及其他 (Tan et al., 2021) 算法。虽然传统算法在一定程度上可以取得令人满意的融合结果,但它们仍然面临融合规则设计复杂以及依赖手工设计特征提取规则等问题。
随着深度学习的快速发展,研究人员提出了众多深度学习算法 (L. Zhang et al., 2022)-(T. Y. Han et al., 2017)。从网络架构的角度来看,这些方法可以大致分为三类:基于编码器的方法 (T. Y. Han et al., 2017)、基于生成对抗网络 (GAN) 的方法 (Y. Gao et al., 2023)-(Zhishe et al., 2023),以及基于Transformer的方法 (J. Ma et al., 2022)-(Tang et al., 2023)。上述方法在一定程度上可以取得令人满意的融合结果。例如,DenseFuse (Li and Wu, 2019) 使用预训练的自编码器进行特征提取,然后通过不同的融合策略进行特征融合,最后重构融合图像。然而,卷积层依赖局部感受野来捕捉图像特征,这限制了这些方法在识别长距离特征依赖和全局上下文信息方面的能力。为了解决这个问题,(W. Tang et al., 2023) 引入了 YDTR,它利用动态 Transformer 模块来增强全局上下文信息的相关性。然而,基于Transformer的方法需要大量的计算资源,特别是在图像处理中,因为自注意力机制的计算复杂度随着输入大小呈二次方增长。这导致在处理高分辨率图像时产生显著的计算开销,从而限制了Transformer在此类环境中的性能。(J. Ma et al., 2022) 通过滑动窗口方法降低了融合方案的计算复杂度 (Tang et al., 2023)。然而,感受野的减小不可避免地导致某些纹理细节的丢失。
最近,结构化状态空间模型因其计算效率和有效建模长距离依赖关系的能力而备受关注 (Albert and Tri, 2021)-(Fu Daniel et al., 2022)。通过对状态矩阵 AAA 应用低秩条件作用,(Albert and Tri, 2021) 有效地缓解了基础状态空间内过高计算和内存需求带来的挑战,从而即使在需要长距离依赖建模的条件下也实现了计算效率的大幅提升。作为Transformer的替代方案,Mamba (Albert and Tri, 2023) 在先前进展的基础上,将选择机制集成到结构化状态空间模型中。尽管如此,在图像融合领域仍存在一些问题。首先,Mamba以递归方式处理展平的图像序列,这可能导致在空间上彼此靠近的像素在序列中变得非常遥远。然而,在红外与可见光图像融合任务领域,局部和全局特征有助于减少图像中的噪声干扰。开发一种基于Mamba的、整合全局和局部信息的有效结构,对于推进红外与可见光图像融合的研究具有重要价值。最后,现有方法未能有效地利用模态之间的全局信息来进一步指导不同模态之间的跨域信息交互,也不能在不同尺度上学习全局信息,从而忽略了高级语义信息的保留。
为了解决上述问题,本文提出了一种双分支并行层次多尺度特征融合网络,称为HSFusion。首先,我们设计了一种基于状态空间模型和卷积神经网络的新型特征多尺度提取模块,该模块通过自适应机制动态提取局部和全局特征。这种设计有效地缓解了现有网络缺乏细粒度图像特征保留的挑战。随后,为了促进跨层级的深度特征交互,我们设计了一种跨层级全局-局部注意力模型。通过在多尺度空间中对不同模态的背景和细节之间的全局-局部特征差异进行建模,该机制有助于减少红外与可见光图像融合中的噪声干扰。此外,为了促进不同模态之间的信息交互,设计了一个自适应特征融合模块。通过结合门控机制和空间注意力,它指导不同模态互补信息的有效融合,并保留每种模态的关键空间信息。此外,它通过促进不同模态之间的深度交互,丰富了网络捕捉高级语义信息的能力。实验结果表明,HSFusion 优于现有的融合技术,在效率和性能上均表现出色。此外,我们在高级视觉任务(如目标检测)中验证了我们算法的优越性。
综上所述,本文的贡献如下:
- 我们设计了一种基于状态空间模型和卷积神经网络的新型特征多尺度提取模块,通过自适应机制动态提取局部和全局特征。
- 设计了一种跨层级全局-局部注意力模型。针对不同模态图像的背景和细节,它在多尺度空间中对全局和局部特征之间的差异进行建模,促进跨层级的深度特征交互,并减少红外与可见光图像融合过程中的噪声干扰。
- 构建了结合门控机制和空间注意力的自适应特征融合模块。它指导不同模态互补信息的有效融合,并保留每种模态的关键空间信息。
- 通过在多个主流数据集上的实验,我们证明了所提出的 HSFusion 方法优于其他方法,有效地提供了丰富的纹理细节并突出了红外目标。
本文的其余部分组织如下。第2节回顾了相关工作。第3节描述了提出的 HSFusion 算法,而第4节讨论了实验结果。最后,第5节对全文进行总结。
2. 相关工作
本节主要回顾了基于深度学习的IVIF方法的代表性工作,以及HSFusion中使用的SSM模块。
2.1. 基于深度学习的图像融合方法
随着计算机视觉的快速发展,深度学习方法在图像融合领域得到了广泛应用 (Tang et al., 2022)。基于深度学习的图像融合方法大致可分为四类:基于AE的方法、基于CNN的方法、基于GAN的方法和基于Transformer的方法。基于AE的图像融合方法遵循常见的编码器-解码器范式,以完成红外与可见光图像特征的提取以及红外与可见光融合图像的重建。Li et al. (2021) 提出了一种端到端的融合网络,用残差架构取代了传统的融合方法,并引入了一种新的细节保留损失函数。然而,这些方法可能仍然是对称的带有残差块的编码器,其使用经过训练的提取器来获取中间特征和补偿特征,然后通过将中间特征与从该过程中派生出的两个注意力图相乘来进行融合。
基于CNN的红外与可见光融合方法得到了广泛研究,涉及各种网络结构,如密集连接、残差连接、注意力机制、多尺度特征和对比学习等。(Z. Zhu et al., 2022) 利用密集连接块作为骨干网络,并引入了自适应信息保留度来约束融合图像与源图像之间的相似性,解决了缺乏真实标签的问题。(Z. Wang et al., 2022) 开发了一种名为Res2Fusion的融合网络,该网络基于密集ResNet和双重非局部注意力机制。该网络通过密集连接提取多尺度特征,并采用双重非局部注意力模型作为融合层来模拟局部特征的长距离依赖关系,从而尽可能多地保留有意义的信息。(H. Xu et al., 2022) 构建了一个无监督对比学习框架,使融合图像能够在局部区域选择性地保留不同源图像中最相似的特征。此外,他们设计了一种对比损失函数,以有效地引导网络重建特征。
基于GAN的图像融合方法通常是无监督的,其训练过程由损失函数驱动。FusionGAN (Jiayi Ma et al., 2019) 是第一个基于GAN的IVIF方法,它包含一个生成器和一个判别器,以强制融合图像包含更多显著目标和更多纹理。然而,单一生成器无法有效地保留来自多种模态的不同特征。因此,(Ma Jiayi et al., 2020) 提出了DDcGAN,它采用双判别器来保留不同源图像的特征。此外,它利用密集连接,并用反卷积层替换了两个上采样层,以更好地保留图像细节。(J. Li et al., 2021) 通过将注意力机制与多尺度特征相结合,设计了一种基于多尺度注意力的生成器和判别器,这有助于引导网络关注更重要的区域。
由于Transformer强大的长距离建模能力,注意力模型已被引导用于探索其在图像融合领域的潜力。(V. Vs et al., 2022) 设计了一种基于Transformer的多尺度融合网络,该网络同时关注局部和全局信息。然而,Transformer在提取局部信息方面并不是特别有效。为了解决这个问题,(Zhao and Nie, 2021) 提出了一种名为DNDT的顺序密集网络和双Transformer架构,用于提取局部和全局信息,其中双Transformer在融合层之前增强了特征图中的全局信息。上述方法只能处理固定大小的输入图像。为了增强网络鲁棒性,(J. Ma et al., 2022) 提出了一种基于跨域长距离学习和Swin Transformer的方法。他们在跨域长距离学习和Swin Transformer中引入了移动窗口机制,使网络能够接受任意大小的图像。然而,有效的注意力设计往往以牺牲全局有效感受野为代价,并且高效计算与全局建模之间的权衡在很大程度上仍未得到解决。
2.2. 状态空间模型
起源于经典控制理论的状态空间模型(SSMs)最近被引入深度学习中,作为具有竞争力的变换主干网络。它在概念上涵盖了现有序列模型的优势,例如连续时间模型(CTMs)、循环神经网络(RNNs)和卷积神经网络(CNNs)。结构化状态空间模型(S4)通过重新参数化状态矩阵解决了计算效率和内存限制的问题。随后,一种选择机制被集成到名为Mamba的SSM中,使得SSM能够基于当前的token沿序列或扫描路径选择性地传播或遗忘信息。这解决了由恒定序列转换引起的基于上下文推理不足的问题。这显著缩小了SSM与Transformer在自然语言处理任务中的性能差距。
由于SSM在自然语言处理领域的成功,它们很快被应用于计算机视觉(CV)任务中。(Yue Liu et al., 2024) 是一种早期且具有代表性的视觉Mamba模型。它通过将图像块沿水平和垂直维度展开为序列,实现了在这两个方向上的双向扫描,从而解决了二维图像一维扫描的局限性。随后,一系列基于Mamba的网络模型迅速涌现,例如PlainMamba (Chenhongyi Yang et al., 2024)、EfficientVMamba (Xiaohuan Pei et al., 2024)。这些模型证明了Mamba在机器视觉领域的有效性。在本文中,我们探索了Mamba在特定图像融合任务(IVIF)中的潜力,作为未来研究的一个简单而有效的基线。
3.方法
在本节中,我们首先介绍关于状态空间模型的关键背景概念。随后,我们对提出的HSFusion框架进行了全面的概述。本节的其余部分将提供关键模块的深入细节。
3.1. 预备知识
SSM源于经典的状态空间理论,通过隐藏空间h′(t)h'(t)h′(t)将一维函数x(t)∈RLx(t) \in \mathbb{R}^Lx(t)∈RL映射到y(t)∈RLy(t) \in \mathbb{R}^Ly(t)∈RL,从而描述系统的状态和行为。通过在状态空间内对序列数据进行结构化表示,它们能够捕获长距离依赖关系,从而克服了传统RNN和CNN在处理长序列时的局限性。状态空间模型(SSMs)源于经典的状态空间模型。它们通过隐藏空间h(t)∈RLh(t) \in \mathbb{R}^Lh(t)∈RL将一维函数x(t)∈RLx(t) \in \mathbb{R}^Lx(t)∈RL映射到y(t)∈RLy(t) \in \mathbb{R}^Ly(t)∈RL来描述系统的状态和行为:
h′(t)=Ah(t)+Bx(t)(1) h'(t) = Ah(t) + Bx(t) \tag{1} h′(t)=Ah(t)+Bx(t)(1)
y(t)=Ch(t)(2) y(t) = Ch(t) \tag{2} y(t)=Ch(t)(2)
其中A∈RN×NA \in \mathbb{R}^{N \times N}A∈RN×N,B∈RN×1B \in \mathbb{R}^{N \times 1}B∈RN×1,C∈R1×NC \in \mathbb{R}^{1 \times N}C∈R1×N表示系统矩阵。然而,在深度学习中,输入token通常是离散的。因此,我们需要对公式(1)进行离散化,一种常用的方法是零阶保持(ZOH),其定义如下:
Aˉ=exp(ΔA)(3) \bar{A} = \exp(\Delta A) \tag{3} Aˉ=exp(ΔA)(3)
Bˉ=(ΔA)−1(exp(ΔA)−I)⋅ΔB(4) \bar{B} = (\Delta A)^{-1}(\exp(\Delta A) - I) \cdot \Delta B \tag{4} Bˉ=(ΔA)−1(exp(ΔA)−I)⋅ΔB(4)
其中Δ∈R\Delta \in \mathbb{R}Δ∈R是引入的时间尺度参数,矩阵AAA和BBB使用Δ\DeltaΔ转换为它们的离散形式,表示为Aˉ\bar{A}Aˉ和Bˉ\bar{B}Bˉ。那么,公式(1)的离散形式可以表示为:
ht=Aˉht−1+Bˉxt(5) h_t = \bar{A}h_{t-1} + \bar{B}x_t \tag{5} ht=Aˉht−1+Bˉxt(5)
yt=Cht(6) y_t = Ch_t \tag{6} yt=Cht(6)
为了进行高效计算,公式(3)可以通过线性递归进行计算以实现可并行化训练,并通过全局卷积进行计算以实现自回归推理:
y=x⊛Kˉ(7) y = x \circledast \bar{K} \tag{7} y=x⊛Kˉ(7)
Kˉ=(CBˉ,CAˉBˉ,⋯ ,CAˉkBˉ,⋯ )(8) \bar{K} = (C\bar{B}, C\bar{A}\bar{B}, \cdots, C\bar{A}^k\bar{B}, \cdots) \tag{8} Kˉ=(CBˉ,CAˉBˉ,⋯,CAˉkBˉ,⋯)(8)
其中⊛\circledast⊛表示卷积操作,Kˉ\bar{K}Kˉ是结构化卷积核。结构化状态空间序列模型(S4)结合了状态空间模型(SSMs)和深度学习技术的优势,通过在状态空间内以结构化的方式表示序列数据,使其能够捕获长期依赖关系。这克服了传统RNN和CNN在处理长序列时的局限性。
3.2. 整体框架
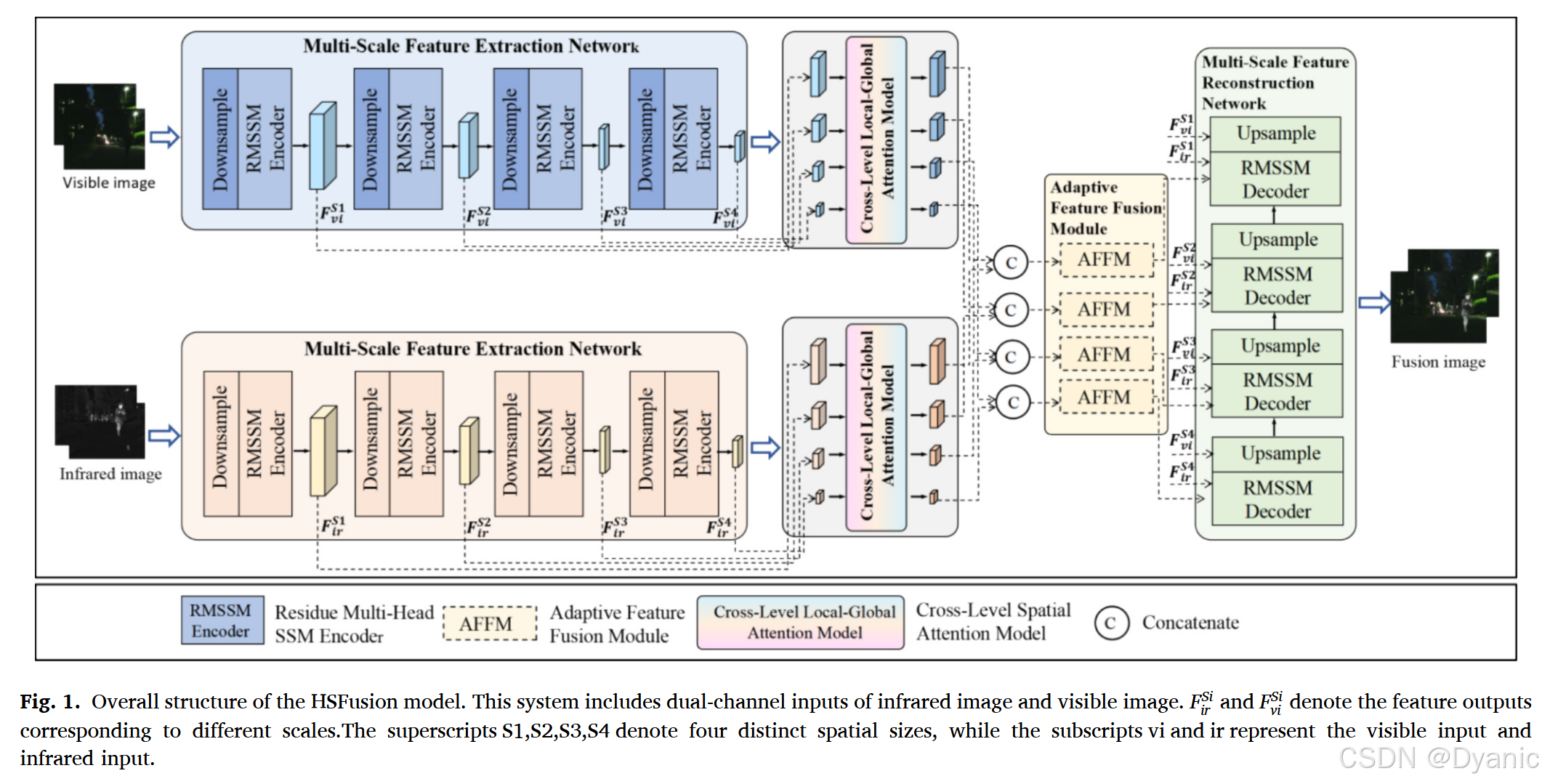
如图1所示,我们的HSFusion采用双分支结构,分别对红外图像和可见光图像进行特征提取。HSFusion通过多尺度特征提取网络(Multi-scale Feature Extraction Network)有效地获取不同尺度下的局部空间信息和全局语义信息。接下来,将不同尺度的局部特征和全局特征输入到跨层级空间注意力模型(Cross-Level Spatial Attention Model)中,以实现层次间的特征交互。为了进一步促进两种模态之间的特征交互,采用自适应特征融合模块(Adaptive Feature Fusion Module)来融合不同模态中对应尺度的交互特征。最后,通过上采样逐步重构融合图像。在接下来的小节中,我们首先介绍多尺度特征提取网络(MFEN),随后详细描述跨层级空间注意力模型(CSAM)、自适应特征融合模块(AFFM)和多尺度特征重构模块(MFRM)。这三个模块的整体架构如图2所示。
3.3. 多尺度特征提取网络
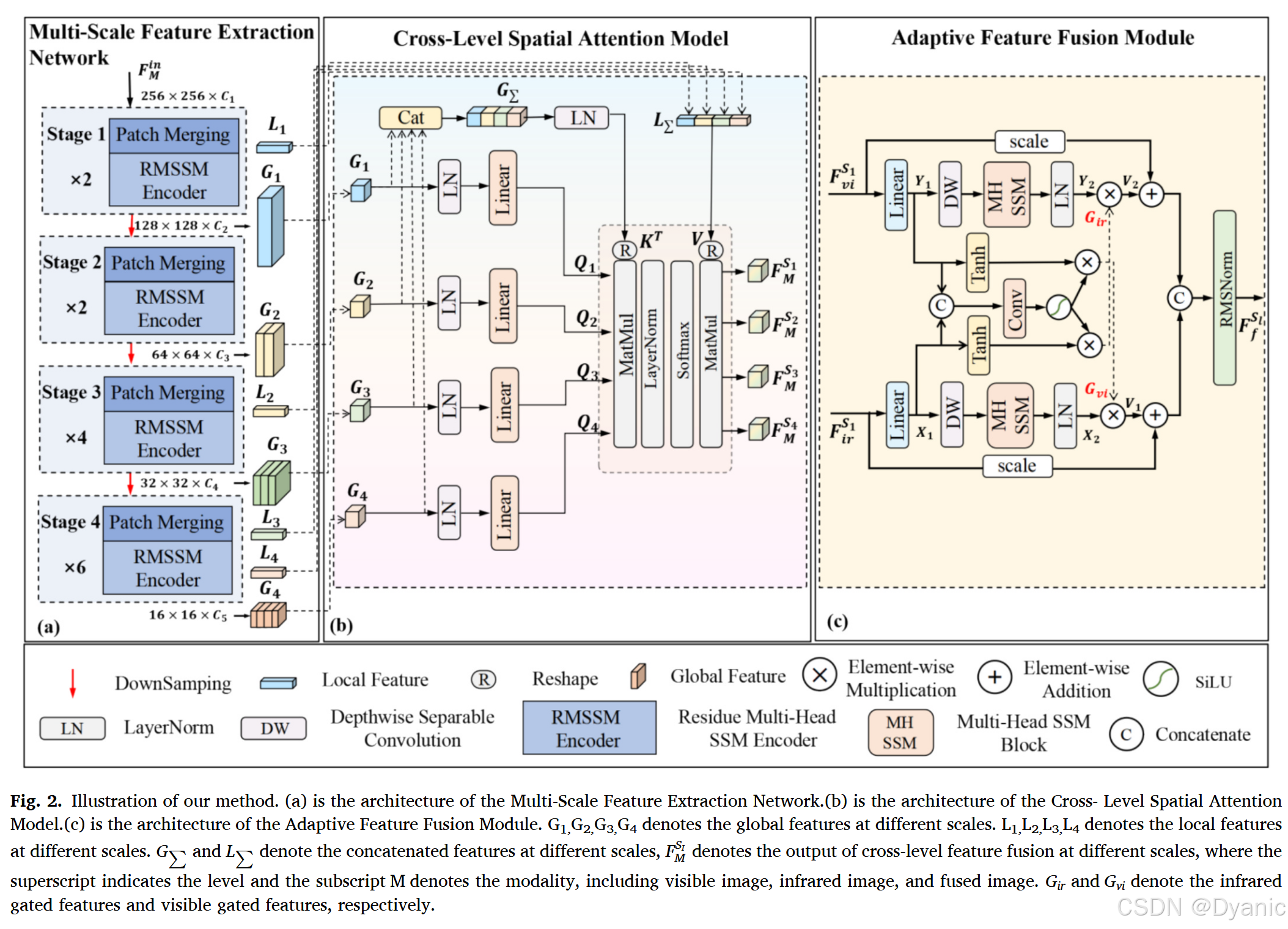
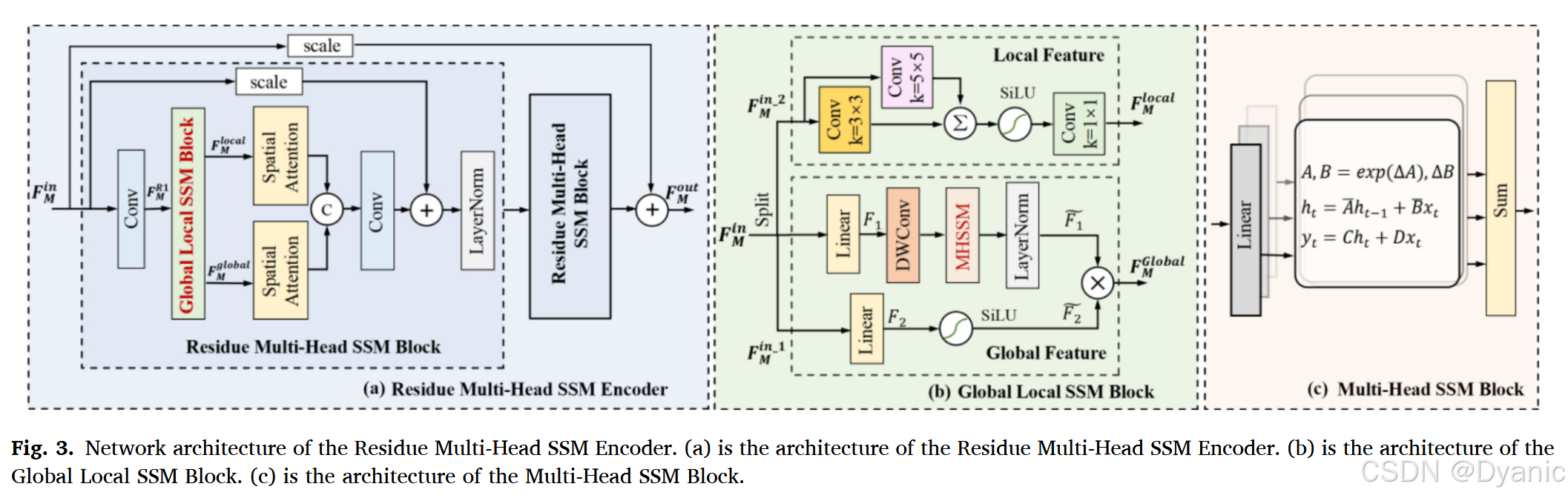
在IVIF任务中,保留不同层级的局部特征和全局信息有利于提升后续高级任务的性能。然而,普通的Vanilla SSM使用一维卷积来提取全局信息,这导致网络缺乏保留局部细节的能力,且在IVIF中的空间感知不足。为了使SSM网络更适合IVIF,我们设计了一个同时包含全局信息和局部信息的多尺度特征提取网络(MFEN),其整体结构如图2(a)所示。多尺度特征提取网络(MFEN)主要由残差多头SSM编码器(RMSSM)组成,它包含两项创新:(i) 全局局部SSM块(GLSSM):通过整合全局和局部特征,并利用空间注意力来定位更关键的局部和全局特征,所提出的方法使得特征能够自适应地融合来自局部和全局表示的关键信息。(ii) 多头SSM块(MHSSM):引入多个独立的注意力头,在不同的子空间中执行SSM模块的计算,从而增强SSM模块的空间感知能力。如图3(a)所示,给定输入特征FMin∈RL×CF_{M}^{in} \in \mathbb{R}^{L \times C}FMin∈RL×C,M∈{红外图像,可见光图像}M \in \{\text{红外图像}, \text{可见光图像}\}M∈{红外图像,可见光图像}。首先,通过卷积层将输入映射到浅层特征FMR1∈RL×2CF_{M}^{R1} \in \mathbb{R}^{L \times 2C}FMR1∈RL×2C。
随后,将FMR1F_{M}^{R1}FMR1输入到全局局部SSM块(GLSSM)以捕获局部和全局特征,生成FMlocalF_{M}^{local}FMlocal和FMglobalF_{M}^{global}FMglobal。最后,采用空间注意力来捕获更全面的空间信息,然后将其拼接并归一化以获得最终结果。为了捕获更丰富的细节,该模块通过残差缩放因子α\alphaα将浅层信息传播到更深层。最终输出表示如下:
FMout=B(FMin)+αFMin(9) F_{M}^{out} = \mathcal{B}(F^{in}_M) + \alpha F^{in}_M \tag{9} FMout=B(FMin)+αFMin(9)
其中FMinF^{in}_MFMin表示红外图像或可见光图像的输入。B(⋅)\mathcal{B}(\cdot)B(⋅)表示由RMSSM组成的编码器,根据经验值,残差缩放因子α\alphaα设置为0.2。
(1) 全局局部SSM块:如图3(b)所示,全局局部SSM模块包括两个主要分支:全局特征提取分支FMglobalF^{global}_MFMglobal和局部特征提取分支FMlocalF^{local}_MFMlocal,旨在同时捕获局部和全局特征信息。设FMin1∈RL×CF^{in_1}_M \in \mathbb{R}^{L \times C}FMin1∈RL×C和FMin2∈RL×CF^{in_2}_M \in \mathbb{R}^{L \times C}FMin2∈RL×C表示通过分割FMinF^{in}_MFMin获得的特征。对于全局特征提取分支,将输入特征FMin1F^{in_1}_MFMin1分割并分别通过两个独立的线性层处理,分别记为F1F_1F1和F2F_2F2。其中一个线性层F1F_1F1之后是深度可分离卷积(DWConv)和多头SSM块(MHSSM),然后进行层归一化(LayerNorm),记为F~1\tilde{F}_1F~1。另一个线性层F2F_2F2通过SiLU激活函数,记为F~2\tilde{F}_2F~2。将这两条路径的输出相乘,得到全局特征FMglobalF^{global}_MFMglobal:
FMglobal=F~1⨂F~2(10) F^{global}_M = \tilde{F}_1 \bigotimes \tilde{F}_2 \tag{10} FMglobal=F~1⨂F~2(10)
对于局部特征提取分支FMlocalF^{local}_MFMlocal,将输入特征FMin2F^{in_2}_MFMin2送入两个并行的卷积层:Conv(k=3×3)\text{Conv}(k = 3 \times 3)Conv(k=3×3)和Conv(k=5×5)\text{Conv}(k = 5 \times 5)Conv(k=5×5)。首先将两个卷积得到的特征图进行合并,然后通过SiLU激活函数引入非线性。最后,通过卷积调整通道维度以获得局部特征FMlocalF^{local}MFMlocal。具体过程公式化如下:
FMlocal=Convk=1(SiLU(Convk=3(FMin2)+Convk=5(FMin2)))(11) F^{local}M = \text{Conv}{k=1}(\text{SiLU}(\text{Conv}{k=3}(F^{in_2}M) + \text{Conv}{k=5}(F^{in_2}_M))) \tag{11} FMlocal=Convk=1(SiLU(Convk=3(FMin2)+Convk=5(FMin2)))(11)
通过以这种方式整合局部和全局特征,全局局部SSM块(Global-Local SSM Block)可以全面表征不同尺度下输入数据的属性,这对于图像特征提取和增强等任务非常有利。
(2) 多头SSM块:如图3(c)所示,为了缓解一维卷积导致的空间感知不足,我们引入多个独立的注意力头在不同的子空间中执行SSM块的计算,这有效地增强了空间感知能力。对于输入F1∈RB×L×DF_1 \in \mathbb{R}^{B \times L \times D}F1∈RB×L×D,它通过一个线性层,然后输入到关键核心模块S6中,以计算每个序列的状态参数,生成与状态相关的长期表示(见算法1)。

S6可以被视为具有头部维度P=1P = 1P=1,多头SSM块的头部维度P>1P > 1P>1,头的数量定义为H=D/PH = D/PH=D/P,其中DDD表示模型维度,PPP表示头部大小。然后,将创建的参数hhh的每个副本分别输入到SSM块中,得到hhh个副本。接着,为每个参数创建HHH个独立的副本并分别输入到SSM块中以获得HHH个副本。最终输出表示为headihead_iheadi:
{Bi=BWiBCi=CWiCheadi=SSMA,Bi,Ci,Δ(xWix)i=1,2,⋯ ,h(12) \begin{cases} B_i = B W_i^B \\ C_i = C W_i^C \\ head_i = \text{SSM}_{A, B_i, C_i, \Delta}(x W_i^x) \end{cases} \quad i = 1, 2, \cdots, h \tag{12} ⎩ ⎨ ⎧Bi=BWiBCi=CWiCheadi=SSMA,Bi,Ci,Δ(xWix)i=1,2,⋯,h(12)
其中投影是参数矩阵Wix∈RL×ed2W_i^x \in \mathbb{R}^{L \times \frac{ed}{2}}Wix∈RL×2ed,WiB∈RL×ed2W_i^B \in \mathbb{R}^{L \times \frac{ed}{2}}WiB∈RL×2ed,WiC∈RL×ed2W_i^C \in \mathbb{R}^{L \times \frac{ed}{2}}WiC∈RL×2ed。接下来,我们将这些值进行拼接,然后重新投影以产生输出YYY。这使得模型能够聚合在不同位置的不同表示子空间中的信息,从而增强其空间感知能力,类似于多头注意力机制:
Y=Concat(head1,head2,⋯ ,headh)WO(13) Y = \text{Concat}(head_1, head_2, \cdots, head_h) W^O \tag{13} Y=Concat(head1,head2,⋯,headh)WO(13)
其中WOW^OWO是可学习的线性变换。最后,得到的YYY被ZZZ门控以获得最终输出,表示为Fout∈RB×L×DF_{out} \in \mathbb{R}^{B \times L \times D}Fout∈RB×L×D:
Fout=Norm(SiLU(Z)⋅Y)(14) F_{out} = \text{Norm}(\text{SiLU}(Z) \cdot Y) \tag{14} Fout=Norm(SiLU(Z)⋅Y)(14)
为了简化,我们将整个过程表示如下:
FfS1=MHSSM(⋅)(15) F_{f}^{S1} = \text{MHSSM}(\cdot) \tag{15} FfS1=MHSSM(⋅)(15)
3.4. 跨层级局部-全局注意力模型
传统的多尺度网络只能在相邻层级之间传递信息流,未能充分利用局部和全局特征跨层级的交互潜力。在红外与可见光图像融合等任务中,不同层级特征(例如,低级纹理和高级语义)的孤立处理很容易导致细节丢失和语义关联不足等问题。为了解决这个问题,我们设计了一个跨层级局部-全局注意力模型(CSAM),旨在融合编码器在各个层级输出的全局和局部特征,增强特征相关性和表示能力。如图2(b)所示,给定第iii层的全局特征Gi∈RCi×h×w,(i=1,2,3,4)G_i \in \mathbb{R}^{C_i \times h \times w}, (i = 1, 2, 3, 4)Gi∈RCi×h×w,(i=1,2,3,4)和局部特征Li∈RCi×h×w,(i=1,2,3,4)L_i \in \mathbb{R}^{C_i \times h \times w}, (i = 1, 2, 3, 4)Li∈RCi×h×w,(i=1,2,3,4),其中h=H/16h = H/16h=H/16和w=W/16w = W/16w=W/16。为了实现层次特征解耦,我们首先分别对全局和局部特征执行层归一化(LN),以消除跨层级特征分布的差异,并为跨层级交互奠定基础:
GΣ=LN(G1,G2,G3,G4),LΣ=LN(L1,L2,L3,L4)(16) G_\Sigma = \text{LN}(G_1, G_2, G_3, G_4), \quad L_\Sigma = \text{LN}(L_1, L_2, L_3, L_4) \tag{16} GΣ=LN(G1,G2,G3,G4),LΣ=LN(L1,L2,L3,L4)(16)
FMSi′=GLCM(G1,G2,G3,G4,GΣ,LΣ)+LN(Gi)(17) F^{S_i'}{M} = \text{GLCM}(G_1, G_2, G_3, G_4, G\Sigma, L_\Sigma) + \text{LN}(G_i) \tag{17} FMSi′=GLCM(G1,G2,G3,G4,GΣ,LΣ)+LN(Gi)(17)
通过独立地对全局特征集G1,G2,G3,G4G_1, G_2, G_3, G_4G1,G2,G3,G4和局部特征集L1,L2,L3,L4L_1, L_2, L_3, L_4L1,L2,L3,L4以及单层全局特征GiG_iGi进行归一化,多尺度特征被分解为"全局-全局"、"局部-局部"和"单层-跨层"维度。这避免了特征混叠,并准确地提取了各个层级的独特信息。基于预处理后的特征,引入了全局局部交叉注意力模块(GLCM)。它通过计算单层全局特征与所有层级拼接后的全局和局部特征之间的相似度来建立跨层级特征关联。给定输入token集G1,G2,G3,G4,GΣ,LΣG_1, G_2, G_3, G_4, G_\Sigma, L_\SigmaG1,G2,G3,G4,GΣ,LΣ,GLCM定义Query、Key和Value矩阵如下:
Qi=WLQGi,K=WLKGΣ,V=WLVLΣ(18) Q_i = W_L^Q G_i, \quad K = W_L^K G_\Sigma, \quad V = W_L^V L_\Sigma \tag{18} Qi=WLQGi,K=WLKGΣ,V=WLVLΣ(18)
其中WLQ,WLK,WLVW_L^Q, W_L^K, W_L^VWLQ,WLK,WLV是用于映射特征维度以进行自适应注意力计算的线性变换矩阵。接下来,我们将Gi∈RCi×h×wG_i \in \mathbb{R}^{C_i \times h \times w}Gi∈RCi×h×w、K∈RCi×h×wK \in \mathbb{R}^{C_i \times h \times w}K∈RCi×h×w和V∈RCi×h×wV \in \mathbb{R}^{C_i \times h \times w}V∈RCi×h×w重塑为RCi×h×w\mathbb{R}^{C_i \times h \times w}RCi×h×w。通过这种设计,单层全局特征G^i\hat{G}iG^i作为Query,与跨层全局特征GΣG\SigmaGΣ (Key)和跨层局部特征LΣL_\SigmaLΣ (Value)进行交互,打破了层级壁垒,实现了"局部-全局"和"单层-跨层"特征的深度关联。在注意力计算之后,通过Softmax和层归一化(Layer Normalization)实现特征校准和增强:
FMSi′=Softmax{LN(QiKTλ)}⋅V(19) F^{S_i'}_{M} = \text{Softmax} \left\{ \text{LN} \left( \frac{Q_i K^T}{\lambda} \right) \right\} \cdot V \tag{19} FMSi′=Softmax{LN(λQiKT)}⋅V(19)
其中λ\lambdaλ是一个缩放因子,用于缓解注意力计算中的维度灾难。Softmax函数动态调整不同层级特征的注意力权重,优先增强关键特征。层归一化进一步校准了特征分布,抑制了噪声和冗余信息。最终输出FMSi′F^{S_i'}_{M}FMSi′保留了多尺度特征的多样性,并为下游融合任务提供了更具区分度、更丰富的层次特征表示。
3.5. 自适应特征融合模块
由于能够捕获不同模态之间的相关性和互补性,交叉注意力在多模态融合中得到了广泛应用。受GMU和CGB中门控机制的启发,我们观察到将跨模态特征捕获的概念与门控机制相结合可以有效地应用于SSM中,从而促进红外图像和可见光图像的融合。因此,我们提出了自适应特征融合模块(AFFM),该模块结合了交叉注意力和门控机制的概念,通过计算来自不同模态的信息对融合特征的贡献并应用交叉门控来实现融合。如图2©所示,它通过两个组件实现交叉融合:一个采用MHSSM模块提取长距离依赖关系,另一个通过门控计算得到自适应权重,随后交换门控权重。在MHSSM分支中,以红外分支为例,输入FinirF_{in}^{ir}Finir首先通过线性层投影为X1X_1X1。随后,使用深度可分离卷积(DWConv)和MHSSM模块进行特征提取。最后,通过层归一化(LN)进行归一化处理以获得X2X_2X2。对于可见光分支FinviF_{in}^{vi}Finvi,通过相同的过程获得Y1Y_1Y1和Y2Y_2Y2。在门控分支中,X1X_1X1和Y1Y_1Y1首先被拼接。拼接结果被送入卷积层并通过SiLU激活。然后,分别将其与经过Tanh激活的X1X_1X1和Y1Y_1Y1进行逐元素相乘,从而获得GirG_{ir}Gir和GviG_{vi}Gvi。为了促进不同模态之间的交互,我们将从红外分支获得的GirG_{ir}Gir与从可见光分支提取的Y2Y_2Y2进行逐元素相乘,同时GviG_{vi}Gvi与X2X_2X2进行逐元素相乘,分别得到V1V_1V1和V2V_2V2。这可以公式化为:
V1=X2⊙Gvi,V2=Y2⊙Gir(20) V_1 = X_2 \odot G_{vi}, \quad V_2 = Y_2 \odot G_{ir} \tag{20} V1=X2⊙Gvi,V2=Y2⊙Gir(20)
最后,我们使用残差连接,随后进行卷积和层归一化,以获得输出FfSlF_{f}^{S_l}FfSl。该过程可以表示为:
FfSl=RMSNorm(Conv(Cat(V1+Finir,V2+Finvi)))(21) F_{f}^{S_l} = \text{RMSNorm}(\text{Conv}(\text{Cat}(V_1 + F_{in}^{ir}, V_2 + F_{in}^{vi}))) \tag{21} FfSl=RMSNorm(Conv(Cat(V1+Finir,V2+Finvi)))(21)
3.6. 多尺度特征重构网络
多尺度特征重构网络如图1所示,其主要模块是RMSSM。输入是各个尺度对应的AFFM的输出,以及来自特征提取模块的全局特征FirSlF_{ir}^{S_l}FirSl和局部特征FviSlF_{vi}^{S_l}FviSl。这三个输入通过Concat拼接在一起,具体过程如下:
F1=Conv(Concat(FfSl,FirSl,FviSl)(22) F_1 = \text{Conv}(\text{Concat}(F_{f}^{S_l}, F_{ir}^{S_l}, F_{vi}^{S_l}) \tag{22} F1=Conv(Concat(FfSl,FirSl,FviSl)(22)
Fout=RMSSM(F1)(23) F_{out} = \text{RMSSM}(F_1) \tag{23} Fout=RMSSM(F1)(23)
3.7. 损失函数
由于红外图像和可见光图像的成像机制不同,它们包含的信息有显著差异。因此,损失函数应充分考虑源图像的固有特征,以获得信息丰富的融合结果,在突出目标的同时保留详细的场景纹理。在这项工作中,我们提出的损失函数定义为:
LTotal=γLSSIM+θLG+βLint(24) L_{Total} = \gamma L_{SSIM} + \theta L_G + \beta L_{int} \tag{24} LTotal=γLSSIM+θLG+βLint(24)
其中LSSIML_{SSIM}LSSIM、LGL_GLG和LintL_{int}Lint分别表示像素损失、梯度损失和结构损失。γ\gammaγ、θ\thetaθ和β\betaβ是用于控制各项权重的因子。结构相似性指数损失(SSIM Loss)是一种用于测量两幅图像之间结构相似性的损失函数。与传统的像素差异指标(如均方误差)不同,SSIM Loss更关注图像的结构信息,包括亮度、对比度和结构的相似性。为了确保融合图像与源图像之间的结构相似性,我们将结构相似性指数(SSIM)纳入损失函数中,其公式化如下:
LSSIM=1−SSIM(If,max(Iir,Ivi))(25) L_{SSIM} = 1 - \text{SSIM}(I_f, \max(I_{ir}, I_{vi})) \tag{25} LSSIM=1−SSIM(If,max(Iir,Ivi))(25)
其中SSIM(⋅)\text{SSIM}(\cdot)SSIM(⋅)包括两幅图像之间对比度和结构相似性的比较。为了获得具有显著细节的融合图像,设计了梯度损失来约束融合结果。梯度损失通过比较它们的梯度图,确保融合图像和源图像在边缘特征和局部变化方面的一致性,公式如下:
LG=1HW∥∇If−max(∇Iir,∇Ivi)∥2(26) L_G = \frac{1}{HW} \| \nabla I_f - \max(\nabla I_{ir}, \nabla I_{vi}) \|_2 \tag{26} LG=HW1∥∇If−max(∇Iir,∇Ivi)∥2(26)
其中∣∣⋅∣∣2||\cdot||2∣∣⋅∣∣2表示矩阵的l2l_2l2-范数。∇\nabla∇表示梯度操作。红外与可见光融合的另一个重要目标是获得显著的热特征。强度损失有效地测量了图像亮度或灰度值的差异。为了捕获图像中的热特征,设计了强度损失来约束融合结果,其定义如下:
Lint=1HW∥If−M(Iir,Ivi)∥1(27) L{int} = \frac{1}{HW} \| I_f - M(I_{ir}, I_{vi}) \|_1 \tag{27} Lint=HW1∥If−M(Iir,Ivi)∥1(27)
其中∣∣⋅∣∣2||\cdot||_2∣∣⋅∣∣2表示矩阵的l2l_2l2-范数。M(⋅)M(\cdot)M(⋅)表示逐元素聚合操作。
4.实验
在本节中,我们首先介绍数据集、实验配置和参数设置。然后,我们提出八个客观指标,并与最先进的方法进行定性和定量比较,这些方法包括 MDLatRR (Li Hui et al., 2020)、Res2Fusion (Z. Wang et al., 2022)、FusionGAN (Jiayi Ma et al., 2019)、DATFuse (Tang Wei He et al., 2023)、DANet (C. Pan et al., 2025)、IFCA (Wang Zhishe et al., 2023) 和 DeDNet (Jingxue Huang et al., 2024)。随后,我们对网络架构和损失函数进行消融实验分析。最后,我们展示了我们的网络在高级视觉任务中的应用,实验结果确认了其优越的性能。
4.1. 实验配置和实现细节
4.1.1. 数据集
在本文中,我们选择了 TNO (Alexander Toet et al., 2014)、RoadScene (Z. Zhu et al., 2014) 和 MSRS 数据集,以将我们的方法与其他对比方法进行评估。(Linfeng Tang et al., 2014) 提出了 MSRS 数据集,该数据集包含 1,083 对红外和可见光图像作为训练数据,361 对作为测试数据。它提供了大量在日常场景中以行人和车辆为特色的场景。TNO 数据集包含 41 对红外和可见光图像,主要描绘了各种与军事相关的场景。RoadScene 数据集包含 221 对红外和可见光图像,以具有车辆、道路和行人的多样化场景为特色。这三个数据集由已对齐的图像对组成。我们从 MSRS 数据集中选择了 1,083 张图像作为训练集,从每张图像中随机裁剪出 120×120120 \times 120120×120 的区域用于训练。随后,在 361 对图像上进行了对比实验。我们选择了 TNO 和 RoadScene 数据集来进一步评估我们方法的泛化能力。
4.1.2. 实验细节
在训练阶段,我们将 batch size 设置为 2,训练 epoch 总数设置为 10。网络参数使用 Adam 优化器进行更新,学习率为 0.001。我们首先将可见光图像转换到 YCbCr 颜色空间,然后将可见光和红外图像的 Y 通道输入到网络中进行训练。最后,我们将得到的融合结果与可见光图像的 Cb 和 Cr 通道结合,形成 YCbCr 图像,然后将其转换为 RGB 图像进行输出。实验在配备 Intel® Core™ i9-10920X CPU、32 GB RAM 和 NVIDIA GeForce GTX 3090 GPU 的平台上进行,确保了稳健的性能和高效的处理。
4.1.3. 评估指标
我们通常使用几个统计指标从不同角度定量评估融合结果。在本文中,我们从四个角度选择了八个评估指标:基于信息的、基于统计特征的、基于视觉信息保真度的和基于结构相似性的。这些指标包括熵 (EN)、互信息 (MI)、标准差 (SD)、平均梯度 (AG)、视觉信息保真度 (VIF)、QAB/FQ^{AB/F}QAB/F、质量估计 (QEQ_EQE) 和结构相似性指数 (SSIM)。指标的细节在 (Ma et al., 2019) 中。EN 和 MI 是基于信息的评估指标。EN 代表熵,测量融合图像中信息的丰富程度;更高的 EN 表明图像包含更多信息,因此更丰富。MI,即互信息,测量两个随机变量之间的依赖性。它可以量化融合图像与输入图像在灰度分布方面的相似性,反映了源图像信息在融合图像中保留了多少。基于统计特征的评估指标包括 SD 和 AG。SD 测量图像中亮度值的离散程度;较大的 SD 表明对比度较高,而较小的 SD 意味着对比度较低。AG,即平均梯度,代表强度的平均变化率,反映了图像中边缘细节和纹理的清晰度。较高的 AG 意味着更锐利的边缘和更清晰的纹理,使其成为评估融合图像清晰度的重要指标。我们选择 VIF、QAB/FQ^{AB/F}QAB/F 和 QEQ_EQE 作为评估视觉信息保真度的指标。VIF 测量参考图像和失真图像之间保留的视觉信息程度;较高的 VIF 表明图像质量更好。QAB/FQ^{AB/F}QAB/F 和 QEQ_EQE 都是基于边缘信息的客观指标。QAB/FQ^{AB/F}QAB/F 通过评估边缘信息从源图像到融合图像的传递来评估融合图像的质量,结合了边缘宽度和角度以进行边缘信息的精细描绘。SSIM 是一种基于结构相似性的指标,通过考虑亮度、对比度和结构信息来评估相似性。
4.2. 对比实验
为了充分展示我们方法的优越性,我们在 MSRS 测试集上与七种最先进 (SOTA) 的算法进行了对比实验。为了保持实验标准的一致性。
4.2.1. 主观评估
七种对比算法的融合结果如图 4 所示。可以看出,虽然所有七种方法都实现了融合效果,但某些问题仍然存在。MDLatRR 很好地保留了红外特征,但缺乏可见光纹理细节,例如树木细节有些模糊。FusionGAN 产生了突出的红外目标,但对可见光背景和细节的保留不足,导致严重的模糊和色彩丢失。与 FusionGAN 相比,IFCA 更好地保留了色彩信息和可见光背景,但缺乏足够的纹理细节并产生显著的伪影(图 4(b))。Res2Fusion 有效地结合了红外和可见光特征,但整体亮度较低,导致在低光条件下丢失了一些可见光背景(图 4(b))。DATFuse 增强了整体亮度并保留了来自两个源图像的特征,但降低了融合图像的对比度,这在图 4© 中远处的行人目标中尤为明显。DeDNet 强调红外目标,但未能保留微弱的纹理细节,并且丢失了一些可见光背景,例如图 4(d) 中的地板纹理,导致整体视觉效果较暗。相比之下,我们的方法不仅实现了突出的红外目标可见性,而且保留了可见光纹理细节,背景呈现出更自然的状态。这是由于我们的多头状态空间模块有效地保留了全局上下文信息,而残差连接的卷积模块保留了丰富的局部纹理细节,从而得到了更清晰、更高质量的融合结果。
4.2.2. 客观评估
主观评估缺乏固定的标准;因此,我们选择了 EN、MI、SD、AG、VIF、QAB/FQ^{AB/F}QAB/F、QEQ_EQE 和 SSIM 作为客观质量指标来比较不同算法的性能。图 5 显示了这些方法在各种指标上的平均排名。HSFusion 算法在 EN、MI、VIF、AG、QAB/FQ^{AB/F}QAB/F 和 QEQ_EQE 上获得了最高分,并且在 SD 上也表现良好,获得了第二好的排名。较高的 MI 和 EN 值表明我们的融合图像成功地保留了来自源图像的更多关键信息,这归功于多头 SSM 块(Multi-Head SSM Block),它使用多头机制更好地从源图像中提取全局特征。较高的 VIF 值表明我们算法的融合结果具有优越的人眼视觉感知,这归因于自适应特征融合模块(Adaptive Feature Fusion Module)有效的跨模态建模和门控机制对重要特征的动态保留。QAB/FQ^{AB/F}QAB/F 和 QEQ_EQE 分数表明我们保留了更多从源图像传递到融合图像的边缘信息,这主要归功于梯度损失。总体而言,指标对比结果证明了我们在融合方面的优越性能,这与我们的主观评估一致。
4.3. 在 TNO 和 RoadScene 数据集上的泛化性能
众所周知,泛化性能是模型评估中的一个关键因素。我们在 TNO 和 RoadScene 数据集上对我们的融合模型进行了泛化实验。
4.3.1. 主观评估
如图 6 所示,我们从 TNO 数据集 (Toet, 2014) 中选择了三张图像,从 RoadScene 数据集中选择了三张图像来展示我们的融合结果。为了更好的可视化,我们将不同尺寸的图像拉伸到统一的显示。图 6 (a)、(b) 和 © 显示了来自 TNO 数据集的图像。在图 6(a) 中,我们放大了房子上的名牌并突出了红外目标。与其他方法相比,我们的方法有效地保留了突出的红外特征和可见光纹理细节。相比之下,DeDNet、DATFuse、FusionGAN 和 Res2Fusion 中的名牌信息模糊甚至丢失,而 ICAF 未能突出红外目标。在图 6(b) 中,我们放大了远处房子的细节并框出了红外特征;由于可见光图像中存在噪声和昏暗的光照,行人信息在可见光图像中丢失。我们的方法成功地突出了红外图像中的行人,同时减少了可见光图像中的噪声。相比之下,FusionGAN、ICAF 和 DeDNet 表现出模糊的纹理细节,SwinFusion 和 MDLatRR 包含过多的噪声,而 Res2Fusion 和 DATFuse 对比度较低。在图 6© 中,DATFuse、Res2Fusion 和 MDLatRR 由于对比度差而模糊了树木细节,FusionGAN 和 DeDNet 缺乏对可见光细节的保留,而 MDLatRR 和 ICAF 未能突出道路红外特征。我们的方法保留了丰富的纹理细节以及突出的红外特征。图 6(d)、图 6(e) 和 图 6(f) 展示了来自 RoadScene 数据集的图像,与 TNO 相反,该数据集大多包含具有详细道路的较亮场景。在图 6(d) 中,我们放大了路标。MDLatRR、FusionGAN、Res2Fusion、DATFuse 和 DeDNet 丢失了可见光纹理细节(例如,文字"ONLY"缺失),而我们的算法完全保留了可见光纹理信息。在图 6(e) 中,我们放大了远处一辆由于过度曝光而被照亮的车辆。DATFuse 由于过度曝光和低对比度而未能保留车辆,FusionGAN 显示出细节模糊,而 ICAF 在低光下缺乏对红外特征的敏感性。然而,我们的方法在过度曝光的情况下仍然保留了可见光纹理信息,并在低光条件下保持了强红外特征。图 6(f) 展示了一个类似的问题。总体而言,我们的方法在捕捉可见光图像中的场景细节的同时,展示了保持红外图像热分布的卓越能力。
4.3.2. 客观评估
图 7 和 图 8 提供了八种算法在来自 TNO 数据集和 RoadScene 数据集的 40 对图像上的客观对比。我们使用了相同的评估指标,表 1 和 表 2 给出了八个指标中每个指标的结果。对于每个指标,最好和第二好的方法分别用粗体和下划线标出。显然,所提出的 HSFusion 在指标 EN、VIF、QAB/FQ^{AB/F}QAB/F 和 QEQ_EQE 上在所有数据集上都实现了最佳性能,并且在 VIF 上比其他替代方法具有特别显著的优势,表明了优越的感知质量。我们的自适应特征融合模块保留了跨模态的更多边缘信息,从而在 QAB/FQ^{AB/F}QAB/F 和 QEQ_EQE 分数上优于其他方法。虽然我们的方法在 SD 和 SSIM 上没有获得最高分,但它非常接近最好的。总体而言,我们的方法在不同数据集上保持了强劲的性能。除了评估指标外,我们还绘制了箱线图来统计评估我们的融合结果,如图 7 和 图 8 所示。在图 7 中,我们的平均 SSIM 不是最高的,但整体指标高度集中,证明了我们的算法在不同场景下保持了强的结构一致性。这种一致性可以归因于 SSIM 损失函数和状态空间模型的动态特征提取。QAB/FQ^{AB/F}QAB/F 和 VIF 均获得最高分,表明我们的融合结果有效地保留了来自源图像的更多边缘信息,从而获得优越的视觉质量并实现了预期的融合目标。在图 8 中,QAB/FQ^{AB/F}QAB/F 和 SD 均排名第一,其值显著高于其他算法,表明我们的算法在目标指标上表现良好,并展示了稳健的融合性能。总体而言,HSFusion 展示了强的客观性能,强调了所提出的残差多头 SSM 编码器(Residue Multi-Head SSM Encode)、跨层级空间注意力模型(Cross-Level Spatial Attention Model)和自适应特征融合模块(Adaptive Feature Fusion Module)的重要性。
4.4. 消融研究
为了验证特定设计选择和损失函数的合理性,本节从主观和客观角度提出相关消融实验的结果。我们从 MSRS 数据集中选择了两组融合结果。图 9 中显示的图像是 01023D,消融实验结果的评估指标列在表 3 中。
4.4.1. 残差多头 SSM 编码器分析
为了证明残差多头 SSM 编码器优异的长距离依赖能力(这使得能够对图像中的上下文信息进行深度探索),我们将其替换为残差卷积模块进行消融实验。框架如图所示。图 9(d) 展示了替换特征提取网络后的实验结果。从图中可以看出,替换提取模块后,图像的深度特征提取不足,未能有效地构建长距离依赖,并且亮度有明显的下降。
4.4.2. 跨层级空间注意力模型分析
自适应特征融合模块主要使用门控瓶颈来由于不同模态之间的相关性和互补性,交叉注意力在多模态融合中得到了广泛应用。自适应地计算不同模态的贡献,引导互补信息的聚合,并最终实现全局跨域特征交互。当我们用简单的拼接操作替换自适应特征融合模块时,融合结果如图 9(e) 所示。从图中可以明显看出,替换后显著目标的亮度降低,并且未能实现互补信息的有效交互。这证明了我们的自适应特征融合模块可以有效地保留来自不同模态的有用的信息。
4.4.3. 自适应特征融合模块分析
跨层级空间注意力模型的关键在于混合和重组所有层级的全局特征和局部特征,从而增强高级语义连接。由于网络有 4 层,query 被设置为 4,而 key (K) 和 value (V) 是通过拼接所有 4 层的全局和局部特征生成的。本节分析了通过拼接来自不同层的特征来生成 K 和 V 对网络的影响,从而验证了全层特征的有效性。表 4 给出了 MSRS 数据集上 K 和 V 的组合方案,其中 KabcK_{abc}Kabc 表示 K 包含来自 a、b 和 c 层的特征,而 VabcV_{abc}Vabc 具有相同的含义。从结果可以看出,包含的层数越多,信息越丰富,模型性能越好,当包含所有层时达到最佳性能。这验证了我们方法的优越性。
4.4.4. 损失函数分析
LSSIML_{SSIM}LSSIM 的目的是构建一个在结构上与源图像一致的融合图像。没有 LSSIML_{SSIM}LSSIM,融合图像表现出一定程度的亮度降低,并且像素质量略微下降。如表 3 清楚所示,MI 和 SD 显著下降,表明缺乏 LSSIML_{SSIM}LSSIM 导致从源图像传递到融合图像的信息减少。LGL_GLG 通过比较梯度图,确保融合图像和源图像在边缘特征和局部变化方面的一致性。如表 3 所示,在缺乏 LGL_GLG 的情况下,AG 值显著下降,表明 LGL_GLG 对图像梯度有显著影响。LintL_{int}Lint 有效地检测图像亮度或灰度值的差异。如表 3 所示,在缺乏 LintL_{int}Lint 的情况下,SD 值显著下降,表明 LintL_{int}Lint 影响图像亮度。
4.4.5. 损失函数权重的有效性
如第 3.7 节所述,我们控制 LSSIML_{SSIM}LSSIM、LGL_GLG 和 LintL_{int}Lint 的权重系数 γ\gammaγ、θ\thetaθ 和 β\betaβ,以引导多模态特征中显著信息和纹理细节的保留。为了验证 γ\gammaγ、θ\thetaθ 和 β\betaβ 的有效性,我们在表 5 中设计了一系列组合,并比较了 MSRS 数据集上的定量性能。γ\gammaγ 负责纹理细节保留,θ\thetaθ 调节显著信息传输,而 β\betaβ 确保多模态特征整合。从表 5 可以明显看出,当 γ\gammaγ 设置为 0 时,EN 的值降低。这一观察结果证实了 γ\gammaγ 在整个融合过程中促进纹理保留的作用。当 γ=10,θ=10,β=20\gamma = 10, \theta = 10, \beta = 20γ=10,θ=10,β=20 时,在 EN、SD、QAB/FQ^{AB/F}QAB/F、QEQ_EQE、VIF、SSIM 的指标上达到了最佳结果,验证了损失函数权重系数的有效性。
4.4.6. 计算效率对比
除了融合指标的评估外,计算性能也是衡量模型性能的重要评估指标。本节在表 6 中给出了我们的算法与其他几种深度学习算法在参数量、每秒浮点运算次数 (FLOPs) 和在 MSRS 数据集上的平均运行时间方面的对比结果。虽然传统算法 MDLatRR 的参数量较低,但其单张图像的运行时间达到 48.12 s,未能满足实时融合的要求。由于 HSFusion 采用了 U-Net 网络结构,与几种基于卷积神经网络的深度学习算法相比,它具有更大的参数量和更高的计算复杂度。然而,与 SwinFusion 相比,它实现了较低的计算复杂度、更少的参数和更快的运行速度。我们的算法在运行速度上比其他算法有显著优势,可以实现实时融合。
4.6. 目标检测实验
为了证明我们方法在高级视觉任务中的有效性,我们使用 YOLOv5 网络进行了目标检测实验,评估了精确率(precision)、召回率(recall)和 mAP 值等指标。这些评估验证了我们的网络具有优越的空间感知和跨模态信息聚合能力。通过融合来自红外和可见光模态的图像,我们实现了改进的目标检测性能。如表 7 所示,精确率和召回率值均高于单模态输入,因为我们的方法有效地保留了突出的热红外信息和可见光纹理细节。从图 10 中,我们可以看到我们的结果结合了两种模态的检测优势。例如,在图 10(a) 中,可见光图像由于低光照而未能检测到阴影中的女人,而在图 10(b) 中,红外图像缺乏色彩细节,使其无法检测到汽车。然而,我们的融合图像捕捉了两种模态的检测优势。在图 10© 中,融合图像中人的检测精确率高于红外(IR)和可见光(VIS)图像。通过利用两种模态的优势,我们的方法有效地证明了所提出算法对后续高级视觉任务的适用性。
5.结论
在这项研究中,我们提出了 HSFusion,一种基于状态空间模型 (SSM) 的层次多尺度特征融合网络,用于红外和可见光图像融合。作为一个端到端框架,HSFusion 通过利用 SSM 的优势(特别是它们高效建模长距离依赖的能力)并将其与卷积网络集成,解决了全球信息提取和计算效率之间长期存在的权衡。实验结果表明,该集成框架在视觉纹理和表现力方面实现了具有竞争力的融合结果,在各种数据集上实现了最先进的性能,并突出了其在目标检测等高级视觉任务中的潜力。虽然我们的算法有效地保留了全局上下文信息,但在某些过度曝光的场景中遇到了纹理细节丢失的一些问题。在我们未来的研究中,我们打算根据特定场景的输入图像参数自动调整这些损失函数的尺度,旨在实现能够更有效地适应不同光照条件的更稳健的融合结果。