rag是retrieval augmented generation(检索增强生成)的缩写,它的原理图如下:
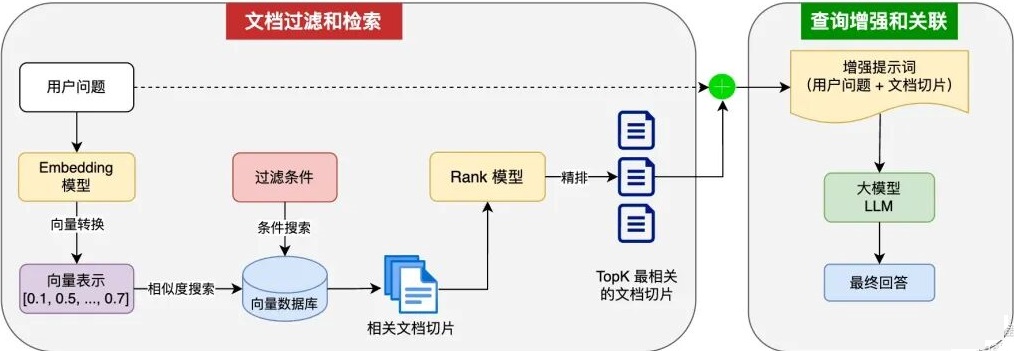
这里,把文本内容分词,然后转向量,存入向量数据库,完成数据存储。
当用户提出问题,会先去查询向量数据库,查出关联的片段,然后选出最相关的文档切片交给大模型LLM去处理,这样就可以避免大模型答非所问,出现幻觉等情况。
rag其实就是在直接和大模型进行对话的基础上,增加了向量存储和查询这部分。
如今向量数据库也有很多,chroma,milvus,faiss,甚至redis,postgresql都有向量扩展程序,支持向量存储。
今天就介绍spring-ai结合pgvector来实现rag,并实现本地知识库。
首先准备工作是需要准备postgresql并且安装pgvector扩展。
这里采用spring-ai来实现rag。
引入依赖:
XML
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.9</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.xxx</groupId>
<artifactId>spring-ai-pgvector</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>spring-ai-pgvector</name>
<description>spring-ai-pgvector</description>
<properties>
<java.version>17</java.version>
<spring-ai.version>1.1.2</spring-ai.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-pgvector</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>springboot版本不能太高,选择的是3.5.9。
添加配置文件:application.yml
XML
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
options:
model: deepseek-r1:1.5b
temperature: 0.7
embedding:
options:
model: nomic-embed-text:latest
vectorstore:
pgvector:
table-name: vector_store
initialize-schema: true
index-type: hnsw
dimensions: 768
datasource:
driver-class-name: org.postgresql.Driver
url: jdbc:postgresql://localhost:5432/test
username: Administrator
password:这里采用的是deepseek-r1:1.5b本地模型,通过ollama启动,分词向量模型:nomic-embed-text。
数据库采用了postgresql带pgvector扩展。指定数据库即可,启动项目,会自动建表vector_store。
springboot启动类没什么好说的,就一个main函数,然后 SpringApplication.run()
这里给出一个主要的controller类:
java
package com.xxx.springaipgvector.web;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.tika.TikaDocumentReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.io.FileSystemResource;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.File;
import java.util.List;
@RestController
@RequestMapping("/rag")
public class RagController {
@Autowired
private VectorStore vectorStore;
@Autowired
private ChatModel chatModel;
@PostMapping("/save")
public ResponseEntity save() {
File document = new File("f:\\test.txt");
TikaDocumentReader tikaDocumentReader = new TikaDocumentReader(new FileSystemResource(document));
TokenTextSplitter textSplitter = new TokenTextSplitter(1000,200,10,400,true);
List<Document> docs = textSplitter.apply(tikaDocumentReader.get());
docs.forEach(doc->{
vectorStore.add(List.of(new Document(doc.getFormattedContent())));
});
return ResponseEntity.ok("ok");
}
@GetMapping("/chat")
public String chat(String question) {
List<Document> documents = vectorStore.similaritySearch(SearchRequest.builder()
.query(question)
.topK(1)
.build());
String promptTemplate = """
你是一个智能助手,你可以根据下面搜索到的内容回复用户
### 用户的问题是
%s
###具体内容
%s
""";
promptTemplate = String.format(promptTemplate, question, documents.get(0).getText());
Prompt prompt = new Prompt(promptTemplate);
ChatResponse response = chatModel.call(prompt);
String result = response.getResult().getOutput().getText();
System.out.println(result);
return result;
}
}这里构建了两个方法,一个save,把本地的一个测试文本加载并写入向量数据库中。
另一个方法是用来进行对话测试的。请求时带上参数question=""即可。

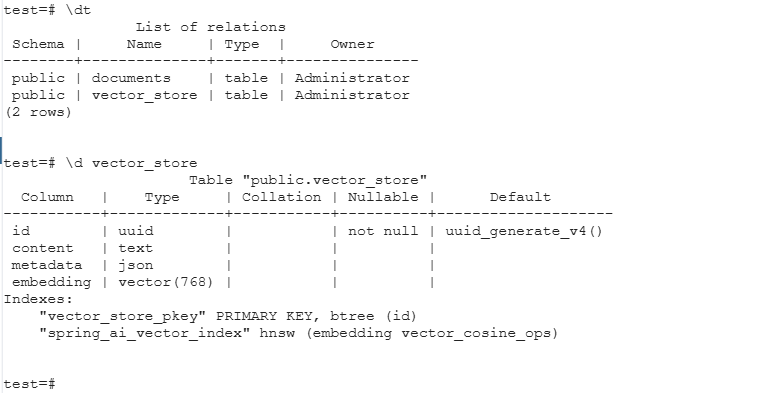
启动项目之前,数据库中没有向量表vector_store。启动springboot项目,数据库中自动生成表。
在运行测试接口之前,我们需要启动ollama服务,这样我们的rag本地模型才能正常工作。

ollama启动正常,会开启11434端口监听,浏览器访问localhost:11434正常则表示启动没问题。
另外,在配置文件中还配置了词向量模型nomic-embed-text:latest,因此我们在测试之前,需要ollama pull nomic-embed-text:latest。

正常启动,先测试save。
我们准备的文本内容如下:
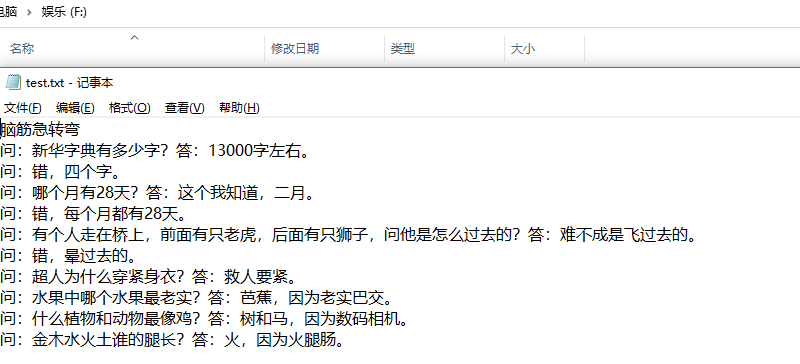
采用一问一答模式的脑筋急转弯题目。
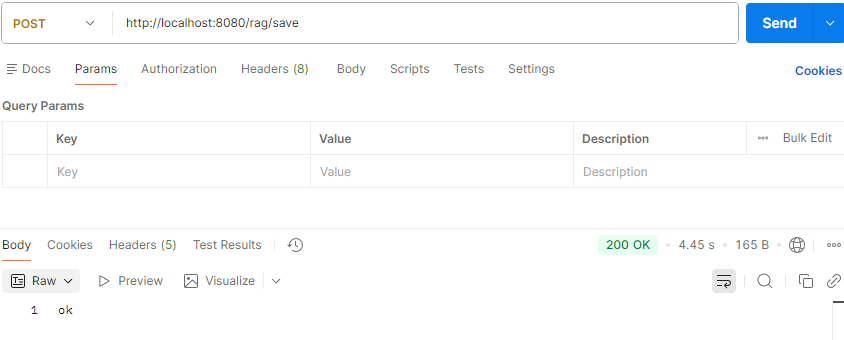
我们启动的是web服务,save接口是post方法,我们直接测试,返回ok。表示成功,文本写入向量数据库。

接着,我们测试几个问题?
超人为什么穿紧身衣?
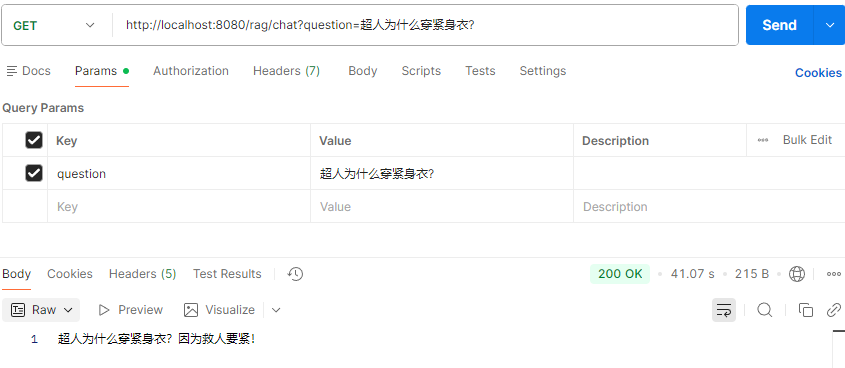
什么水果最老实?
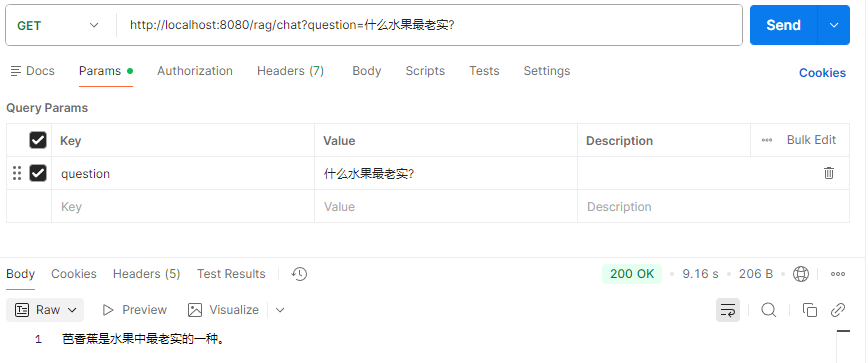
以上通过java的方式实现了rag本地知识库。熟悉了rag的原理。项目第一次运行,会下载一些python相关的依赖,可能会失败或者很慢,需要耐心等待。
本文还结合了ollama运行本地模型,这里没有重点展开。在window上运行,我们需要下载ollama-desktop程序并安装。